基于双通道交叉融合的卷积神经网络图像识别方法研究
2024-12-31黄曼曼王松林周正贵侯秀丽





摘" 要:针对单通道卷积神经网络的特征提取不够充分、深度网络存在训练困难的问题,提出一种双通道交叉融合的卷积神经网络模型。该模型包括三个特征提取阶段,每个阶段分两条通道进行图像卷积,当两条通道的卷积结束后进行特征交叉融合,经过三次交叉融合后输入到全局平均池化层以及全连接层中得到分类结果。将该模型应用于Cifar10、Cifar100和Fashion-MNIST的图像分类任务以验证模型的有效性。结果表明,双通道交叉融合模型可以在当前支持GPU加速的主流笔记本电脑上进行训练,在同样规模的数据集上具有比同类其他模型更好的分类性能。
关键词:卷积神经网络;双通道;融合;分类;准确率
中图分类号:TP391.4;TP183" 文献标识码:A" 文章编号:2096-4706(2024)12-0047-06
Research on the Image Recognition Method of Convolutional Neural Networks Based on Dual-channel Cross-fusion
HUANG Manman, WANG Songlin, ZHOU Zhenggui, HOU Xiuli
(School of Information and Artificial Intelligence, Anhui Business College, Wuhu" 241002, China)
Abstract: In response to the problems of insufficient feature extraction in single-channel Convolutional Neural Networks and the difficulty in training deep networks, a dual-channel cross-fusion Convolutional Neural Networks model is proposed. This model includes three feature extraction stages, with each stage performing image convolution through two separate channels. After the convolution