一种基于知识蒸馏的边缘联邦学习算法
2025-01-01石玲何常乐常宝方王亚丽袁培燕




摘要: 针对边缘计算环境中参与联邦学习的客户端数据资源的有限性,同时局限于使用硬标签知识训练模型的边缘联邦学习算法难以进一步提高模型精度的问题,提出了基于知识蒸馏的边缘联邦学习算法。利用知识蒸馏对软标签信息的提取能够有效提升模型性能的特点,将知识蒸馏技术引入联邦学习的模型训练中。在每一轮的联邦学习模型训练过程中,客户端将模型参数和样本逻辑值一起上传到边缘服务器,服务器端聚合生成全局模型和全局软标签,并一起发送给客户端进行下一轮的学习,使得客户端在进行本地训练时也能够得到全局软标签知识的指导。同时在模型训练中对利用软标签知识和硬标签知识的占比设计了动态调整机制,使得在联邦学习中能够较为合理地利用两者的知识指导模型训练,实验结果验证了提出的基于知识蒸馏的边缘联邦学习算法能够有效地提升模型的精度。
关键词: 边缘计算; 知识蒸馏; 客户端; 软标签; 硬标签
中图分类号: TP391.1
文献标志码: A
文章编号: 1671-6841(2025)02-0044-07
DOI: 10.13705/j.issn.1671-6841.2023158
An Edge Federated Learning Algorithm Based on Knowledge Distillation
SHI Ling1,2, HE Changle1,2, CHANG Baofang1,2, WANG Yali1,2, YUAN Peiyan1,2
(1.College of Computer and Information Engineering, Henan Normal University, Xinxiang 453007, China;
2.Engineering Laboratory of Intellectual Business and Internet of Things Technologies, Xinxiang 453007, China)
Abstract: In view of the clients′ limited data resources involved in federated learning in edge computing environment, and the problem that it was difficult to further improve the accuracy of edge federated learning algorithm which used hard label knowledge to train the model, an edge federated learning algorithm based on knowledge distillation was proposed. The extraction of soft label information by knowledge distillation could effectively improve the performance of the model, so the knowledge distillation technology was introduced into the model training of federated learning. In each round of federated learning