基于多尺度特征提取的层次多标签文本分类方法
2025-01-01武子轩王烨于洪








摘要: 针对现有的特征提取方法忽略文本局部和全局联系的问题,提出了基于多尺度特征提取的层次多标签文本分类方法。首先,设计了多尺度特征提取模块,对不同尺度特征进行捕捉,更好地表示文本语义。其次,将层次特征嵌入文本表示中,得到具有标签特征的文本语义表示。最后,在标签层次结构的指导下对输入文本构建正负样本,进行对比学习,提高分类效果。在WOS、RCV1-V2、NYT和AAPD数据集上进行对比实验,结果表明,所提模型在评价指标上表现出色,超过了其他主流模型。此外,针对层次分类提出层次Micro-F1和层次Macro-F1指标,并对模型效果进行了评价。
关键词: 层次多标签文本分类; 多尺度特征提取; 对比学习; 层次Micro-F1; 层次Macro-F1
中图分类号: TP391
文献标志码: A
文章编号: 1671-6841(2025)02-0024-07
DOI: 10.13705/j.issn.1671-6841.2023120
Hierarchical Multi-label Text Classification Method Based
on Multi-scale Feature Extraction
WU Zixuan, WANG Ye, YU Hong
(Chongqing Key Laboratory of Computational Intelligence, Chongqing University of Posts and
Telecommunications, Chongqing 400065, China)
Abstract:
A hierarchical multi-label text classification method based on multi-scale feature extraction was proposed to address the issue of current feature extraction methods in neglecting the local and global connections in text. Firstly, a multi-scale feature extraction module was designed to capture features at different scales, aiming to provide a better representation of text semantics. Secondly, the hierarchical features were embedded into the text representation to obtain a text semantic representation with label features. Finally, with the guidance of the label hierarchy, positive and negative samples were constructed for the input text, and contrastive learning was performed to enhance