of the two channels is completed, feature cross-fusion is carried out. After three rounds of cross-fusion, the features are input into a global average pooling layer and a fully connected layer to obtain classification results. This model is applied to image classification tasks on Cifar10, Cifar100, and Fashion-MNIST to verify its effectiveness. The results show that the dual-channel cross-fusion model can be trained on current mainstream laptops that support GPU acceleration, and it exhibits better classification performance than other similar models on datasets of the same scale.
Keywords: Convolutional Neural Networks; dual-channel; fusion; classification; accuracy
0" 引" 言
自2012年AlexNet [1]模型在ImageNet图像分类比赛中崭露头角以来,卷积神经网络(Convolutional Neural Networks, CNN)被广泛应用于不同的计算机视觉领域,如图像分割[2]、目标跟踪[3]、物体检测[4]等。为了不断地提升图像分类准确率,研究人员从很多方面开展了研究。在加深网络深度方面,Lin [5]等在NIN中使用1×1卷积核将特征信息进行跨通道融合,提升了模型的特征表达能力。Simonyan等[6]利用3×3卷积核,将网络深度扩展到19层,所构建的VGG模型在ImageNet图像分类中取得了不错的效果。在加宽网络宽度方面,Szegedy等[7]提出了GoogLeNet模型,该模型共22个卷积层,由多个Inception模块组成,每个模块均包含多个不同尺寸的卷积核,能有效地提取多尺度信息,从而提升图像分类精度。