model training process, the client uploaded the model parameters and samples logic values to the edge server, and the server generated the global model and global soft label together and sent them to the client for the next round of learning, so that the client could also get the guidance of global soft label knowledge during local training. At the same time, a dynamic adjustment mechanism was designed for the proportion of soft label knowledge and hard label knowledge in model training, so that the knowledge of both could be reasonably used to guide model training in federated learning. The experimental results verified that the proposed edge federated learning algorithm based on knowledge distillation could effectively improve the accuracy of the model.
Key words: edge computing; knowledge distillation; client; soft label; hard label
0 引言
机器学习发展十分迅速,在很多方面都取得了较好的效果[1-2]。但是近年来,互联网用户对数据隐私安全越来越重视,不同组织机构出于种种原因不愿意共享数据,导致数据碎片化、孤岛化等相关问题,严重阻碍了人工智能进一步发展,因而能够解决这些问题的联邦学习技术应运而生[3]。联邦学习只需要用户使用私有数据训练本地模型,然后通过聚合服务器接收来自各个用户的模型参数来更新全局模型,从而协作训练出性能更优的全局模型。联邦学习由于其独特的模型训练过程,在最近几年引起相关研究人员广泛的关注[4]。
在联邦学习的模型聚合阶段进行相关优化是提高联邦学习效率的一种常用方案[5-6]。文献[7]在联邦学习的客户端本地训练结束后,全局模型采用异步聚合的方式,客户端无需额外的等待时间直接上传本地模型,减少了时间消耗。文献[8]提出了基于最新系统状态自适应选择最优全局聚合频率的控制算法,这是一种云-边-端协同的架构,能有效减少联邦学习过程的能耗。在联邦学习中客户端训练的本地模型对全局模型的性能起到决定性的作用,因而文献[9]通过排除联邦学习中一些不相关的本地模型,减少了其对全局模型聚合的影响,能够有效地提升全局模型的最终精度。在联邦学习过程中,对目标函数重新加权,可以为损失较大的客户端分配较高的权重,这在一定程度上增加了权重分配的公平合理性,文献[10]采用此种方式,提升了联邦学习的模型性能。联邦学习中客户端本地模型训练的更新速度不同,文献[11]根据聚合服务器上接收到的本地模型参数,依据其时效性采取了一种更加合理的自适应加权聚合的方式,使模型精度有了进一步的提升。