the classification effectiveness. Comparative experiments were conducted on the WOS, RCV1-V2, NYT and AAPD datasets. The results indicated that the proposed model performed well in terms of the evaluation indices and exceeded other mainstream models. Additionally, the hierarchical Micro-F1 and Macro-F1 indicators were proposed for hierarchical classification, and the effectiveness of the model was evaluated.
Key words: hierarchical multi-label text classification; multi-scale feature extraction; contrastive learning; hierarchical Micro-F1; hierarchical Macro-F1
0 引言
层次多标签文本分类(hierarchical multi-label text classification,HMTC)问题是指在现实情境中,一个样本可能具有多个类标签,并且这些类标签之间存在层次结构,分类任务的目标是将这些具有层次结构的类标签正确地分配给样本。层次多标签分类问题与多标签分类类似,不同之处在于样本对应多个类标签时,这些标签之间具有天然的层次依赖关系,如父与子关系或祖先与后代关系。此外,这些标签之间的依赖关系具有不同权重,较低层级的标签会受到较高层级标签的约束。
为引入类别层级信息,Banerjee等[1]提出HTrans模型,采用迁移学习的方式为每个类别训练一个二分类器,子类别的分类器采用父类别的模型参数进行初始化。Cesa-Bianchi等[2]提出层次贝叶斯模型,增量学习每个节点的线性分类器。Zhou等[3]将层次表示为有向图,并利用标签依赖的先验概率来聚集节点信息,提出一种层次感知全局模型HiAGM。Deng等[4]在HiAGM基础上提出基于文本标签互信息最大化的HTCInfoMax模型。除此之外,一些方法同时利用了局部和全局信息。Huang等[5]提出HARNN模型,用局部分类器采用注意力机制提取标签特征,用全局分类器将各层级提取的特征拼接起来,给出全局预测结果。Zhang等[6]利用公共因子在同级类别之间建立联系,由父层向子层传递文本表征,设计了LA-HCN模型,判断文本与子层中哪个类别最相匹配。Wang等[7]提出基于层次引导的对比学习模型,将层次嵌入文本编码器中,而不是单独建模。