按照以往单纯地加深网络深度,网络的性能却越来越差,出现了梯度消失问题。He等[8]提出了ResNet模型,通过引入残差学习解决了梯度消失问题,使得网络层次达到了152层乃至1 000层。Huang等[9]受此启发提出了性能更为优越的DenseNet模型用于图像分类。近几年,研究人员又把研究重心放在了改变卷积方式方面,基于深度可分离卷积结构,Howard等[10]面向移动端应用提出了MobileNet模型。
以上模型通过加深网络深度和宽度、引入残差学习、改变卷积方式等,虽然在一定程度上提升了模型的性能,但是这些模型主要在大型数据集上进行训练,需要较高的训练平台,这样模型应用就具有一定的局限性。另外,如何高效地训练一个深层网络仍然是一个挑战,诸如采用Dropout 技术、批归一化、残差连接和优化网络结构可提升信息流动,从而训练更深的网络。鉴于此,本文在单通道卷积神经网络的基础上,结合人眼视觉原理,提出了一种双通道交叉融合的卷积神经网络模型。在物体分类数据集Cifar10和Cifar100以及服装分类数据集Fashion-MNIST上进行实验,与主流模型Highway、ResNet、MobileNet等相比,本文模型取得了更优越的分类性能。
1" 相关工作
目前,从深度融合网络的结构上来看,很多经典卷积神经网络模型都有深度融合的思想,如GoogLeNet、ResNet、HighwayNetworks [11]等均有深度融合的影子。尤其是GoogLeNet模型中的Inception系列和ResNeXt [12]都对深度融合结构做了深入研究。面对这些层数极深的网络,其融合次数也相应增多,这使得网络可以获取更多的基础信息和更佳的流动信息。
深度融合的方式多种多样,例如GoogLeNet模型由多个Inception模块组成,每个模块的结尾使用拼接融合。ResNet使用加法融合,可以看作是深度融合的一种特例。谭震等[13]利用多个不同卷积尺度的卷积通路并行提取信息特征,并进行信息的分类预测,具有比同类其他模型更好的性能。张李炜等[14]采取了并联式结构,通过2次通道提取特征,将特征融合起来,相较于其他模型,准确率更高,整体效果更好。在图像数据Cifar10和Cifar100这种小型数据集上,采用单通道卷积网络学习整个图像细节较为困难,通过双通道交叉融合方式,使得两条通道联合学习,减少特征信息损失,能够提取图像的深层特征,有效提升模型在数据集上的分类精度。
