微博垃圾用户行为研究
2024-12-31高郭威赵卫东孙中全


摘要:垃圾用户作为垃圾信息的传播者,一直是微博反垃圾研究的重点,现有的垃圾用户检测研究还局限于传统的二值分类问题上,只是将用户简单地判断为垃圾用户和正常用户。然而,微博平台中的垃圾用户类型多种多样,将各类垃圾用户按照单一类别垃圾用户进行处理,会存在各类垃圾用户之间特征相互影响的问题,从而降低整体检测效果。为了解决上述问题,文章对各类垃圾用户行为进行了分析。首先,根据垃圾用户的行为目的和行为模式,将垃圾用户分为4类;其次,通过爬虫程序获取数据集,构造特征分析样本集并进行标注,计算用户的各项统计特征;最后,对4类垃圾用户的特征进行定量分析,归纳总结出每类用户的特点。实验结果表明,各类垃圾用户与正常用户之间存在区分度较高的相关特征,利用这些特征能够有效区分各种垃圾用户与正常用户,提升检测精度。
关键词:微博;垃圾用户;用户行为;用户分类
中图分类号:TP393.092" 文献标志码:A
基金项目:2022年安徽省高校自然科学研究重大项目;项目编号:2022AH040332。安徽省职成教项目;项目名称:后疫情时代基于OBE理念的高职公共基础课程混合式教学模式的构建与实施;项目编号:Azcj2022178。安徽省职业与成人教育学会教育科研规划课题;项目编号:Azcj2022180。
作者简介:高郭威(1991— ),男,助教,硕士;研究方向:大数据,网络安全。
0" 引言
最早的微博平台是由美国人W. Evan创建的Twitter,国内最知名的微博平台要数新浪微博,因此本文的研究和实验数据都来自新浪微博。与传统互联网中垃圾问题的单一性不同,微博平台中的垃圾问题存在多种特性。垃圾问题从垃圾的类型分可以分为垃圾微博和垃圾用户。垃圾用户在分类上与其他平台不同,具有突出的目的性,表现出来的特征十分明显。微博平台须要根据不同类型的垃圾用户行为,针对性地给出不同的处理方案,这更加有利于对垃圾用户的管理,也能够更好地针对不同用户制定行为规范准则。
1" 微博垃圾用户存在的问题及解决方案
微博平台[1]作为一个开放、高效、即时的传播媒介,吸引了大量的微博垃圾用户,其中包括诸多垃圾用户行为。现阶段的微博垃圾问题层出不穷,垃圾行为也越来越多样与复杂。传统的基于垃圾用户特征分析的机器学习检测方法大多是对全局的垃圾用户进行分析,也就是传统的二值分类问题,即垃圾用户和正常用户。通过对垃圾用户的深入分析,本文发现垃圾用户的行为目的不同,所表现出来的垃圾行为模式也不尽相同,然而大多数的垃圾用户检测都缺乏针对某类特定垃圾用户的行为分析研究,这样往往会使得某类垃圾用户逃避检测系统的检测。
在微博垃圾用户行为分析中,范雨萌等[2]提出了一种利用新浪微博的用户行为对垃圾用户进行检测的方法,将用户分为过度广告恶意用户、过度关注恶意用户和重复转发恶意用户。在对现阶段垃圾用户进行分析[3]的过程中,发现有些垃圾用户行为已经很少存在,同时也出现了新的垃圾行为。针对现在的微博平台,上述的划分标准就会显得不那么合理。
