基于CS与模糊均值的电力客户画像模型研究
2024-12-19杨帅张伟郭浩朱银龙石振东



摘 要:本文基于CS算法和模糊均值算法,研究了电力信息化客户画像模型,旨在提高电力企业对客户的了解和服务水平。本文收集了客户的个人信息和消费行为数据,利用CS算法进行特征选择和数据降维,并运用模糊均值算法进行聚类分析,最终得出客户的画像结果。试验结果表明,该模型能够对客户进行准确分类和描述,为电力企业提供精准的市场营销和服务决策支持。
关键词:CS算法;模糊均值算法;电力信息化;客户画像
中图分类号:TM 721 " " " 文献标志码:A
随着电力行业快速发展和电力市场的竞争加剧,电力企业需要更好地了解客户需求和行为,以提供个性化的服务和精准的营销策略[1]。客户画像模型是电力信息化的核心技术之一,帮助电力企业对客户进行分类和描述,从而进行精准营销和个性化服务[2]。本文基于CS算法和模糊均值算法,研究了电力信息化客户画像模型,旨在提高电力企业的市场竞争力和服务水平。
1 基于CS算法和模糊均值算法的电力信息化客户画像模型构建
1.1 电力信息化客户信息采集
用电需求:假设电力营销客户的特征域分量为p,表示客户在不同方面的特征,例如用电量、用电时间和用电设备等。客户在梯度方向上的用电强度为d,表示客户用电的强度和变化趋势[3]。采集客户信息的时间为t,表示信息采集的时间段。用电需求Q(x,t)如公式(1)所示。
(1)
式中:δ为对客户信息进行采集和分析的操作;u为多个特征分量的集合;∂为客户特征分量对电力需求的变化率;x为对客户信息进行梯度方向上的处理或分析。
用电输出:通过采集和记录这些信息,电力企业能够更好地了解客户的身份和联系方式,以便进行个性化服务和沟通。假设客户特征域信息为H,客户用电总量为O,客户信息为U,则用电输出信息D(l)如公式(2)所示。
D(l)=O∙H(k-1)+U(k) " " " " " " " " "(2)
式中:k为客户信息维度。
用电分布:由于前两部分的信息采集导致客户画像信息分布散乱,使客户的特征分量在空间上没有明显的规律或趋势,无法准确了解客户的用电需求和行为特征。为了更好地进行电力营销,需要进行第三部分的信息采集。在第三部分的信息采集中,假设客户的用电分布特征为r,表示客户在空间上的用电情况,包括用电量、用电时间和用电设备等方面[4]。采集和分析这些用电分布特征,更准确地了解客户的用电需求和行为特征,为电力企业提供个性化的营销策略和服务。同时,设梯度方向上的客户用电信息输出为o。梯度方向是指函数在某一点上变化率最大的方向,本文的梯度方向表示客户用电分布特征的变化趋势或规律。采集和分析梯度方向上的客户用电信息输出o,更好地理解客户用电行为的演化和变化趋势,为电力企业提供更准确的用电需求预测和优化方案。客户画像用电分布信息值C如公式(3)所示。
C=ox+r " " " " " " " " " " " " " (3)
1.2 电力信息化客户信息预处理
使用插值方法,例如均值插值或回归插值来填充缺失的数据。在缺失数据较多的情况下,需要考虑删除含有缺失数据的记录,以保证数据的完整性和准确性。此外,去除或修改数据源中的格式错误,包括修正数据的格式错误,例如日期格式错误或数值格式错误,或者删除含有格式错误的数据记录。