2" 模型及结果分析
2.1" 双通道交叉融合模型的建立
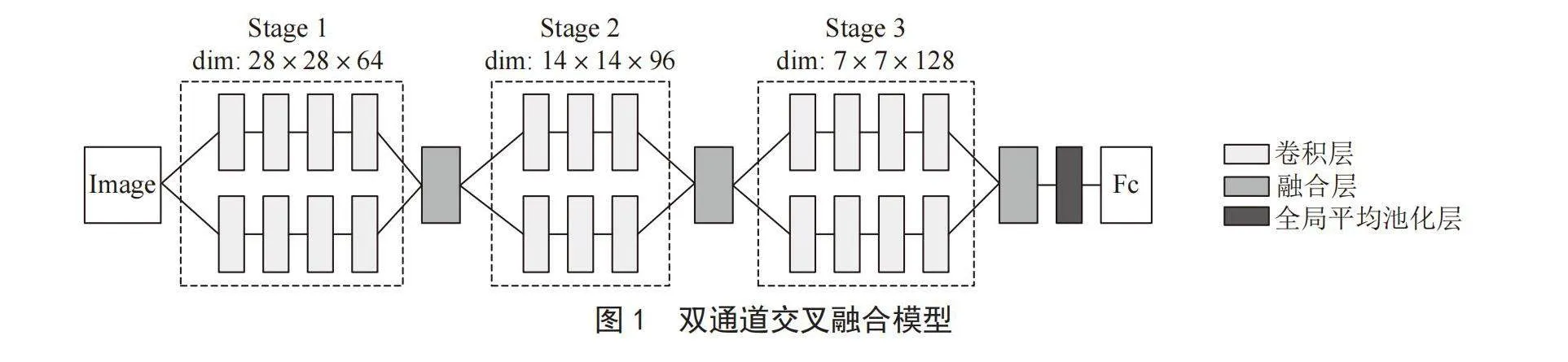
人眼视觉原理表明,当人们用眼睛观察目标时,通过两条视觉神经传递信息,再通过漆状体和视交叉后形成交叉混合信息供大脑进行分析。针对单通道卷积神经网络提取到的图像信息不充分的问题,受人眼视觉原理启发,本文提出了一种双通道交叉融合的模型结构,如图1所示。
其中,两条通道的卷积深度控制在11层,并遵循以下三个设计规则:
1)整个模型主要分三个特征提取阶段,每个阶段包含两条通道,两条通道中的特征尺寸和卷积核的数量均相等,每个阶段的特征提取结束后进行融合。
2)当特征图尺寸减半时,卷积核的数量相应增加,并直接使用步长为2的卷积层进行下采样。
3)与ResNet模型相同,尾部采用全局平均池化层和全连接层输出分类结果。
卷积层的数学表达式如式(1)所示:
(1)
其中" 为上一层的输出特征图, 为卷积核的权值, 为每个特征图的偏置项, 为激活函数。
本文给出了两条通道特征融合的数学表达式,如式(2)和式(3)所示:
(2)
(3)
式(2)中, 为第一条通道的卷积输出, 为第二条通道的卷积输出,f (x)为两条通道输出特征的融合函数, 为融合后的输出。式(3)中,z为融合后的输出特征图数量,s为融合类型。
2.2" 尺度融合方式
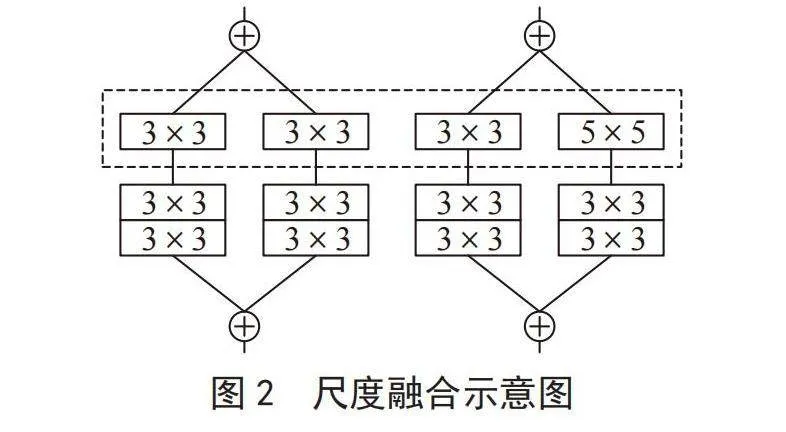
在尺度融合方式上,主要观察相同尺度网络融合和不同尺度网络融合的分类性能。以图1中阶段2为例,有两种融合方式,如图2所示。两种融合方式的主要区别在于步长为2的下采样层,左图的两条通道采用相同尺度的卷积核进行下采样,右图的两条通道采用不同尺度的卷积核进行下采样。这样左图可以看作是两个相同网络的交叉融合,右图可以看作是不同网络的交叉融合。
2.3" 特征融合方式
Caffe深度学习框架里的Concat层和Eltwise层用于特征融合。前者是拼接融合,要求特征图的尺寸必须相同,对于特征图数量没有要求。后者的融合方式有相加融合(Sum)、最大值融合(Max)、点乘融合(Product)三种,常用的是相加融合,进行特征融合时,要求特征图的尺寸和数量必须相同。以阶段2为例,特征融合示意图如图3所示,左边为拼接融合,右边为相加融合。为了能够观察两种融合方式的性能,模型中每个阶段的双通道卷积层的输出特征图数量均保持一致。
