基于预训练表示和宽度学习的虚假新闻早期检测
2025-01-01胡舜邦王琳刘伍颖









摘要: 为了实现虚假新闻的早期检测,提出一种基于预训练表示和宽度学习的虚假新闻早期检测方法。首先,将新闻文本输入大规模预训练语言模型RoBERTa中,得到对应新闻文本的上下文语义表示。其次,将得到的新闻文本的上下文语义表示输入宽度学习的特征节点和增强节点中,利用宽度学习的特征节点和增强节点进一步提取新闻文本的线性和非线性特征并构造分类器,从而预测新闻的真实性。最后,在3个真实数据集上进行了对比实验,结果表明,所提方法可以在4 h内检测出虚假新闻,准确率超过80%,优于基线方法。
关键词: 早期检测; 虚假新闻; 预训练表示; 宽度学习; 文本分类
中图分类号: TP391
文献标志码: A
文章编号: 1671-6841(2025)02-0031-06
DOI: 10.13705/j.issn.1671-6841.2023129
Early Detection of Fake News Based on Pre-training Representation
and Broad Learning
HU Shunbang1, WANG Lin2, LIU Wuying3,4
(1.School of Information Science and Technology, Guangdong University of Foreign Studies, Guangzhou
510006, China; 2.Xianda College of Economics and Humanities, Shanghai International Studies University,
Shanghai 200083, China; 3.Shandong Key Laboratory of Language Resources Development and Application,
Ludong University, Yantai 264025, China; 4.Center for Linguistics and Applied Linguistics, Guangdong
University of Foreign Studies, Guangzhou 510420, China)
Abstract: In order to achieve early detection of fake news, a method based on pre-training representation and broad learning was proposed. Firstly, the news text was input into the RoBERTa large-scale pre-training language model to obtain the contextual semantic representation of the corresponding news text. Secondly, the obtained contextual semantic representation was fed into the feature nodes and enhanced nodes of broad learning. By leveraging these broad learning nodes, both linear and non-linear features were extracted from the news text, enabling the construction of a classifier for predicting the authenticity of the news. Finally, comparative experiments were conducted on three real datasets, and the results demonstrated that the proposed method was capable of detecting fake news within 4 h with an accuracy rate exceeding 80%, surpassing the performance of the baseline method.