因此,为解决上述问题,本文利用网络爬虫程序[4]对微博用户数据进行爬取,分析了现有微博用户的垃圾行为,设计了一种垃圾用户分类方法。该方法根据垃圾用户的行为目的和行为模式将垃圾用户分为4类,然后针对每一类垃圾用户进行特征分析,为更准确地检测垃圾用户提供行为特征依据。垃圾用户由于目的各不相同,会呈现多种多样的垃圾行为,如果只是简单的二值分类,往往会造成特征维度过高的情况,而多分类特性分析,会针对各类垃圾用户的最显著特性进行分析,从而减低了特征维度,达到降维目的。
2" 微博垃圾用户分析
通过对新浪微博平台中的各类用户[5]进行观察,本文发现由于各类垃圾用户的目的不同或者技术和资金投入的不同,他们采用的行为策略也存在差别,呈现的垃圾行为也不尽相同。对垃圾用户的分类可以更好地找出区分度高的垃圾用户特性,这些区别度高的特征是设计检测方法须要考虑的重要因素之一。如果不对这些用户进行区分,就可能存在2类垃圾用户的某些特征相互矛盾的情况,因此,对垃圾用户进行分类十分有必要。
根据垃圾用户所采取策略的不同,本文把垃圾用户分为2个大类:主动策略和慎重策略。在这2类策略的导向下,垃圾用户表现出了不同的行为特点。
2.1" 主动型垃圾用户
主动型垃圾用户为了达到目的,会采取最简单粗暴的方法进行推销、诈骗等行为。他们都选择主动去骚扰用户,不对自己做任何保护措施,也不怕被其他用户举报或是被微博官方直接封号。他们的运营成本比较低,发布垃圾信息之后就会被抛弃或者是被封号,只要有少数用户上当受骗就达到了目的。此类策略下的垃圾用户主要有2种:
2.1.1" 主动骚扰型垃圾用户
这类用户的行为特点是几乎每条微博都会提及其他用户,即发布带有“@”符号的微博,提及的用户并不是他的好友,也不在关注列表里面。
2.1.2" 过度关注型垃圾用户
目前普通用户的关注上限是2000,过度关注型垃圾用户的最大特点是会大量关注其他用户。许多过度关注型垃圾用户的关注数甚至快要逼近关注上限,相反,他们自己的粉丝数量却很少。
2.2" 慎重型垃圾用户
相比于主动型垃圾用户,慎重型垃圾用户采取的行为策略更为保守,垃圾行为也更有组织性。此类策略下的垃圾用户主要有2种:
2.2.1" 重复发送型垃圾用户
该类垃圾用户比较典型的垃圾行为是发送或者转发大量内容相同或者相似的垃圾信息。
2.2.2" 营销广告型垃圾用户
该类垃圾用户在经过几代演变之后,其行为已经和正常用户十分相似,在微博平台上的数量也最多。为了宣传产品,该类垃圾用户的微博中会含有产品图片和产品URL链接,图片和URL链接会与之前的内容十分相似。然而,区别于重复发送型垃圾用户,他们的正文往往不会相似度很高。
3" 微博垃圾用户爬取
3.1" 微博垃圾用户收集方式
现阶段的微博用户获取方法[6]一般有3类:利用蜜罐吸引用户、直接购买用户和利用爬虫程序爬取用户。
蜜罐是一种主动安全技术,设置一个专门让黑客攻击的系统,用来记录黑客的活动,帮助了解黑客的信息,发现潜在的威胁。微博蜜罐程序与传统的主动型蜜罐不同,相当于一个诱饵程序,目的是吸引垃圾用户去关注它。Webb等[7]设置了51个蜜罐账户,这些账户注册了之后,不发布微博也不关注其他账户,只等其他用户的关注。在经历了4个月之后,他们共获得了1570个恶意用户的关注。这类收集方式的时间跨度大、效率低,不适合短时间内大量获取垃圾用户。