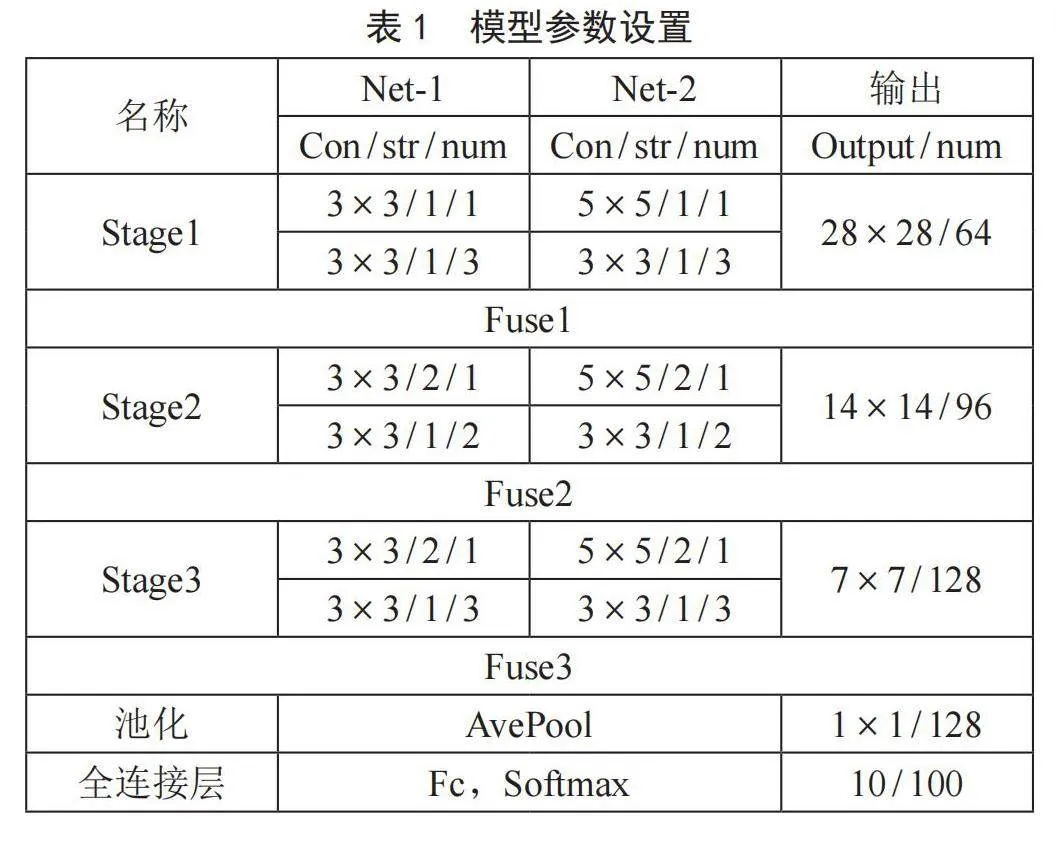
2.4" 模型参数设置
表1给出了一种不同尺度网络融合的模型参数设置。其中,每种网络均包含11层的卷积,两种网络的下采样层分别使用步长为2的卷积核3×3和5×5。
3" 实验设置与结果分析
3.1" 实验设置
为了评估本文模型的有效性,在物体分类数据集Cifar10和Cifar100上进行模型分类效果的实验。
3.1.1" 数据集
Cifar10数据集包含10种类别的彩色图像,分别是飞机、汽车、船、卡车、马、鸟、狗、猫、鹿、青蛙,每类有6 000张,共60 000张,其中50 000张作为训练图像,10 000张作为测试图像,该数据集的部分样本如图4所示。Cifar100与Cifar10类似,包括100类,每类图像数量是600,共60 000张图像,其中50 000张训练图像和10 000张测试图像。以上两个数据集的图像像素均为32×32,相比之下,Cifar100种类明显多于Cifar10,而且每个种类图像数量更少,在分类时更加困难。
3.1.2" 图像预处理
数据增强是从每张图像的5个方位随机裁剪生成28×28像素的图像,再进行翻转操作可以将图像数量扩增为原始图像数据的10倍,如图5所示。
3.1.3" 实验平台
实验平台的计算机配置为神舟笔记本Intel Core i5-8265U CPU、Windows 11操作系统、8 GB内存以及单条NVIDIA-GTX 1050 Ti GPU显卡,编程环境为Python 3.6,深度学习框架为Caffe。
3.1.4" 训练参数设置
为了适应当前训练平台,训练批次设置为64,测试批次设置为100。经过多次实验,本文给出了在Cifar10和Cifar100上的训练参数设置:在Cifar10上训练时,学习率为0.001,变化方式为poly,gamma为0.9,power为1.5,最大迭代100 000次;在Cifar100上训练时,学习率为0.008,学习率变化方式为multistep,gamma为0.2,stepvalue为24 000、48 000和72 000,最大迭代80 000次。
3.2" 实验结果及分析
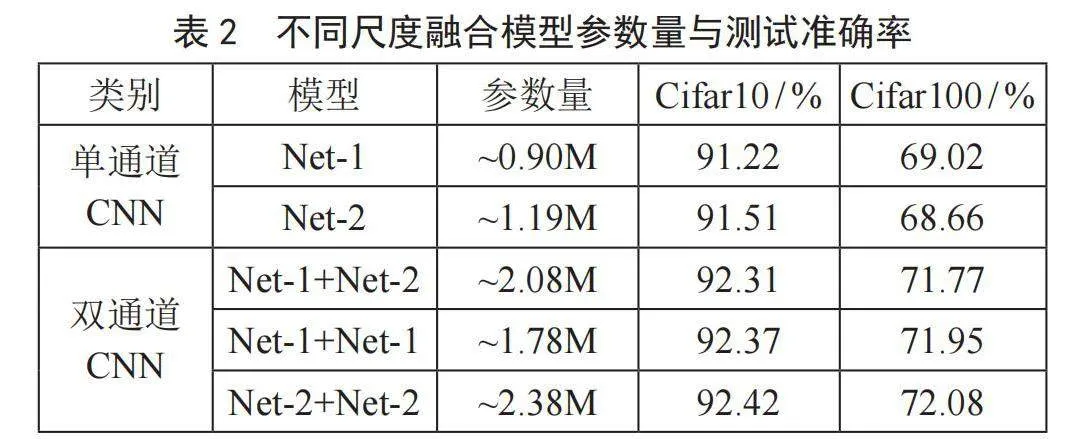
表2列出了在尺度融合上的参数量以及在Cifar10和Cifar100上的分类准确率。由于待分类的图像种类数量不同,模型参数量有略微的差别,本文用“~”表示采用相同模型训练的参数量。