Key words: early detection; fake news; pre-training representation; broad learning; text classification
0 引言
随着互联网的不断发展和社交媒体网站的普及,人们可以很方便地通过移动互联网设备阅读新闻资讯信息,但这也为虚假新闻的滋生提供了温床。虚假新闻的广泛传播严重扰乱了社会的正常秩序[1],因此对虚假新闻的及时检测与发现是非常有必要的。现有的虚假新闻检测方法可以分为基于机器学习的方法和基于深度学习的方法。
基于机器学习的方法主要是通过从新闻文本内容中抽取语言特征输入机器学习分类器中进行虚假新闻的检测。Castillo 等[2]通过从新闻文本内容中提取特殊字符和关键词等特征来进行虚假新闻的检测。Kwon 等[3]通过抽取新闻文本中的写作风格特征来进行虚假新闻的检测。Feng等[4]通过新闻文本中的词汇和句法特征进行虚假新闻的检测。然而,在虚假新闻传播的早期,一些有效的特征往往是不具备或者是不充分的,而且依赖于特征工程的机器学习方法耗时、耗力,不利于虚假新闻的及时检测。
基于深度学习的方法主要是通过对新闻文本内容以及社交上下文内容进行建模,从而实现虚假新闻的检测。Ma等[5]通过循环神经网络(recurrent neural network, RNN)对新闻文本内容建模,从而实现虚假新闻的检测。Ma等[6]还通过RNN同时训练虚假新闻检测和用户立场分类两个任务,首次将多任务学习的思想应用到虚假新闻检测中,从而使虚假新闻检测任务的效果得到提升。Bian等[7]通过构造新闻的传播结构图,利用双向图卷积神经网络学习其新闻传播特征,从而进行虚假新闻的检测。虽然这些基于深度学习的方法在虚假新闻检测任务中取得了不错的效果,但是在新闻传播的早期,新闻的评论数据往往是比较稀缺的,用户对虚假新闻更倾向于转发而不是评论,收集评论数据往往比较困难,而且构建其传播结构图复杂且耗时,存在理论分析困难、训练推理速度慢、难以收敛的问题。
为了解决上述虚假新闻早期检测中存在的问题,本文提出一种基于预训练表示和宽度学习(pre-training representation and broad learning)的虚假新闻早期检测方法,简称为PTBL。该方法可以在虚假新闻传播的早期,在社交上下文信息较为短缺的情况下,提高虚假新闻早期检测的准确率,同时使得模型的训练推理速度更快,结构更为简洁清晰,理论分析更为方便。
1 PTBL模型
PTBL模型结构如图1所示。首先,将新闻文本作为RoBERTa预训练模型的输入,以获得其与上下文语义相关的词向量,然后对每个词向量求和,再求其平均,得到新闻文本表示。新闻文本表示通过线性激活函数进行线性变换生成宽度学习的特征节点,通过非线性激活函数对特征节点进行非线性变换生成宽度学习的增强节点。然后,将特征节点和增强节点拼接起来,输入宽度学习的输出层,最后再输出到Softmax函数得到其概率分布,从而实现了对新闻文本真实性的判定。
1.1 新闻文本表示
由于在虚假新闻传播的早期,收集新闻的用户评论信息以及构造其传播结构图是相当困难的,为了贴合实际情况,只选择从新闻文本中获取线索去识别新闻的真实性。
大规模预训练语言模型得益于其可以在大量的未标注语料上学习到通用的上下文语义信息,在自然语言处理的多个任务中都取得了不错的成绩,其中最为熟悉的预训练语言模型是BERT[8]模型。RoBERT68a800aff2c7bd8bdc5f29347da9e5d98a8e155896368d7a52aae04d5c78095fa是一种鲁棒优化的BERT预训练语言模型,采用的模型结构与BERT相似,都是使用多个Transformer[9]编码器进行编码,其核心的多头自注意力机制具有强大的上下文语义提取能力。