由于微博营销[8]的不断升温,出现了很多微博营销类的服务。他们提供“粉丝”购买,用户可以在花费一定费用之后,获得粉丝的关注,提高自己的关注度。此方法虽然可以短时间内获得大量垃圾用户,但是垃圾用户种类单一,不利于垃圾用户行为分析。
微博爬虫[9]是时下最热门的微博数据获取技术,能够快速、准确地获得微博数据。微博爬虫一般有2种形式:微博平台提供的开放API和网页爬虫技术。虽然各大平台都提供了API,但是为了防止过度调用,平台对API的调用次数都做了限制。新浪微博提供的API只能下载已授权用户的最近几条微博信息,而这些信息对于垃圾用户检测研究而言是远远不够的。因此,本文采用网页爬虫技术对新浪微博用户数据进行爬取。
3.2" 微博爬虫
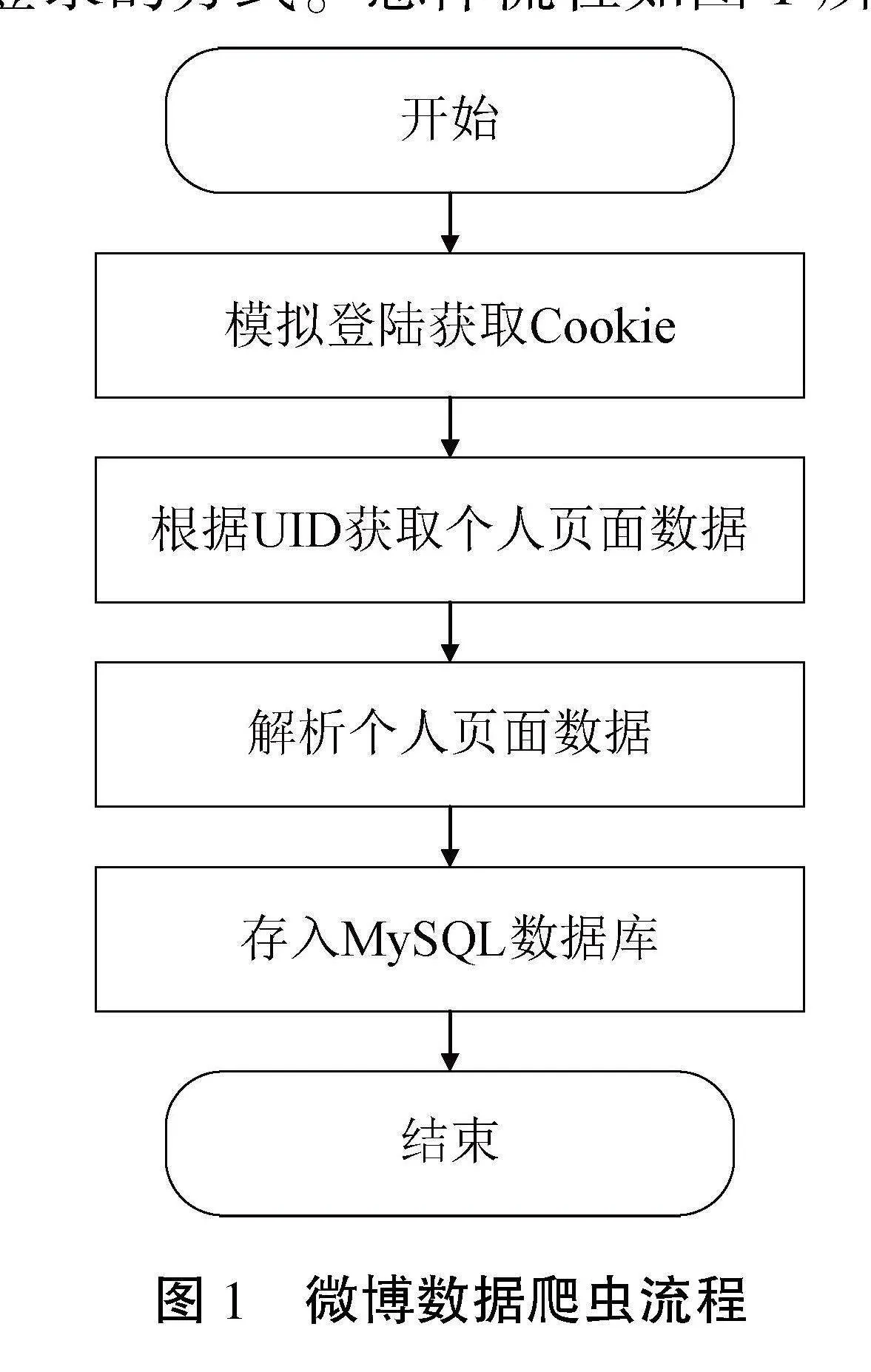
本文采用的网页爬虫方法是UID(User IDentification)遍历爬取策略。UID就是新浪微博提供给每一个用户的ID号,唯一对应且不会改变。UID遍历全网爬虫的算法是根据指定的UID段去爬取微博用户数据。该UID爬虫程序包括3个模块:模拟登录、网页爬虫和网页内容解析。首先根据新浪微博的特点,本文实现程序对微博网页的模拟登录;接着通过HTTP协议使用GET方法采集网页数据并对该数据进行解析。这种方法通过模拟正常用户使用浏览器客户端浏览微博的过程,不依赖于微博平台开放API,可以根据自己的需求灵活改变爬取数据字段。为了获得真实可靠的UID,本文从爬盟中国提供的新浪微博用户数据集中获取UID,作为参数输入。为了能够让程序能够通过微博页面的用户登录认证,本文采取模拟登录的方式。总体流程如图1所示。
具体流程如下:
(1) 模拟登录微博平台;
(2) 根据给定的UID访问用户的微博信息界面;
(3) 将微博界面信息爬取下来;
(4) 采用网页解析技术提取出页面中的信息,包括用户名、性别、地址、关注数、粉丝数、微博数以及微博内容等;
(5) 将信息存入数据库;
(6) 程序结束。
3.3" 微博用户数据集
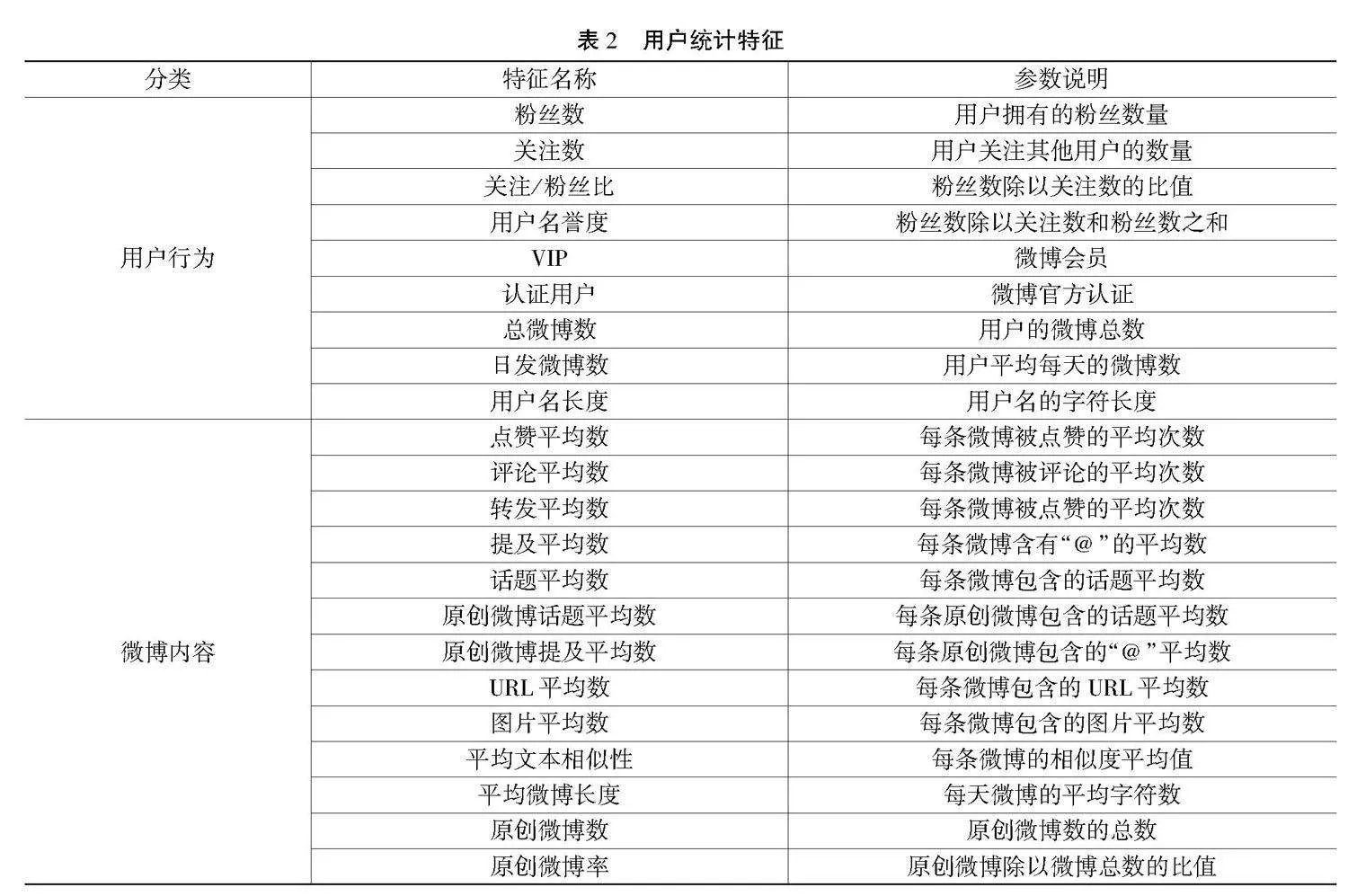
在实际爬取过程中,本文通过解析微博用户网页内容,可以获取包括用户名、用户ID、微博数、关注数、粉丝数、近50条微博内容、点赞数、转发数和评论数等15个字段信息。本研究中这些字段来自20000多名用户的个人信息及其发表的149090条微博信息,这些数据被保存到MySQL数据库。
4" 获取微博垃圾用户的行为特征
4.1" 样本处理