联邦学习虽然具有保护用户数据隐私以及解决数据孤岛等问题的优点,但与集中式机器学习训练的模型相比,在精度上有一定差距[12]。移动边缘计算中有很多方法能有效缓解网络拥塞,更好地进行联邦学习[13-14]。但当面对边缘计算环境时,客户端上的数据会由于不同用户的使用习惯以及兴趣爱好等,呈现出不平衡的非独立同分布的状态,使本就采用分布式学习的联邦学习在精度上进一步下降[15-17]。当下提升联邦学习的性能是研究在边缘计算环境部署联邦学习的当务之急。
在边缘计算环境中,客户端拥有的本地数据资源都是有限的,机器学习模型的性能也取决于能够参与训练的数据量,在不能获取更多数据资源的时候,可以考虑对现有模型资源的充分利用。知识蒸馏能够实现对现有模型资源的重复充分利用,将模型中的软标签知识蒸馏出来,并用于指导模型进行新的训练,以此提升模型的性能。本文主要研究基于知识蒸馏的边缘联邦学习,主要贡献包括两个方面:1) 提出了基于知识蒸馏的边缘联邦学习算法,利用知识蒸馏能从软标签中获取知识的特点,提升边缘联邦学习模型的性能。2) 设计了客户端分组参与联邦学习的模型训练方式,同时依据联邦学习训练阶段对知识蒸馏过程中硬标签的损失与软标签的损失在总损失中的比例设计了一个动态调整机制,提升了模型训练的效率。
1 基于知识蒸馏的边缘联邦学习算法
1.1 基于知识蒸馏的边缘联邦学习
在联邦学习中,客户端利用从聚合服务器下载的全局模型以及本地数据集训练本地模型。假设有K个客户端参与联邦学习,每个客户端都有本地数据集(xk,yk),客户端的模型参数为ω(k),则每个客户端损失函数定义为fk(ω)=l(ω;xk,yk),在学习率η下,本地模型采用梯度下降法进行训练,Δfk(ω(k))表示客户端k的模型ω(k)的梯度,则训练过程可表示为ω(k)=ω(k)-ηΔ
fk(ω(k)),然后,服务器根据客户端数据量对接收到的参数进行加权平均,则在第r轮通信中全局模型参数为ωr=DkD∑Kkω(k)r,其中:D为数据样本总量;Dk为第k个客户端的本地数据大小。
尽管通过对客户端进行选择可以有效地提升模型性能,但是边缘联邦学习采用的是基于样本硬标签的训练方式,知识映射到模型的渠道单一、效率不高,这些因素阻碍着联邦学习模型性能的进一步提升。而知识蒸馏技术在模型训练中引入软标签知识来增加模型的知识,提高了模型在训练中获取知识的效率,从而达到提升模型准确率的目的。
知识蒸馏的训练结构采用的是教师-学生(teacher-student, T-S)结构,简单来说就是学生模型可以通过蒸馏获取到教师模型的知识,神经网络中输出层产生的类概率可以表示为Φi(zi)=exp(zi)/∑jexp(zj),其中:zi是第i类逻辑单元值;Φi(zi)是第i类概率。
当使用类概率表示知识时,类概率层的负标签信息就是软目标知识,而数据标签则称为硬目标知识。在神经网络的训练过程中负标签会被Softmax函数压扁接近于零,因此会使软目标知识的部分信息丢失。为了达到对软标签知识的利用,设温度系数为T,控制输出概率的软化程度,则
Φi(zi,T)=exp(zi/T)/∑jexp(zi/T)。
在教师-学生结构模型中,知识蒸馏(knowledge distillation)损失定义为LKD(Φ(tea,T),p(stu,T))=∑i(-Φi(teai,T)log(Φi(stui,T))),
其中:LKD表示知识蒸馏损失;stu和tea分别是学生模型和教师模型输出的逻辑单元。
