基于两阶段分类的虚假新闻检测研究
2024-12-31赵依然刘伟江马樱文







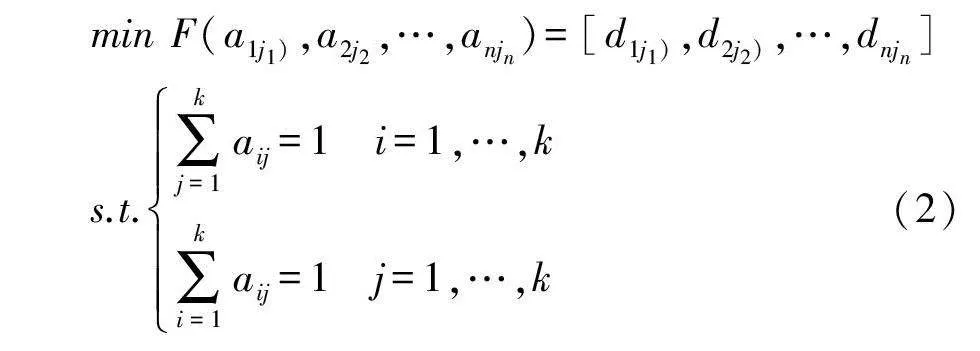

关键词:虚假新闻;多目标优化;Pareto有效;卷积神经网络;两阶段分类;减负训练;混合标签
DOI:10.3969/j.issn.1008-0821.2024.11.009
〔中图分类号〕TP391.1 〔文献标识码〕A 〔文章编号〕1008-0821(2024)11-0090-09
虚假新闻表现为虚构内容、篡改事实、捏造证据、误导引诱等多种形式交融的混杂状态。通过理论抽象可将虚假新闻划分为内容不实及文题不符两类,对新闻虚假性的判别本质上是处理两类混合标签。新闻数据的非结构化特征与混合标签结合形成了一种特殊的复杂背景,限制了分类模型的性能突破(ACC、F1、TPR和FPR难以同时兼顾)。针对这种情况,本文试图探索一个行之有效的方法使分类模型能同时在TPR和FPR两方面取得突破。
1相关研究评述
近年来,国内外对虚假新闻检测的研究可以归纳为以下3个方面:
在检测依据上,主要依据新闻内容[1-2]、用户信息[3]和传播结构[4]3类特征来进行识别。其中以新闻内容为依据的研究主要关注新闻中的内涵属性,包括所用材料的真实性、主题的契合性以及语言的恰当性等重要判据,而以用户信息和传播结构为主要依据来进行判别的研究更多考虑的是新闻外围因素而非核心内涵,因此无法有效地解释内容不实和文题不符两类混合标签;同时由于隐私政策和访问限制,数据获取方面也存在挑战,传播结构的不完整性可能导致路径的缺失,影响分析的准确性。
在识别方法上,监督学习、无监督学习、深度学习、卷积神经网络和知识图谱等方法被广泛用于对主题[5-6]和语言风格[7-8]等文本特征建模。监督学习可以更好地控制建模的方向和效果,深度学习[9]能更有效地抽象和理解特征信息,而卷积神经网络则可以利用信息交互识别出虚假新闻[10-11];无监督学习主要应用在对社交媒体和社交人物基本信息的提取与关联上[12],通过追踪和鉴别交互关系来构建新闻传播链特征[13]与检测模型[14];知识图谱则是通过借助新闻外部的背景知识特征进行内容的一致性检验[15]。上述方法在理论上是基于一个独立的标签来构建的,即假设标签在概念上是清晰的,表达的含义是单一的。面对虚假新闻标签中可能隐含的内容不实和文题不符两类标签[16],上述方法很难同时对两类标签进行分离和识别,这也是此类研究难以取得模型突破的主要原因。
