基于大数据技术的工业大数据高可用集群搭建设计与实现
2024-12-31张艳敏马晓涛杨冰倩吴卫宏赵滨




摘要:随着互联网技术在工业生产中广泛应用,工业互联网的发展突飞猛进。在工业生产中,企业为了对工业大数据进行更好的采集、分析和预处理,利用大数据技术搭建大数据集群来完成各个生产环节。基于Hadoop的高可用分布式框架已经成为很多企业在集群搭建中的首选。文章在基于高可用Hadoop组件基础上,搭建了Hive、HBase、Spark、Flink、Kafka等大数据生态系统中一些重要组件,用于对数据的存储、采集、抽取、清洗、预处理和分析等操作,帮助企业在生产过程中完善生产环节,提高生产效率。
关键词:工业大数据;Hadoop集群搭建;数据处理
中图分类号:TP311" 文献标志码:A
基金项目:2023年保定市科技计划项目;项目名称:基于高可用集群和随机森林算法的工业大数据分析平台;项目编号:2311ZG018。
作者简介:张艳敏(1985— ),女,讲师,硕士;研究方向:大数据技术,软件技术。
0" 引言
在工业生产过程中,各个生产环节产生的数据越来越多,这些数据大多是非结构化数据,传统的关系型数据库已无法满足对这些数据的存储与处理,因此,文章利用大数据技术原理搭建大数据高可用集群来实现工业大数据的采集与存储等操作,集群中包含大数据生态系统中一些常用的组件。在已搭建的集群中通过Spark技术实现对离线数据的抽取、清洗和预处理,利用Flink技术对实时数据进行分析与存储。整个生产过程在大数据集群环境中运转流畅,最终达到了为企业节约成本、创造更多有益价值的目的。
1" 系统整体设计
