基于时间序列的发电机设备异常分析
2024-12-31陆钊龙法宁陈国年

摘" 要:为提高发电机组设备运行维护管理水平,提出一种基于PCA-Informer方法的发电设备故障预测技术。首先使用主成分分析(PCA)算法降低时间序列数据的特征维度;其次将数据分批次输入Encoder中,由Encoder执行蒸馏操作,提取长时间序列输入间的Long-Range依赖,通过蒸馏操作为重要特征赋予更高的权重,并在下一层生成聚焦的Self-Attention Feature Map;最后由Decoder通过一个正向过程一步生成长序列输出。通过实验验证,该方法能够有效地对发电设备的故障进行预测。
关键词:发电机设备;主成分分析;Informer;故障预测
中图分类号:TP391;TP183 文献标识码:A 文章编号:2096-4706(2024)12-0121-04
Abnormal Analysis of Generator Equipment Based on Time Series
LU Zhao, LONG Faning, CHEN Guonian
(Yulin Normal University, Yulin" 537000, China)
Abstract: To improve the level of maintenance and management of power generation equipment operation, a fault prediction technology for power generation equipment based on PCA-Informer method is proposed. Firstly, it uses Principal Component Analysis (PCA) algorithm to reduce the feature dimension of time series data. Secondly, the data is inputted into the Encoder in batches, and the Encoder performs distillation