微博垃圾用户检测的最终目的是利用微博的统计特征构建分类模型,完成垃圾用户分类。首先对微博用户进行标注并将爬取的字段信息处理为计算机可以识别的统计特征。为了便于测试,本文在数据库中随机抽样了6500名用户并对这些用户完成标注工作。为了获取客观、准确的标注结果,本文根据4类垃圾用户的分类标准对样本进行标注,其中正常用户标注为0,营销广告型垃圾用户标注为1,重复发送型垃圾用户标注为2,过度关注型垃圾用户标注为3,主动骚扰型垃圾用户标注为4,无法确定或者被系统封掉的账号标准为5。其次,本文选择多名标注者给出一致标注值的用户账号,去除不确定的用户账号,得到用来进行特性分析的样本集合(见表1)。其中,主动骚扰型垃圾用户105人,过度关注型垃圾用户103人,重复发送型垃圾用户338人,营销广告型垃圾用户892人,正常用户4377人。
本文从垃圾用户的社会关系特征、微博活跃性特征以及微博内容特征这3个方面计算用于分析用户行为的特征值。社会关系特征统计量主要是粉丝数量、关注数量以及相互之间的比例,能够体现微博用户在微博平台的社会关系;微博活跃性特征统计量主要是用户发布的微博总数、每日平均微博数量等,能够体现出微博用户的活跃程度;微博内容特征统计量主要是与微博内容相关,比如微博正文中的图片数量、URL数量、“@”数量以及文本相似度等。前2类特征属于用户行为上面的特征,后者属于与微博内容相关的特征。本文以关注/粉丝比例特征和平均文本相似度特征为例,介绍一下相关特征的计算方法。
关注/粉丝比例的计算公式如公式(1)所示。
reputation(u)=NFollowersNFollowees(1)
式中,NFollowees为用户u的关注数;NFollowers为用户u的粉丝数。
本文选择向量空间余弦相似度(Cosine Similarity)来计算微博中的文本相似度。首先,对微博文本进行预处理,主要是对文本进行中文分词和去停用词;然后,对文本特征项进行选择与加权并把文本简化为以特征项(关键词)的权重为分量的N维向量表示,用D(Document)表示文本,用T(Term)表示特征项,则文本可以表示为D(T1,T2,T3,…,Tn),那么计算2个文本直接的相似度公式如公式(2)所示。
Sim(D1,D2)=∑nk=1W1k×W2k∑nk=1W1k2∑nk=1W2k2(2)
式中,D1,D2 为微博文本;W1k,W2k为D1,D2的第k个特征项的权值,1≤k≤N。
最后计算出22个特征值,如表2所示。
4.2" 垃圾用户特征分析
为了找出4类垃圾用户与正常用户之间区分度较高的特征,本文利用累积分布函数(Cumulative Distribution Function,CDF)来绘制4类垃圾用户的CDF曲线。CDF可以完整描述一个实数随机变量的概率分布,是概率密度函数的积分。用密度函数表示为:
F(x;μ,σ)=1σ2π∫x-∞exp-(x-μ)22σ2dx(3)
式中,x为随机变量;μ为随机变量数学期望;σ为标准方差。
每一条CDF曲线代表了一类垃圾用户的某一个统计特征的数据分布,CDF曲线上的X值表示该统计特征的一个值,CDF曲线上的Y值表示统计特征小于这个值的该类样本占该类样本总数的比值。因此,通过绘制CDF曲线,本文可以很直观地找出4类垃圾用户在同一个统计特征上面的数据分布差别,这正是须要寻找的“区分度”。
本文利用上一节中的样本数据,采用MATLAB软件绘制4类垃圾用户和正常用户的全部特征并选择了部分有代表性的特征来进行分析。