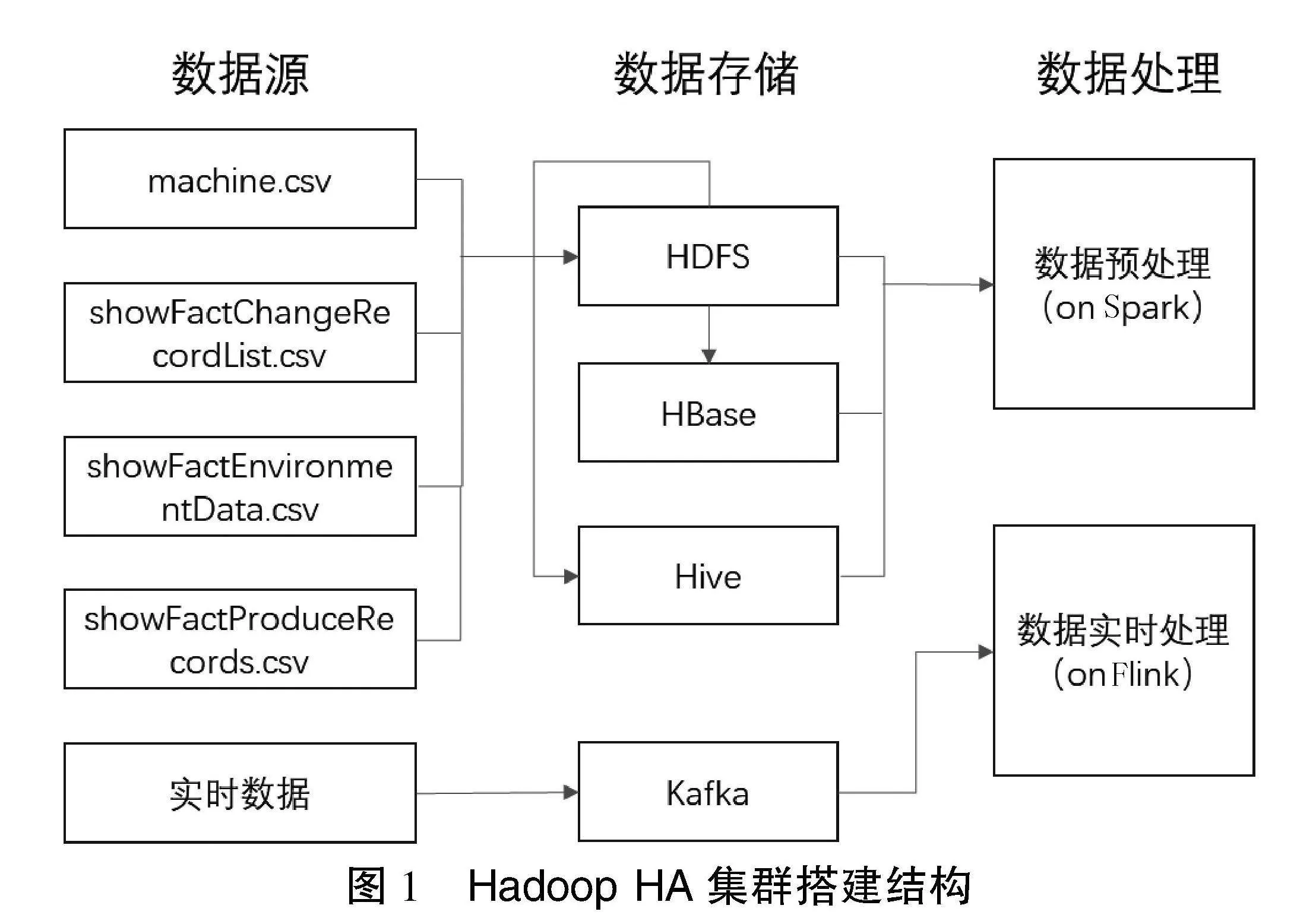
根据企业实际生产场景,本文搭建了基于Hadoop HA高可用的集群[1],集群中包含Hive、HBase、Spark、Flink、Redis和MySQL等组件,实现对工业生产中设备信息(machine.csv)、设备状态信息(showFactChangeRecordList.csv)、环境检测信息(showFactEnvironmentData.csv)和产品加工信息(showFactProduceRecord.csv)的采集和处理。其中HDFS、Hive和HBase等组件用来存储数据,Spark用来对离线数据进行抽取、清洗和预处理,Flink主要对实时生产数据进行计算和分析后存储到Redis或MySQL数据库中[2]。集群整体结构如图1所示。
2" 离线数据处理
离线数据处理是利用Spark技术对已经存储在数据库中的数据进行预处理,一般用Scala语言编写,通常包括数据抽取、清洗和指标计算等操作[3]。
2.1" 数据抽取
数据抽取包含全量抽取和增量抽取[3]。全量抽取是将源数据库中的所有数据抽取到目标数据库中,增量抽取是将自上次抽取后发生改变的数据从源数据库抽取到目标数据库中。
2.1.1" 全量抽取
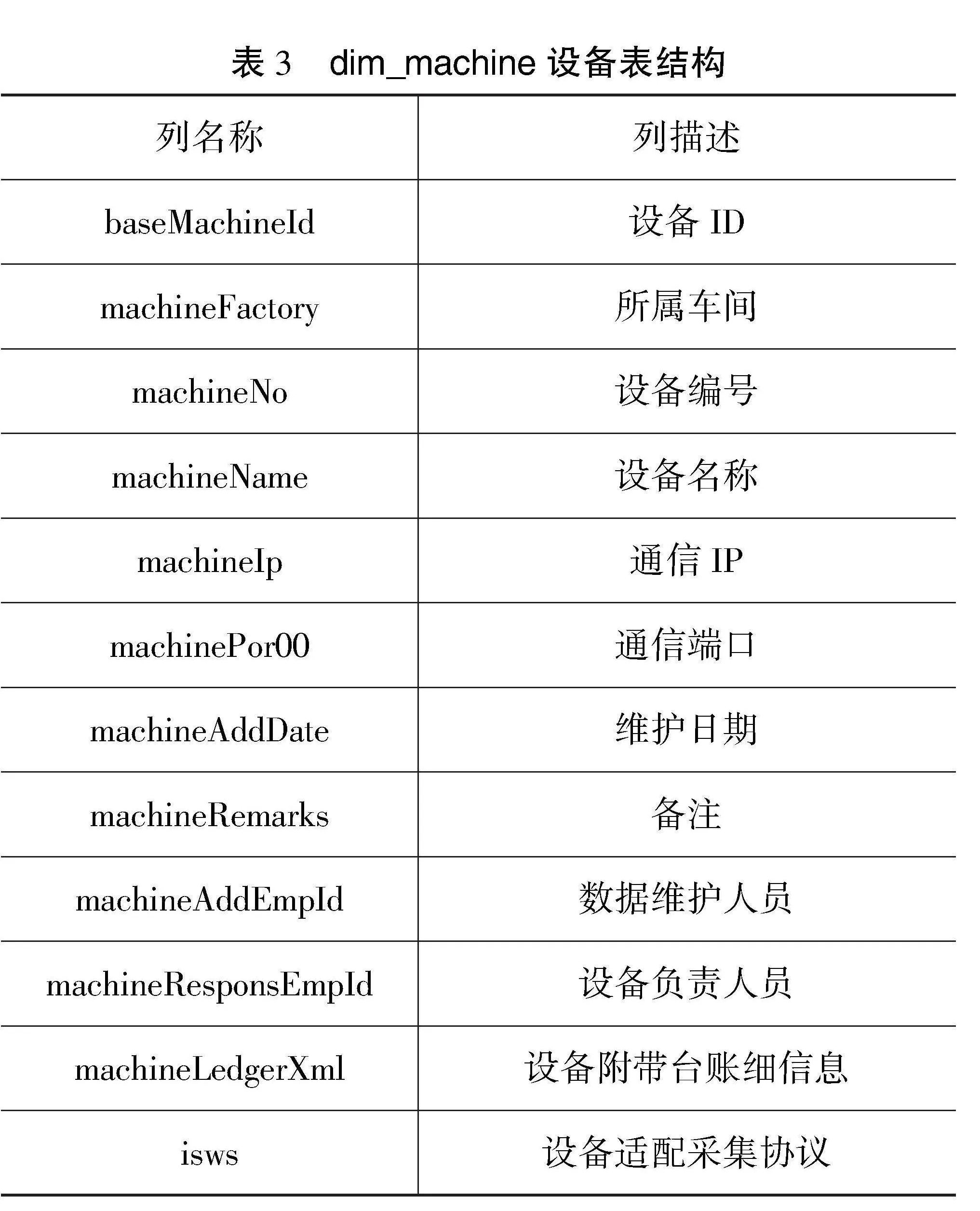
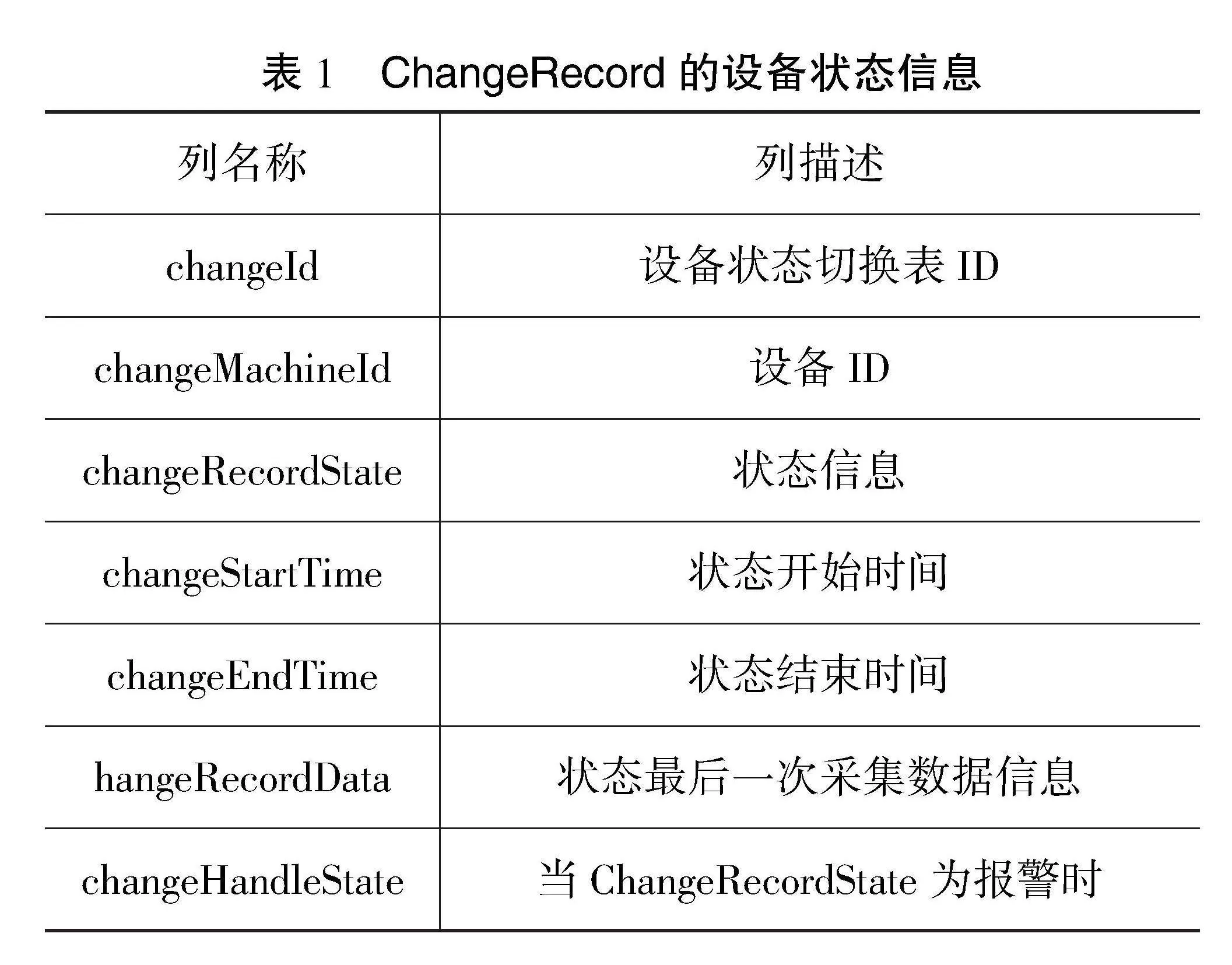
