基于多模态唇部状态识别的语音导航抗干扰系统
2025-01-13王晗陈怡霖季钰姣杜若琳
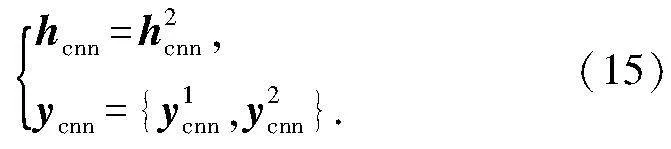
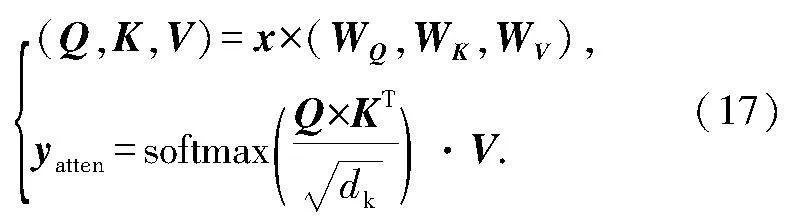
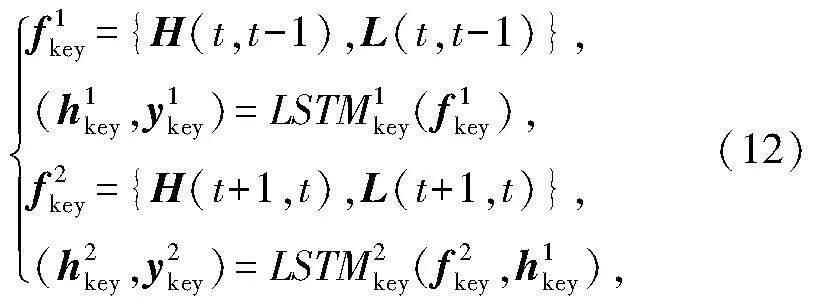

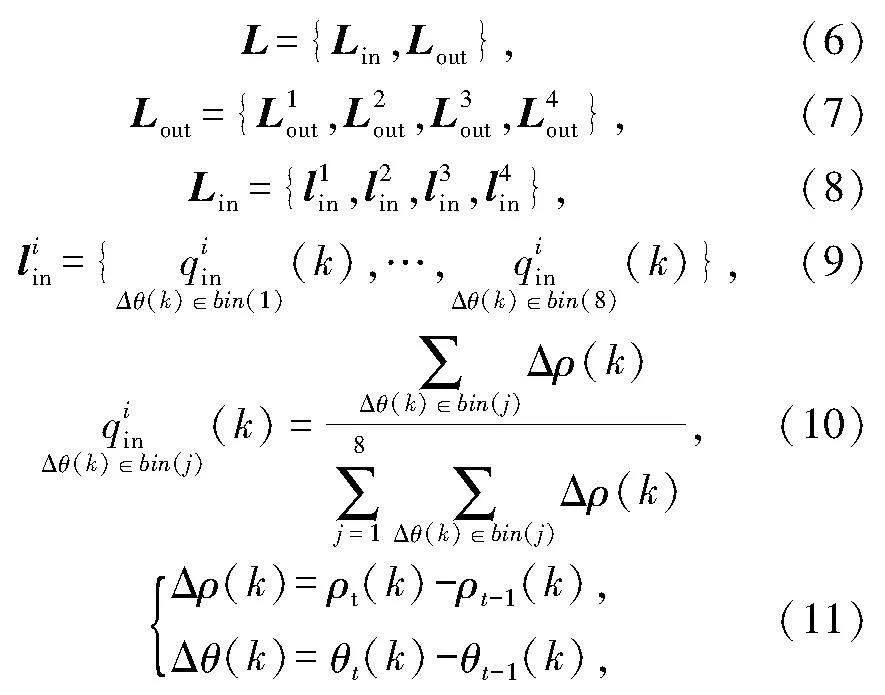
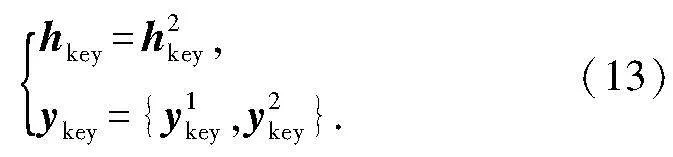


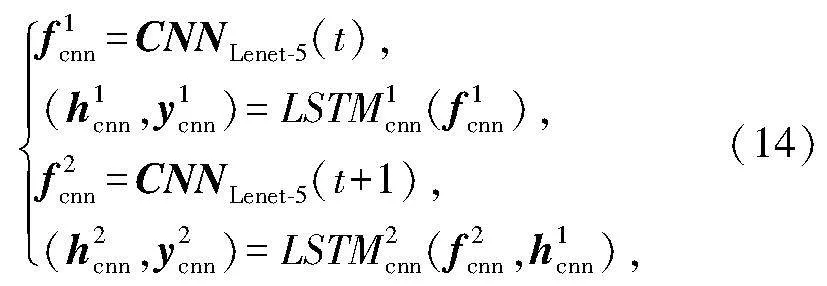



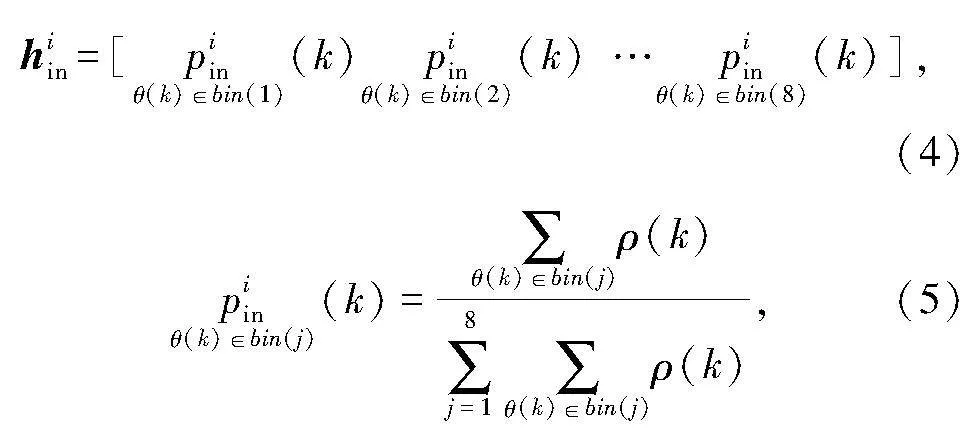

摘要: 针对现有车载语音导航设备易受到车内外噪声干扰、无法准确判定声音信号来源的问题,提出了一种基于唇部状态识别的语音导航抗干扰系统.通过摄像头实时识别驾驶员唇部状态,准确判定驾驶员声音信号的起止时间端点,进而控制语音导航输入信号开启和关闭,增强驾驶员对语音导航的控制权限,减少车内外的噪声干扰.为保证唇部状态识别的准确性和鲁棒性,提出了一种基于关键点-外观短时特征融合的多模态唇部状态识别网络,进行了关键点短时特征有效性试验、多模态特征融合的唇部状态识别消融试验、实验室模拟环境和真实车载环境下的语音导航抗干扰试验.结果表明,文中提出的关键点短时特征算子可增强唇部状态变化表征能力14%以上,关键点-外观特征融合的唇部状态识别网络通过特征互补提升识别准确性8.98%以上.基于该网络的语音导航抗干扰系统准确性高(92.6%)、实时性好(检测速度为35帧/s);在驾驶员左、右侧面超过70°的大幅度头部姿态变化下,能有效减少车内外噪声对导航语音控制的干扰,表现出较高的鲁棒性.