若用y表示硬标签向量,则学生模型的损失可以定义为
Lstu(y,p(stu,T))=∑i(-yilog(Φi(stui,T)))。
所以对知识蒸馏的总损失可以定义为Ltotal=λ·LKD+(1-λ)·Lstu,其中λ是超参数。
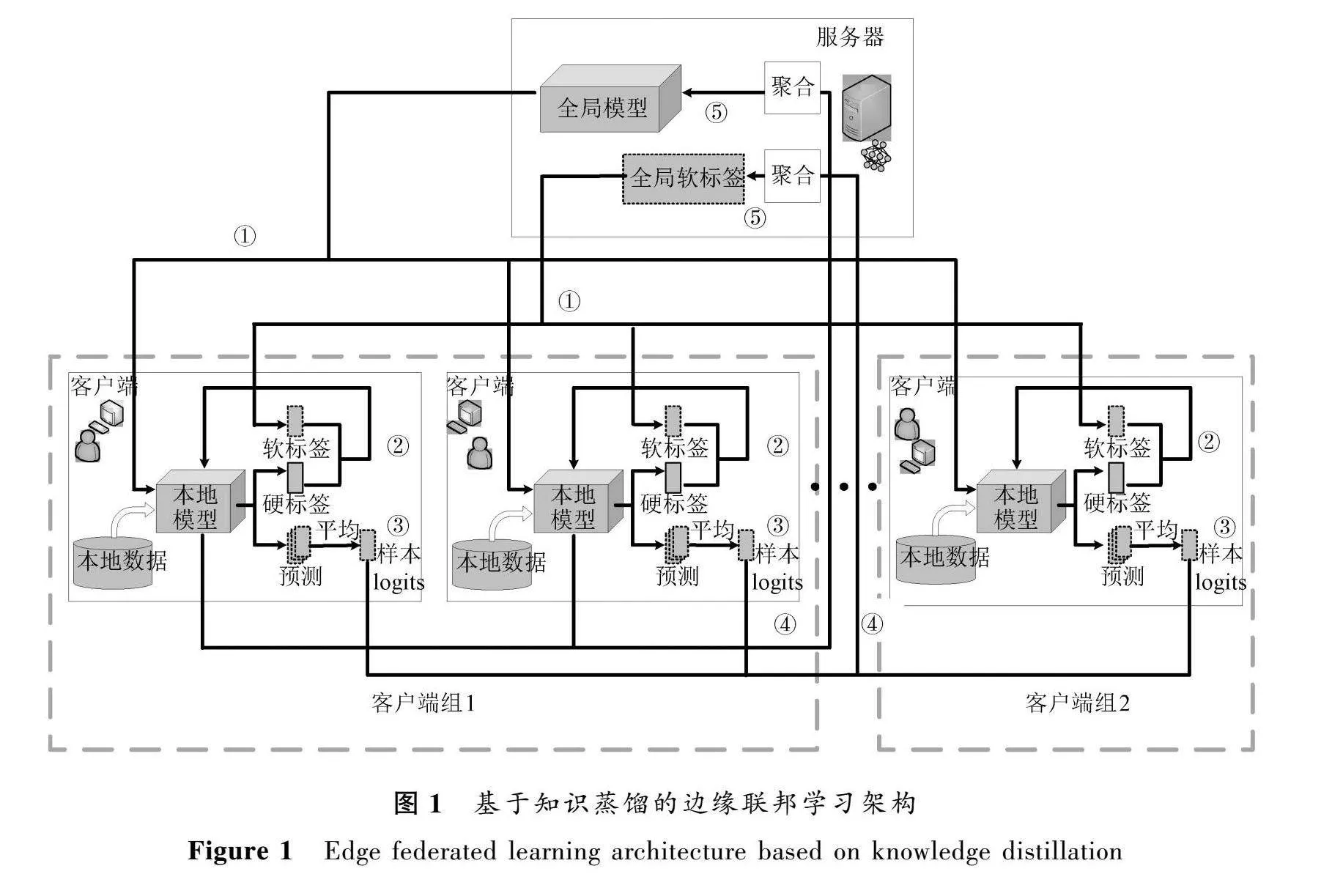
如图1所示,本文把参与联邦学习的客户端分为组1和组2,按响应时间先选取出组1的客户端,并保证其性能,从而为整体的联邦学习效率奠定基础。接着从剩余客户端中随机选取与组1相同数量的客户端构成组2。组1中的客户端是联邦学习的主要参与者,对模型的最终性能起主导作用,在本地训练结束时,需要上传本地模型参数以及样本logits。组1中的客户端进行同步训练,即在每一个学习轮次中,边缘服务器只有在接收到组1所有更新的本地模型参数和样本logits之后,才会进行聚合操作[18]。组2的客户端作为辅助参与者,采用的是异步训练方式,在本地训练结束时,只需要上传样本logits。虽然边缘计算环境下客户端的资源状态是动态的,但总体而言,组2中客户端的质量低于组1,所以在组1中的客户端全部完成本地训练时,组2中的客户端可能只有部分完成本地训练,在本文方法中,联邦学习每轮训练的截止时间以组1中所有客户端上传完本地参数和样本logits为准。到达截止时间时,边缘服务器聚合当前所接收的来自组2上传的样本logits。组2中客户端的参与,使得全局软标签涉及的范围更广,有效提高了整体的训练效率。服务器对全局模型的聚合为
ωr+1=∑Kk=1(
Dk×ω(k)r+1)/∑Kk=1Dk,
其中:K表示组1中客户端的数量;ω(k)r+1表示设备k在完成第r轮本地训练后上传的模型参数;Dk表示第k个客户端本地数据集的大小。服务器端全局软标签的聚合为
yr+1=∑Kk=1(Dk×ykr+1)/(∑Kk=1Dk)+Δy+1,
其中:ykr+1表示在组1中,客户端k在完成第r轮本地训练后上传的样本logits的平均值;Δy+1表示在第r轮结束时来自组2中的客户端生成的局部软标签梯度,用以对全局软标签信息的补充修正。
在组2中,假设时间阈值Te截止时,在第r-1轮接收到m个客户端上传的样本logits,在第r轮接收到n个客户端上传的样本logits,则
Δy+1=∑mk=1Dk×ykr
∑mk=1Dk-
∑nk=1Dk×ykr+1∑nk=1Dk。
客户端使用梯度下降法更新权重并生成样本logits,所用公式为ω(k)r+1=ω(k)r-ηgk,其中:η是本地模型训练的学习率;gk=Δfk(ω(k))表示当前模型参数ω(k)的梯度。若客户端k在第r轮本地训练中产生了D个样本logits,则最终把样本logits的平均值ykr+1上传到边缘服务器,其中ykr+1=∑Di=1yki/D。
本文所提算法模型训练的基本思想是使预测模型既要逼近硬标签,也要逼近相应的软标签,则参与联邦学习的客户端的本地训练中损失函数为L(ω)=λF(Ylab,y)+(1-λ)GKL(Ysf‖y),其中:y表示模型预测;λ是超参数,且λ∈(0,1);Ysf为软标签;Ylab为硬标签;F(Ylab,y)表示交叉熵损失函数;GKL(Ysf‖y)为KL散度损失函数,若客户端k的本地数据集的数量为nk,则
F(Ylab,y)=-∑nki=1Ylablogexp(yi)∑jexp(yj),
GKL(Ysf‖y)=-∑nki=1Ysflogexp(yi)∑jexp(Yjsf)exp(Yisf)∑jexp(yj)。
因此本算法优化函数可定义为