与BERT模型相比,RoBERTa使用了更多的数据进行预训练,这使得其具有更强的语言理解能力。此外,RoBERTa模型还对预训练过程进行了调整,采用了更大的批量大小和更多的训练步数进行训练,在每个训练步骤中使用动态掩码机制随机掩盖不同的词,增加了模型的泛化能力。与此同时,RoBERTa在预训练阶段去掉了BERT中预测下一个句子(next sentence prediction,NSP)的任务,该任务要求模型预测两个句子是否相邻。然而,NSP 任务对语言理解能力的提升并不明显,去掉该任务可以让模型更好地学习语言表示。因此,采用RoBERTa预训练语言模型来获取新闻的文本表示。具体地,首先将数据集输入RoBERTa中进行微调,使其适应虚假新闻检测任务,然后取其最后一个隐藏层作为词向量,对所有词向量求和,再求其平均,得到新闻文本表示,
T=1n∑ni=1Vi,(1)
式中:T为新闻文本表示;Vi表示新闻文本中第i个词的词向量;n为新闻文本中单词的个数。
1.2 宽度学习方法
宽度学习[10]在图像分类[11]、视觉识别[12]等任务中取得了不错的效果,主要由特征节点、增强节点和输出层组成。宽度学习只需要训练输出层的权重即可,它可以通过计算其输入矩阵的伪逆矩阵来求解。因此,宽度学习具有结构简单、求解速度快的优点,而且还能在原模型的基础上进行增量学习,使得模型能够更加快速地进行迭代,符合虚假新闻早期检测任务需要模型训练更新速度快的要求。本文采用宽度学习方法对新闻文本表示进一步地进行特征抽取,使得模型能够更加迅速地学习到新闻的更深层次的语义特征,有助于在短时间内提高虚假新闻早期检测的准确率,使得虚假新闻在其传播早期就得到及时遏止,缩小其在社交媒体的传播范围,进一步减少虚假新闻对社会的危害。
设训练数据{X,Y}∈
RN×(d+c),其中:N为样本数;d为特征维数;c为新闻类别数。
首先,将新闻文本表示T线性变换为n组特征节点,特征节点Fi可表示为
Fi=L(TWfi+Bfi),i=1,2,…,n,(2)
式中:L为线性激活函数;Wfi和Bfi分别为随机生成的权重矩阵和偏置矩阵。则n组特征节点可表示为
Fn[F1,F2,…,Fn]。(3)
将n组特征节点Fn通过非线性激活函数非线性转换到m组增强节点,增强节点Sj可表示为
Sj=φ(FnWsj+Bsj),j=1,2,…,m,(4)
式中:φ为非线性激活函数;Wsj和Bsj分别为随机生成的权重矩阵和偏置矩阵。则m组增强节点可表示为
Sm[S1,S2,…,Sm]。(5)
然后,将n组特征节点与m组增强节点拼接输入到输出层O,则O可表示为
O=[Fn,Sm]W=AW,(6)
式中:W为输出层O的权重矩阵;A=[Fn,Sm]为输出层O的输入矩阵。假设矩阵A′是输入矩阵A的伪逆矩阵,那么权重矩阵W表示为
W=A′O。(7)
为有效地减少计算时间,防止过拟合,采用岭回归的方法来求解伪逆矩阵A′的值,可表示为
A′=limλ→0(λI+AAT)-1
AT。(8)
最后,将输出层O通过Softmax函数得到标签的概率分布,从而可以对新闻真实性进行预测。
2 实验与分析
为了验证本文提出的PTBL模型在虚假新闻早期检测中的有效性,在Weibo[5]、Twitter15和Twitter16[13]3个公开数据集上进行实验与分析。
2.1 数据集
Weibo数据集只包含“真”“假”两个分类标签,Twitter15和Twitter16数据集则包含四个不同的分类标签,分别是“真”“假”“未核实”“揭穿假”。其中,“揭穿假”的标签是指:告诉人们某个新闻故事是假的。数据集统计信息如表1所示。
2.2 评价指标与实验设置
在Weibo数据集上采用的评价指标是准确率、精确率、召回率和F1 值,在Twitter15与Twitter16数据集上采用的评价指标是准确率和F1 值。为了进行公平的比较,使用文献[14]中方式对3个数据集进行了同样的划分,即10%的样本作为验证集,剩下的样本按3∶1的比例划分为训练集和测试集。