从表2可以看出,双通道交叉融合CNN模型的准确率明显优于单通道CNN模型,说明双通道融合更有利于特征提取。但是由于是两条通道进行交叉融合,双通道融合模型的参数量要高于单通道模型。从双通道CNN模型的性能来看,采用相同尺度Net-1+Net-1和Net-2+Net-2模型比采用不同尺度Net-1+Net-2模型的分类准确率分别高出0.06%、0.18%和0.11%、0.31%,说明相同尺度网络交叉融合的分类性能要优于不同尺度网络的交叉融合。综合评价来看,Net-1+Net-1模型性能较优,其参数数量比其他两种类型的双通道CNN模型更少,而与获得最高准确率的Net-2+Net-2模型相比,模型的准确率仅仅分别低了0.05%和0.13%。
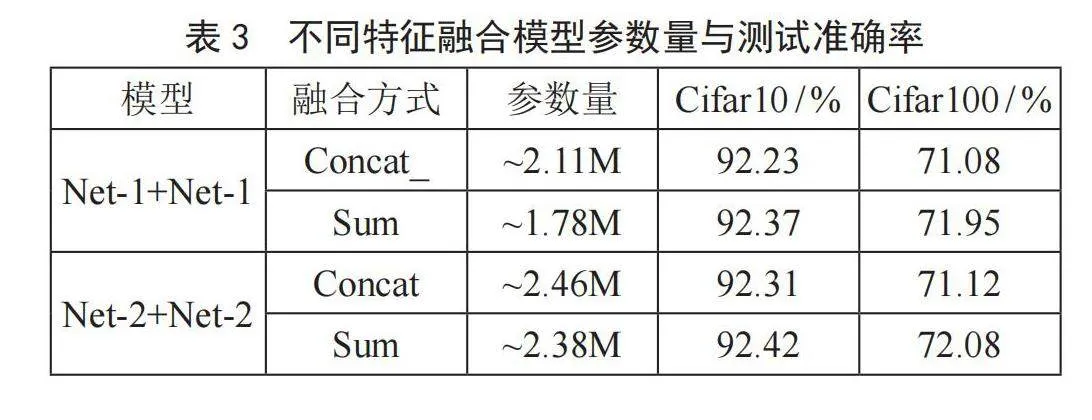
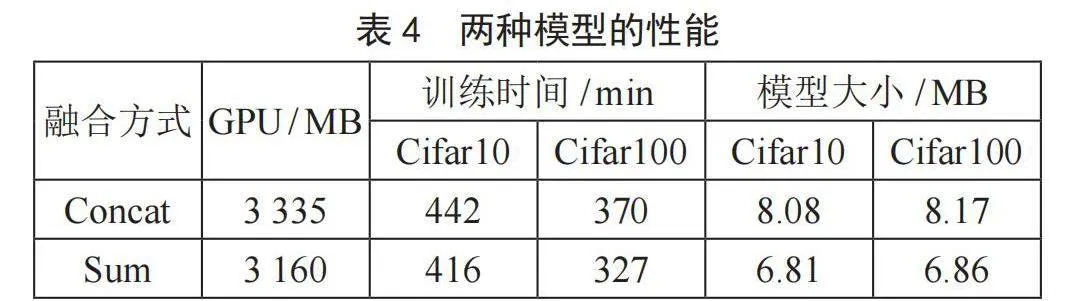
表3列出了在特征融合方式上的参数量以及在Cifar10和Cifar100上的分类准确率。以Net-1+Net-1为例,从表3可以看出,当特征融合方式为拼接(Concat)融合时,模型参数有2.11M,在Cifar10和Cifar100上的最优分类准确率分别为92.23%和71.08%;当特征融合方式为相加(Sum)融合时,模型参数有1.78M,在Cifar10和Cifar100上的最优分类准确率分别为92.37%和71.95%。同理,对于Net-2+Net-2为研究对象来说,发现采用特征融合方式为相加(Sum)融合时,类性能更为优越。
表4给出了以本文实验平台为例,两种特征融合模型的一些性能参数。总体来看,模型训练消耗的GPU显存不超过3.5 GB,生成的模型大小不足10 MB,训练平台要求不高,可以在当前支持GPU图像加速的主流笔记本电脑上训练本文模型。
3.3" 与其他模型对比
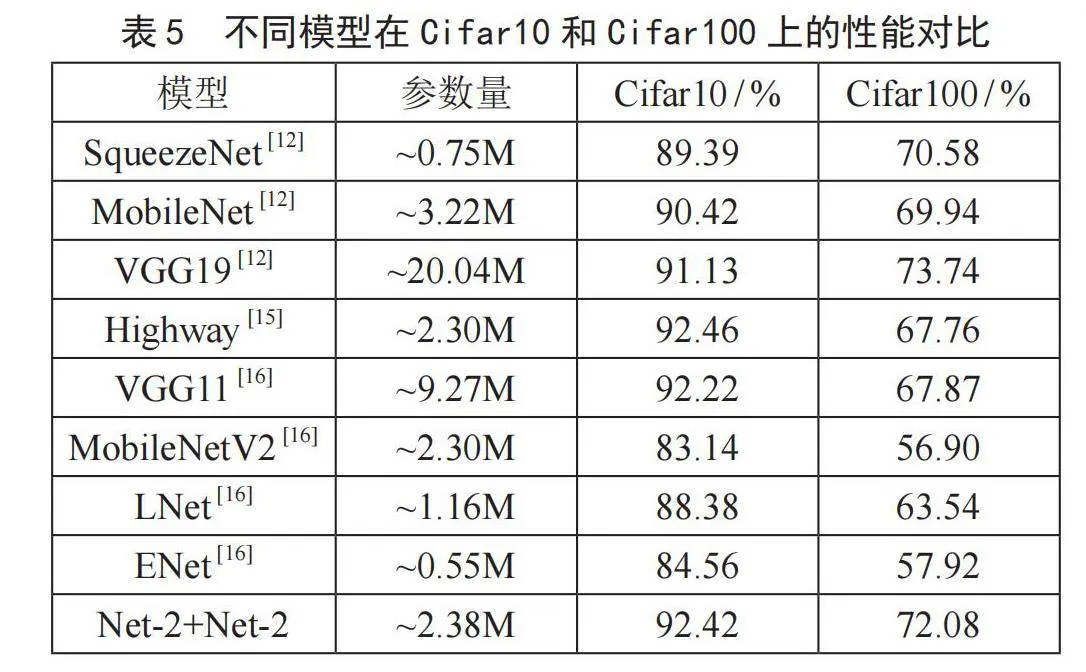
表5列出了实验中两个分类性能较优的双通道交叉融合模型与主流模型以及改进模型的性能对比。表5中的主流模型MobileNet和VGG19的网络层次均较深,计算量大,对训练平台要求较高,文献[12]在单条NVIDIA TITAN Xp GPU(12 GB)上训练了以上模型,并给出了在Cifar10和Cifar100上的分类性能。