关键词:" 语音导航抗干扰系统; 唇部状态识别; 关键点; 外观特征; 特征融合; 长短期记忆网络
中图分类号: TP391.41; TP183" 文献标志码:" A" 文章编号:"" 1671-7775(2025)01-0082-09
Voice navigation anti-interference system based on
multimodal lip state recognition
Abstract: To solve the problem that the existing in-vehicle voice navigation devices were susceptible to interference from the noise both inside and outside vehicle and could not accurately determine the source of sound signals, the voice navigation anti-interference system based on lip state recognition was proposed. Using a camera to perform real-time recognition of the driver lip state, the start and end points of the driver voice signal were accurately determined, and the activation and deactivation of the voice navigation input signal were controlled for enhancing the driver control over the voice navigation and reducing the interference from the noise inside and outside vehicle. To accurately assess the accuracy and robustness of lip state recognition, the multimodal lip state recognition network based on key point-appearance short-term feature fusion was proposed. The experiment of validating the effectiveness of key point short-term features, the ablation experiment of multimodal feature fusion in lip state recognition and the voice navigation anti-interference tests in both simulated laboratory environments and real in-vehicle environments were conducted. The results show that the proposed key point short-term feature operator can enhance the representation ability of lip state changes by more than 14%. The key point-appearance fusion lip state recognition network improves the recognition accuracy by 8.98% through feature complementation. The voice navigation anti-interference system based on this network exhibits high accuracy of 92.6% and good real-time performance with detection speed of 35 F/s. The interference from the noise inside and outside vehicle on the driver voice control authority can be effectively reduced even under the significant head pose changes of more than 70 degrees to the left or right, which demonstrates high robustness.
Key words:" voice navigation anti-interference system; lip state recognition; key points; appearance features; feature fusion; long short-term memory network
随着导航技术的迅速发展,车载导航设备被广泛应用于道路交通[1].常见导航交互系统可分为触摸式和语音式[2].触摸式即通过手部的触碰、选择确定导航的输入信息.相较于触摸式导航设备,语音式操作更加方便[3]:解放双手,在车辆行驶过程中通过语音命令对其交互控制,避免手动操作时潜在的驾驶危险.然而,常见语音导航设备无法准确判定声音信号的来源,车内外噪声对驾驶员的语音控制权限造成干扰.利用视觉检测驾驶员嘴部说话状态,进而控制语音导航的控制权限,可有效减少车内乘客语音和车外环境的噪声干扰,显著增强驾驶员对导航的语音控制.
现有唇部状态识别方法可分为基于唇部关键点和基于唇部外观特征的识别方法.LIN B. S.等[4]利用唇部特征点纵横向比值结合轮廓面积对唇部状态进行识别.马宁等[5]将连续帧的特征点序列作为输入,利用长短期记忆网络(long short-term memory,LSTM)对唇部特征点时间序列建模.SONG T.等[6]建立Chaos相位图模式评价函数对相邻两帧的唇部区域图像像素点变化情况进行识别,克服光流法[7]易受光线变化的影响.闫捷[8]利用卷积神经网络(convolutional neural networks, CNN)提取唇部区域图像的外观特征,将外观特征序列作为输入,采用双向长短期记忆网络[9](bi-directional long short-term memory,BiLSTM)对唇部外观特征序列变化进行建模,识别唇部状态.
唇部关键点建模方法可有效减少光照及方向变化影响;唇部外观特征建模方法对于唇部局域像素点变化更敏感.文中拟提出基于“特征点-外观”短时特征融合的多模态唇部状态识别网络,以有效融合不同特性的特征,提高唇部状态识别准确性和鲁棒性.
1 基于视觉检测的语音导航抗干扰系统
1.1 语音导航抗干扰原理与系统结构
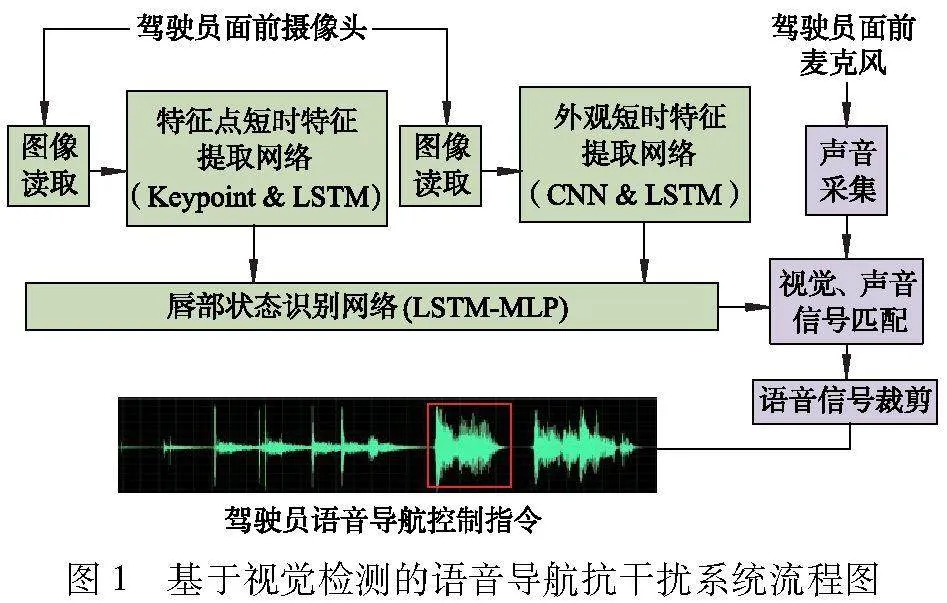
图1给出了文中提出的基于视觉检测语音导航抗干扰系统的流程图.通过摄像头对驾驶员唇部状态的实时识别,准确判定驾驶员声音信号的起止时间端点,确定语音导航输入信号开启和关闭的时间,增强驾驶员对语音导航的控制权限,减少车内外的噪声干扰.
1.2 多模态短时特征唇部状态识别网络
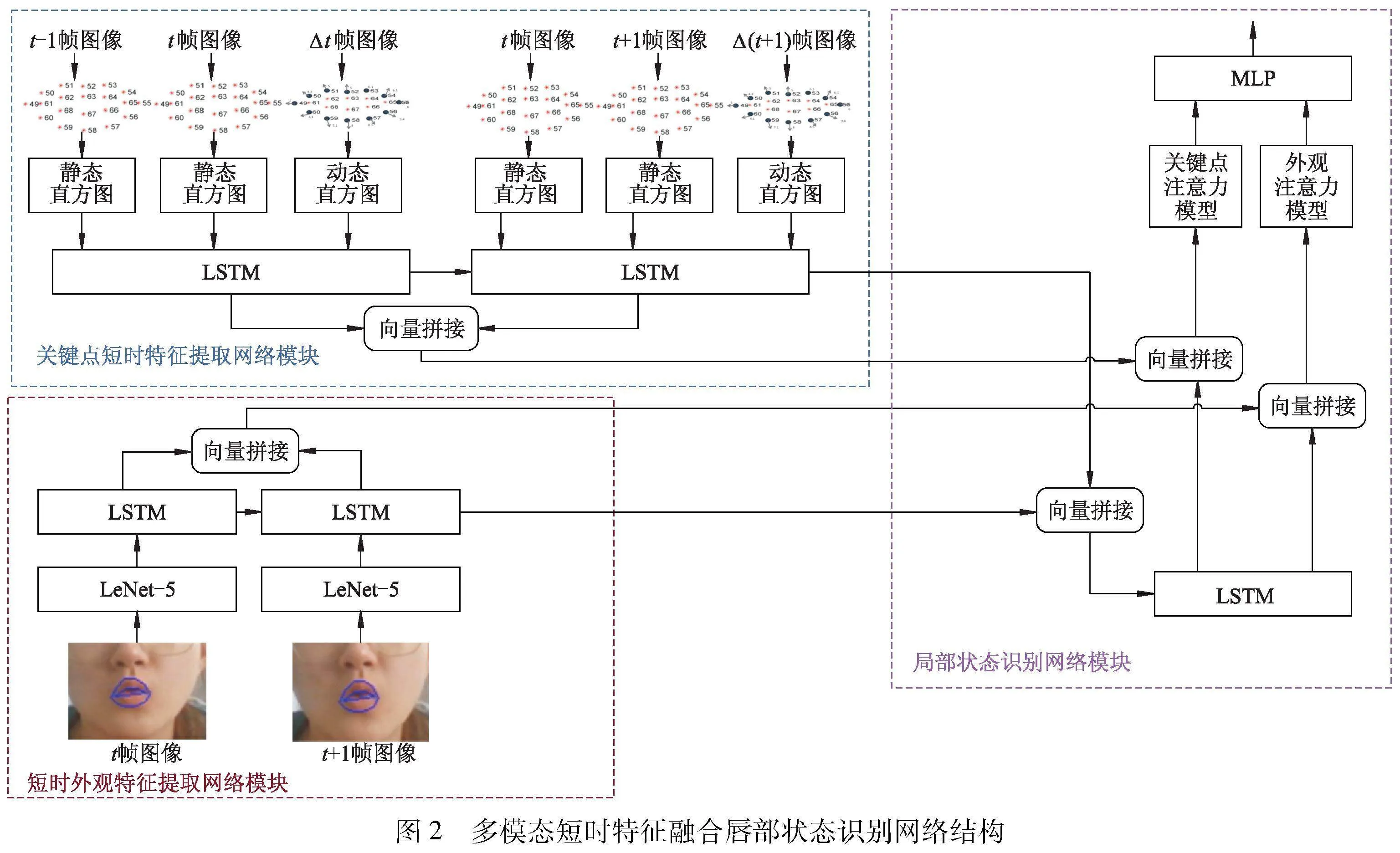
文中提出的多模态短时特征融合唇部状态识别网络结构如图2所示.该网络共由3个子网络模块构成:唇部关键点短时特征提取网络模块、唇部外观短时特征提取网络模块和唇部状态识别网络模块.