在生产过程中,研究人员通常会将数据从MySQL中抽取到Hive中,方便数据更高效的处理。MySQL中包括数据库shtd_industry,抽取shtd_industry库中ChangeRecord表的全量数据进入Hive的ods库,构成表changerecord,字段排序、类型不变;同时添加静态分区,分区字段为etldate,类型为String,值为当前日期(如20230702)。ChangeRecord的表结构如表1所示。
抽取操作执行完毕后,系统可以通过hive cli执行show partitions ods.changerecord命令查看分区结果,如图2所示。
2.1.2" 增量抽取
在企业生产过程中,有些数据只保留最新数据,例如环境监测表EnvironmentData(表结构如表2所示)中只保留每台设备的最新监测数据,在数据抽取时抽取MySQL中shtd_industry库的EnvironmentData表的增量数据;将其输入Hive的ods库中构成表environmentdata,将ods.environmentdata表中inputtime作为增量字段,仅将新增的数据抽入,字段排序、类型不变;同时添加静态分区,分区字段为etldate,类型为String,值为当前日期(如20230702)。
2.2" 数据清洗
在生产过程中,系统会产生大量的“脏”数据,数据清洗就是去除这些“脏”数据,通过筛选、过滤等操作使数据变得更加干净和准确[4]。数据清洗是数据处理过程中非常重要的一步,可以提高数据的质量和可信度,为后续的数据处理工作提供更有效安全的数据,例如对数据进行去重整合等操作。