为了实现数据的一致性和可比性,需要建立一个数据字典或映射表。数据字典的作用是将不同的命名映射为统一的编码,以保证不同数据源中的相似数据能够被正确匹配和比较。使用数据字典可以避免由不同命名导致的数据混乱和错误,提高数据的整体质量和可管理性。
在数据处理过程中,需要仔细检查数据的范围、关联关系和逻辑约束等方面。判断数据的逻辑性错误可以保证数据的准确性和可靠性。例如,检查数据是否符合预设的范围和逻辑规则、是否存在不一致或矛盾的关联关系以及是否满足特定的逻辑约束条件,以便发现并纠正数据中的问题,保证数据的质量和可靠性,从而提高数据处理的效率和准确性。
识别和删除重复的数据记录,保证数据的准确性和一致性。设置合理的数据范围或使用数据验证的方法去除编造的或不合理的数据,保证数据的可靠性[5]。调整数据源中的数据冲突问题,获得更准确、一致的数据,为后续的分析和决策提供可靠基础。
数据标准化是数据处理过程中非常关键的一步,旨在将不同数据源中的数据统一为相同的格式和单位,从而使数据更易于进行比较和关联分析。数据标准化可以消除数据源间的差异性,保证数据在不同系统或环境下的一致性和可比性。数据标准化还有助于提高数据的可读性和可理解性,使数据更容易被分析和利用。另外,数据规范化是数据处理中的另一个重要环节,它将数据转换为标准的数据类型和范围,以便更好地进行数据关联和分析。数据规范化可以保证数据的一致性和准确性,避免出现数据类型不匹配或范围不符合要求的情况。数据规范化还有助于提高数据的质量和可靠性,减少数据处理过程中的错误和失误,提高数据分析的准确性和效率。
1.3 电力信息化客户信息关联性
支持度约束。在数据分析中,需要限制项集(ψ→ϑ)的出现次数,以确定该项集在数据源中的重要程度。在电力营销主体客户的数据采集中,将每个客户对应的属性值(ϑ)与客户本身(ψ)组成一个项集。在一个数据采集周期T中,采集到n个电力营销主体客户,从而形成n个项集,即n项集。每个项集都由客户(ψ)及其对应的属性值(ϑ)组成。为了评估每个项集的重要性,需要计算其支持度。支持度是指项集(ψ→ϑ)在数据源中的出现次数,用{ψ,ϑ}的出现次数来表示项集的支持度,支持度统计了在数据源中同时出现客户(ψ)及其对应属性值(ϑ)的次数。支持度约束的目的是计算项集的出现次数(O(ψ∪ϑ)),以确定其在数据源中的重要程度。如果一个项集出现的次数较少,那么它不具有较高的重要性。相反,如果一个项集出现的次数较多,那么它具有较高的重要性,如公式(4)所示。
(4)
置信度约束。在电力营销中,需要了解不同属性值(ϑ)与特定客户(ψ)间的关联程度,以确定是否将该属性值添加到该客户的画像中。为了评估这种关联程度,需要使用置信度。置信度是指属性值(ϑ)出现在电力营销主体客户(ψ)中的概率。在给定客户(ψ)的情况下,计算属性值(ϑ)同时出现的次数与客户(ψ)出现的次数之比,可以得到置信度。计算置信度可以确定在给定客户(ψ)的情况下属性值(ϑ)出现的概率。如果置信度较高,说明属性值(ϑ)在该客户(ψ)的画像中具有较强的关联性。相反,如果置信度较低,说明属性值(ϑ)与该客户(ψ)的关联性较弱,如公式(5)所示。