1.2.1 唇部关键点短时特征提取模块
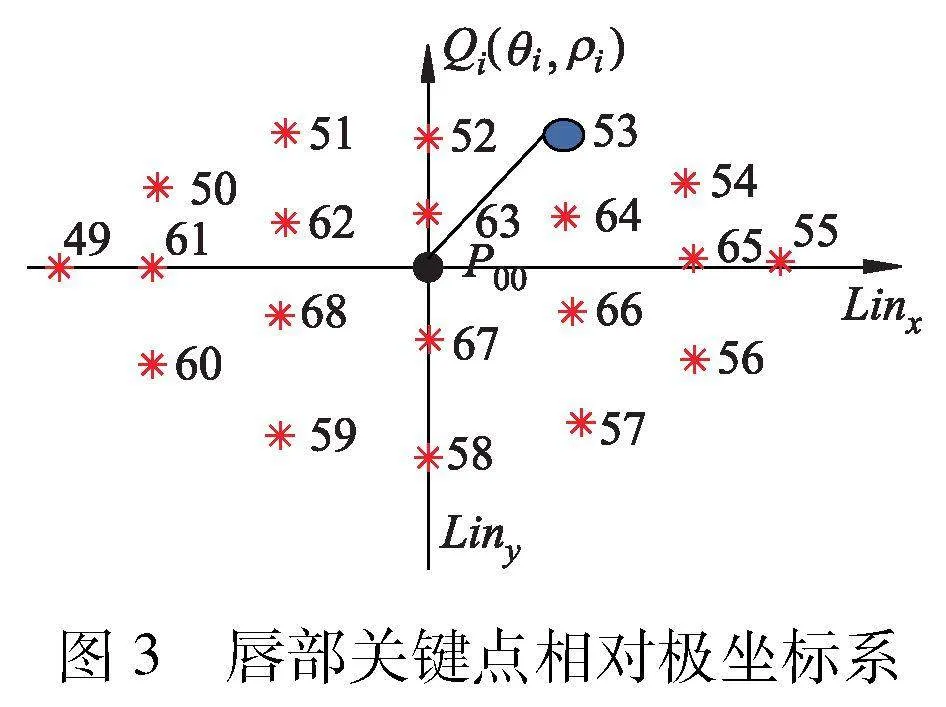
关键点短时特征提取网络模块巧妙地运用了长短期记忆网络(LSTM)技术,精准建模相邻两帧图像中唇部轮廓关键点位置信息的细微动态变化.唇部关键点的相对极坐标系(见图3)简化了位置变化的描述,显著提升了模型识别效率与精确度.
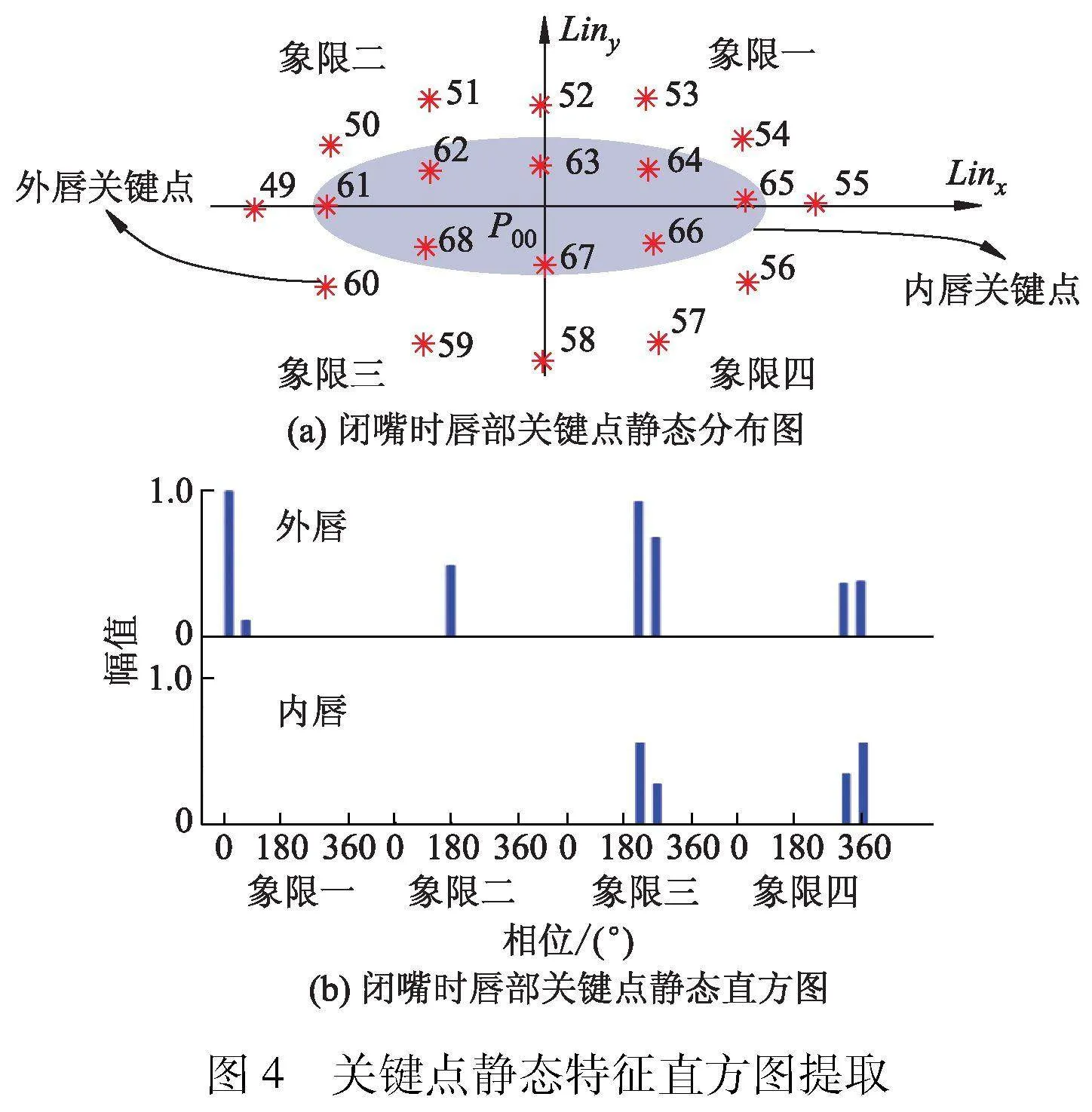
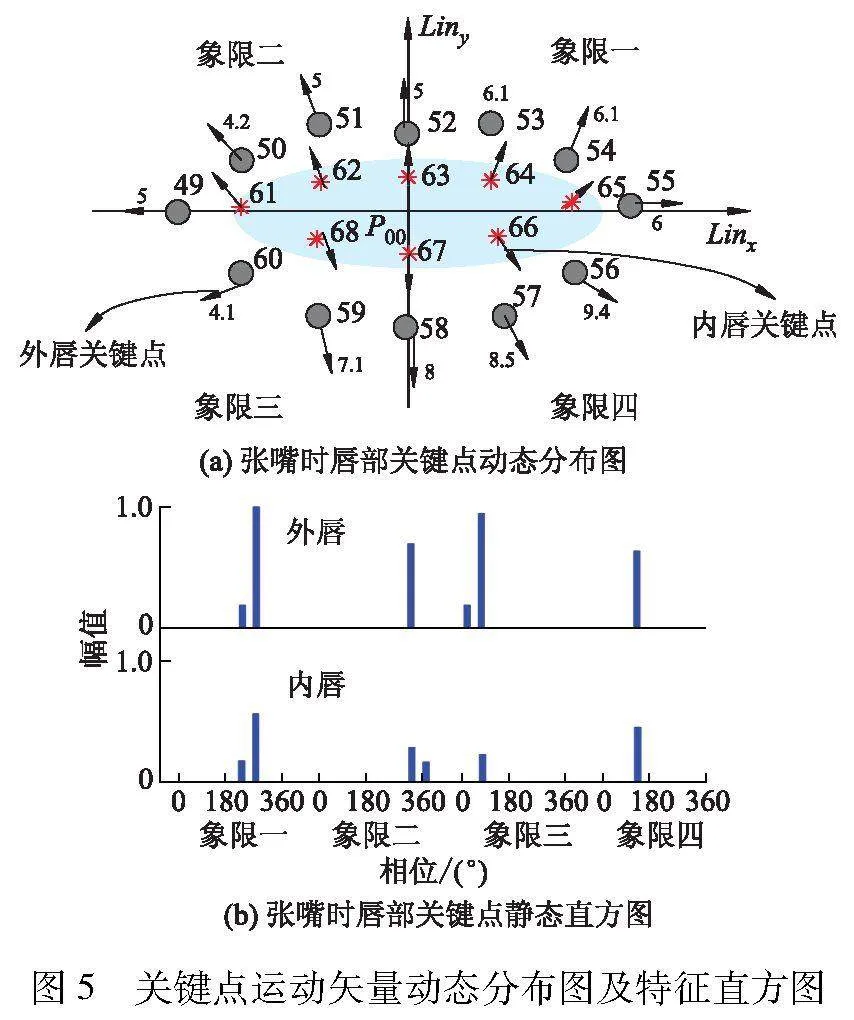
为了消除面部的运动及其方向变化对唇部关键点坐标信息的影响,利用检测到的唇部关键点,构建“唇部区域相对极坐标系”过程如下:以关键点P52和P58的连线Liny方向,确定纵坐标方向;以关键点P49和P55的连线Linx方向,确定横坐标方向;交点P00作为原点,Linx作为极坐标系的正方向,建立唇部关键点相对极坐标系,如图3所示.其中,第i关键点极坐标记作Qi(θi,ρi).为准确描述驾驶员说话时唇部关键点之间的位置信息变化,文中创新性地提出了关键点短时特征直方图描述算子,该算子能够高效捕捉唇部动态特征,其包括两部分:静态特征直方图、动态特征直方图.关键点静态特征直方图提取过程如图4所示.
静态特征直方图提取过程如下:首先,按Linx和Liny方向把极坐标系分为4个象限,并将唇部关键点分为内唇轮廓关键点和外唇轮廓关键点两种,分别统计外唇关键点、内唇关键点在4个象限内的“幅值-相位”直方图,然后将其连接成为一个整体直方图;其次,相位按照45°为间隔将0°-360°分割为8个bin区间;最后,对其进行量纲一化处理.具体求解公式如下:
H={Hin,Hout},(1)
Hout={h1out,h2out,h3out,h4out},(2)
Hin={h1in,h2in,h3in,h4in},(3)