operations to extract Long-Range dependencies between long time series inputs. The important features are given higher weights through distillation operation, and a focused Self-Attention Feature Map is generated in the next layer. Finally, the Decoder generates a long sequence output by one-step reaction through a forward process. Experimental results show this method can effectively predict the faults of power generation equipment.
Keywords: generator equipment; PCA; Informer; fault prediction
0" 引" 言
由于能源的需求不断增加,我国持续推动风力、光伏发电场的建设。这些发电场一般位于相对较偏僻的平原、山顶或者海上,不利于对发电机组设备实施运行监测和故障维修。为提高发电机组设备运行维护管理水平,采用智能系统成为故障诊断研究领域的一个重要发展方向和必然趋势[1]。例如,张李炜等提出了基于Apriori算法和卷积神经网络的风电机组故障诊断模型[2],周凌等进行了基于FISSA-DBN模型的风电机组运行状态监测研究[3];刘志刚等进行了基于小波包-神经网络的电厂发电机组故障诊断研究[4];朱小超提出了基于聚类算法的光伏发电设备故障诊断方法[5];陈万志等提出了融合LSTM和优化SVM的风力发电机组故障预测方法[6]。这些方法在发电设备的监测与故障诊断方面均取得了一定的成效。本文将基于Informer [7]模型为基础,对某风电场群一年的SCADA系统数据进行分析,实现对风机短期的故障预测,同时为后续学者研究提供参考。
1" Informer模型