在模型目标上,传统分类模型追求的是模型的精度和性能[17],而近年来建模目标有朝着模型可解释性转变的倾向,可解释性旨在通过人类能够理解的方式描述模型的内部结构和原理,这决定了模型的应用价值。这方面的研究主要包括:对抗神经网络和协同注意力网络用于对事件的关联[18]以及图像和文本的融合[19]来进行虚假新闻检测等。侧重模型的精度通常会牺牲模型的实用性,而在模型精度的制约下,模型的应用价值也难以获得释放,在保障模型应用价值的前提下提升模型精度是一个富有挑战性的课题。
2本文出发点
本文预期在识别精度和可解释性上对模型进行提升,在研究目标上既要给出识别虚假新闻的分类模型,也要提供判别内容不实和文题不符两类性质的方法和过程,以提高模型性能和应用价值。因此,本文设计了一个两阶段的识别过程,第一阶段侧重显性的文题不符类虚假新闻的识别,人们对这些新闻通常有明显的直观感受,这意味着此类新闻具有很强的显性特征,对于一则新闻而言,其主题、语义和情感是一个有机的整体,其协调性和匹配性是新闻评判的重要因素,好的新闻和真实的新闻其主题、语义和情感三要素在标题和正文上具有良好的匹配性,给读者以自然协调的直观感受,而正文和标题匹配程度越低,其协调性就越差,文题不符的特征就越明显。据此,首先对正文和标题的匹配性进行测度,然后在第一阶段依据Pareto有效性原理对文题不符类新闻进行筛选,同时为第二阶段的模型训练准备减负环境,在最大得失比的意义下尽可能清除文题不符类新闻对第二阶段训练的干扰;第二阶段集中识别隐性的内容不实类虚假新闻,在这一阶段采用异构图神经网络来增强模型的准确性,在现实场景中研究对象往往是多类型的,对象之间的交互关系也是多样化的。因此,异构图神经网络能够更好地贴近现实,同时图结构可以融合节点信息和关系,得到更加丰富的判别依据,以提供更好的技术性解释。
3技术路线
本文的目标是建立新闻N={n1,n2,…,nk}和判断R={虚假新闻,真实新闻}之间的映射L:N→R,通过两阶段过程来实现映射L,包括特征融合、差异矩阵计算、Pareto有效性识别、异构图构建和神经网络识别5个环节,如图1所示。
3.1特征融合和差异矩阵计算
新闻的核心三要素为主题、语义和情感。新闻的中心意图是主题,内容的表述形成语义,表达的方式体现情感。一则新闻由标题和正文两部分构成,三要素在标题和正文都会有所体现,其表达的一致性和相容性是新闻真实性的一个重要判别依据。文题不符类新闻为了吸引读者的阅读,往往采用诱导话术和炒作热点的手段去制造标题,导致在标题和正文之间会存在明显冲突,违背了相容性;而内容不实类新闻则在语义上与新闻事实不一致。为了度量标题和正文之间的一致性与相容性,本文采用余弦距离计算标题和正文特征向量间的差异值,余弦距离适合解决异常值和数据稀疏问题,适用于特征向量维度较多的情况,同时也能处理新闻文本模态单一的问题。