式中: H是静态直方图;Hin是内唇关键点静态直方图;Hout是外唇关键点静态直方图;hiin是第i个象限的内唇关键点静态直方图分量;k为关键点的索引值;ρ(k)是幅值;θ(k)是相位;式(5)代表第i象限第j个bin区间的直方图分量计算公式.图5给出了关键点运动矢量动态分布图及特征直方图.
动态直方图提取过程建立在关键点的运动矢量基础上,运动矢量定义为相同关键点在相邻两帧图像上的极坐标矢量差.关键点动态直方图求解公式如下:
式中:L是动态直方图;Lin是内唇关键点动态直方图;Lout是外唇关键点动态直方图;liin是第i象限的内唇关键点动态直方图分量;Δρ(k)是幅值;Δθ(k) 是相位角.
利用LSTM对唇部轮廓关键点特征直方图的状态变化规律进行数学描述,采用步长为2的LSTM状态模块建模,模型定义如下:
式中: fikey是第i个LSTM模块的输入;hikey是第i个LSTM模块的状态输出;yikey是第i个LSTM模块的输出.关键点特征短时变化规律LSTM模型输出为
1.2.2 唇部短时外观特征提取网络模块
利用唇部区域图像提取唇部外观特征.如图2左下所示,首先利用LeNet-5网络提取t帧特征和t+1帧的图像外观特征.相邻两帧图像的短时外观特征的变化规律采用步长为2的LSTM状态模块进行建模.LSTM状态模块数学模型定义如下:
式中: ficnn是第i个LSTM模块的输入;hicnn是第i个LSTM模块的输出;yicnn是第i个LSTM状态模块的输出.因此,外观特征短时变化LSTM模型的输出为
1.2.3 唇部状态识别模块
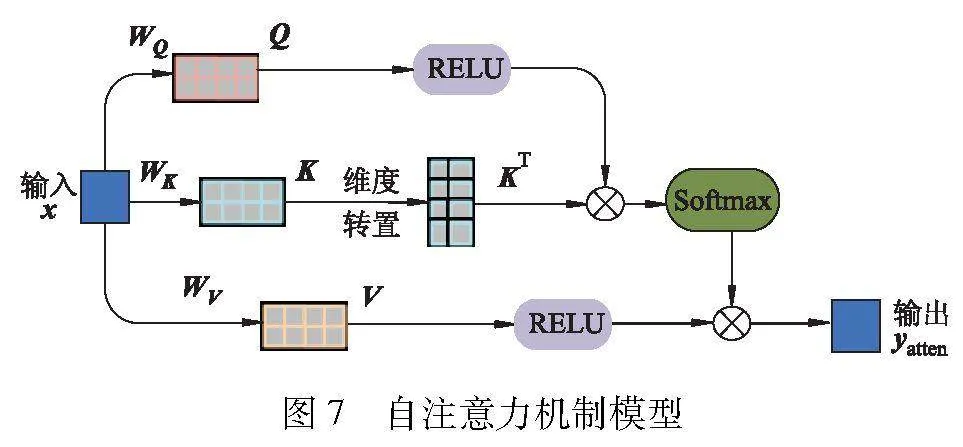
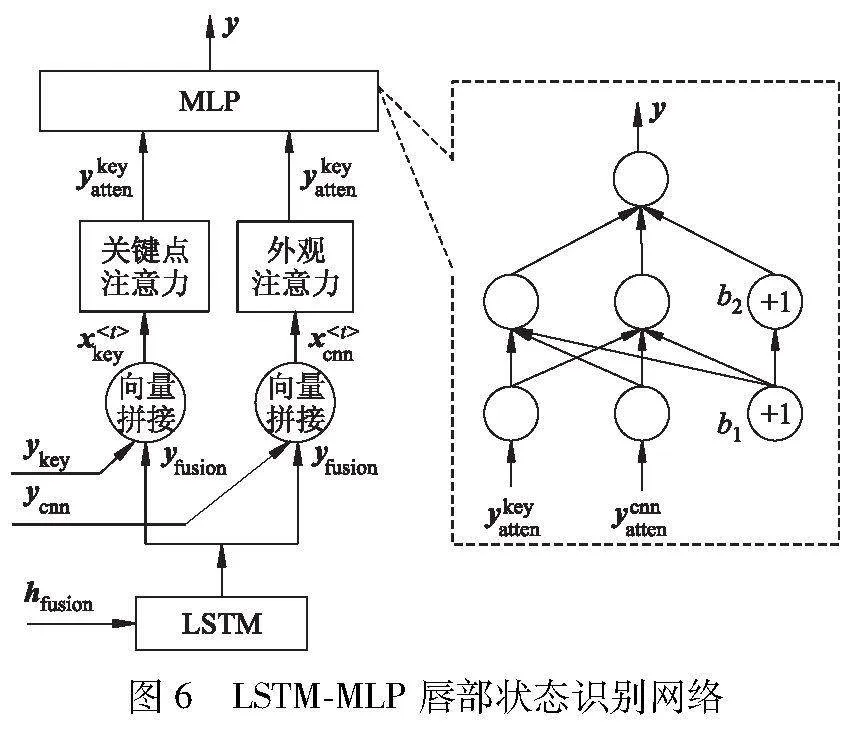
采用LSTM-MLP网络实现上述两种特征的融合,网络之间利用双注意力模型[10-11]调节不同通道的权重,最后通过MLP[12]输出唇部状态识别结果,网络结构如图6所示.