在数据抽取中,系统将MySQL中数据抽取到Hive的ods库中,在数据清洗中将ods库中的changerecord全量数据抽取到dwd库表fact_change_record中,在抽取之前须要对数据根据changeid和changemachineid进行联合去重处理,并且添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time这4列。其中dwd_insert_user、dwd_modify_user均填写“user1”;dwd_insert_time、dwd_modify_time均填写当前操作时间。执行完毕后,系统使用hive cli按照change_machine_id、change_id降序排序,查询前1条数据,如图3所示。
2.3" 指标计算
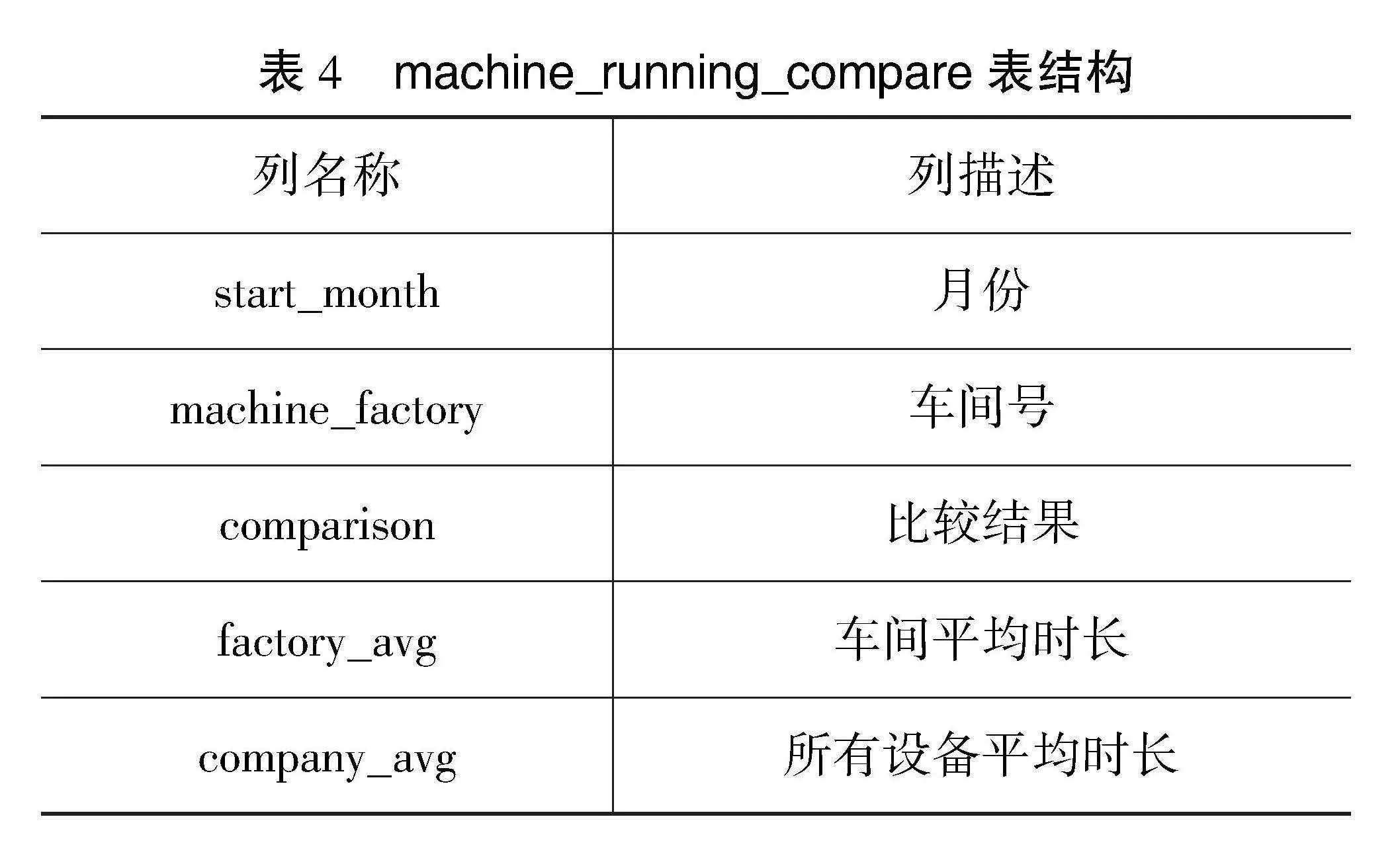
系统将清洗后的数据存入dwd库,进入指标计算。指标计算是企业根据业务需求对数据进行的针对性查询[5],通常是将多个数据源的数据集成到一个统一的数据存储库中。例如:系统使用Spark根据dwd层的fact_change_record表和dim_machine表统计,计算每个车间设备的月平均运行时长与所有设备的月平均运行时长对比结果(即设备状态为“运行”,结果值为:高/低/相同),计算结果存入MySQL数据库shtd_industry的machine_running_compare表中。dim_machine表、machine_running_compare表结构分别如表3和4所示。
3" 实时数据采集与处理
在工业生产过程中,系统除了对离线数据进行处理,还须要对实时数据进行处理。实时数据通过Flume采集后存储在Kafka消息队列中,再通过Flink读取Kafka中的流数据,对数据进行实时处理与分析,将结果存储到数据库中。