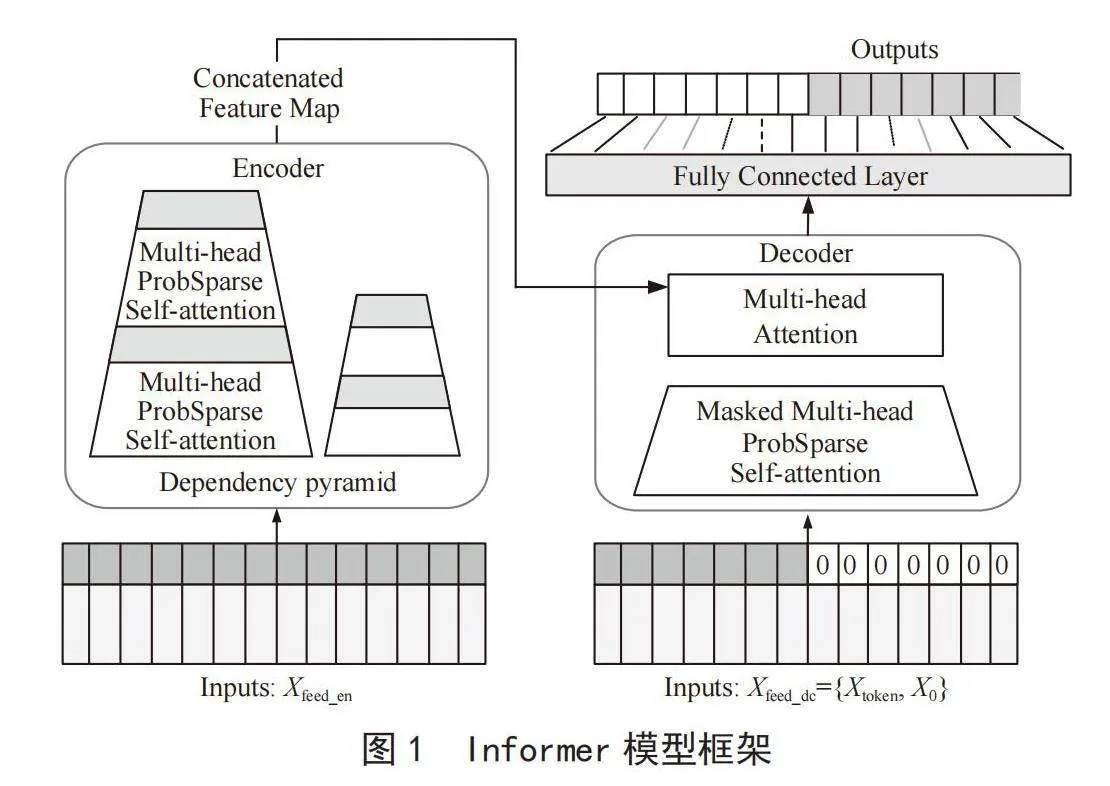
Informer模型是改进后的Transformer网络模型,通过使用多头概率稀疏自注意力机制,给重要特征分配更大的权重,降低了网络模型的时间复杂度[8],同时基于生成式解码提高预测速度,解决了时间序列数据的长时(Long-Range)依赖问题,对于长时间序列预测具有显著优势。Informer模型保留了Transformer的基础构成,其在整体上是由编码器(Encoder)以及解码器(Decoder)两个部分构成。Informer模型的整体框架如图1所示。
在Informer模型中,编码器主要用于获取原始输入序列鲁棒性的长期依赖,而解码器则进一步实现序列预测[9]。如图1所示,图的左侧部分为编码器(Encoder)部分,它负责接收的是超长的输入数据(feed_en),然后再将传统的Self-Attention层替换为ProbSpare Self-Attention层。使用Self-Attention Disilling操作来进行特征压缩。Encoder模块通过堆叠上述的两个操作来提高算法的鲁棒性。右侧是Decoder部分,它接收一系列的长序列输入(feed_de),并将预测目标位置填充为0,再通过经过Mask的Attention层,最后一步生成预测输出。
2" 实验数据及预处理
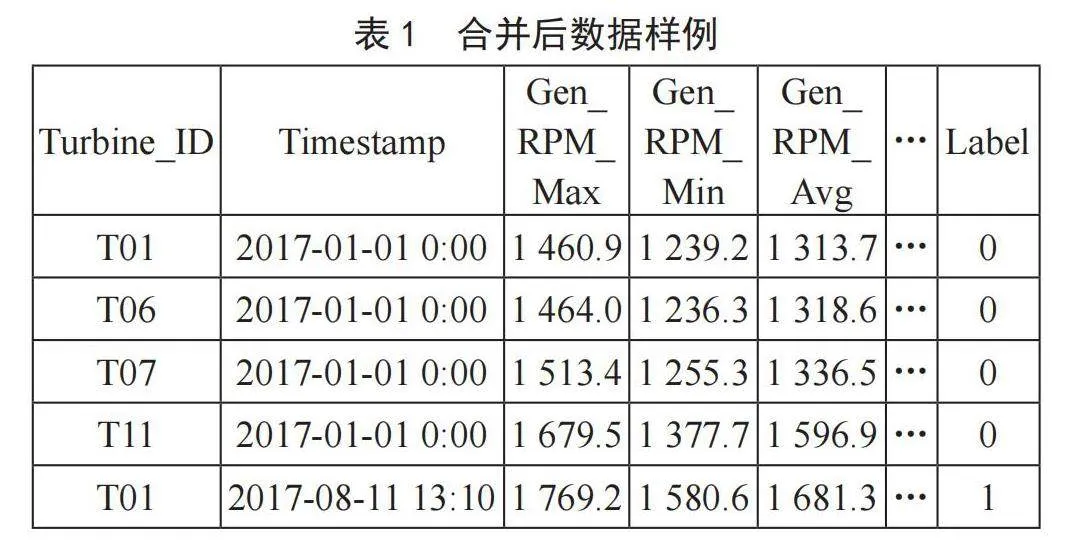
所使用的数据来源于微信公众号“数据如琥珀”,数据主要描述的是某风电场群在2016年和2017年这两年SCADA真实运行数据,该数据集包含了风机正常运行时的SCADA的实时数据、故障日志、重要的事件日志、风机出厂参数等。从中选取htw-failures-2017.csv(2017年风电场群在运行时出现故障的时间以及故障类型等)和data_wind_prod.csv(2017年风电场群正常运行时的SCADA的实时数据)分别进行预处理,最后合并成4台风机(Turbine_ID)、82个特征(Timestamp、Gen_RPM_Max等)、1个标签(Label)和210 235行记录数据的数据集,如表1所示。