图7给出了自注意力机制模型.
设置权重矩阵分别为WQ、WK、WV, 则经过自注意力模型后,实现注意力权重向量分配,表达式为
经过自注意力模型优化后的输出特征向量:ykeyatten是关键点注意力模型的输出;ycnnatten是外观注意力模型的输出.最后,采用一个3层网络结构的MLP(单隐含层,输入层和隐含层)输出唇部状态识别结果y,计算式为
1.3 视觉、声音信号匹配
采用上述多模态特征识别网络对驾驶员唇部状态进行识别,确定驾驶员说话的时间窗,对相应的声波进行剪裁.为获取实时准确视觉-声音信号的匹配效果,采用双线程信号采集和处理过程,如图8所示.
由于语音信号采集频率高于视觉识别的结果更新的频率.因此,在语音信号采集线程中,始终扫描检测全局标志位变量的值,根据标志位的数值实时控制声音信号开启、关闭的命令,如表1所示.
2 试验结果与分析
2.1 试验环境与数据
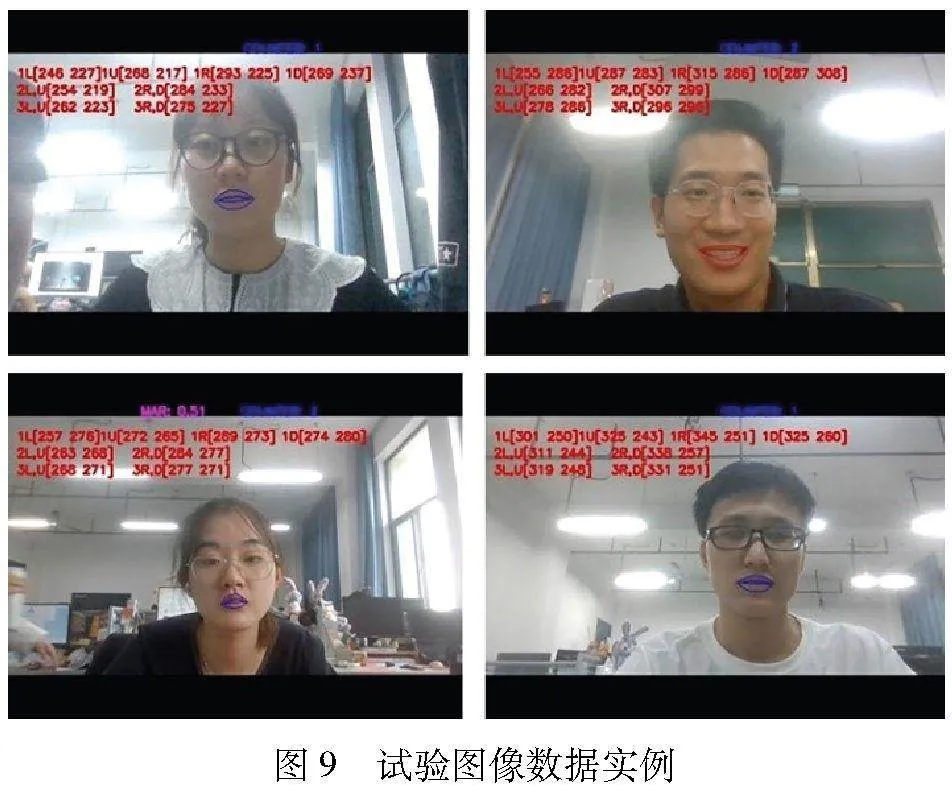
试验服务器硬件与软件环境如下:CPU为AMD Ryzen Threadripper 1950X 16-Core;GPU为NVIDIA GeForce GTX1080Ti;内存为64 GB;显卡为Cuda9.2;软件为python3.5.4、PyCharm2019.3.3、Tensorflow1.2.0深度学习框架.收集30位实验室不同学生的自然状态说话视频数据.经过采样、标注,共获得30 000幅图像序列,每人1 000张.其中,70%作为训练数据、其余30%作为测试数据.图9随机给出了4名学生的试验数据.
2.2 关键点短时特征直方图有效性试验
基于唇部关键点的特征可以有效地表征唇部状态[13].然而,无论是直接利用每帧的关键点坐标作为特征[14],还是利用关键点之间的距离比例作为状态特征,均属单帧的“静态特征”.静态特征无法对于唇部状态间的变化规律进行准确的描述.