minω{Φ(ω)∑Kk=1
pk(λFk(ω)+(1-λ)GkL(ω))},
其中:pk=Dk/(∑Kk=1Dk)。从优化函数中可以看出超参数
λ决定着知识蒸馏过程中硬标签的损失与软标签的损失在总损失中的比例。在模型训练的初始阶段以及前期阶段,软标签中蕴含的知识较少,硬标签的信息对模型性能提升占据绝对主导地位,在模型训练的后期,模型已充分利用了硬标签的知识信息后逐渐开始收敛,此时软标签知识的出现将进一步提升模型性能。基于上述考虑,为超参数λ设计一个模型训练前期取值较大,之后逐渐减小到最低阈值的动态取值方法,
λ=max(φ,(R-r)/R),(1)
其中:r是联邦学习当前的通信轮数;R是总通信轮数;φ是设定的最低比例阈值,用来保证联邦学习中必要比例的硬标签知识信息的输入。
1.2 算法实现
基于知识蒸馏的边缘联邦学习机制的每一轮次学习过程如下:① 边缘服务器选取当前轮次中参与联邦学习的客户端,并给这些客户端下发当前全局模型和当前全局软标签;② 客户端在本地数据集上利用从边缘服务器下载的当前全局软标签和全局模型采用知识蒸馏方式训练更新本地模型,同时也生成新的样本logits;③ 客户端将训练好的本地模型以及新生成的样本logits上传到边缘服务器端;④ 服务器对客户端模型参数以及样本logits分别进行聚合操作,从而更新全局模型和全局软标签,具体算法如下。
算法1 基于知识蒸馏的边缘联邦学习算法
输入:客户端总数N,每轮时间阈值Te,客户端批处理大小B,本地训练迭代轮数E,训练总轮数R,学习率η,最低比例阈值φ,控制参与联邦学习客户端数量的比例系数,客户端具有硬标签Ylab的数据集D={D1,D2,…,DN}。
输出:全局模型ωr+1,全局软标签yr+1。
选择客户端进程(client selection, CS)。
1) 客户端组1:Kset1←「N×依据客户端响应时间选取;
2) 客户端组2: Kset2←剩余客户端中随机选取数量等于Kset1的客户端。
服务器进程(server process, SP)。
1)K←客户端组1数量;
2) 初始化全局模型ω以及全局软标签y,并将其发送给选取的客户端;
3) for each round r=1, 2, … do
4) for 客户端 Ck∈K do
5) (ωkr+1,ykr+1)←ClientUpdate(ωr,yr)
6) end for
7) ωr+1=ωr+∑Kk=1(Dk×ωkr+1)/∑Kk=1Dk;
8) yr+1=∑Kk=1(Dk×ykr+1)/∑Kk=1Dk+Δy+1;
9)end for
客户端进程(worker process, WP)。
1)λ←maxφ,R-rR;
2) for epoch i in 1 to E do
3) for batch b in 1 to B do
4) L(ω)=λF(yω,Ylab)+(1-λ)GKL(yω,Ysf)
5) ωr=ω-ηΔL(ω)
6) end for
7) end for
8)yr←Prediction(ω,D)
9)return (ωr,yr)。
2 实验与结果分析
2.1 实验设置
