基于改进挖掘算法的电力中台服务数据整合研究
2024-12-21范程宇丁文昊张祝



摘 要:由于电力中台服务数据构成较复杂,不能保证整合后数据的完整性,因此本文提出基于改进挖掘算法的电力中台服务数据整合研究。将电力中台服务数据的属性指示矩阵映射到单一维度的环境中后,根据单个电力中台服务数据属性在单一维度下的投影结果挖掘数据的特征;在整合阶段,确定目标电力中台服务数据特征对应的整合范围后,根据电力中台服务数据与整合中心特征之间的关系确定整合结果。在测试结果中,不仅针对各指标数据的完整性始终保持较高的稳定状态,而且对应的完整性水平也始终处于较高状态,在96.5%~99.5%区间内小幅波动。
关键词:改进挖掘算法;电力中台服务数据;属性指示矩阵;单一维度;投影结果;数据特征;整合范围
中图分类号:TP 391" " 文献标志码:A
电力中台服务数据在构成上主要体现了电力系统的多种属性特征[1]。通过整合电力中台服务数据可以形成统一的数据视图,消除数据孤岛,使数据资源得到更高效的利用[2]。电力企业可以更准确地了解电力系统的运行状态,提高电力系统的稳定性和可靠性。整合后的数据可以支持更高级的数据分析应用[3],优化电力设备的布局和配置,提高电力系统的运行效率,降低能源成本,推动电力行业的创新发展。
文献[4]提出以概率-非概率样本为基础的数据整合方法,通过随机抽样等方式获取具有代表性好、误差可控特点的数据,结合非概率样本方法在灵活性方面的优势,使整合后的数据更详细和更具体。这种方法可能受到主观因素的影响,导致数据的准确性和客观性受到一定影响。文献[5]提出以人工智能技术为基础的数据整合方法,利用人工智能技术可以自动识别、清洗、关联和融合数据,结合数据中的潜在规律和模式,提高了数据整合的效率和准确性。该方法对数据质量的要求较高,算法模型需要不断优化。
因此,本文提出基于改进挖掘算法的电力中台服务数据整合方法,通过测试验证了设计方法的性能。
1 电力中台服务数据整合方法设计
1.1 基于改进挖掘算法的电力中台服务数据特征提取
电力中台服务数据具有多样化的属性特征和复杂的构成,难以保障数据整合后的完整性[6]。为了有效地提取这些数据的特征,本文提出一种基于改进挖掘算法的方法,并引入一系列计算公式来实现这一过程。
首先,对原始的电力中台服务数据来说,受平台设置的影响,其具有标准化的属性特征。针对此,本文建立了以数据属性为基础的指示矩阵,同时,为了考虑不同属性之间的尺度差异,设置了以数据尺度为基础的约束矩阵,如公式(1)所示。
(1)
式中:Z为电力中台服务数据的属性指示矩阵;l为电力中台服务数据中的有效信息数量;z为单个电力中台服务数据的属性构成;m-l为电力中台服务数据的维度;B为电力中台服务数据的尺度约束矩阵。
其次,按照上述所示的方式,为了便于后续的数据分析,本文将属性指示矩阵映射到单一维度的数据矩阵环境中,这一过程通过矩阵因子λ来实现。λ的取值基于原始数据的分布离散程度,如公式(2)所示。
λ=f(σ) (2)
式中:f为离散程度与λ之间的映射函数;σ为原始数据的标准差,用于衡量数据的离散程度。
当σ较大时,意味数据分布较为离散,λ取较大值;反之,当σ较小时,λ取较小值。
将属性指示矩阵映射到单一维度的数据矩阵环境中,如公式(3)所示。
C=BF|Zλ (3)
式中:C为单一维度下电力中台服务数据的属性指示矩阵;F为同维度矩阵对应电力中台服务数据的矩阵因子。