在Weibo数据集上使用的预训练模型是Cui等[15]提出的Chinese-RoBERTa-wwm-ext模型,因为该模型在中文任务上的性能表现更好,而在Twitter15和Twitter16数据集上使用的预训练模型是RoBERTa-base模型。
对数据集进行微调的批次大小都设置为64,最大序列长度为128,学习率为5×10-5,训练步数为105。每组特征节点与增强节点的个数以及特征节点与增强节点的组数对虚假新闻早期检测的性能有明显的影响。在Weibo数据集上,当每组特征节点与增强节点的个数设置为2 000,组数分别为15和20时,模型的性能达到最佳。在Twitter15和Twitter16数据集上,当每组特征节点与增强节点的个数设置为500,组数分别为10和15时,模型的性能达到最佳。
2.3 对比方法
为了验证PTBL模型的性能,将其与以下常用的虚假新闻早期检测基线模型进行对比。1) DTC:Castillo等[2]提出的一种基于决策树的模型,利用新闻特征的组合进行虚假新闻的检测。2) DTR:Zhao等[16]提出的一种基于决策树的通过查询短语来检测虚假新闻的排名方法。3) GRU:Ma等[5]提出的一种基于RNN的模型,从用户评论中学习时间语言模式用于虚假新闻的检测工作。4) RFC:Kwon等[17]提出的一种利用用户、语言和结构特征的随机森林分类器来进行虚假新闻的检测。5) PTK:Ma等[13]提出的一种具有传播树内核的SVM分类器,通过从传播树中学习时间结构模式来检测虚假新闻。
2.4 评价结果分析
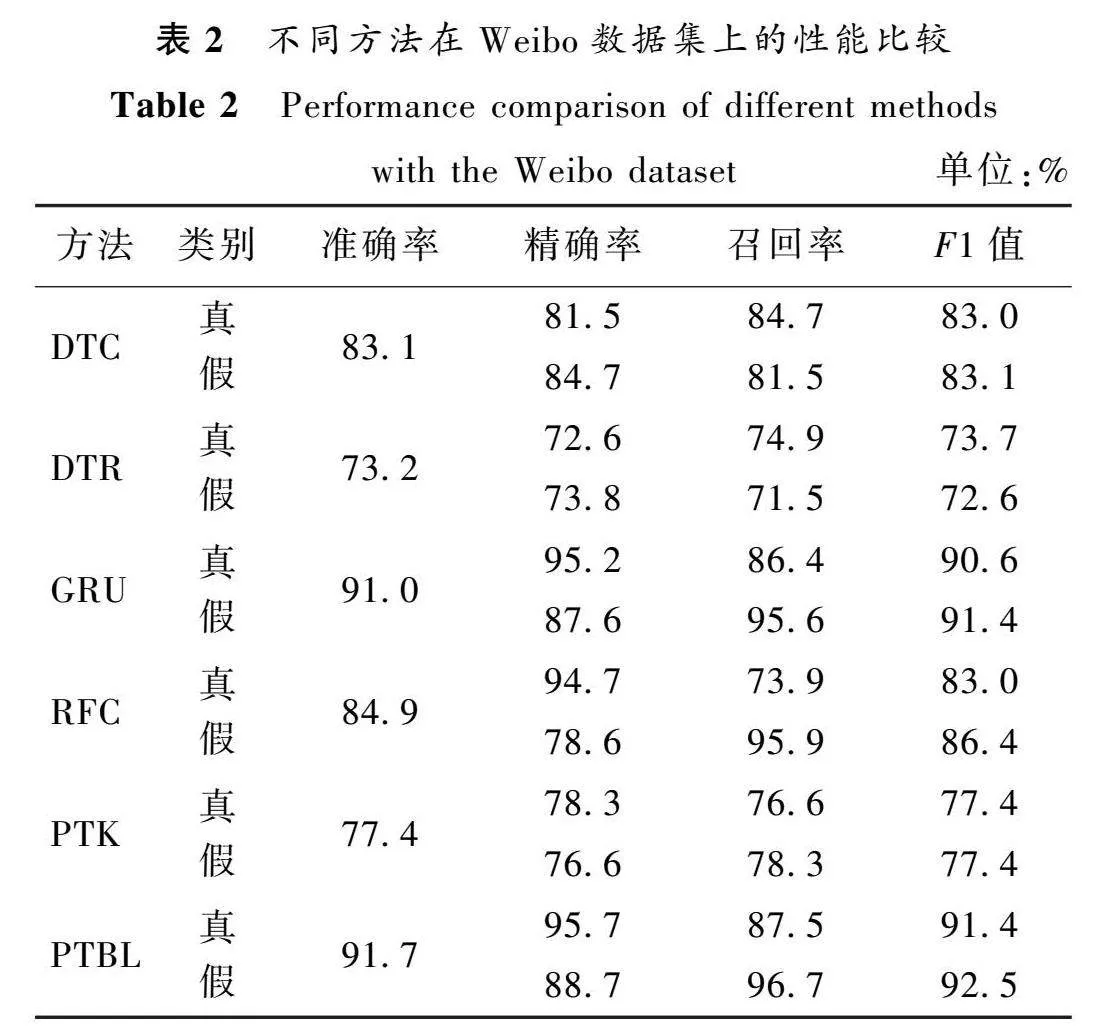
文献[14]指出,对于上述对比方法,当检测截止时间超过24 h时,它们的检测性能就会达到饱和。因此,为了公平比较,将模型检测截止时间均设置为24 h。PTBL模型和对比方法在Weibo、Twitter15和Twitter16数据集上的虚假新闻检测性能结果如表2~ 4所示。可以发现,PTBL模型性能优于对比方法,在3个数据集上的准确率分别为91.7%、80.5%和84.0%。
PTBL模型无论是在准确率还是在F1值上都比基线方法表现得更加出色,说明所提的基于预训练表示和宽度学习的方法能够有效地提高虚假新闻检测的性能,在Weibo数据集上的准确率能够达到91.7%,在Twitter15和Twitter16数据集上更是超出对比方法至少5个百分点。
PTBL模型能够充分地理解虚假新闻的语义信息,这主要得益于大规模预训练语言模型RoBERTa能够事先在大量
的无标注数据中学习到许多通用的语义信息,而且还通过宽度学习的特征节点和增强节点对新闻的语义信息进行更深层次的挖掘学习,从而进一步提升了该方法在虚假新闻早期检测任务中的性能。
2.5 消融实验
大规模预训练语言模型RoBERTa在自然语言处理的多项任务中的表现十分出色,已经得到了广泛的认可。为了验证PTBL模型中宽度学习模块的有效性,对宽度学习模块进行了消融实验,实验结果如表5所示。可以看出,在PTBL模型的基础上去除宽度学习模块,在3个数据集上其准确率至少降低了3个百分点,表明宽度学习模块在PTBL模型中起着重要作用。
2.6 虚假新闻早期检测性能
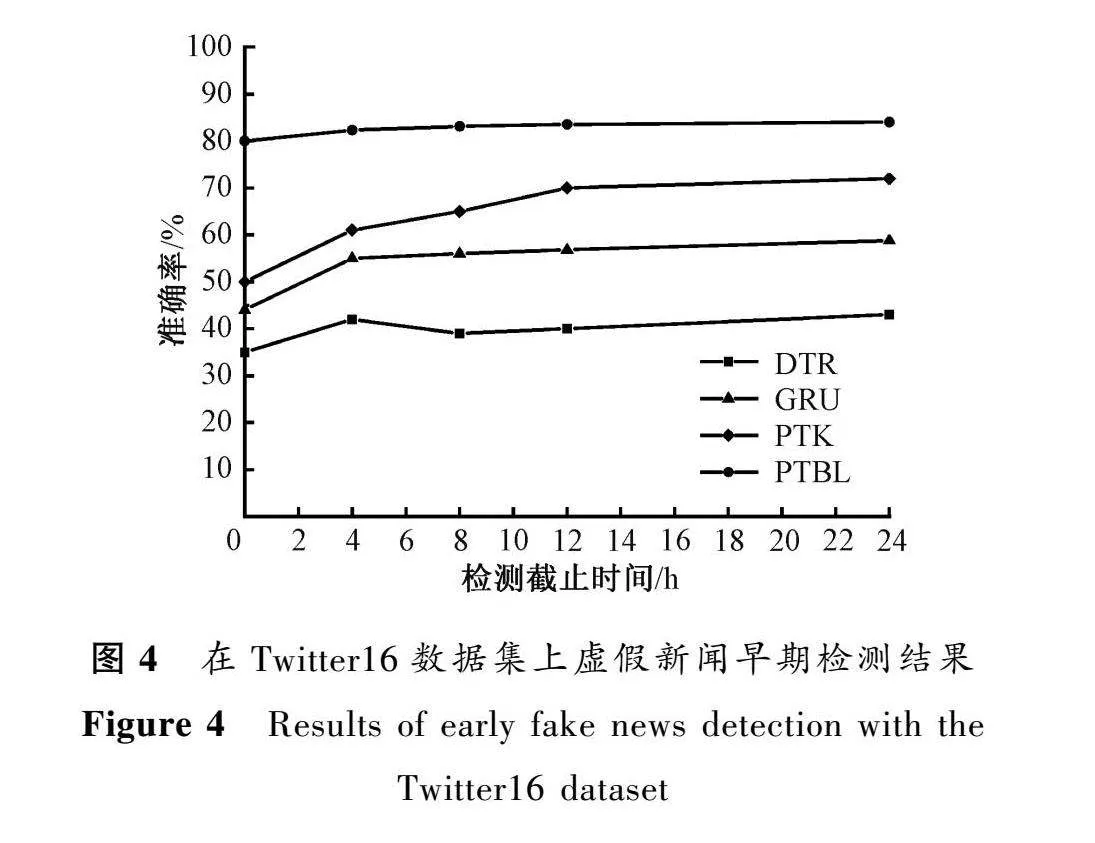
为了进一步观察PTBL模型在虚假新闻早期检测中的性能表现,选择了DTR、GRU和PTK模型进行对比实验,观察其在虚假新闻开始传播后24 h内检测性能表现。PTBL模型和3个对比模型在Weibo、Twitter15和Twitter16数据集上虚假新闻早期检测结果如图2~4所示。从实验结果可以看出,PTBL模型在新闻开始传播后4 h内就能够较快地达到很好的检测准确率,远远好于DTR、GRU和PTK这3个对比模型。这主要是由于DTR和GRU方法依赖于从用户评论中提取的语言特征,而PTK方法依赖于从新闻传播结构中提取的语言和结构特征。然而,在虚假新闻传播早期,获取用户评论与构造新闻传播结构图是很困难的,所以这3个对比方法在虚假新闻传播早期的检测性能都比较差。