当前在处理层次多标签分类问题时,面临的一个主要挑战是文本特征提取的局限性。现有的特征提取方法不够多样化,往往忽视了文本特征在局部和全局之间的联系。文本本身蕴含着多个方面的信息,仅仅关注词语或句子的单一表示方法可能会导致部分信息丢失。局部的文本表示无法完全捕捉文本中的全局信息,而实际上,文本的意义往往由单个词或句子与周围文本相互联系共同构成。因此,本文提出了基于多尺度特征提取的层次多标签文本分类方法(hierarchical multi-label text classification method based on multi-scale feature extraction),简称为MHGCLR。首先设计了多尺度特征提取模块,将BERT[8]词向量和Doc2Vec[9]句向量结合起来,从不同尺度捕捉特征,以更好地区分文本,提高分类性能。为了充分捕捉文本中的多层次信息,文本分类中同时使用单词级别和句子级别的特征。这些不同尺度的特征往往具有各自独特的语义信息和特点,将这些特征结合起来可以相互弥补不足之处。MHGCLR模型采用门控单元对不同尺度的特征进行融合,可以自适应变化,决定信息的重要性和传递的路径,提升分类效果。
此外,根据层次文本分类(hierarchical text classification,HTC)的传统评估度量,会把孤立节点视为正确有效的预测,但是这样并不合理。每个节点的预测不应该与它所在路径内的结果相冲突,孤立的预测和不一致路径不符合实际要求。针对标签不一致问题,本文提出了两个新的指标:层次Micro-F1和层次Macro-F1。只有将真实标签的所有祖先都预测正确,才能认为这个标签预测正确。这两个指标能够更全面地评估模型的性能,避免了使用传统指标带来的局限性。在WOS、RCV1-V2、NYT和AAPD数据集上进行了对比实验,结果表明,所提出的MHGCLR模型优于其他主流模型。
1 基于多尺度特征提取的HMTC方法
为了应对原始文本转化为高维度向量的问题,特别是其在计算资源和模型复杂度方面所造成的负担,需要进行特征提取处理。特征提取是将原始文本数据转换为低维度且稠密的特征向量的过程。这个过程通过保留原始文本的关键信息,能够降低特征向量的维度,从而提高模型训练效率和预测准确性。常见的特征提取方法包括TF-IDF、Doc2Vec、BERT等。
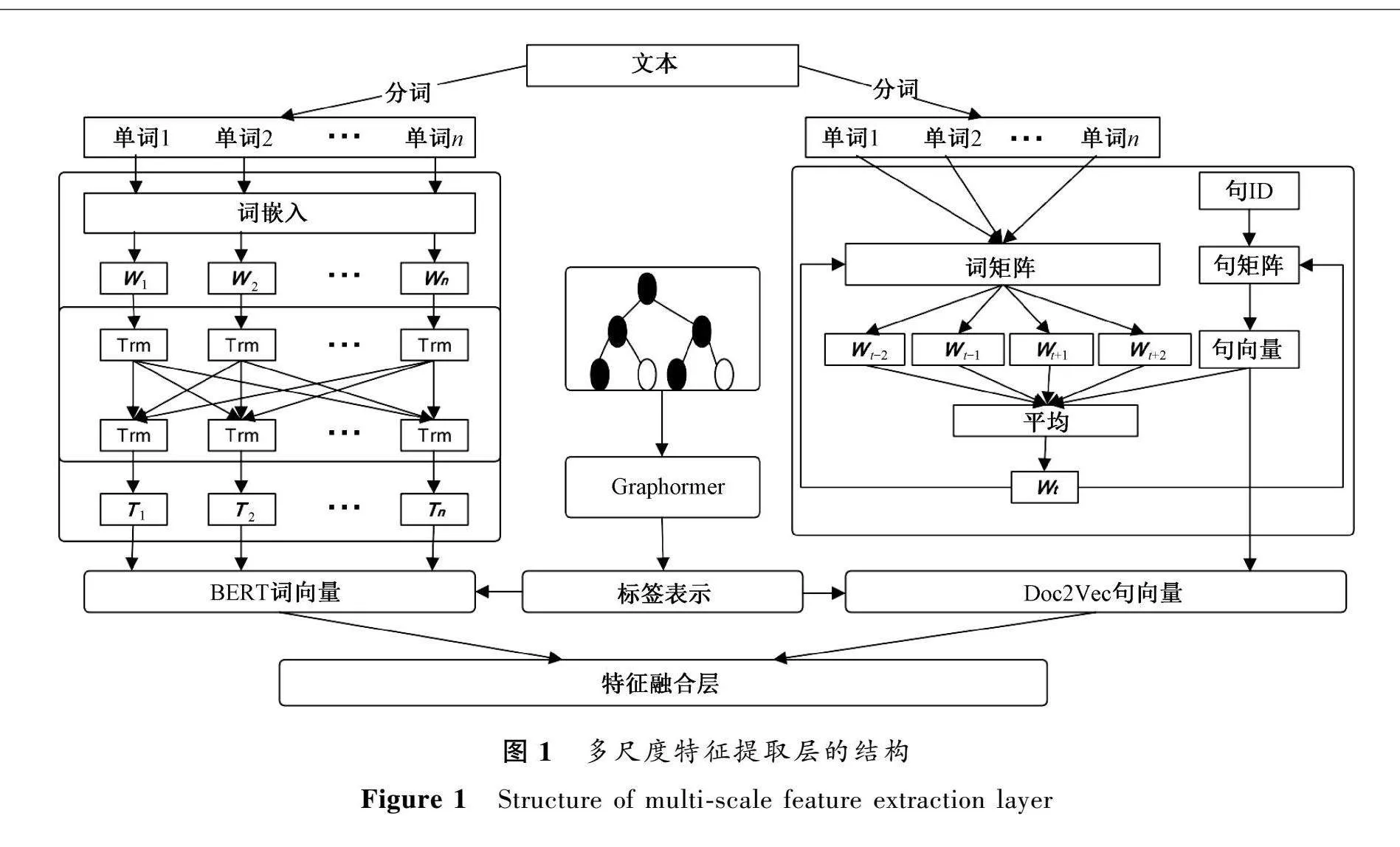
传统上常倾向于单一特征提取方法,然而这些常用的方法如BERT和Doc2Vec都存在一定的局限性。具体而言,BERT能够提供上下文相关的词向量,精准地表达每个单词的含义,但在捕捉整个句子的语义信息方面相对较弱。与之相反,Doc2Vec能够捕捉到整个句子的语义信息,但它平均化了单词的表示,失去了单词级别的丰富信息。本文采用了融合BERT和Doc2Vec的策略,将BERT词向量和Doc2Vec句向量结合起来,有助于克服它们各自的局限性。这种融合方法利用了门控单元自适应地确定信息的重要性,从而将信息融合在一起。最终得到的特征表示能够更全面、准确地表达文本信息。图1展示了多尺度特征提取层的结构。
1.1 BERT
使用BERT模型在词尺度生成高质量的词向量表示。BERT是基于Transformer Encoder的模型,其中每个Transformer Encoder包含多头自注意力机制与前馈神经网络。
使用残差连接和层归一化操作提高模型训练效率与泛化能力,解决梯度消失和梯度爆炸问题,
y=LayerNorm(x+Sublayer(x)),(1)
式中:Sublayer表示自注意力机制或者前馈网络子层;LayerNorm表示层归一化;x是子层的输入向量;y表示输出向量。
1.2 Doc2Vec