4.2.1" 用户行为特征分析
首先,有关用户行为的2类典型特征为日发微博数和关注/粉丝比。相比于其他4类垃圾用户,正常用户每日发布的微博数明显少于垃圾用户,这是因为微博平台对于正常用户而言更多的是作为一个信息接收平台而非信息发表的平台。营销广告型和重复发送型垃圾用户为了达到宣传和扩散的目的,须要大量发送微博,因此,他们的每日发布数很高,活跃度也最高。过度关注型垃圾用户是以关注其他用户为目的,每日发布微博数相对较少。
过度关注型垃圾用户的粉丝/好友比例最高,这是由于该类垃圾用户会大量关注其他用户,而很少得到其他用户的关注,导致关注数很高而粉丝数很低。主动骚扰型垃圾用户的关注数和粉丝数都很低,因此,粉丝/好友比例也低。慎重型的2类垃圾用户一方面为了提升自己的可信度会购买僵尸粉来增加自己的粉丝数,另一方面也须要经常经营维护自己的微博,建立了固定的好友群体,因此,关注/粉丝比例也比较低。
4.2.2" 用户微博内容特征分析
用户微博内容的6类典型特征为URL平均数、话题平均数、提及平均数、平均文本相似性、图片平均数以及点赞平均数。
(1)URL平均数。
主动骚扰型垃圾用户的URL链接数最多,就是为了利用“@”用户来点开微博中的链接,这类链接多为垃圾广告和钓鱼链接等。重复发送型垃圾用户的URL链接数也较多,此类链接多为推广页面,为了增加宣传力度。正常用户的URL链接明显少于其他4类垃圾用户,一般情况下微博中不会含有URL链接,最多也不会超过1条URL链接。
(2)话题平均数。
正常用户微博中的话题数量较少,而重复发送和营销广告类垃圾用户为了宣传推广会在微博中添加热点话题来吸引正常用户阅读,属于蹭热点的典型行为。
(3)提及平均数。
主动骚扰型垃圾用户为了骚扰用户,会大量利用“@”来提及用户,微博中的“@”数量明显高于其他用户。重复发送型垃圾用户由于会重复转发他人微博,因此微博中一般也会含有1~2个“@”符号。
(4)平均文本相似性。
正常用户的文本相似性最低,过度关注型和营销广告型垃圾用户的文本相似性也比较低。主动骚扰型垃圾用户由于会发布相同带有URL链接的微博来提及用户,因此,相似度较高。重复发送型垃圾用户因为存在大量转发相同微博的打榜行为和发布相同内容的推广行为,所以文本相似度极高,90%的该类用户的文本相似性都超过了0.4,而90%正常用户的文本相似性都低于0.4。
(5)图片平均数。
主动骚扰型垃圾用户一般不存在推销的产品,图片平均数最少。营销广告型垃圾用户为了推广自己产品,会发布大量产品的照片来吸引用户,因此,图片数最多。
(6)点赞平均数。
4类垃圾用户和正常用户的点赞平均数没有明显区别,属于区分度低的一类特征值,这类特征在垃圾用户检测中的贡献度低,会被舍弃。