为了评估本文提出的算法,分别在两种常见的数据集MNIST和CIFAR-10上进行实验,其中MNIST数据集为70 000张被标准化、像素大小为28×28的手写数字0~9构成的灰度图像,类别数为10,训练集和测试集分别包括60 000张和10 000张图像。CIFAR-10数据集为60 000张像素大小32×32的RGB图像,类别数为10,训练集和测试集分别包括50 000张和10 000张图像。在实验中模拟生成的客户端数量为100,同时考虑客户端数据独立同分布(independent and identically distributed, IID)和非独立同分布(non-independent and identically distributed, Non-IID)两种情形。在独立同分布的实验状态下,分别对MNIST和CIFAR-10的训练数据集进行均匀置乱操作,然后分配给每个客户端,实现对客户端数据集独立同分布的划分。在非独立同分布的实验状态下,分别对MNIST和CIFAR-10数据集按照标签进行排序,然后将这两个数据集分别以300个和250个样本划分为一个片区,共分成200个片区,最后为每个客户端分配两个不同类的片区,实现客户端在数据集上的非独立同分布。在实验中对MNIST数据集使用的模型有两个卷积层,卷积核都为3×3,输出通道均为8,填充和步长都为1,卷积层后均使用2×2的最大池化层,最后连接一个输入为392维、输出为10维的全连接层网络。对CIFAR-10数据集使用的模型有三个卷积层,卷积核都为5×5,输出通道分别为16、16和32,填充都为2,步长都为1,卷积层后均使用2×2的最大池化层,最后连接一个输入为512维、输出为10维的全连接层网络,本文算法在与其他联邦学习算法的对比实验中,最低比例阈值φ取值0.6。
本文提出的算法用Our algorithm表示,同时为了验证算法对模型性能的提升,选取了联邦学习领域中比较经典的FedAvg[18]和FedProx[19]算法做参照实验。FedKD是在FedAvg架构下单纯地将知识蒸馏技术与联邦学习结合,即在客户端增加了生成样本logits的操作,在服务器端增加了全局软标签聚合的操作,其与本文算法相比,没有设计动态取值超参数λ,并且没有对客户端采取分组差异性的全局聚合算法。
2.2 实验结果分析
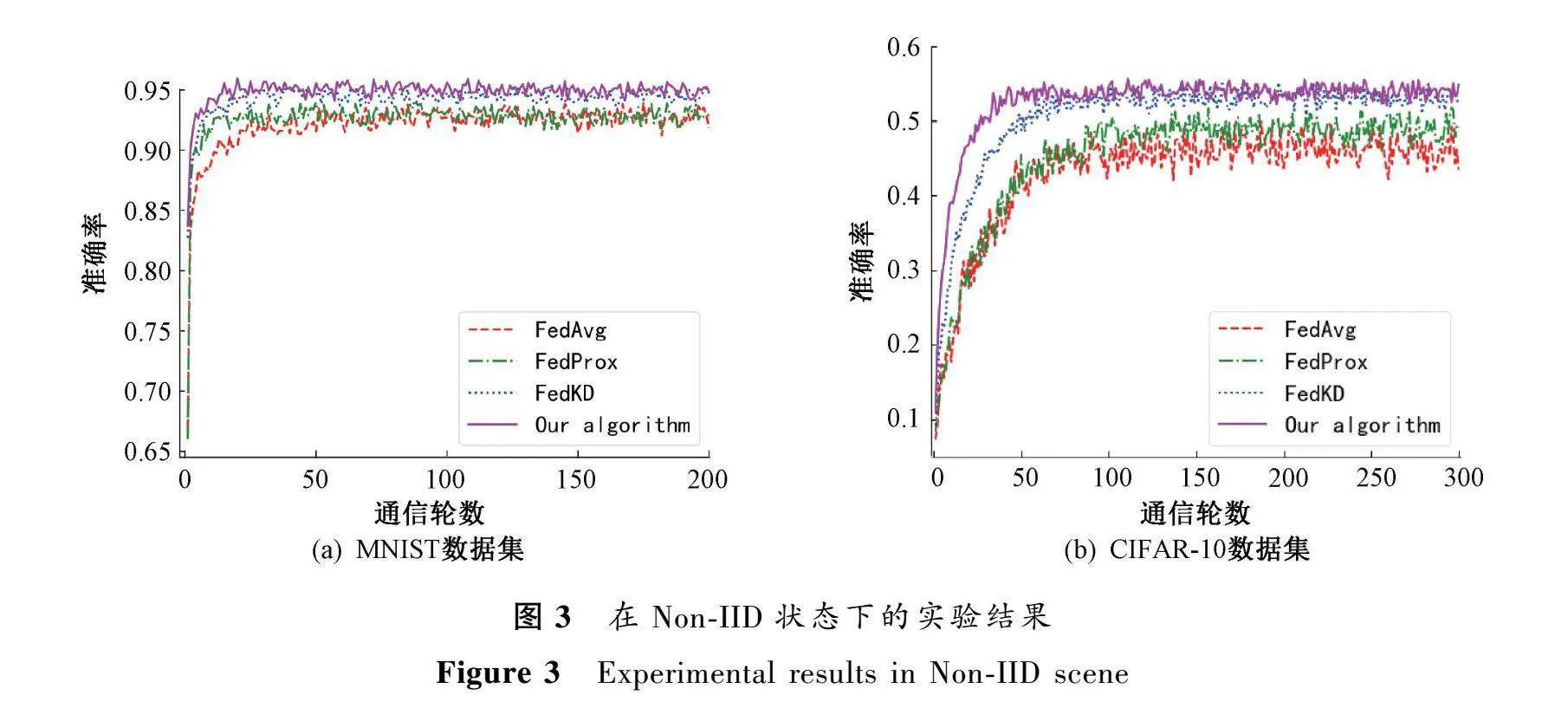
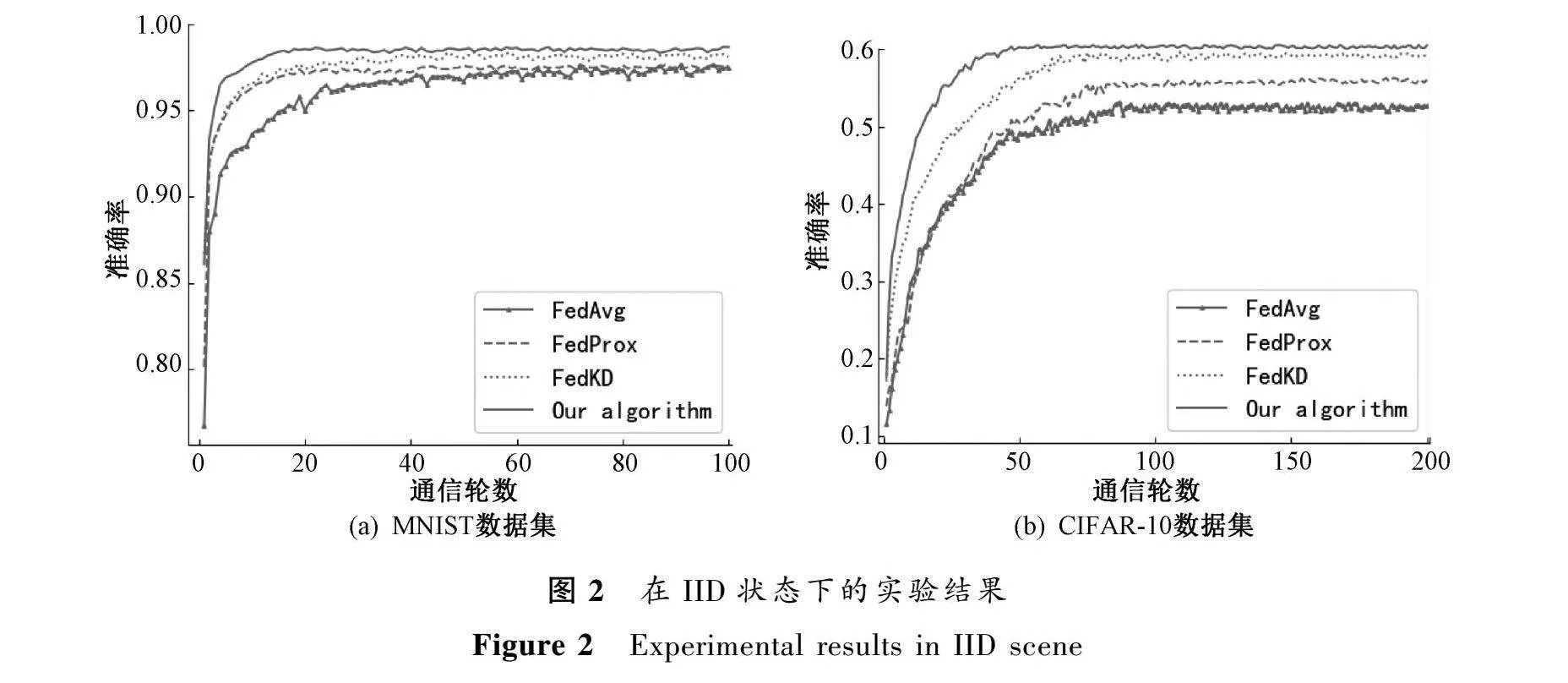
图2和图3分别是在独立同分布和非独立同分布状态下MNIST和CIFAR-10数据集对FedAvg、FedProx、FedKD和本文算法训练的模型性能对比。实验中对于评价模型的性能均采用模型的训练准确率与通信轮数之间的变化趋势来反映,其中在独立同分布状态下,MNIST和CIFAR-10数据集分别进行了100轮和200轮通信;在非独立同分布状态下,MNIST和CIFAR-10数据集分别进行了200轮和300轮通信。
在独立同分布实验状态下,对于MNIST数据集,本文提出的算法最终精度为99.05%,而FedAvg、FedProx和FedKD算法的最终精度分别为97.37%、97.54%和98.17%,与之相比,本文方法在模型最终精度上分别提升了1.7%、1.5%和0.9%。对于CIFAR-10数据集,本文算法最终精度为60.31%,而FedAvg、FedProx和FedKD算法的最终精度分别为52.51%、55.93%和59.17%,与之相比本文方法在模型最终精度上分别提升了14.9%、7.8%和1.9%。
在非独立同分布实验状态下,对于MNIST数据集,本文提出的算法最终精度为94.94%,而FedAvg、FedProx和FedKD算法的最终精度分别为92.64%、92.86%和94.56%,与之相比,本文方法在模型最终精度上分别提升了1.2%、1.0%和0.4%。对于CIFAR-10数据集,本文算法最终精度为53.99%,而FedAvg、FedProx和FedKD算法的最终精度分别为45.69%、49.05%和53.18%,与之相比本文方法在模型最终精度上分别提升了18.1%、10.1%和1.5%。