(5)
式中:ρ(ψ,ϑ)为属性值(ϑ)出现在电力营销主体客户(ψ)中的概率;P(ψ|ϑ)为在给定客户(ψ)的情况下,属性(ϑ)出现的次数与总客户数之比;P(ψ∪ϑ)为在给定客户(ψ)的情况下,同时具有属性(ϑ)的次数与总客户数之比;P(ψ)为在给定的时间周期内,客户(ψ)重复出现的次数与总客户数之比。
1.4 电力信息化客户画像模型建立
在样本数量为c的情况下,构建一个大小为c×J的计算矩阵。矩阵中的每个元素用二进制表示,其中1表示属性值ϑ在对应的电力营销主体客户ψ中出现,0表示不出现。计算矩阵可以了解每个电力营销主体客户ψ与属性值ϑ间的关系。通过分析矩阵的行、列以及整体模式,可以发现不同属性值与电力营销主体客户间的关联程度,分别如公式(6)~公式(8)所示。
ϑ-x=αϖ+λ " " " " " " " " " " "(6)
(7)
(8)
式中:φjc为聚类中心J在属性值c上的中心位置;δγ为属性值的适应度,是指每个属性值在电力营销主体客户样本中的适应程度或匹配程度;γ为模糊因子;L为电力营销客户样本ψi与第j个聚类中心间的相似度或距离程度;ψi为电力营销客户样本;θij为电力营销客户样本ψi属于第j个聚类中心的程度。
根据具体的评估标准或指标衡量适应度,例如属性值的频率、重要性和相关性等。如果对应的电力营销主体客户ψ的属性值划分结果能够满足每个属性值的适应度δγ,那么表明客户画像模型能够准确反映电力营销主体客户的属性值分布和特征。换句话说,模型能够将每个客户的属性值划分到与其适应度最高的类别或聚类中心中。
2 试验结果
2.1 电力信息化客户画像模型构建
2.1.1 电力信息化客户信息采集
采集客户的基本信息,包括姓名为X女士、性别为女性、年龄为30岁、身高为165cm、体重为56kg、受教育程度为硕士、婚姻状况为已婚、居住地为F小区、信用透支情况为无、没有儿女、工作方向是超市销售、消费情况为每月4000元、社交风格为知识青年、职位是主管、兴趣爱好是运动以及常用的App为腾讯和阿里等信息。这些信息将作为构建电力信息化客户画像模型的基础数据。
2.1.2 电力信息化客户信息预处理
采集信息后,对客户信息进行预处理,包括数据清洗、缺失值处理和异常值处理等步骤,保证数据的准确性和完整性。进行数据预处理能够提高后续建模的准确性和可靠性。
2.1.3 电力信息化客户信息关联性
利用CS算法和模糊均值算法对客户信息进行关联性分析。这些算法有助于发现客户信息间的关联规律和模式,从而揭示客户画像中隐藏的信息和特征。分析客户信息的关联性可以更好地理解客户的行为和需求,为后续建模提供重要参考。
2.1.4 电力信息化客户画像模型建立
基于CS算法和模糊均值算法的结果建立电力信息化客户画像模型。该模型会综合考虑客户的各项信息特征,包括个人基本信息、消费行为、社交风格和兴趣爱好等,构建客户的全面画像,以更好地了解客户群体的特点和需求,为电力系统营销提供个性化服务和精准营销策略。
2.2 试验结果分析
2.2.1 第一组试验结果
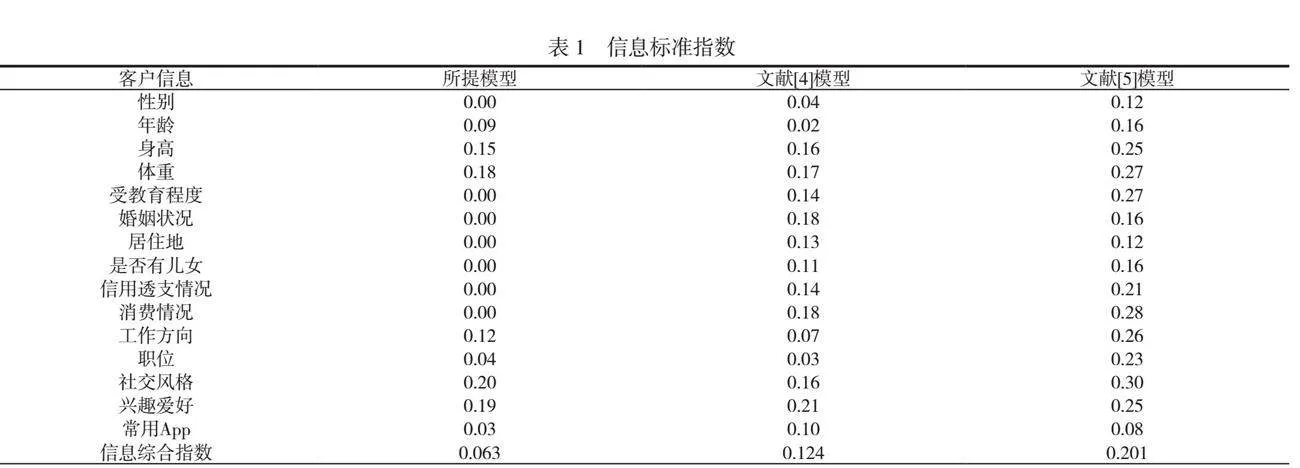
采用信息标准指数,验证3组模型构建的客户画像与客户实际信息的拟合度。信息标准指数见表1。