D=(dij)称为差异矩阵,差异矩阵的对角线代表一则新闻的标题和自己的正文之间的差异程度,称为自差异值,它是站在自身角度的一种绝对差异度量;矩阵中的其他元素为不同新闻的标题与正文之间的余弦距离,其中行列都是以不同的标题或正文作为参考点进行度量的。差异矩阵提供了绝对和相对两种度量结果以及对角线、行、列3个评价角度,包含了非常丰富的新闻标题与正文之间的关联信息,为判别虚假新闻提供了强大支撑。
3.2显性虚假新闻识别原理
根据差异矩阵可以匹配标题和正文:一则新闻的正文和标题所涵盖的内容应保持一致,如果一则新闻的标题恰好与自己的正文匹配(dii较小)就形成了自匹配;如果dii较大,就会由相对较小的dij决定互匹配。在互匹配下,一则新闻的标题没有与自己的正文匹配,说明该新闻的标题和正文一定在主题、语义和情感三要素上存在冲突,文题不符类虚假新闻的主要特征就会呈现。
匹配结果可以由1个多目标优化过程来决定:假设aij=1表示Ti与Cj匹配,否则aij=0,对全部新闻的整体匹配问题可表达为式(2):
上面的优化问题既是一个多目标优化,同时也是一个指派优化,其中自匹配数量最多的Pareto有效解称为最佳匹配。Pareto有效性原理可以保障最佳匹配具有如下性质:
1)任何一个自匹配的改变必然损伤其他自匹配,因此最佳匹配是不可被改进的,不可能有其他匹配比“自己与自己匹配”的效果更好、更合理。
2)如果一则新闻没有达到自匹配,就意味着该新闻标题和正文之间存在冲突,在Pareto有效解的意义下可归类为文题不符。
Pareto有效性原理本质上[23]是在多个目标之间权衡取舍,以实现资源分配的最优状态。基于Pareto有效解评估虚假新闻,是相对意义下的筛选过程,具备一定客观性和动态自适应性。
3.3第一阶段:显性样本识别
Pareto有效性原理奠定了通过差异矩阵匹配新闻标题和正文的理论基础。但在大样本情况下,差异矩阵的规模巨大,计算复杂度呈指数型增长,限制了其应用范围和价值的发挥,因此需要找到一个简明的、合理的近似计算过程。Pareto有效性原理揭示了文题不符类的虚假新闻会以较大的概率形成互匹配,其自差异值较高,互差异值较低;而文题相符类的真实新闻则会以较大的概率形成自匹配,表现为自差异值较低,互差异值较高。围绕这一中心思想,就可以充分挖掘差异矩阵中包含的丰富信息,得到Pareto有效解的近似计算方法。