从表5可以看出,Net-2+Net-2模型在Cifar100的分类准确率为72.08%,其分类性能超过SqueezeNet模型1.50%,超过MobileNet模型2.14%,超过Highway模型4.32%,证明了本文模型的优越性。但与深度更深和参数更多的VGG19模型相比,在Cifar10上高了1.29%,在Cifar100上低了1.66%,分类准确率相差较小。总体来看,本文模型在参数较少的条件下,与主流模型以及改进模型相比具有同样甚至更优越的分类性能。
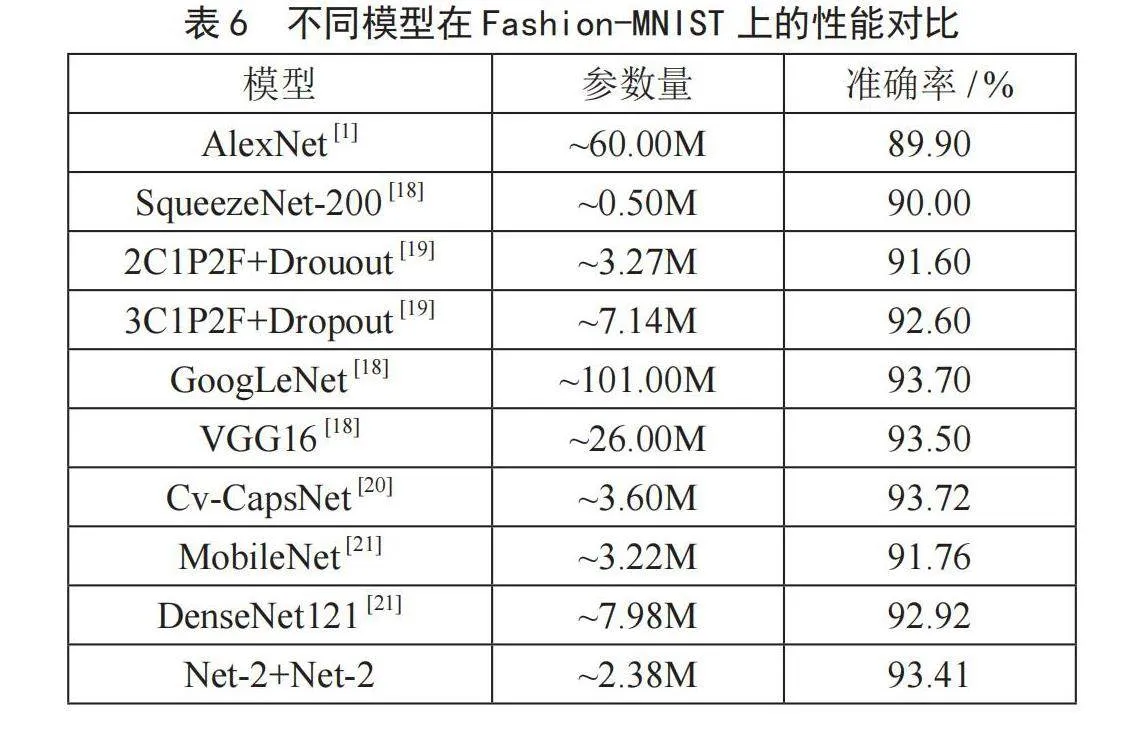
为了进一步评测模型在具体应用中的性能,实验选取了服装分类数据集Fashion-MNIST [17]进行迁移学习。该数据集包含10类灰度化的服装,是一个替换MNIST手写数字集的图像数据集,被广泛应用于评估模型性能,表6给出了本文中两种模型以及其他模型在Fashion-MNIST上的性能对比。
从表6可以看出,Net-2+Net-2模型具有2.38M参数,在Fashion-MNIST上的分类准确率为93.41%,超过SqueezeNet模型3.41%;而与主流模型GoogLeNet、VGG16和DenseNet121相比,Net-2+Net-2模型以更少的参数量达到了同样水平的准确率,特别是与GoogLeNet相比,模型参数仅占其2.36%。
综上所述,可以得到以下结论:
1)在控制了单通道卷积层的深度的情况下,使用双通道交叉融合可以提取更为丰富的图像特征,进而提升模型的分类性能。
2)相同尺度卷积交叉融合的分类性能要优于不同尺度卷积的交叉融合。
3)相加融合的参数量低于拼接融合,但是分类性能更为优越。
4" 结" 论
为了充分提取图像识别率,提出了一种双通道交叉融合的卷积神经网络模型,该模型包括三个阶段的双通道交叉融合,通过双通道的联合学习图像特征以及交叉融合,使得卷积层的特征信息流动更为流畅,进而提升了图像分类精度,同时模型拥有较少的参数量。在同样规模的数据集上,本文模型具有比同类其他模型更好的分类性能,能够在当前主流的笔记本电脑上进行训练,为其他单通道模型的特征提取提供了新的思路。另外,本文的双通道交叉融合模型仍有很大的提升空间,可以在更高的平台上,通过加深卷积深度,结合更多高效的深度学习方法,进一步提升模型的分类性能。
参考文献:
[1] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks [J].Communications of the ACM,2017,60(6):84-90.