F的具体取值以电力中台服务数据的分布为基础,即原始电力中台服务数据分布的离散程度越高,F的值越大,原始电力中台服务数据分布的离散程度越低,F的值越小。
此时,在单一维度环境下,本文在对数据的特征进行提取时,运用改进的挖掘算法来提取数据特征[7]。算法的核心思想是利用数据属性在单一维度下的投影结果来揭示数据的内在结构。对应的投影结果v(z)如公式(4)所示。
(4)
式中:f(C)为电力中台服务数据的特征;v(z)为单个电力中台服务数据属性在单一维度下的投影结果;ρ(a)为具体电力中台服务数据a在单一维度下的的概率密度分布情况。
当电力中台服务数据a的属性为单一属性时,其在单一维度下的概率密度分布与m-l维度下的概率密度分布一致;当电力中台服务数据a的属性不唯一时,其在单一维度下的概率密度分布为m-l维度下概率密度分布的立体投影。通过这一计算,得到每个数据属性在单一维度下的投影结果,从而可以分析数据的分布情况和内在特征。
为了更精确地描述数据的特征,还引入概率密度分布ρ(a)。对单一属性的数据来说,其概率密度分布与维度下的分布一致;对多属性的数据来说,通过计算多维分布在单一维度下的立体投影来获取概率密度分布。
此外,为了评估不同属性之间的相关程度,引入相关系数δ的计算公式,如公式(5)所示。
(5)
式中:x和y分别为2个属性的数据序列;μx和μy分别为它们的均值。
通过计算δ的值,可以了解不同属性之间的相关性强弱,从而在数据整合过程中考虑这些关联关系。
综上所述,通过构建属性指示矩阵和尺度约束矩阵、实现数据矩阵的单一维度映射以及运用改进的挖掘算法和相关计算公式,能够有效地提取电力中台服务数据的特征。这些特征为后续的数据整合和处理提供了可靠的依据,有助于提升电力中台服务的性能和质量。
1.2 电力中台服务数据整合
电力中台服务数据整合是确保数据质量和提升电力中台服务性能的关键环节。在上一章节中,已经通过改进挖掘算法成功提取了电力中台服务数据的特征。结合1.1对电力中台服务数据特征的提取结果,本章节将详细阐述电力中台服务数据的整合过程,以实际需求为导向,将对应的属性作为整合中心,开展相应的处理,并引入一系列计算公式,以加强数据整合的准确性和效率。
首先,需要确定数据整合的范围。整合范围的大小直接决定了整合结果的全面性和有效性。考虑数据的多样性和复杂性,采用特征指数函数和特征标准差函数来共同确定整合范围[8-9]。特征指数函数能够反映数据特征的重要性和影响程度,而特征标准差函数则能够衡量数据特征的离散程度。通过结合这2个函数,可以得到一个既考虑数据特征重要性又考虑数据离散程度的整合范围。其中,对于具体数据整合范围的设置方式如公式(6)所示。
(6)
式中:β为以zi电力中台服务数据特征为基础的整合范围;cr为电力中台服务数据特征的指数函数;Φ为电力中台服务数据对应的特征标准差函数。
结合公式(4)可以看出,对zi电力中台服务数据的属性特征来说,其整合范围与电力中台服务数据纵向维度l成负相关关系。
确定了整合范围后,进一步考虑电力中台服务数据与整合中心特征之间的关系。整合中心特征是基于数据特征提取结果而确定的,它代表了整合的核心和目标。为了衡量数据点与整合中心特征之间的关联程度,引入相似度计算公式和距离计算公式。相似度计算公式用于计算数据点与整合中心特征之间的相似程度,而距离计算公式则用于衡量数据点与整合中心特征之间的距离。通过综合考虑这2个因素,可以确定每个数据点在整合结果中的位置和权重。以此为基础,根据电力中台服务数据与整合中心特征之间的关系,最终的整合结果如公式(7)所示。