3.1" 实时数据采集
在主节点中,系统使用Flume采集/data_log目录下实时日志文件中的数据,将数据存入Kafka的Topic中(Topic名称为ChangeRecord,分区数为4)[6],Flume采集ChangeRecord主题的配置如图4所示。
3.2" 实时数据处理
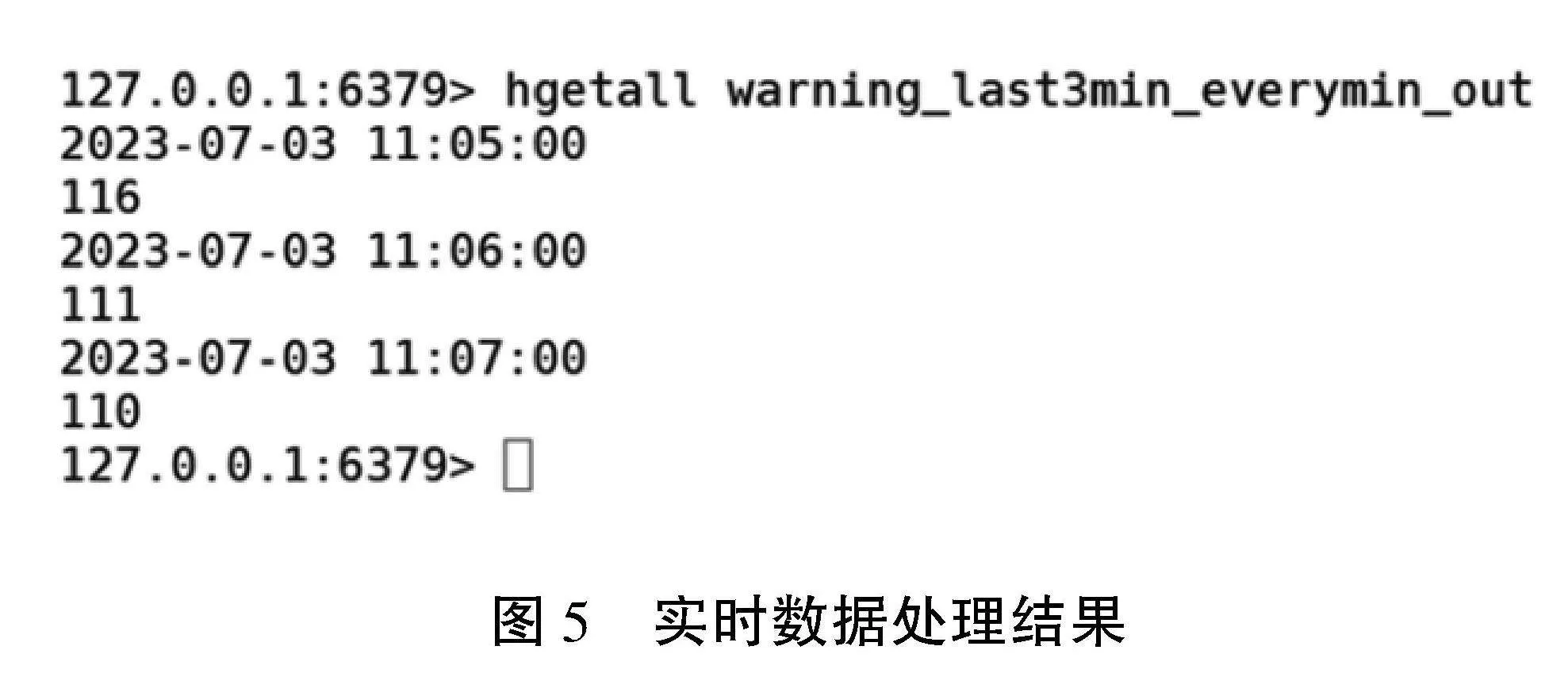
当实时数据采集完毕后,系统使用Flink消费Kafka中ChangeRecord主题的数据[7],例如每隔1 min输出最近3 min的预警次数最多的设备,将结果存入Redis,key值为“warning_last3min_everymin_out”,value值为“窗口结束时间,设备id”。本文使用redis cli以HGETALL key方式获取warning_last3min_everymin_out值,如图5所示。
4" 结语
文章介绍了工业大数据高可用集群搭建的整体架构,在此基础上实现了离线数据处理以及实时数据的采集和处理。系统在离线数据处理中采用数据抽取、清洗和指标计算;在实时数据中使用Flume采集数据到Kafka中,再通过Flink技术进行计算后将结果存入Redis。整个流程来自真实的企业生产过程。本文将大数据技术应用到企业生产中,为企业生产效率提高、转换提供了有效价值。
参考文献
[1]刘晓莉,李满,熊超,等.基于Hadoop搭建高可用数据仓库的研究和实现[J].现代信息科技,2023(1):99-101.