对于独立同分布实验状态和非独立同分布实验状态,与FedAvg、FedProx以及FedKD算法相比,本文提出的算法模型收敛速度更快,能以更少的通信轮次率先达到模型的收敛,同时在模型最终训练的精度上也更高。
为了弄清楚知识蒸馏过程中,硬标签损失和软标签损失对模型最终性能的影响,接下来,我们将研究集中在控制知识蒸馏过程中硬标签的损失与软标签的损失在总损失中所占比例的超参数λ上。本文在式(1)中对超参数λ设计了一个随着训练轮数进行动态调整,且同时具有最低比例阈值φ的取值机制,因而在接下来的实验中研究不同最低比例阈值对于模型最终精度的影响。本文设计的基于知识蒸馏的边缘联邦学习算法中分别选取的最低比例阈值φ从0.1到0.9进行了实验,得到如下的结果。
在利用知识蒸馏训练机器学习模型的过程中,模型的准确率并不是与最低比例阈值φ成绝对正相关的。使用MNIST数据集进行实验时,在IID和Non-IID两种状态下,当最低比例阈值为0.6时,模型的精度是最高的。这也表明了在模型训练过程中,硬标签知识对于训练模型而言是不可或缺的,同时设置超参数λ的最低阈值是十分有必要的。由于超参数λ控制着在训练过程中基于软标签的损失和基于样本硬标签的损失在总损失函数中所占的比例,所以λ的取值决定着模型性能。由知识蒸馏中软标签知识的来源可知,模型的准确率是与软标签中具有的知识量成正相关的。在联邦学习初期,模型本身的准确率就较低,因而生成的软标签知识量也是较低的,此时如果用软标签知识指导模型训练,不仅会效率低下,甚至可能会误导模型的优化方向。随着联邦学习训练轮次的增加,模型的准确率也得到了提升,此时生成的软标签中的知识量也相对丰富了,在模型无法从硬标签中获得更多的知识指导时,软标签的参与将会进一步促进模型性能的提升。在联邦学习过程中,随着训练轮数的增加,生成的软标签知识量也在逐渐丰富,因此对超参数依据联邦学习训练的轮数采取动态取值是较为合理的。但是在模型训练中软标签知识是无法起到主导作用的,对软标签知识在模型训练中所占比例设置上限是有必要的,当硬标签占比低于0.6,即软标签知识占比超过0.4时,模型的准确率下降。因而在联邦学习训练中合理地选取最低比例阈值,更合理地利用硬标签和软标签知识能够使得模型取得最佳训练效果。同样的,使用CIFAR-10数据集进行实验时,在IID和Non-IID两种状态下,当最低比例阈值为0.6时,模型的准确率也是最高的。
通过上述实验分析可知,客户端在进行本地模型训练时,由于有全局软标签的参与,本地模型性能在一定程度上得到了提升,最终提升了全局模型的性能。
3 结论
本文提出了基于知识蒸馏的边缘联邦学习算法,拓展了传统联邦学习算法中只能从样本硬标签获取知识训练模型的单一渠道,使得在联邦学习模型训练的过程中,能够利用软标签中所涵盖的知识,从而达到进一步提升联邦学习在边缘计算环境中模型性能的目的。与联邦学习中其他较为经典算法的对比实验表明,本文提出的方法能够有效地提升模型的性能。在未来的工作中,需要在追求模型性能的同时,兼顾学习过程中的总能耗,合理控制联邦学习的成本。
参考文献:
[1] 魏明军, 闫旭文, 纪占林, 等. 基于CNN与LightGBM的入侵检测研究[J]. 郑州大学学报(理学版), 2023, 55(6): 35-40.