(7)
式中:G(a)为以zi电力中台服务数据特征为基础的整合结果。
结合公式(5)可以看出,对zi电力中台服务数据的属性特征来说,其整合结果与电力中台服务数据横向维度m成正相关关系。
需要特别注意的是,在实际应用中,电力中台服务数据可能存在特征交叉的情况,即一个数据点可能表现出多个属性特征。为了处理这种情况,采用特征权重分配策略。具体来说,根据每个特征与整合中心特征之间的相似度和重要性,为每个特征分配一个权重。然后,在整合结果计算过程中,根据每个数据点的特征权重进行加权求和,以充分考虑多个特征对整合结果的影响。
通过引入这些计算公式和策略,能够实现对电力中台服务数据的有效整合处理。数据整合的意义在于提高数据的完整性和一致性,为后续的数据分析和应用提供可靠的基础。通过整合处理,可以消除数据冗余和矛盾,提升数据的准确性和可靠性。同时,整合后的数据更易于管理和利用,能够为电力中台服务的优化和决策提供更有力的支持。
此外,本文采用的改进挖掘算法在数据特征提取和整合过程中具有显著优势。首先,该算法能够更准确地提取数据的特征信息,避免了传统方法可能存在的信息丢失和误判问题。其次,算法通过综合考虑多个因素来确定整合范围和整合结果,使整合过程更科学、更客观。最后,该算法具有较高的处理效率和可扩展性,能够满足大规模电力中台服务数据的处理需求。
综上所述,通过引入一系列计算公式和策略,结合改进挖掘算法的优势,能够实现电力中台服务数据的有效整合处理。这一工作不仅提高了数据的利用价值,而且还为电力中台服务的优化和决策提供了有力支持。
2 测试分析
2.1 测试数据准备
为了对本文设计的电力中台服务数据整合方法的性能进行深入分析,进行了详细的对比测试。测试数据主要基于某电力企业的实际中台服务数据,涵盖了多个关键属性,例如交易日期、交易类型、交易量、电价、发电企业、售电企业/电力用户、交易状态和备注等。这些属性数据之间存在复杂的关联关系,需要通过整合来提高数据的管理和应用效率。其中,具体的电力中台服务数据构成以及数据之间的关联关系见表1。
结合表1所示的信息可以看出,测试电力中台服务数据主要包括交易日期、交易类型、交易量、电价、发电企业、售电企业/电力用户、交易状态和备注。这些属性数据之间存在一定的关联关系,在实际的应用管理过程中,为了提高效率,需要按照具体的要求对数据进行适应性整合。
在具体的测试阶段,针对给出的第一季度电力中台服务数据信息,以用电用户为导向,开展具体的整合测试。为了全面评估本文方法的性能,从提高测试结果分析价值的角度分析,分别设置文献[4]提出以概率-非概率样本为基础的数据整合方法以及文献[5]提出以人工智能技术为基础的数据整合方法作为测试的对照组。
试验步骤如下。1)数据预处理。对原始电力中台服务数据进行清洗、去重和格式化,确保数据的一致性和准确性。2)特征提取。根据1.1描述的改进挖掘算法对预处理后的数据进行特征提取,得到每个数据点的特征向量。3)对照组方法实现。分别实现文献[4]和文献[5]中的数据整合方法,并应用于测试数据。4)本文方法实现。应用本文提出的电力中台服务数据整合方法对测试数据进行整合处理。5)性能评估。通过对比不同方法在整合数据完整性的表现,以评估本文方法的性能优势。