因为Informer模型的时间复杂度为O(LlogL),其中L是序列的长度。特征数量多造成计算量过大,需要进行降维处理。本文采用主成分分析(PCA)算法对特征参数进行训练,并获取其中与数据关联性较高的部分特征。首先需要剔除数值一直没有波动的列,再对数据进行归一化处理。其次计算协方差矩阵,求解协方差矩阵的特征值与特征向量[10]。最后,特征值进行排序,获取前20个最大的特征值。
3" 对比实验
使用Informer模型进行长序列预测的命令行参数设置和训练,包括数据选择、模型参数设置、训练循环以及额外选项。通过设置不同参数组合,可实现对不同类型数据的预测任务。为了验证Informer模型对风机故障的预测效果,本文进行三个对比实验,分别为:基于百度PaddleTs的RNN对比实验,基于百度PaddleTs的MLP对比实验,以及基于TensorFlow的LSTM对比实验。并将均方误差(MSE)以及平均绝对误差(MAE)的结果作为模型性能的评价指标。
以下是Informer模型算法的伪代码:
输入:序列数据X = {x1,x2,…,xn},序列长度L,嵌入维度d,头数h,层数N,dropout rate p
输出:预测标签Ŷ
初始化位置编码PE
初始化输入嵌入矩阵E = Embedding(X)
将输入嵌入矩阵E与位置编码PE相加得到输入矩阵Input = E + PE
初始化多头自注意力机制MultiHeadAttention和前馈神经网络FeedForward
初始化输出矩阵Output = Input
for layer in range(N):
1)计算自注意力得分AttentionScores=MultiHeadAttention(Output,Output,Output)
2)对自注意力得分进行dropout操作AttentionScores=Dropout(AttentionScores,p)
3)将自注意力得分转化为权重矩阵 AttentionWeights=Softmax(AttentionScores)
4)使用权重矩阵对输入矩阵进行加权求和 WeightedSum = MatMul(AttentionWeights,Input)
5)将加权求和结果通过前馈神经网络得到输出矩阵Output = FeedForward(WeightedSum)