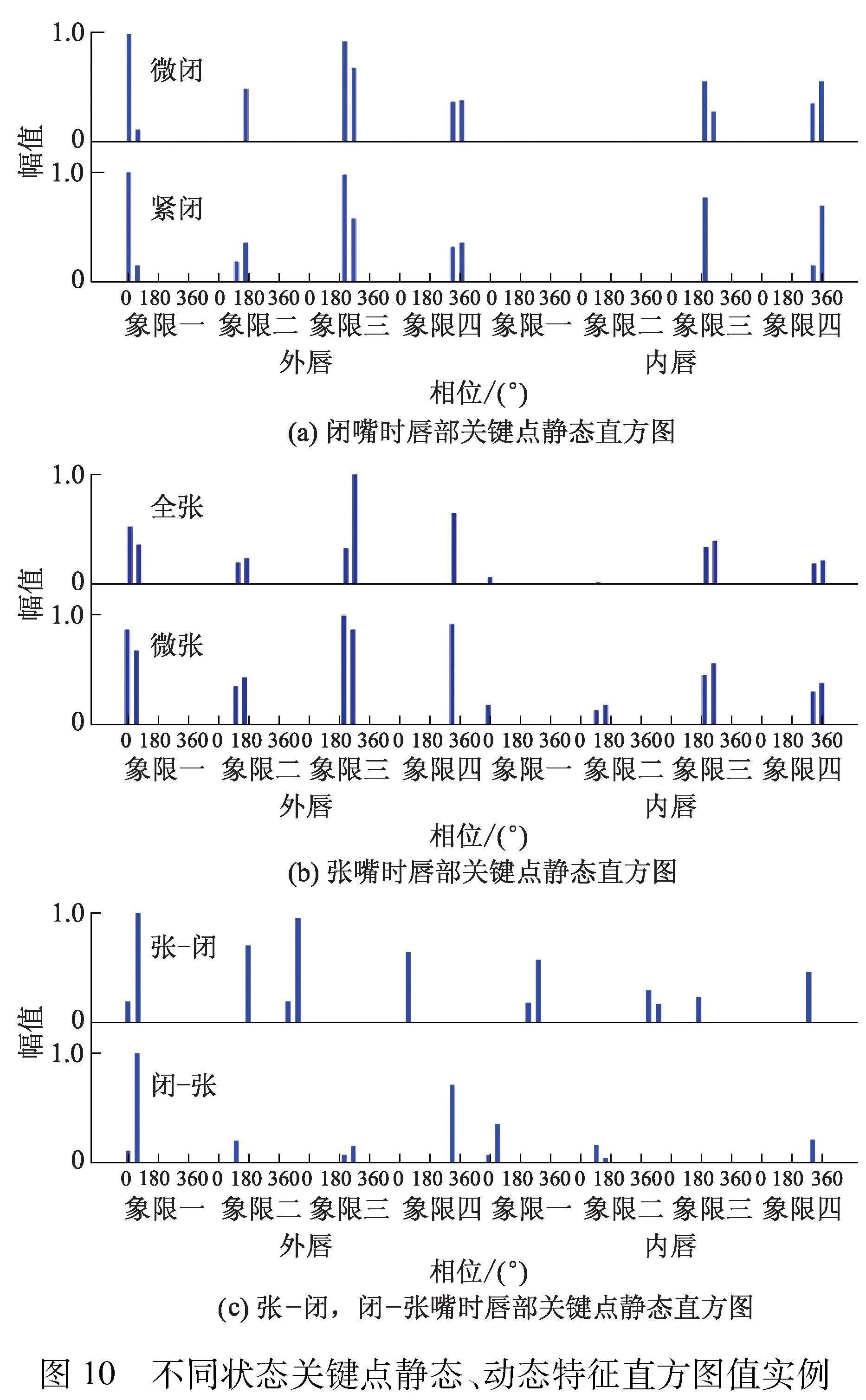
区别于传统方法,文中提出的关键点短时特征直方图算子包括描述每帧唇部轮廓形状的静态特征直方图、描述帧间唇部轮廓变化的动态特征直方图.基于帧间运动矢量的动态特征直方图可以有效增强唇部状态变化规律的描述能力.图10给出了关键点静态、动态特征直方图值实例.
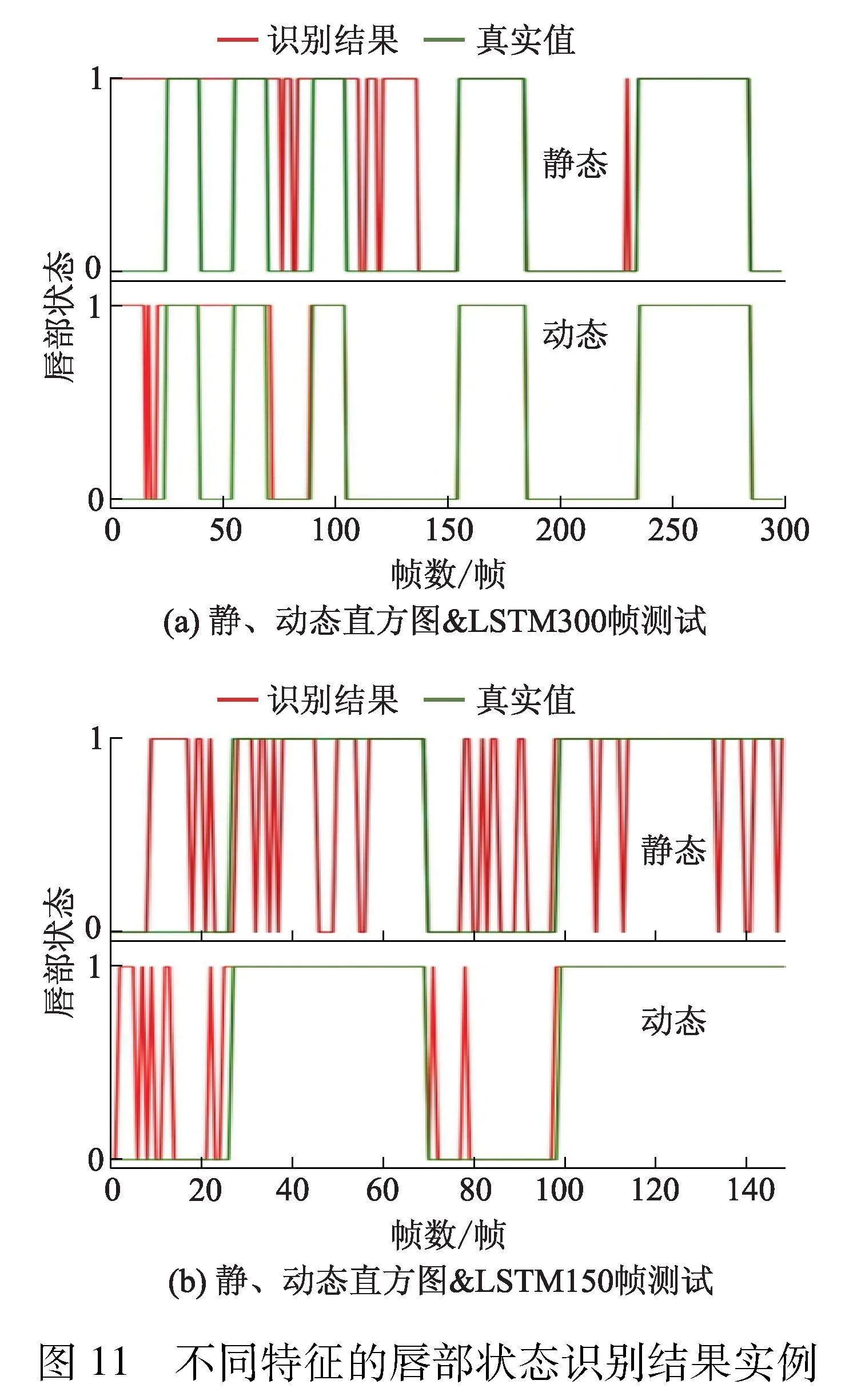
图10b是一组随机选取的张嘴状态关键点静态特征直方图,其中嘴部张开、闭合的幅度、唇部轮廓均略有差异.从图10a、10b可见,不同时刻、不同幅度的张嘴、闭嘴单帧图像对应的静态直方图分布表现较为相似、差异不大.这说明单帧静态特征直方图对于唇部状态变化规律的识别能力不强.相反,从图10c可见,嘴部张-闭、闭-张帧间图像对应的动态特征直方图分布差异明显,可见动态直方图对于唇部的短时变化规律的表征能力较强.
图11给出了两组测试数据(300、150帧)分别以静态、动态直方图作为特征时的唇部状态识别结果实例.其中纵坐标取值1代表说话,取值0代表非说话.
表2给出了对比试验结果.
由表2可见,动态直方图可提供有效增强唇部状态变化规律描述能力14%以上.