大样本下的自差异值近似服从正态分布,在虚假新闻日益增多的情况下就会呈现厚尾分布,根据实际的分布适当截取厚尾部分,就可以用最小的代价得到上述多目标优化问题的近似有效解,对此本文设计两种计算方法来完成近似求解过程。
3.3.1基于自匹配信息的显性样本识别
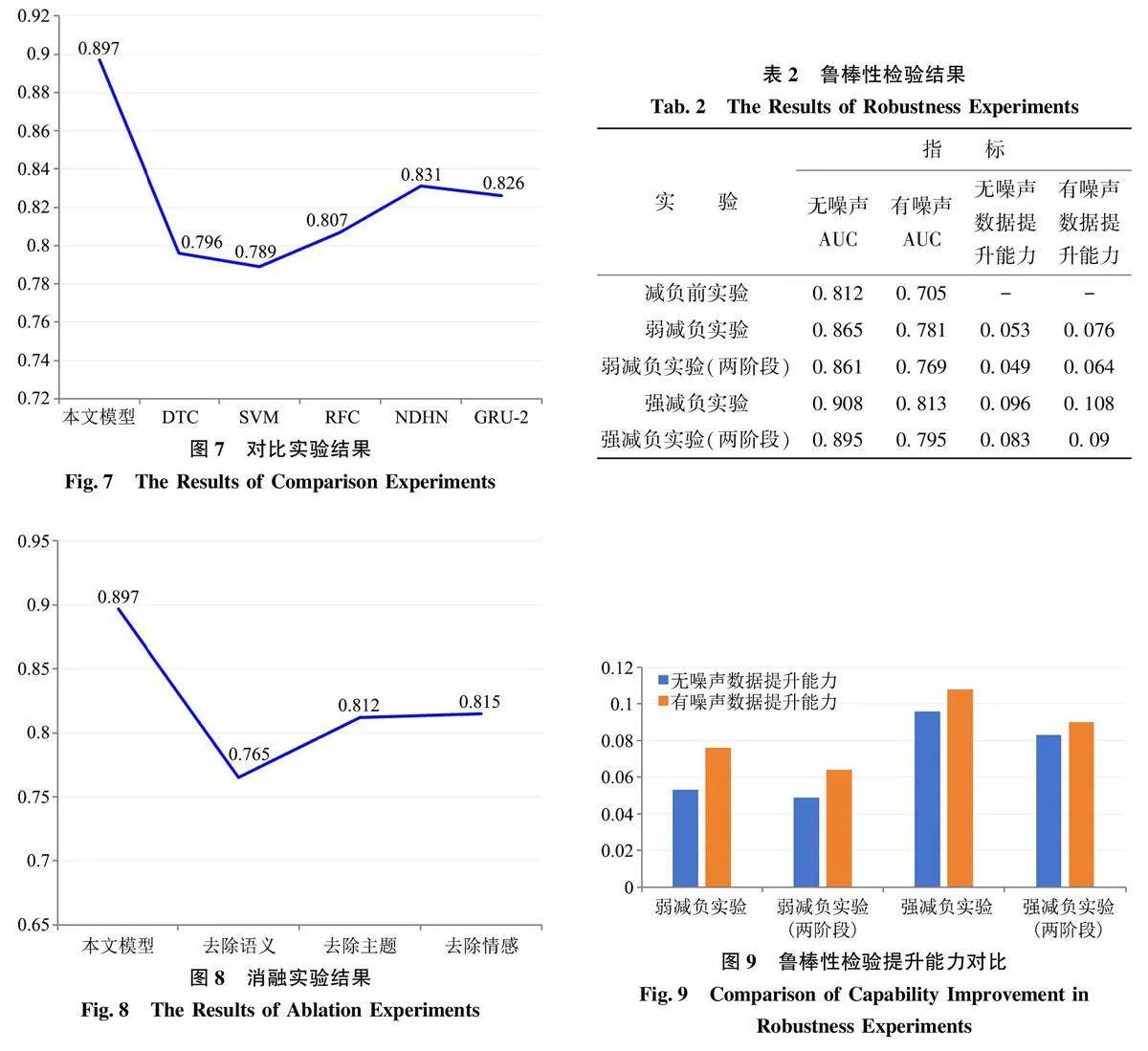
从自匹配角度来进行显性样本识别,主要利用差异矩阵的对角线信息进行分析,一则新闻的自差异值越高,其隶属于文题不符类新闻的可能性越大,在多目标匹配优化中能实现自匹配的概率就越低。本文测算了Fake News Corpus数据集的差异矩阵,得到主对角线上自差异值的分布,如图2所示。
在图2中,正样本明显呈现厚尾分布(可采用四阶中心距和Moment型估计量来判断厚尾的存在),则可用最大得失比来界定显性的文题不符类虚假新闻,以保障用较低的误识率来换取较高的准确率。根据上面分布得到筛选阈值为0.6(称为弱减负阈值),将差异值大于阈值的新闻识别为文题不符类虚假新闻,共筛选出1438个正样本和118个负样本,得失比为12.186∶1,其中正样本占全部正样本的比率为0.036,负样本占全部负样本的比率为0.003。将保留样本送入异构图神经网络进行下一阶段的识别,避免了匹配较差的新闻对全局信息和训练过程产生的负面影响。
4实验
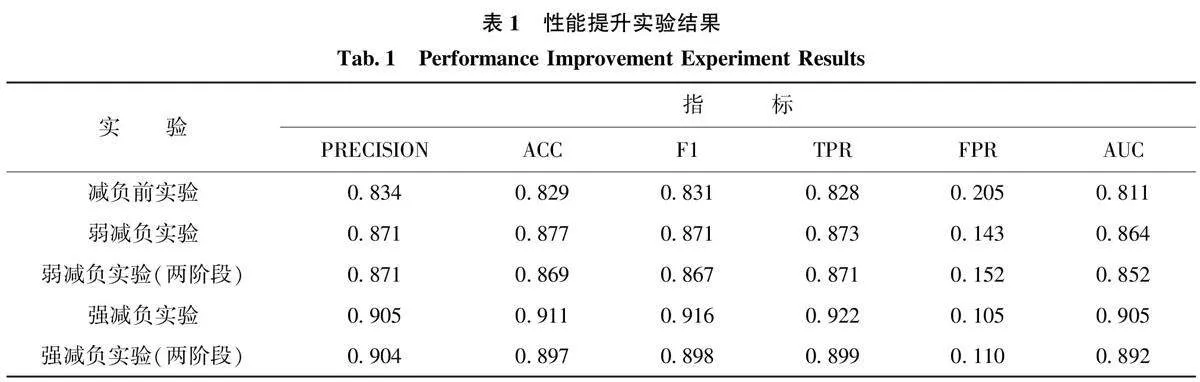
在FakeNewsCorpus新闻数据库[26]中选择Clickbait和Credible两种类别的新闻数据分别作为正样本和负样本,每类样本各选40000条,构成共80000条数据的平衡数据集,测试集和训练集按照6∶4进行划分。训练参数设置如下:
采用LDA模型提取主题特征向量(u=6),通过DistilBert模型得到语义特征向量(v=768),利用RoBERTa模型得到情感特征向量(w=28)。异构图卷积神经网络的隐含维度为512,层数设置为2,词嵌入维度为3741,BatchSize为64,正则化因子设定为0.00001,学习率设置为0.0001,Ep⁃och设置为100。
4.1性能提升实验
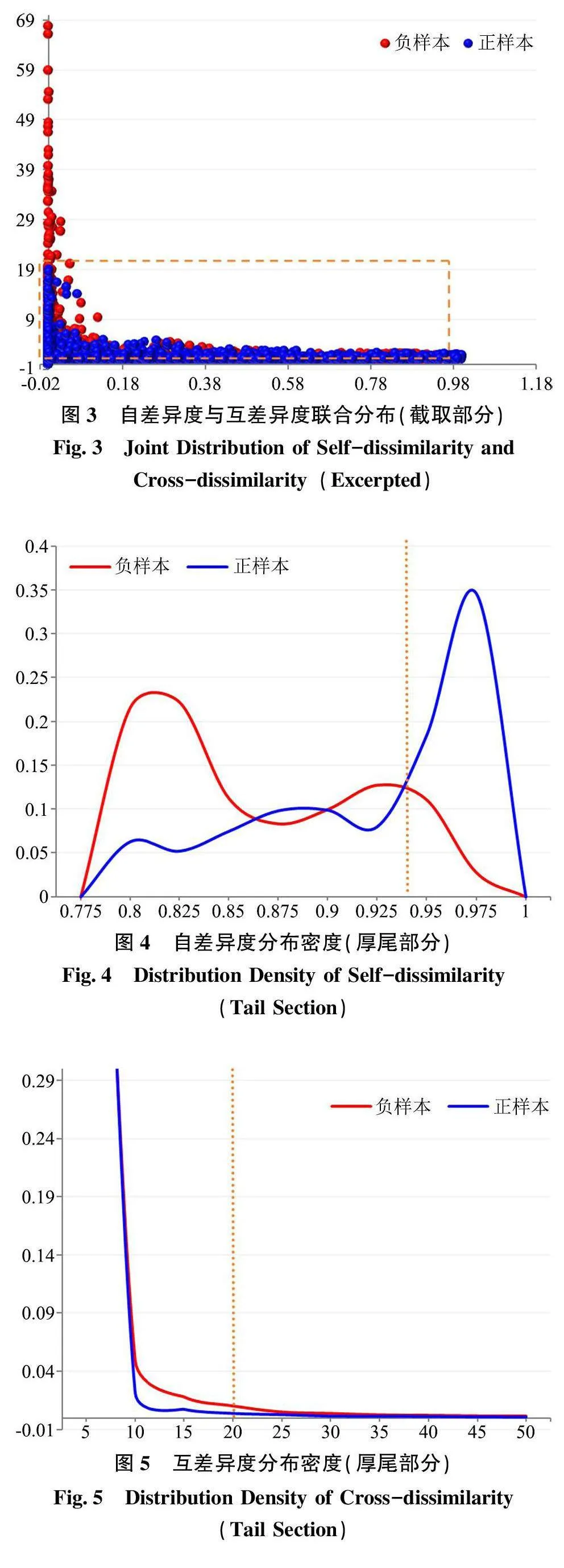
性能提升实验设计为以下3组实验,实验结果如表1所示,性能提升实验ROC曲线结果如图6所示。
1)用全部训练数据进行实验(称为减负前实验)。
2)用弱减负阈值剔除部分样本进行实验(称为弱减负实验),并将两阶段结果合并进行实验。