6)对输出矩阵进行dropout操作Output = Dropout(Output,p)
7)将输出矩阵与输入矩阵进行残差连接并归一化Output = LayerNorm(Output+Input)
通过线性层将输出矩阵转化为预测标签Ŷ = Linear(Output)
返回预测标签Ŷ
主Informer源文件(代码略)提供了训练和测试模型的过程,包括输出信息、计算均方误差和平均绝对误差、保存结果为列表和DataFrame格式,并将DataFrame保存为CSV文件。主要思路和步骤如下:
1)导入所需的库,包括argparse(用于处理命令行参数)、os、numpy、pandas、torch等。
2)定义一个名为parser的ArgumentParser对象,这是argparse库中的一个类,用于存储所有需要解析的命令行参数信息。
3)使用add_argument()方法向parser对象中添加各种命令行参数,如模型名称、数据名称、数据文件路径、预测任务类型等。每个add_argument()调用都会创建一个新的命令行参数选项。
4)使用parse_args()方法解析命令行参数,并将结果保存在一个名为args的对象中。这个对象包含了所有的命令行参数值。
5)根据args对象中的参数值,执行相应的操作。例如,如果args.model的值为'informerstack',则创建一个Exp_Informer对象;如果args.use_gpu为True且torch.cuda.is_available()也为True,则将args.use_gpu设置为True。
6)在for循环中,根据不同的数据名称(如'特征-标签数据')和目标特征(如'M'),从data_parser字典中获取相应的数据信息,并将其保存在args对象中。然后根据这些参数值执行相应的操作。
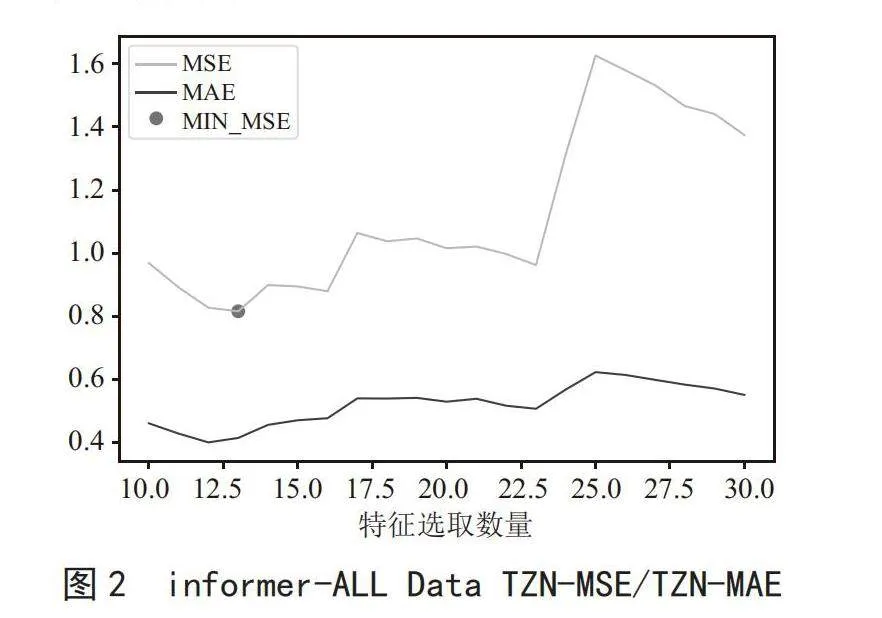
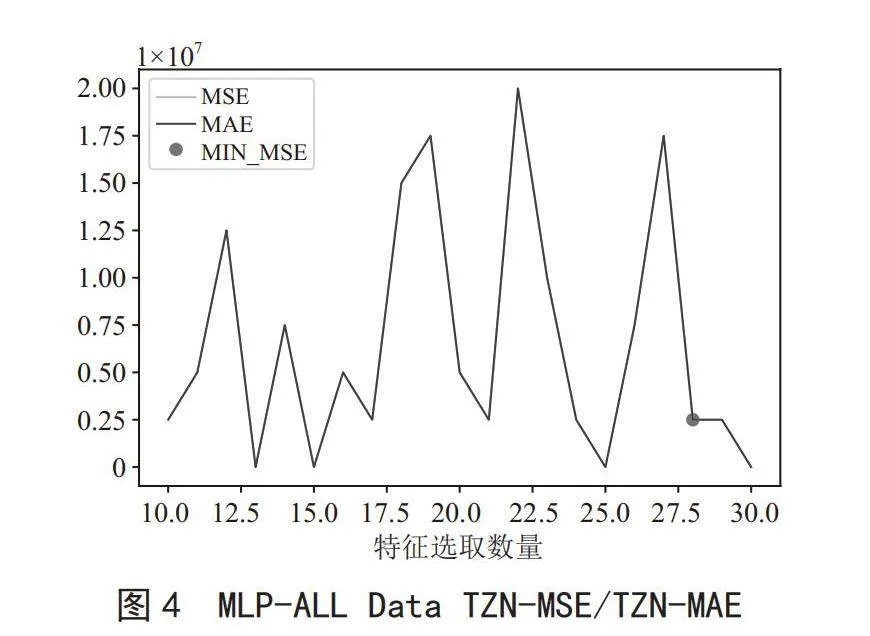
首先将训练结果按模型与特征选取数量进行分组,绘制特征选取数量与MSE、MAE的关系图,如图2至图5所示。
