低照度图像增强算法研究
2024-12-19陈惠妹曹斯茹金可艺






摘 要:在弱光条件下会出现一些质量低的图像,这类图像可能会受到噪声、曝光和对比度低等问题的影响,导致视觉质量下降。本文针对该问题提出一种在语义引导低照度图像增强网络基础上的改进模型,简称NSG-LLIE(New Semantic Guided-Low light image enhancement)。首先,在增强网络中加入SE通道注意力机制模块,该模块能够抑制噪声引起的特征干扰训练。其次,在SE模块的基础上加入非局部均值模块,使系统在增强过程中能够保留全局特征,减少曝光情况。最后,在DarkFace数据集中进行对比试验,结果表明,与原模型相比本文的PNSR、SSIM和NIQE分别提高了1.93、0.07和0.37。
关键词:低照度图像;通道注意力机制;非局部均值
中国分类号:TP 391 " " " 文献标志码:A
在现实生活中,由于获取图像的设备较差以及环境等因素,因此会得到一些低质量的图像。这类图像一般会有整体偏暗、对比度差以及细节不明显问题。
为解决暗低照度图像出现的视觉问题,研究人员利用Retinex-Net低照度图像增强网络得到一种基于Retinex和深度学习的改善低照度条件下的图像质量方法。KinD网络在Retinex-Net基础上进行改进,增强了光照不均匀处理能力。JIANG等[1]提出的EnlightenGAN是一种无监督的GAN网络,其能够增强未配对的低照度图像画质,不再受参考图像制约,并且可以降低图像获取的成本。LI等[2]基于Zero-DCE++算法设计了一种轻量级的光增强曲线逼近网络。张亚邦等[3]对低光照图像的亮度通道的主要结构和边缘细节分别进行对比度增强,更好地抑制图像细节丢失。
语义信息在高级视觉任务中十分重要,但是研究人员忽略了语义信息,因此语义引导低照度图像增强(Semantic-Guided Zero-shot,SGZ)采用一种新的语义损失来保留图像中的语义信息,在复杂场景中的低照度图像在增强过程中不会破坏图像的高层次语义结构。为了进一步提高图像增强的效果,本文在该网络中引入通道注意力机制和非局部均值模块,能够帮助模型更好地捕捉图像中的重要特征和全局上下文信息,降低图像噪声和曝光度,提升图像增强效果。
1 语义引导低照度图像增强
基础模型语义引导低照度图像增强网络是在没有配对图像、配对数据集和分割标注的情况下训练的,其结合无监督学习和语义信息,能够增强低照度图像亮度。包括以下3个网络。
1.1 增强因子提取网络
增强因子提取(Enhancement Factor Extraction,EFE)网络的主要功能是学习并提取低光照图像中的像素级光照不足信息。具体来说,EFE网络具有深度可分离卷积层和跳跃连接结构,能够有效地捕捉图像中的细粒度特征,并将这些特征转化为一个增强因子。这个增强因子记录了图像中每个像素点的光照不足程度,为后续的图像增强过程提供关键信息。学习低光照图像的像素级光照不足情况,EFE网络能够准确地捕捉这些信息并对其进行编码,使增强因子成为后续图像增强网络的重要参考。
1.2 递归图像增强网络
递归图像增强(Recurrent Image Enhancement,RIE)网络可以逐步调整图像的亮度和对比度,使低光照图像逐渐清晰、明亮。这种方法不仅提高了图像的视觉质量,还保留了图像中的结构信息和重要细节,保证增强过程的自然性和一致性。RIE网络利用从EFE网络得到的增强因子以及先前阶段的输出逐步增强低光照图像。
1.3 无监督语义分割网络
为了保留图像增强过程中的语义信息,无监督语义分割(Unsupervised Semantic Segmentation,USS)网络采用无监督方法发现图像中的潜在语义区域,然后将这些区域的特征作为辅助信息,完成零样本的目标任务。与此同时,对增强后的图像进行精确的逐像素分割,并利用语义损失函数保留在图像渐进增强的过程中的语义信息。