Doc2Vec是基于Word2Vec模型的一种算法,用于生成文档的向量表示,即句向量。与Word2Vec不同,Doc2Vec能够捕捉整个文档的语义信息。PV-DM是Doc2Vec的一种变体,也被称为Distributed Memory模型,该技术能将文档和单词嵌入固定的向量空间中。PV-DM模型接受上下文单词和句向量作为输入,通过神经网络预测目标单词。模型参数通过反向传播算法进行调整,使得模型能够准确预测目标单词并生成准确的文档向量。通过这种方式,PV-DM模型能够捕捉整个句子的信息,而不仅仅是单词级别。将BERT的语义表征与Doc2Vec句向量输入特征融合层进行融合,然后完成分类任务。这种融合能够更好地结合句子的语义信息,为分类任务提供更准确的输入。
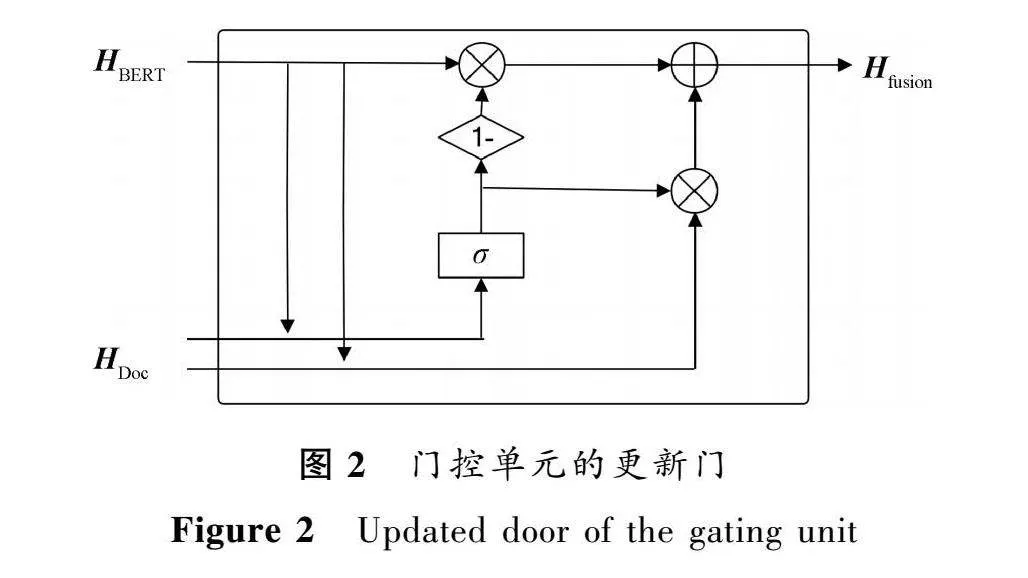
1.3 特征融合
采用门控单元GRU的更新门,对BERT和Doc2Vec进行特征融合。具体来说,将BERT词向量和Doc2Vec句向量作为GRU网络的输入,通过门控单元自适应地决定信息的重要性,将信息进行融合,得到最终的特征表示。首先通过线性变换将两个向量的维度对齐,
Doc=W·
HDoc,(2)
式中:HDoc表示Doc2Vec特征向量;Doc表示转化后的特征向量;
W是变换矩阵。
之后,通过更新门机制来确定信息的保留程度,
gw=σ(wiDoc+
wcHBERT+bg),(3)
式中:gw表示信息的保留程度;HBERT表示BERT文本特征向量;σ表示sigmoid激活函数;
wi与wc为更新门权重;bg表示更新门偏置。
特征融合可表示为
Hfusion=
gDoc+(1-g)HBERT,(4)
式中:Hfusion表示融合后的文本特征向量。
门控单元的更新门如图2所示。
1.4 图形编码器
采用Graphormer作为标签层次结构的建模工具。Graphormer是一种基于Transformer的神经网络架构,该架构通过层次标签树对节点信息进行编码。将Graphormer与文本编码器BERT和Doc2Vec相结合,以有效整合层次信息和文本信息,这种融合为层次分类任务带来了显著的性能提升。
1.5 对比学习
首先利用之前学习到的标签特征进行一个注意力的选择,得到Aij矩阵。Aij
代表每一个不同的token对相应标签的贡献概率,并通过Softmax函数得到一个概率分布。给定一个特定的标签,就可以从这个分布中抽取token并形成一个正样本。设定了一个阈值γ,用于确定采样的token。如果某个token对不同标签的影响概率超过这个阈值,就将其判定为属于该标签的正样本。负样本的构建过程是将学习到的真实样本以及相应的正样本组成N个正对(hi,i),对其添加一个非线性层,
ci=W2ReLU(W1hi),(5)
i=
W2ReLU(W1i),(6)
式中:W1∈Rdh×dh,W2∈Rdh×dh,dh为隐藏层层数。
对于每个正对,有
2(N-1)个负例。对于2N个例子Z={z∈{ci}∪
{i}},采用NT-Xent损失函数强迫正、负例之间的距离变大,计算zm的NT-Xent损失,可表示为
Lconm=-logexp(sim(zm,
μ(zm))/τ)
∑2Ni=1,i≠m
exp(sim(zm,zi)/τ),(7)
式中:τ为温度超参数;sim为余弦相似函数,sim(u,v)=u·v/(‖u‖‖v‖);μ为匹配函数,并且
μ(zm)=