PTBL模型在虚假新闻传播早期就能达到较好的效果,这主要是由于该模型具有以下特点。
1) 其不依赖于用户的评论信息和新闻传播结构建模,能够充分利用大规模预训练模型强大的语义理解能力。
2) 宽度学习模块的训练推理速度快,它只需要求解输入矩阵的伪逆矩阵即可求解出输出层的权重值,在提高了PTBL模型语义理解能力的同时,加快了模型的更新与推理速度,使得PTBL模型在虚假新闻早期检测任务中的整体性能好于对比方法。
3 结语
针对现有的虚假新闻早期检测方法严重依赖于新闻评论数据和新闻传播结构图的问题,本文提出一种基于预训练表示和宽度学习的虚假新闻早期检测方法。通过大规模预训练语言模型从大量的未标注语料上学习到通用的语义知识,并通过宽度学习对新闻文本进一步地进行语义提取挖掘,模型结构简单且容易分析,能够在虚假新闻早期检测任务中取得比基线方法更好的检测效果。下一步的研究工作将探索更加适用于虚假新闻早期检测任务的预训练表示方法,使其在更加充分表达新闻文本语义信息的同时,模型大小能够进一步压缩。为了更好地挖掘新闻的语义信息和提高模型的推理速度,也将探索不同级联方式的宽度学习方法来进行虚假新闻的早期检测工作。
参考文献:
[1] 冀源蕊, 康海燕, 方铭浩. 基于Attention与Bi-LSTM的谣言识别方法[J]. 郑州大学学报(理学版), 2023, 55(4): 16-22.
JI Y R, KANG H Y, FANG M H. Rumor recognition method based on Attention and Bi-LSTM[J]. Journal of Zhengzhou university (natural science edition), 2023, 55(4): 16-22.
[2] CASTILLO C, MENDOZA M, POBLETE B. Information credibility on Twitter[C]∥Proceedings of the 20th International Conference on World Wide Web. New York: ACM Press, 2011: 675-684.
[3] KWON S, CHA M, JUNG K, et al. Prominent features of rumor propagation in online social media[C]∥Proceedings of the IEEE 13th International Conference on Data Mining. Piscataway:IEEE Press, 2014: 1103-1108.
[4] FENG S, BANERJEE R, CHOI Y. Syntactic stylometry for deception detection[C]∥Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics,2012: 171-175.
[5] MA J, GAO W, MITRA P, et al. Detecting rumors from microblogs with recurrent neural networks[C]∥International Joint Conference on Artificial Intelligence. Amsterdam: Elsevier Press,2016: 56-66.
[6] MA J, GAO W, WONG K F. Detect rumor and stance jointly by neural multi-task learning[C]∥Proceedings of the Web Conference. New York: ACM Press, 2018: 585-593.