3)用强减负阈值剔除部分样本进行实验(称为强减负实验),并将两阶段结果合并进行实验。
实验结果表明,弱减负后FPR和TPR分别改进了0.062和0.045,神经网络在性能上得到提升。这主要来源于第一阶段剔除的正样本比率为0.036,而付出的召回率代价仅为0.003,从而减轻了神经网络拟合的负担;弱减负实验(两阶段)的综合模型结果与弱减负实验结果比较接近,呈现出性能上的总体提升,说明采用最大得失比来确定第一阶段的筛选阈值是应用Pareto有效性原理的较为经济的方式。从表1和图6中可以看出,强减负的效果比弱减负又有更大的性能突破。
4.2对比消融实验
将本文模型与DTC、SVM、RFC、NDHN和GRU-2[27]5种基线模型进行对比分析,得到准确率对比分析结果如图7所示。可以看出无论是传统机器学习方法还是深度学习方法,本文提出的虚假新闻检测模型在分类性能上均得到了较好提升,能够实现对社交媒体虚假新闻的有效识别。
为验证模型各因素的必要性,分别去除主题、语义和情感因素进行消融实验,观察因素缺失情况下模型的表现,如图8所示。结果表明,主题、语义和情感3个因素中任何一个因素的缺失都会导致模型性能表现的明显下降。这说明新闻三要素是分析和评判新闻性质的核心内涵,任何一个要素的缺失都会形成观察的片面性。
4.3鲁棒性检验
鲁棒性检验是衡量模型在异常输入或苛刻环境条件下是否能维持正常操作的关键环节。本文通过向模型引入噪声的方式,模拟了潜在的干扰场景,并系统地观察了模型性能的变化,以全面评估其抗干扰能力。具体而言,本文将原始数据集与10%的噪声数据混合,构建了对照数据集,并应用于模型的鲁棒性测试中。
检验结果表明,无论在有噪声还是无噪声的数据环境下,经过优化减负后的模型相较于原始模型,在性能提升方面均展现出了显著的成效,性能的提升幅度普遍超过0.05,如表2所示。这一结果充分证明了本文所提出的方法在提升模型性能方面具有较强的鲁棒性。此外,本文还发现在减负前模型性能较弱的情况下,经过优化减负后,模型性能的提升空间更为显著,如图9所示。
4.4动态检验
为检验模型在不同数据规模下的稳定性和一致性,以及对不同时间段虚假新闻数据的敏感性,本文采用固定数据量增量的方法再次对数据集进行划分。由于原始数据集中的数据是分多个时间点获取的,本文抽取原始数据集第1时间段中前2万条数据作为数据集D2,第2时间段2万条加上第1时间段2万条共4万条数据作为数据集D4,依次类推得到数据集D6(6万条数据)和D8(8万条数据)。这样选取的数据集不仅体现了数据规模上的差异,同时也代表了时间演化的信息。本文分别根据上述4个数据集进行同样的实验过程来实现对模型的动态检验,并从稳定性、一致性和敏感性3方面对检验结果进行具体分析,实验结果如表3、图10~12所示。