ci,if
zm=i,
i,if
zm=ci。(8)
总对比学习损失为所有例子的平均损失,可表示为
Lcon=12N∑2Nm=1Lconm。(9)
1.6 输出层与损失函数
将多标签分类的层次结构扁平化,把隐藏的特征输入线性层,并使用sigmoid函数计算概率。将特征融合得到的语义信息进行概率转换,输出文本i出现在标签j上的概率,从而得到模型的预测结果,可表示为
pij=sigmoid(whi+b)j,(10)
式中:w为权重系数;b为偏置项;
hi为特征向量;pij为预测概率。
对于多标签分类,对标签j上的文本i使用一个二元交叉熵损失函数,可表示为
LCij=-yijlg(pij)-(1-yij)lg(1-pij),(11)
LC=∑Ni=1∑kj=1LCij,(12)
式中:yij为样本的真实标签。
最终的损失函数是分类损失和对比学习损失的组合,可表示为
L=LC+λLcon,(13)
式中:λ为控制对比损失权重的超参数。
2 实验
2.1 实验准备
2.1.1 数据集
在WOS[10]、NYT[11]、RCV1-V2[12]和AAPD[13]数据集上进行实验,并采用多种指标对实验结果进行评价。WOS涵盖了Web of Science数据库中发表的学术论文摘要,AAPD则搜集了Arxiv学术论文的摘要以及对应的学科类别信息,而NYT和RCV1-V2都是新闻分类语料库。WOS用于单路径HTC,而NYT、RCV1-V2和AAPD包含多路径分类标签,数据集的标签为树状的层级结构。4个数据集的统计信息如表1所示。
2.1.2 实验设置
对于文本编码器,使用BERT和Doc2Vec模型,其中Transformer的bert-base-uncased作为基本架构。对于Graphormer,将自适应图注意力头设置为8,特征大小设置为768,batch size设置为16。选择的优化器是Adam,学习率设置为3×10-4。使用训练集对模型进行训练,每个轮次结束后对验证集进行评估,如果在连续6 个轮次中Macro-F1不增加,则停止训练。阈值γ在WOS上设置为0.02,在NYT、RCV1-V2和AAPD上设置为0.005。WOS、RCV1-V2和AAPD的损失权重λ为0.1,NYT的损失权重λ为0.3,对比模块的温度超参数固定为1。在PyTorch中实现模型,并在NVIDIA GeForce RTX 3090上进行实验。
2.1.3 评价指标
首先使用准确率、召回率、Micro-F1和Macro-F1来评估实验结果,其次引入了两个新的评价指标:层次Micro-F1(HMicro-F1)和层次Macro-F1(HMacro-F1)。这两个新指标与传统度量的区别在于,这些受约束的评价指标要求对于一个节点的预测结果被视为“真”,必须满足该节点在每个层次上的所有祖先节点都被预测为“真”。
2.2 实验结果
将本文提出的MHGCLR模型与经典模型以及其他目前主流的模型在WOS、RCV1-V2、NYT和AAPD数据集上进行对比实验。选择的基线方法包括TextCNN[14]、TextRNN[15]、TextRCNN[16]、FastText[17]、AttentiveConvNet[18]、TextVDCNN[19]、HTCInfoMax[4]、HBGL[20]和HiMatch[21]模型。