[7] BIAN T A, XIAO X, XU T Y, et al. Rumor detection on social media with bi-directional graph convolutional networks[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press,2020: 549-556.
[8] DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding[C]∥Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: Association for Computational Linguistics, 2019: 4171-4186.
[9] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM Press, 2017: 6000-6010.
[10]PHILIP C C L, LIU Z L. Broad learning system: an effective and efficient incremental learning system without the need for deep architecture[J]. IEEE transactions on neural networks and learning systems, 2018, 29(1): 10-24.
[11]CHU Y H, LIN H F, YANG L A, et al. Hyperspectral image classification with discriminative manifold broad learning system[J]. Neurocomputing, 2021, 442: 236-248.
[12]JIN J W, LI Y T, YANG T J, et al. Discriminative group-sparsity constrained broad learning system for visual recognition[J]. Information sciences, 2021, 576: 800-818.
[13]MA J, GAO W, WONG K F. Detect rumors in microblog posts using propagation structure via kernel learning[C]∥Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2017: 708-717.
[14]LIU Y, WU Y F. Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018:354-361.
[15]CUI Y M, CHE W X, LIU T, et al. Revisiting pre-trained models for Chinese natural language processing[C]∥Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: Association for Computational Linguistics, 2020: 657-668.
[16]ZHAO Z, RESNICK P, MEI Q Z. Enquiring minds: early detection of rumors in social media from enquiry posts[C]∥Proceedings of the 24th International Conference on World Wide Web. New York: ACM Press, 2015: 1395-1405.
[17]KWON S, CHA M, JUNG K. Rumor detection over varying time windows[J]. PLoS one, 2017, 12(1): e0168344.