WEI M J, YAN X W, JI Z L, et al. Research on intrusion detection based on CNN and LightGBM[J]. Journal of Zhengzhou university (natural science edition), 2023, 55(6): 35-40.
[2] 吴宇鑫, 陈知明, 李建军. 基于半监督深度学习网络的水体分割方法[J]. 郑州大学学报(理学版), 2023, 55(6): 29-34.
WU Y X, CHEN Z M, LI J J. Semi-supervised deep learning network based water body segmentation method[J]. Journal of Zhengzhou university (natural science edition), 2023, 55(6): 29-34.
[3] BONAWITZ K, EICHNER H, GRIESKAMP W, et al. Towards federated learning at scale: system design [EB/OL]. (2019-03-22) [2023-04-28]. https:∥arxiv.org/abs/1902.01046.
[4] WANG X F, HAN Y W, WANG C Y, et al. In-edge AI: intelligentizing mobile edge computing, caching and communication by federated learning[J]. IEEE network, 2019, 33(5): 156-165.
[5] ZHANG C, XIE Y, BAI H, et al. A survey on federated learning[J]. Knowledge-based systems, 2021, 216: 106775.
[6] YU B, MAO W J, LV Y H, et al. A survey on federated learning in data mining[J]. WIREs data mining and knowledge discovery, 2022, 12(1): e1443.
[7] SPRAGUE M R, JALALIRAD A, SCAVUZZO M, et al. Asynchronous federated learning for geospatial applications[C]∥Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Cham: Springer International Publishing, 2019: 21-28.
[8] WANG S Q, TUOR T, SALONIDIS T, et al. Adaptive federated learning in resource constrained edge computing systems[J]. IEEE journal on selected areas in communications, 2019, 37(6): 1205-1221.
[9] WANG L P, WANG W, LI B. CMFL: mitigating communication overhead for federated learning[C]∥2019 IEEE 39th International Conference on Distributed Computing Systems. Piscataway: IEEE Press, 2019: 954-964.
[10]LI T, SANJABI M, SMITH V. Fair resource allocation in federated learning [EB/OL]. (2020-02-14) [2023-04-28]. https:∥arxiv.org/abs/1905.10497v1.
[11]YOSHIDA N, NISHIO T, MORIKURA M, et al. Hybrid-FL for wireless networks: cooperative learning mechanism using non-IID data[C].(2019-05-17)[2023-04-28]. https:∥arxiv.org/pdf/1905.07210V2.pdf.
[12]ZHAO Y, LI M, LAI L Z, et al. Federated learning with non-iid data [EB/OL]. (2022-07-21) [2023-04-28]. https:∥arxiv.org/abs/1806.00582.
[13]YUAN P Y, ZHAO X Y, CHANG B F, et al. COPO: a context aware and posterior caching scheme in mobile edge computing[C]∥2019 IEEE International Conference on Signal Processing, Communications and Computing. Piscataway: IEEE Press, 2019: 1-5.
[14]YUAN P Y, CAI Y Y. Contact ratio aware mobile edge computing for content offloading[C]∥IEEE International Conference on Parallel and Distributed Systems. Piscataway: IEEE Press, 2019: 520-524.
[15]LIU J, HUANG J Z, ZHOU Y, et al. From distributed machine learning to federated learning: a survey[J]. Knowledge and information systems, 2022, 64(4): 885-917.
[16]HUANG W K, YE M, DU B. Learn from others and be yourself in heterogeneous federated learning[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 10143-10153.
[17]CHAI Z, FAYYAZ H, FAYYAZ Z, et al. Towards taming the resource and data heterogeneity in federated learning[C]∥2019 USENIX Conference on Operational Machine Learning. Berkeley: USENIX Association Press, 2019: 19-21.
[18]MCMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[EB/OL]. (2016-02-17) [2023-04-28]. https:∥arxiv.org/abs/1602.05629.
[19]LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks[EB/OL]. (2019-04-21) [2023-04-28]. https:∥arxiv.org/abs/1812. 06127.