本文提出的模型在各项客户信息的拟合度方面具有显著的优势。在性别、受教育程度、婚姻状况、居住地、是否有儿女、信用透支情况和消费情况等方面,本文模型的拟合度均为0,即完全拟合了客户的信息。模型能够准确反映客户在这些方面的特征和情况,为电力信息化客户画像提供了精准描述和分析。在其他客户信息方面,例如年龄、身高、体重、工作方向、职位、社交风格、兴趣爱好和常用App等方面,本文模型的拟合度也表现出较高水平,其指数值均为0.09~0.20,说明模型对这些信息的解释能力较强,能够较好地捕捉客户的特征和行为习惯。与文献中提到的其他模型相比,本文模型在这些方面的拟合度更高,具有更优越的性能和准确性。综合各项客户信息的拟合度,本文模型的信息综合指数为0.063,文献中提到的其他模型的信息综合指数分别为0.124和0.201,可见本文模型在整体拟合度方面更优越,表明本文模型能够更全面、准确地描述客户的特征和行为,能够为电力信息化客户画像的建立和分析提供更可靠的依据和支持。综上所述,本文模型进行了各项客户信息的综合分析和拟合度评估,为电力系统的客户管理和营销策略的制定提供了重要的参考和指导。
2.2.2 第二组试验结果
采用规范拟合指数,验证3组模型构建的客户画像与客户实际信息的拟合度。规范拟合指数见表2。
本文模型在规范拟合度方面具有显著优势。在所有客户信息中,本文模型的规范拟合指数均为1.00,即完全符合规范拟合的要求,而文献中提到的其他模型的规范拟合度为0.84~0.98,说明本文模型对各项客户信息的拟合程度非常高,符合规范拟合的标准,能够为电力信息化客户画像的构建提供可靠的基础。综合各项客户信息的规范拟合度,本文模型的信息综合指数为1.00,其他模型的信息综合指数分别为0.91和0.84,可见本文模型在整体规范拟合度方面表现更优,表明本文模型全面符合规范拟合的要求,能够为电力系统的客户管理和营销策略的制定提供更可靠的依据和支持。
3 结语
本文基于CS算法和模糊均值算法,研究了电力信息化客户画像模型。试验结果表明,本文模型能够准确地对客户进行分类和描述,为电力企业提供精准的市场营销和服务决策支持。然而,本文研究还存在一些局限性,例如数据采集的难度和数据处理的复杂性等。未来的研究将进一步优化模型算法,提高模型的准确性和效率,同时探索更多的客户画像因素,以满足电力企业日益增长的需求。
参考文献
[1]陈娟,夏鹏,梁晓伟,等.基于CSPSO-K-means算法的电力客户细分及定制化增值服务系统研究[J].微型电脑应用,2021,37(10):90-93.
[2]史尊伟,李韫莛,陈敏,等.基于多维关联细粒度的电力信息化客户画像模型研究[J].信息技术,2023,47(7):179-184.
[3]刘紫微,杨晓忠.一种基于CS-FCM算法的模糊时间序列预测模型[J].应用数学学报,2022,45(3):322-338.
[4]王林信,周盛成,罗世刚,等.基于改进词向量模型的电力缴费用户画像关键技术研究[J].电力信息与通信技术,2022(2):42-48.
[5]陈幸,陈盛华,陈国华,等.基于改进模糊均值聚类算法的遥感图像分割技术[J].沈阳工业大学学报,2023,45(6):716-720.