2.3 多模态唇部状态识别消融试验
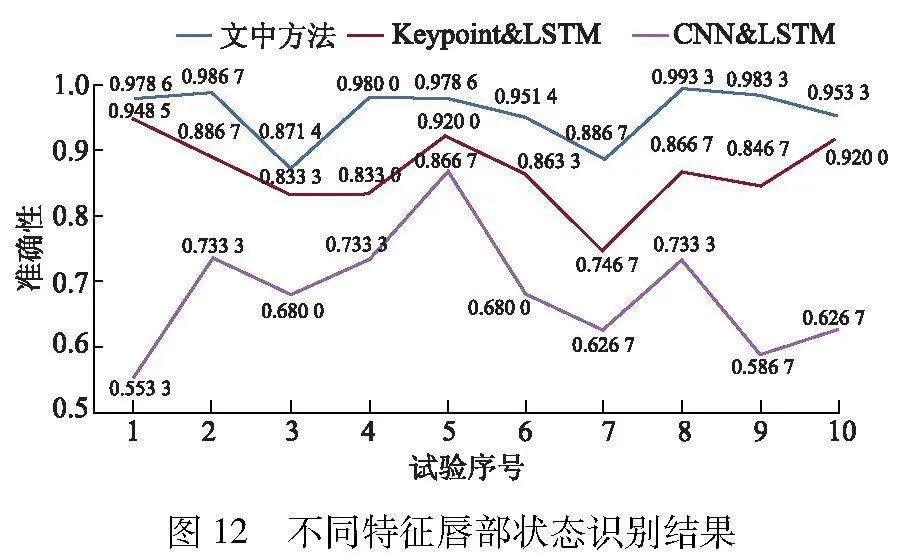
为验证文中“关键点-外观”多模态特征融合的唇部识别网络有效性,随机10次按照70%训练、30%测试的比例抽取部分试验数据,训练和测试3种唇部状态识别网络模型,包括外观特征(CNN)amp; LSTM、关键点(Keypoint)amp; LSTM和文中多模态特征识别网络.图12给出了上述3种方法10次识别结果的准确性曲线图.由图12可见,Keypoint amp; LSTM方法的准确性明显优于CNN amp; LSTM方法,这说明基于关键点的特征对于唇部状态的表征能力优于基于CNN的外观特征;而文中多模态特征融合的唇部状态识别网络准确性优于单模态特征的识别网络.可见,文中方法可有效地融合关键点和外观特征,显著提高准确性.此外,通过比较3条曲线的振荡幅度变化程度可知,蓝色虚线的振荡幅度明显小于其他两种曲线,这说明通过多模态特征的融合,可实现特征优势互补,提高唇部状态识别的鲁棒性.
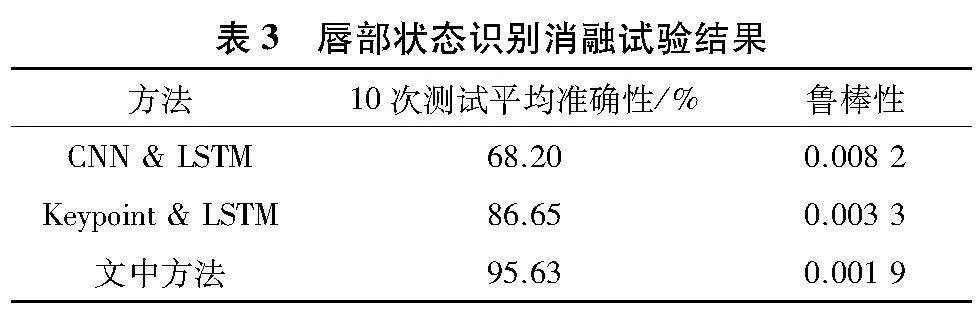
表3给出了图11中3种方法对应10次测试平均准确性和鲁棒性的量化对比结果.其中,利用10次准确性的方差值作为该方法的鲁棒性指标.曲线振荡幅度越大说明算法鲁棒性越低,曲线振荡幅度越小说明算法鲁棒性越高.
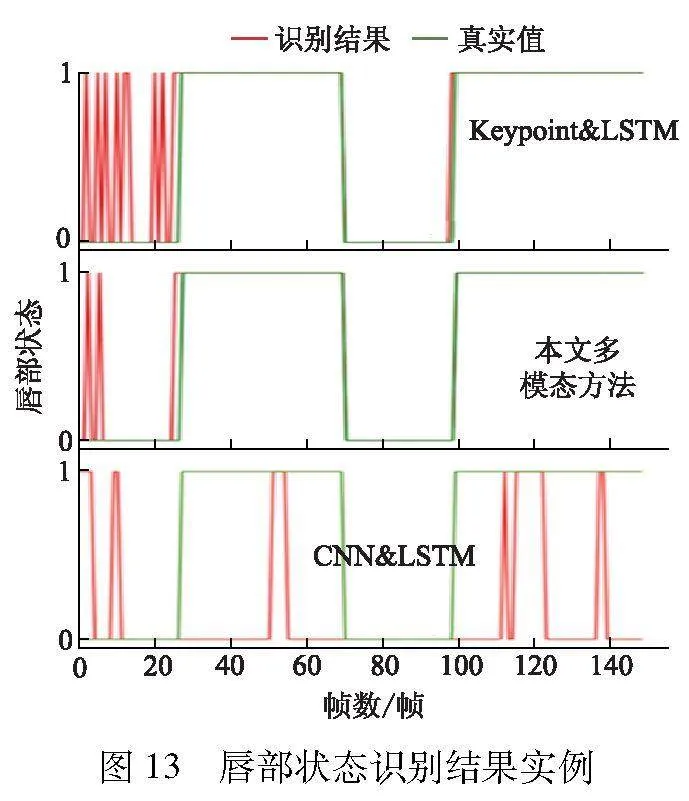
由表3可见,文中方法平均准确性为95.63%、鲁棒性为0.001 9,识别性能显著优于其他两种基于单模态特征的识别方法,提升识别准确性8.98%以上.图13给出了随机选取说话状态150帧的视频识别结果实例.
由图13可见,Keypoint amp; LSTM模型错误识别集中在非说话状态,CNN amp; LSTM模型的误检多发生在说话状态.这说明Keypoint amp; LSTM模型的说话状态识别准确性较好,对于说话状态的识别能力优于CNN amp; LSTM模型.相反,CNN amp; LSTM模型的非说话状态识别准确性较好,对于非说话状态的识别能力优于Keypoint amp; LSTM模型.而文中提出的多模态识别网络可以有效结合关键点特征(Keypoint)和外观特征(CNN)两种特征的表征优势,实现优势互补,显著提高唇部状态识别的准确性.
2.4 唇部状态识别比较试验
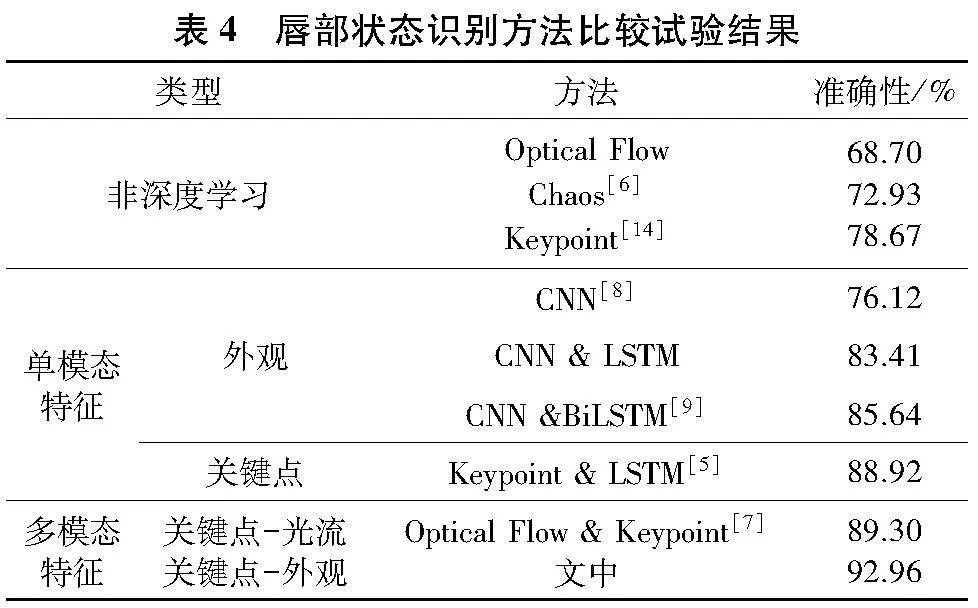
为验证文中方法有效性,选取如下8种方法作为比较对象,包括Optical Flow、Chaos[6]、Keypoint[14]、CNN[8]、CNN amp; LSTM、CNN amp; BiLSTM[9]、Keypoint amp; LSTM[5] 、Optical Flow amp; Keypoint[7].表4给出了上述8种方法在文中测试数据上的比较试验结果.