[2] 朱素杰.改进卷积神经网络的船舶纹理图形分割方法 [J].舰船科学技术,2023,45(8):177-180.
[3] 张瑶,卢焕章,张路平,等.基于深度学习的视觉多目标跟踪算法综述 [J].计算机工程与应用,2021,57(13):55-66.
[4] 侯越千,张丽红.基于Transformer的多尺度物体检测 [J].测试技术学报,2023,37(4):342-347.
[5] LIN M,CHEN Q,YAN S C. Network in Network [J/OL].arXiv:1312.4400 [cs.NE].(2013-12-16).https://arxiv.org/abs/1312.4400.
[6] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks For Large-scale Image Recognition [J/OL].arXiv:1409.1556 [cs.CV].(2014-09-04).https://arxiv.org/abs/1409.1556.
[7] SZEGEDY C,LIU W,JIA Y Q,et al. Going Deeper with Convolutions [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Boston:IEEE,2015:1-9.
[8] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:770-778.
[9] HUANG G,LIU Z,MAATEN L V D,et al. Densely Connected Convolutional Networks [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:2261-2269.
[10] HOWARD A G,ZHU M,CHEN B,et al. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications [J/OL].arXiv:1704.04861 [cs.CV].(2017-04-17).http://www.arxiv.org/abs/1704.04861.
[11] XIE S N,GIRSHICK R,DOLLÁR P,et al. Aggregated Residual Transformations for Deep Neural Networks [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:5987-5995.
[12] SANTOS A G,SOUZA C O D,ZANCHETTIN C,et al. Reducing SqueezeNet Storage Size with Depthwise Separable Convolutions [C]//2018 International Joint Conference on Neural Networks (IJCNN).Rio de Janeiro:IEEE,2018:1-6.
[13] 谭震,郭新蕾,李甲振,等.基于多尺度卷积神经网络的管道泄漏检测模型研究 [J].水利学报,2023,54(2):220-231.
[14] 张李炜,李孝忠.基于改进CNN和BiGRU双通道特征融合的风电机组故障诊断模型 [J].天津科技大学学报,2023,38(1):55-60+69.
[15] SRIVASTAVA R K,GREFF K,SCHMIDHUBER J. Highway Networks [J/OL].arXiv:1505.00387 [cs.LG].(2015-05-03).https://arxiv.org/abs/1505.00387.
[16] 张晓青,刘小舟,陈登.面向移动端图像分类的轻量级CNN优化 [J].计算机工程与设计,2024,45(2):436-442.
[17] XIAO H,RASUL K,VOLLGRAF R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms [J/OL].arXiv:1708.07747 [cs.LG].(2017-08-25).https://arxiv.org/abs/1708.07747v1.
[18] SUN Y N,XUE B,ZHANG M J. Evolving Deep Convolutional Neural Networks for Image Classification [J].IEEE Transactions on Evolutionary Computation,2020,24(2):394-407.
[19] OYEDOTUN O K,SHABAYEK A E R,AOUADA D,et al. Highway Network Block with Gates Constraints for Training Very Deep Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).Salt Lake City:IEEE,2018:1739-1749.
[20] CHENG X M,HE J N,HEA J B,et al. Cv-CapsNet: Complex-valued Capsule Network [J].IEEE Access,2019(7):85492-85499.
[21] 张文韬,张婷.基于迁移学习的卷积神经网络图像识别方法研究 [J].现代信息科技,2023,7(14):57-60.
作者简介:黄曼曼(1991—),女,汉族,安徽阜阳人,助教,硕士研究生,研究方向:图像识别。