不同模型在4个公开数据集上的实验结果如表2和表3所示(最优结果加黑显示)。可以看出,MHGCLR模型在WOS、RCV1-V2、NYT和AAPD数据集上的准确率分别为90.66%、87.72%、85.71%和85.82%;Micro-F1值分别为87.32%、86.41%、78.92%和79.79%;Macro-F1值分别为81.54%、69.32%、67.61%和63.92%,相比其他模型具有更好的性能。在新的层次评价指标方面,MHGCLR模型依然表现良好,在4个数据集上的HMicro-F1值分别为85.75%、84.57%、74.67%和77.03%,HMacro-F1值分别为80.64%、67.51%、65.26%和60.04%,说明MHGCLR模型通过建模多尺度特征对层次间的依赖也产生了效果。
2.3 性能分析
首先进行消融实验,分别在有、无多尺度特征提取模块下进行实验,从而验证了模块的有效性。接着进行分层表现实验,观察模型在不同层次上的性能表现。
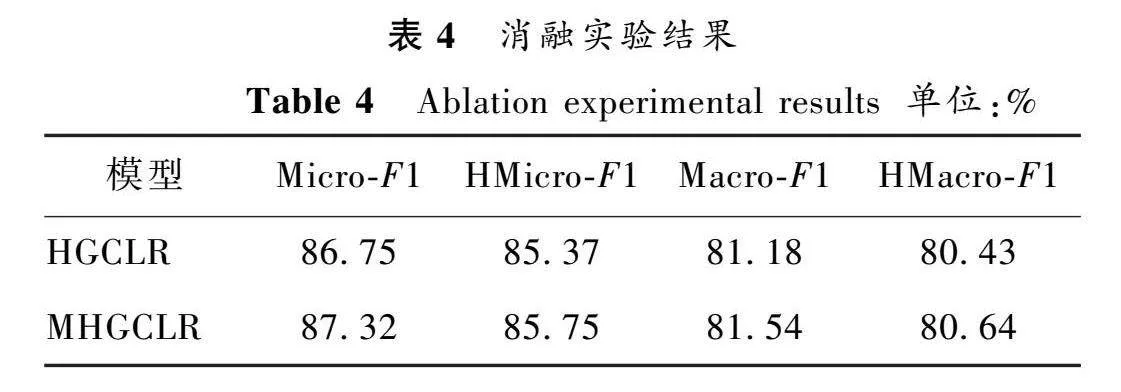
2.3.1 消融实验
在WOS数据集上进行消融实验,结果如表4所示。可以看出,有多尺度特征提取模块的MHGCLR模型的分类效果要优于无多尺度特征提取模块的HGCLR模型,其在Micro-F1和Macro-F1上分别提升0.57和0.36个百分点,而且HMicro-F1和HMacro-F1层次指标也略有提高。
2.3.2 分层表现实验
对每个层次的分类情况进行了分层输出,并将MHGCLR模型与其他模型的表现进行了比较。由于RCV1-V2数据集中存在部分少样本标签,故选择在具有3个层次的RCV1-V2数据集上进行实验。由于Micro-F1值对分布不平衡情况更为敏感,选用其作为对比指标,模型在不同层
次上的实验结果如表5所示。结果表明,MHGCLR模型在每个层次上都优于其他模型,并且在深层次上的性能明显优于其他模型。MHGCLR模型能够充分利用多尺度表征中学习到的知识,特别是在深层次的少样本标签分类方面表现出色。
3 结语
本文将多尺度特征提取和特征融合引入HMTC任务中,结合了Graphormer和对比学习工作,提出了MHGCLR模型。该模型可以提取不同尺度的特征,考虑了文本的多尺度性以及局部和全局之间的联系,从而提高了模型在HMTC任务上的整体性能。首先设计了多尺度特征提取模块,将文本划分为不同尺度并提取相应的特征,然后进行特征融合。这样做可以在浅层特征中提取词汇信息,在深层特征中提取更抽象的语义信息,从而更好地捕捉文本的层次化结构。在WOS、RCV1-V2、NYT和AAPD数据集上进行了对比实验,结果表明,该模型不仅在传统评价指标上取得了显著提升,而且在新提出的具有层次约束的评价指标HMicro-F1和HMacro-F1上的表现也超越了其他模型。未来的研究方向将着重于建模标签之间的关联性,以更准确地反映其层次结构和相关性。
参考文献:
[1] BANERJEE S, AKKAYA C, PEREZ-SORROSAL F, et al. Hierarchical transfer learning for multi-label text classification[C]∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2019: 6295-6300.