综合用户行为特征和微博内容特征,可以得出如下结论:(1)营销广告型垃圾用户会很好地经营自己的微博,他们的粉丝数量、微博数量会很高。此外,为了推销产品,其微博内容中还多含有产品图片、URL链接等;(2)重复发送型垃圾用户会大量发送和转发相同内容的微博,因此,文本相似度是其最重要的特征之一。此外,为了增加微博的曝光度,用户微博中会加入热点话题;(3)过度关注型垃圾用户的关注数量很高,而粉丝数量很少,这导致了其关注/粉丝比会远远高出其他类型的垃圾用户,与积极的关注行为相反,这类垃圾用户的微博数量较少;(4)主动骚扰型垃圾用户最明显的特征就是滥用“@”提及功能来骚扰正常用户,因此其微博中的“@”数量最多。由于此类垃圾用户的目的性较强,其微博内容中也多含有URL链接。
5" 结语
本文主要对垃圾用户的行为进行详细分析。首先,对微博平台上的垃圾用户进行长期的观察和研究,根据垃圾用户在实际行为中采取的策略不同,将垃圾用户分为主动策略型和慎重策略型。在这2类策略的导向下,又将垃圾用户细分为营销广告型、重复发送型、过度关注型和主动骚扰型。其次,为了对垃圾用户进行更有针对性的研究,本文采用一种基于UID遍历爬取策略的微博爬虫程序对新浪微博上的用户进行爬取,获得数据集。最后,本文对样本数据集中的4类垃圾用户进行定量分析,通过绘制CDF曲线找到了各类垃圾用户与正常用户和各类垃圾用户之间区分度较高的相关特征,证明了垃圾用户分类的现实意义。
参考文献
[1]黄卫东,程小香.基于微博平台的舆情参与主体情感强度研究[J].计算机技术与发展,2022(11):140-145.
[2]范雨萌,易秀双,倪石建,等.基于统计特征的微博垃圾用户检测系统研究[J].信息安全与技术,2019(9):20-25.
[3]杨倩雯.面向网络舆情管控的微博谣言用户识别研究[D].武汉:武汉大学,2019.
[4]何波.基于Python的新浪微博中爬虫程序维护方法[J].软件,2022(2):52-54.
[5]金茂辉.微博用户的个性特征及交互关系分析[J].环球首映,2021(6):234-236.
[6]刘希.基于半监督学习算法的微博水军识别方法研究[D].成都:电子科技大学,2022.
[7]WEBB S, CAVERLEE, PU C. Social honeypots: Making friends with a spammer near you[EB/OL].(2008-12-29)[2024-08-10].https://people.engr.tamu.edu/caverlee/pubs/webb08socialhoneypots.pdf.
[8]薛晓茹.微博营销下用户高影响力转发行为影响因素研究[D].大连:大连大学,2022.
[9]万朔.面向语料库的微博情感分析研究[D].南京:南京航空航天大学,2020.
(编辑" 王雪芬)
Research on the behavior of Weibo spammers
GAO" Guowei, ZHAO" Weidong, SUN" Zhongquan
(Chuzhou Polytechnic, Chuzhou 239000, China)
Abstract:" Spammer, as a disseminator of spam, has become the focus of Weibo’s anti-spam research. Existing research on spammer detection is confined to traditional binary classification problem, which is simply to determine the user for spammer and non-spammer. However, there are many types of spammers in the Weibo platform, if all kinds of spammers are considered as the same category, there will be the problem that spammers’ characteristics can affect each other, so that the overall detection performance decreases. To solve this problem, the behavior of many kinds of spammers is analyzed in this thesis. First of all, according to spammers’ behavior purposes and behavior patterns, spammers are classified into four categories. Secondly, the data sets are obtained by the crawler program, and a set of samples for analyzing the characteristics are constructed and labeled, then the statistical characteristics of users are calculated. Finally, the characteristics of the four types of spammers are analyzed quantitatively, and the characteristics of each type of users are summarized. The experimental results show that there are highly distinguishable features between various types of spammers and non-spammer, which can effectively distinguish various types of spammers and non-spammer and improve the detection accuracy.
Key words: Weibo; spammer; user behavior; user classification