由表4可见,基于深度学习的唇部状态识别方法总体准确性优于传统统计学方法,包括Optical Flow、Chaos[6]、Keypoint[14].而在深度学习模型中,单一CNN模型的准确性最低,仅有76.12%.LSTM系列模型的准确性明显高于CNN模型.这说明LSTM模型对于唇部状态序列随时间变化的内在规律具有较好的建模能力.此外,Keypoint amp; LSTM[5]的准确性88.92%,优于CNN amp; LSTM、CNN amp; BiLSTM[9].这说明唇部轮廓关键点特征(Keypoint)对于嘴部开、合的判定更有效;相反,CNN提取的唇部区域外观特征易受到肤色、光照因素影响.
文中利用关键点静态特征直方图描述单帧图像嘴部开、合状态;利用动态矢量直方图描述帧间唇部状态变化规律.同时,利用LSTM融合两种不同特性的特征,融合模型的准确性达92.96%,明显优于其他单模态特征模型,有效实现了特征优势互补.
2.5 实验室模拟环境语音导航抗干扰试验
图14给出了基于唇部状态检测的语音导航仿真系统在实验室模拟环境的试验结果实例.由图14a可见,仿真系统在驾驶员面部较大的转动范围内均能够有效地剪切出其说话时间段的声音信号.由图14b可见,驾驶员输入声音波形成一条直线,环境声音波形剧烈振荡,这说明系统可以有效地减少环境噪声对于语音导航系统的干扰.通过定量评价实验结果表明,该仿真系统的准确性达92.6%、平均计算速度35帧/s,且在驾驶员面部水平方向超过70°的转动后仍能保证系统的鲁棒性.
2.6 车载环境语音导航抗干扰试验
图15给出了车载环境下,语音导航抗干扰系统的试验结果.
由图15a可见,系统能够在面部转动较大的范围内准确地检测驾驶员的说话状态,进而剪切驾驶员说话的语音信号作为语音导航系统的输入.这说明文中的唇部关键点匹配方法和多模态唇部状态识别网络在驾驶员面部发生较大转动时的鲁棒性较高、适应能力较强.由图15b可见,车内驾驶员不说话、后排乘客说话时,视觉识别驾驶员唇部状态为“非说话状态”,车载语音导航系统的语音输入开关关闭.因此,驾驶员声音波形显示为一条直线,声波幅值在时间轴不发生变化.同时,乘客声音引起车内环境声音波形振荡、声波幅值在时间轴上的连续变化.车内噪声被完全屏蔽.这说明本系统能够准确地通过驾驶员唇部状态的识别控制车载导航系统的语音输入开关,有效减少车内、外环境噪声对于车载语音导航输入的干扰,增强驾驶员对于车载导航系统的语音控制权限.
3 结 论
为减少噪声引起的车载语音导航系统的干扰、增强驾驶员对车载语音导航系统的控制权限,文中提出了一种基于唇部关键点特征与唇部外观特征相融合的多模态唇部状态识别网络.采用极坐标系下的唇部轮廓关键点静态直方图描述嘴部开、合的状态,利用关键点动态矢量直方图增强对于小口型、闭嘴音的识别;通过唇部轮廓关键点特征与CNN卷积外观特征的融合减少不同人唇部、口腔肤色差异、光照变化对于说话状态识别的影响.试验结果表明,多模态唇部状态识别网络可以有效实现不同模态特征的优势互补,显著增强唇部状态的识别准确性与鲁棒性.车载实验室验证了基于视觉检测的车载语音抗干扰系统能够有效协助驾驶员掌控车载语音导航系统的话语输入权限,显著降低车内外噪声所带来的干扰,从而提升了驾驶安全与语音交互的准确性.系统凭借其出色的性能,具有良好的市场推广前景.
参考文献(References)
[1] 辜声峰,戴春齐,何成鹏, 等.面向城市车载导航的多系统PPP-RTK/VIO半紧组合算法性能分析[J].武汉大学学报·信息科学版, 2021,46(12):1852-1861.
GU S F, DAI C Q, HE C P, et al. Analysis of semi-tightly coupled muli-GNSS PPP-RTK/VIO for vehicle navigation in urban areas[J]. Geomatics and Information Science of Wuhan University, 2021,46(12):1852-1861.(in Chinese)
[2] 姜囡,庞永恒,高爽.基于注意力机制语谱图特征提取的语音识别[J].吉林大学学报(理学版),2024,62(2):320-330.
JIANG N, PANG Y H, GAO S. Speech recognition based on attention mechanism and spectrogram feature extraction[J]. Journal of Jilin University (Science Edition), 2024,62(2):320-330.(in Chinese)
[3] BI L, CAO J, LI G H, et al. SpeakNav: a voice-based navigation system via route description language understanding[C]∥Proceedings of the 2021 37th IEEE International Conference on Data Engineering. Piscataway:IEEE Computer Society, 2021:2669-2672.
[4] LIN B S, YAO Y H, LIU C F, et al. Development of novel lip-reading recognition algorithm [J].IEEE Access, 2017,5:794-801.
[5] 马宁,田国栋,周曦.一种基于long short-term memory的唇语识别方法[J].中国科学院大学学报, 2018,35(1):109-117.
MA N, TIAN G D, ZHOU X. A lip-reading recognition approach based on long short-term memory[J]. Journal of University of Chinese Academy of Sciences, 2018,35(1):109-117.(in Chinese)
[6] SONG T, LEE K, KO H S. Visual voice activity detection via chaos based lip motion measure robust under illumination changes[J]. IEEE Transactions on Consumer Electronics, 2014,60(2):251-257.
[7] 王晔,王峰,贾海蓉,等. 结合人脸关键点与光流特征的微表情识别[J]. 激光杂志, 2023,44(5):72-77.
WANG Y, WANG F, JIA H R, et al. Micro-expression recognition combining facial key points and optical flow features[J]. Laser Journal, 2023,44(5):72-77.(in Chinese)
[8] 闫捷. 基于深度学习的唇语识别方法研究[D].北京:北方工业大学,2019.
[9] SUN Q N, JANKOVIC M V, BALLY L, et al. Predicting blood glucose with an LSTM and bi-LSTM based deep neural network[C]∥Proceedings of the 2018 14th Symposium on Neural Networks and Applications. DOI: 10.1109/NEUREL.2018.8586990.
[10] PAN X R, GE C J, LU R, et al. On the integration of self-attention and convolution[C]∥Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Computer Society,2022:805-815.
[11] ZHANG H, WU C R, ZHANG Z Y, et al. ResNeSt: split-attention networks[C]∥Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway:IEEE Computer Society, 2022:2735-2745.
[12] GUO J Y, TANG Y H, HAN K, et al. Hire-MLP: vision MLP via hierarchical rearrangement [C]∥Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Computer Society,2022:816-826.
[13] NANDAKISHOR S, PATI D. Extraction of lip contour and geometric lip features for audio-visual phoneme re-cognizer[J]. International Journal of Computer Science amp; Programming Languages, 2020,6(1):25-33.
[14] RONG P, YUNUSOVA Y, RICHBURG B, et al. Automatic extraction of abnormal lip movement features from the alternating motion rate task in amyotrophic lateral sclerosis[J]. International Journal of Speech-Language Pathology, 2018,20(6):610-623.