[2] CESA-BIANCHI N, GENTILE C, ZANIBONI L. Incremental algorithms for hierarchical classification[J]. Journal of machine learning research, 2006, 7: 31-54.
[3] ZHOU J E, MA C P, LONG D K, et al. Hierarchy-aware global model for hierarchical text classification[C]∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2020: 1106-1117.
[4] DENG Z F, PENG H, HE D X, et al. HTCInfoMax: a global model for hierarchical text classification via information maximization[C]∥Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: Association for Computational Linguistics, 2021: 3259-3265.
[5] HUANG W, CHEN E H, LIU Q, et al. Hierarchical multi-label text classification: an attention-based recurrent network approach[C]∥Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM Press, 2019: 1051-1060.
[6] ZHANG X Y, XU J H, SOH C, et al. LA-HCN: label-based attention for hierarchical multi-label text classification neural network[J]. Expert systems with applications, 2022, 187: 115922.
[7] WANG Z H, WANG P Y, HUANG L Z, et al. Incorporating hierarchy into text encoder: a contrastive learning approach for hierarchical text classification[C]∥Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2022: 7109-7119.
[8] 刘燕. 基于BERT-BiGRU的中文专利文本自动分类[J]. 郑州大学学报(理学版), 2023, 55(2): 33-40.
LIU Y. Automatic classification method for Chinese patent texts based on BERT-BiGRU[J]. Journal of Zhengzhou university (natural science edition), 2023, 55(2): 33-40.
[9] 曾立英, 许乾坤, 张丽颖, 等. 面向主题检索的科技政策扩散识别方法[J]. 郑州大学学报(理学版), 2022, 54(5): 82-89.
ZENG L Y, XU Q K, ZHANG L Y, et al. Identification method for subject retrieval of science and technology policy diffusion[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(5): 82-89.
[10]KOWSARI K, BROWN D E, HEIDARYSAFA M, et al. HDLTex: hierarchical deep learning for text classification[C]∥ Proceedings of the 16th IEEE International Conference on Machine Learning and Applications. Piscataway:IEEE Press, 2018: 364-371.
[11]BOWMAN S R, ANGELI G, POTTS C, et al. A large annotated corpus for learning natural language inference[C]∥Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2015: 632-642.
[12]LEWIS D, YANG Y M, ROSE T, et al. RCV1: a new benchmark collection for text categorization research[J]. Journal of machine learning research, 2004, 5: 361-397.
[13]YANG P, SUN X, LI W, et al. SGM: sequence generation model for multi-label classification[C]∥Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2018: 3915-3926.
[14]KIM Y. Convolutional neural networks for sentence classification[C]∥Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2014: 1746-1751.
[15]LIU X, WU J, YANG Y. Recurrent neural network for text classification with multi-task learning[C]∥Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: Association for Computational Linguistics, 2016: 10-21.
[16]LAI S W, XU L H, LIU K, et al. Recurrent convolutional neural networks for text classification[C]∥ Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press,2015: 2268-2274.
[17]JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification[C]∥Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2017: 427-431.
[18]NEUMANN M, VU N T. Attentive convolutional neural network based speech emotion recognition: a study on the impact of input features, signal length, and acted speech[C]∥ IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2017: 1972-1976.
[19]CONNEAU A, SCHWENK H, BARRAULT L, et al. Very deep convolutional networks for text classification[C]∥Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2017: 1107-1116.
[20]JIANG T, WANG D Q, SUN L L, et al. Exploiting global and local hierarchies for hierarchical text classification[C]∥Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2022: 4030-4039.
[21]CHEN H B, MA Q L, LIN Z X, et al. Hierarchy-aware label semantics matching network for hierarchical text classification[C]∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2021: 4370-4379.