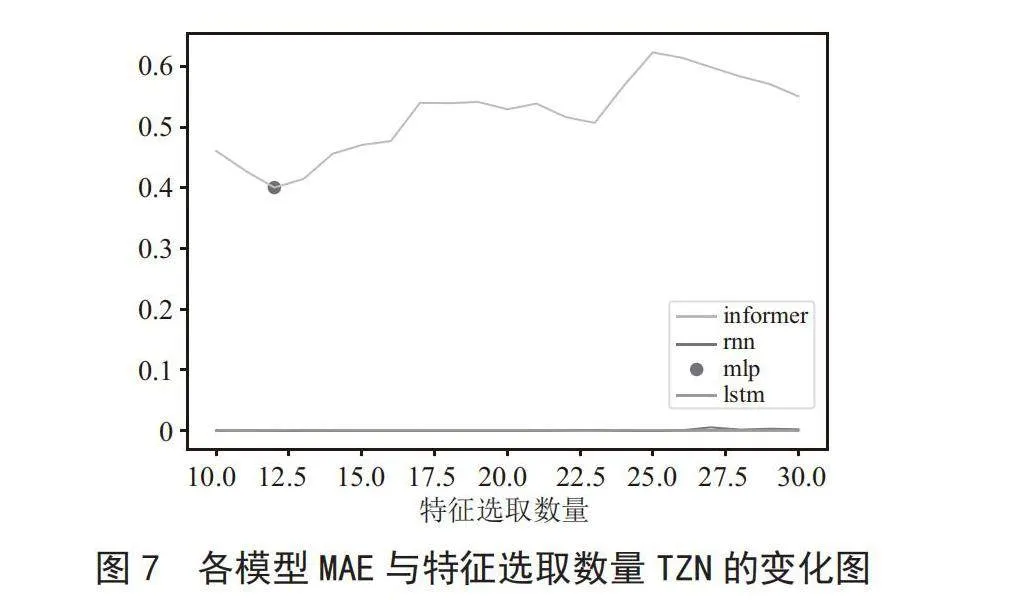
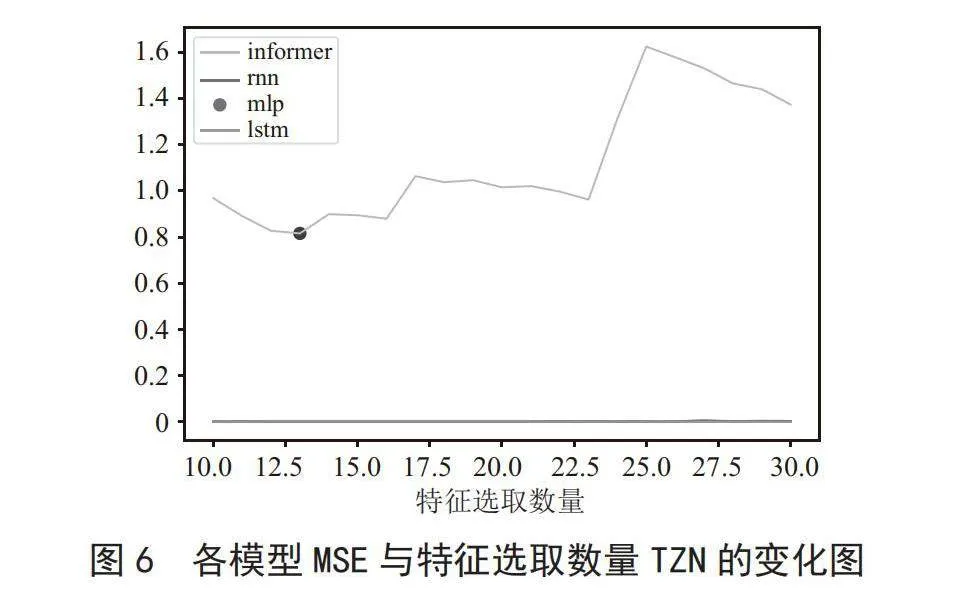
将所有数据绘制于一起,所得结果如图6、图7所示。
由上述图示可以得出,基于Informer算法所训练的模型,其曲线较为平滑,在各参数训练所得结果中,并未出现评价指标归零的情况;而基于其他算法的模型结果,其曲线变化波动异常,不利于对发电设备健康预测的应用。
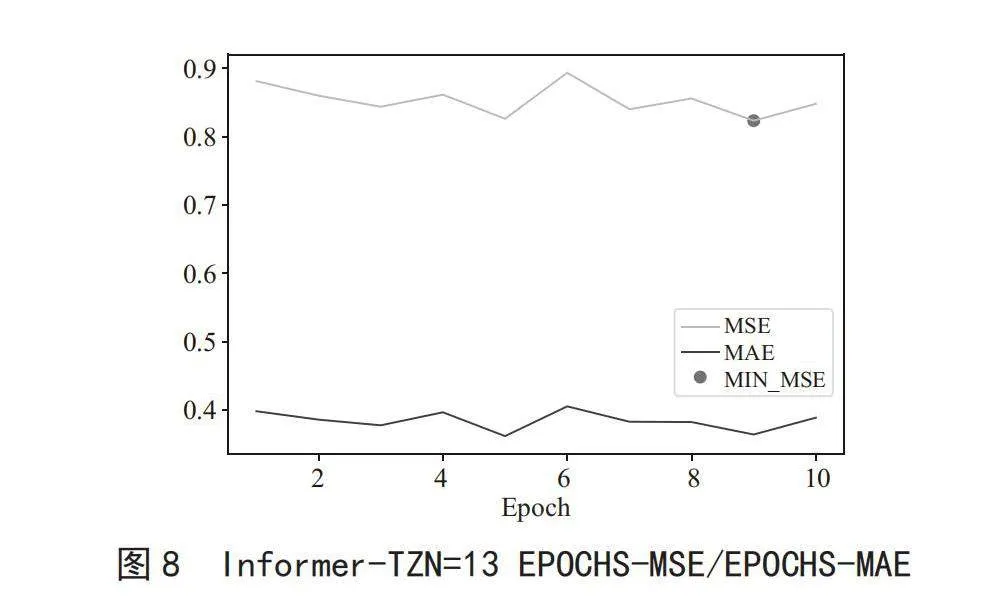
由上诉图例中,基于Informer算法的模型,总体在特征选取数量为13时,MSE结果最小,对特征选取数量为13的参数训练结果进行分析,绘制如图8所示的关系图。
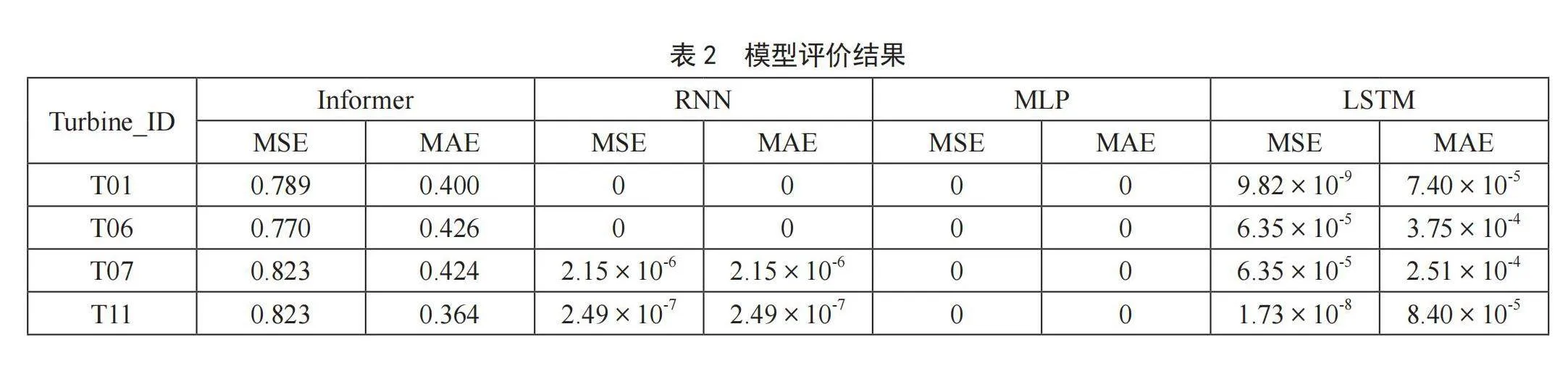
由图8可知,当特征选取数量为13,模型训练次数为9时,能获得最小的模型评价指标,即最大的模型性能。当特征选取数据为13,模型训练次数为9时,获得的各模型训练结果如表2所示。
4" 结" 论
综上所述,基于Informer算法所建立的模型在风机故障预测中取得了平稳的评价结果。对于特征选取部分,本文仅在特征选取数为10~20个、模型训练次数为1~10次的前提下进行研究,对于特征选取数量为其他值的结果,本文并未得知,存在更优解的可能。同时,本文仅在是否发生故障这一单方面对数据进行训练与预测,在实际生产过程中,应针对可能出现的多种故障类型进行训练,精准的预测风机等多种发电设备可能出现的故障的时间节点以及故障类型。
参考文献:
[1] ZHANG Y,SUN S M,YU P,et al. Research and application of fault diagnostics method for new energy power plant equipment based on big data mining [J/OL].IOP Conference Series: Earth and Environmental Science,2018,188(1):1-9[2023-04-10].https://iopscience.iop.org/article/10.1088/1755-1315/188/1/012115.