2.2 测试结果与分析
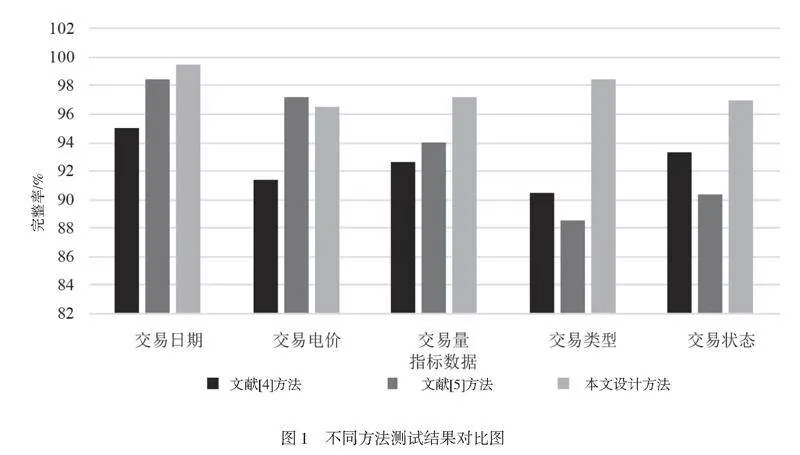
当分析3种不同方法测试结果时,本文将整合数据的完整性作为具体的评价指标,其中,对于整合后数据完整性的评价,分别以数据的交易日期、交易电价、交易量、交易类型以及交易状态作为指标,通过分类各指标尺度下整合后对应测试电力中台服务数据与原始数据之间的比例关系对整合效果进行分析。3种不同数据整合方法具体的测试结果如图1所示。
结合图1所示的测试结构可以看出,在3种不同整合方法下,测试电力中台服务数据完整性的控制效果表现出了较为明显的差异。其中,在文献[4]提出以概率-非概率样本为基础的数据整合方法下,各指标数据对应的完整性相对稳定,但是具体的水平存在进一步提升的空间,基本稳定在90.0%~95.0%;在文献[5]提出以人工智能技术为基础的数据整合方法下,各指标数据对应的完整性出现了较明显的波动性,对应的最大值达到了98.5%(交易日期),最小值仅为88.0%(交易类型),表明其对不同指标数据的整合效果在稳定性方面存在进一步提升的空间;在本文设计数据整合方法下,不仅对各指标数据的完整性始终保持较高的稳定状态,而且对应的完整性水平也始终处于较高状态,在96.5%~99.5%区间内小幅波动。结合上述的测试结果以及对应的分析可以得出结论,本文设计的基于改进挖掘算法的电力中台服务数据整合方法可以实现对数据进行有效整合的目标。
3 结语
为了能够最大限度地提高数据的利用效率,使数据在关决策中发挥更大价值,对数据进行整合处理是极为必要的。因此,本文提出基于改进挖掘算法的电力中台服务数据整合方法研究,在结合电力中台服务数据的特征对挖掘算法进行适应性改进后,切实实现了对数据进行有效整合的目标,在极大程度上保证了数据的完整性。借助本文的设计与研究,希望可以为实际的数据整合提供有价值的参考。
参考文献
[1]郭丽,孙华.基于K-means和支持向量机SVM的电力数据通信网络流量分类方法[J].网络安全技术与应用,2024(4):64-66.
[2]常荣,徐敏.基于改进K-Means和DNN算法的电力数据异常检测[J].南京理工大学学报,2023,47(6):790-796,858.
[3]张锦元.基于时间序列的电力工程基建项目前期费用整合模型设计[J].中国管理信息化,2023,26(21):100-103.
[4]刘晓宇,金勇进,倪成.大数据背景下概率-非概率样本的数据整合推断——从误差校正的视角出发[J].统计研究,2023,40(8):149-160.
[5]冯国礼,李蓉,吴双.基于人工智能技术的电力信息系统运维数据整合方法[J].电力信息与通信技术,2022,20(1):68-73.
[6]胡学强.基于大数据挖掘的电力客服中台数据智能整合方法[J].自动化技术与应用,2023,42(3):117-121.
[7]何立恒,吕萌,朱婷茹.DMSP-OLS与NPP-VIIRS夜间灯光遥感影像数据整合[J].测绘通报,2023(1):31-38.
[8]邵泽兴,张雨,陈鹏,等.基于FME的自然灾害风险普查数据整合与质检方法研究——以房屋建筑普查为例[J].地理空间信息,2022,20(9):14-17.
[9]徐进.能源电力企业战略性重组与专业化整合的新思考[J].能源,2022(3):35-39.