1)稳定性:在评估模型稳定性时,本文重点关注了不同数据规模下模型两阶段划分阈值的变化。如图10所示,本文发现不同规模数据集实验(D2、D4、D6、D8)的第一阶段自匹配阈值、互匹配双阈值与主实验(D)的阈值差异并不大,这表明两阶段模型在应对不同规模的数据时,能够保持相对稳定的性能。现实世界中数据的规模往往是不确定的,因此能够在不同数据规模下保持稳定性能的模型往往具有更高的使用价值。
2)一致性:为了验证模型的一致性,本文将动态实验与性能提升实验结果进行了对比。如图11所示,在D2、D4、D6、D8数据集上,各个模型的AUC与主实验(D)保持了高度的一致性。这种一致性不仅证明了模型的有效性和可靠性,也为模型的进一步应用提供了重要参考。
3)敏感性:本文采用固定增量而非固定时间间隔的数据集进行测算,由于网络媒体新闻是伴随着突发事件而呈现间歇性的模态,因此通过固定数据增量的测算方法能够比固定时间间隔更精确地捕捉网络媒体中虚假新闻的节奏和趋势。对数据集D2、D4、D6和D8的测算结果如图12所示,在不同时间段上模型都能够有效地识别出虚假新闻,并且其性能提升幅度与主实验(D)相比并未因时间因素而出现明显波动。这一结果说明了本文模型对时间因素并不敏感,能够在不同时期的数据下保持稳定的性能,这对于应对现实世界中复杂多变的虚假新闻环境具有重要意义。
综上所述,根据动态检验结果可以看出,本文提出的模型对数据规模大小和时间演进过程均具有较强的适应性和稳定性。这说明:在原理上,时间因素不是模型性能的核心本质因素;在应用上,本文提出的模型可以根据时间的推进和样本的演化变迁进行动态跟随,以适应时代的发展。
5结语
虚假新闻和真实新闻形成的双侧厚尾分布给以神经网络为代表的分类模型带来较大负担,限制了模型性能上的提升和突破。本文研究表明:通过减负训练可以明显提升模型性能;双侧厚尾分布提供了两阶段分类过程的可行性,可以选择对一侧或双侧厚尾进行切割形成弱减负或强减负的应用环境,以最大得失比为依据确定阈值对减负训练最为有利;Pareto有效性原理表明真实新闻具有良好的自匹配性,这种自匹配性还可用于对新闻的质量和水平等方面的评价,为Pareto有效性原理与新闻数据分析的结合提供了桥梁。本文模型对于无标题新闻数据的识别存在局限性,将两阶段混合标签处理过程拓展到对多标签的识别仍有很大的空间值得探索。