[2]黎心怡,夏梓彤,庄嘉濠,等.基于大数据技术的实时轨道交通分析预测可视化系统的设计与实现[J].电脑知识与技术,2023(29):71-74.
[3]郑倩倩.基于Kettle的工业数据集成与应用[D].重庆:西南大学,2023.
[4]谢文阁,佟玉军,贾丹,等.数据清洗中重复记录清洗算法的研究[J].软件工程师,2015(9):61-62.
[5]何文韬.基于Spark的工业大数据能效分析平台的设计与实现[D].大连:大连理工大学,2018.
[6]林子雨.数据采集与预处理[M].北京:人民邮电出版社,2022.
[7]林子雨,陶继平.Flink编程基础[M].北京:清华大学出版社,2022.
(编辑" 王雪芬)
Design and implementation of industrial big data high availability cluster construction based
on big data technology
ZHANG" Yanmin, MA" Xiaotao, YANG" Bingqian, WU" Weihong, ZHAO" Bin
(Hebei Software Institute, Baoding 071000, China)
Abstract: With the wide application of the Internet in industrial production, the development of industrial Internet is advancing rapidly. In industrial production, in order to assist enterprises in better collecting, analyzing, and preprocessing the industrial big data, it is necessary to build a big data cluster to complete various production processes using big data technology. Hadoop based highly available distributed frameworks have become the preferred choice for many enterprises in cluster construction. In the article, based on highly available Hadoop components,some important components in the big data ecosystem such as Hive, HBase,Spark, Flink,Kafka, etc." are built to store, collect, extract, clean, preprocess, and analyze data, helping enterprises improve production processes and increase production efficiency.
Key words: industrial big data; Hadoop cluster construction; data processing