[2] 张李炜,李孝忠.基于Apriori算法和卷积神经网络的风电机组故障诊断模型 [J].天津科技大学学报,2022,37(5):50-55.
[3] 周凌,赵前程,朱岸锋,等.基于FISSA-DBN模型的风电机组运行状态监测 [J].振动.测试与诊断,2023,43(1):80-87+199.
[4] 刘志刚,赵晓燕,张涛,等.基于小波包-神经网络的电厂发电机组故障诊断研究 [J].机械传动,2018,42(8):179-182.
[5] 朱小超.基于聚类算法的光伏发电设备故障诊断方法 [J].宁夏电力,2022(4):12-18.
[6] 陈万志,李昊哲,刘恒嘉,等.融合LSTM和优化SVM的风力发电机组故障预测方法 [J].辽宁工程技术大学学报:自然科学版,2022,41(4):379-384.
[7] ZHOU H Y,ZHANG S H,PENG J,et al. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting [C]//Proceedings of the AAAI Conference on Artificial Intelligence.Palo Alto:AAAI Press,2021,35(12):11106-11115.
[8] 左敏,胡天宇,董微,等.基于Informer神经网络的农产品物流需求预测分析——以华中地区为例 [J].智慧农业:中英文,2023,5(1):34-43.
[9] 董浩,孙琳,欧阳峰.基于Informer的PM(2.5)浓度预测 [J].环境工程,2022,40(6):48-54+62.
[10] 黎嘉盈.基于并行幂法的分布式主成分分析算法研究及应用 [D].深圳:深圳大学,2022.
作者简介:陆钊(1978—),男,壮族,广西南宁人,
副教授,本科,研究方向:数据挖掘;通讯作者:龙法宁(1978—),男,汉族,广西玉林人,高级工程师,硕士研究生,研究方向:机器学习;陈国年(1999—),男,汉族,广西钦州人,本科在读,研究方向:数据科学与大数据技术。