1.4 损失函数
为了提升图像增强效果,图卷积(Simple Graph Convolution,SGC)网络设计了多个损失函数,包括空间一致性损失、亮度损失、总变分损失和语义损失。下面详细介绍每个损失函数的设计及其作用。
1.4.1 空间一致性损失
空间一致性损失的作用是保证增强后的图像在空间中的结构与原始图像一致。计算增强图像与低光照图像在空间域内的梯度差异得到空间一致性损失,如公式(1)所示。
(1)
式中:Lspa为空间一致性损失;A为局部区域的边,本文设为4;i为从1遍历至4的像素单元;j为遍历ϕ(i)的邻域值;ϕ(i)为4个相邻单元(上,下,左,右)的邻域值;Yi、Ii分别为增强图像和弱光图像在i像素单元处的像素值;Yj、Ij分别为增强图像和弱光图像在相邻单元处的像素值;α为非邻域值的权重系数,本文设为0.5;k为遍历ϑ(i)中的邻域值;ϑ(i)为4 个非相邻单元(左上,右上,左
下,右下)的邻域值;Yk与Ik分别为增强图像和弱光图像在非相邻单元处的像素值。
1.4.2 亮度损失
亮度损失的作用是控制图像的全局亮度,保证增强后的图像在亮度方面达到预期效果。计算图像整体亮度的差异来得到亮度损失,计算过程如公式(2)所示。
(2)
式中:Lbri为亮度损失;Ya为在a处的像素值;E为将特定区域的平均像素值降至预定曝光水平,也就是理想的图像曝光值,本文设为0.60。
1.4.3 总变分损失
总变分损失的作用是减少图像中的噪声,提高图像的平滑度和视觉质量。其计算过程如公式(3)所示。
(3)
式中:Ltv为总变分损失;C、H和W分别为图像的通道、高度和宽度;c、h和w为索引变量,其作用是遍历所有的通道、高度和宽度,取值为[1,C]、[1,H]和[1,W];Δx和Δy分别为水平和垂直的梯度;Yc,h,w为增强后的图像在c、h和w处的像素值;(ΔxYc,h,w)+(ΔyYc,h,w)为图像的梯度总和,最小化该损失可以使图像更加平滑、自然。
1.4.4 语义损失
语义损失可以保留图像中的语义信息,保证增强过程不会破坏图像的高层次语义结构。该损失函数利用预训练的语义分割网络提取图像的语义特征,计算图像增强前后在语义特征空间的差异。其计算过程如公式(4)所示。
(4)
式中:Lsem为语义损失,参考焦点损失来编写成本函数。该损失不需要分割标签,只需要1个预先初始化的模型β1、β2为焦点系数;ρi,j 为分割网络在高度为i、宽度为j的像素点的估计类概率;(1-ρi,j )为在二分类交叉熵损失基础上加入的一个调节因子,可以使模型更关注错分的样本。
2 改进的语义引导低照度图像增强
2.1 SE通道注意力机制模块
利用EFE和RIE网络对图像进行增强后,模型不能很好地捕捉能够使光照增强的信息并产生噪声,为了提高图像质量,降低噪声,突出有用信息,本文引入SE通道注意力机制模块,如图1所示。
2.1.1 全局平均池化
SEBlock会对输入的特征图执行全局平均池化操作,将特征图的每个通道都压缩成一个标量值。
2.1.2 全连接层和激活函数
SEBlock利用2个全连接层和ReLU激活函数生成每个通道的权重。
2.1.3 Sigmoid激活和扩展
利用Sigmoid激活函数将权重调整至0~1,并将其扩展至原始特征图的维度。
2.1.4 通道重新加权
将这些权重与原始特征图逐元素相乘,在通道间进行自适应加权。
2.2 非局部均值模块
基础模型经常会出现过曝光的情况,因此本文引入了非局部均值(Non-Local Means,NLM)模块,如图2所示,NLM模块有助于捕捉全局的特征信息,通道注意力机制能够调整不同通道的重要程度,评估像素之间的相似性。结合两者可以同时关注全局特征,使系统在增强过程中能够更有效地保留全局特征。如果局限于局部的邻域像素,那么训练效果不佳,例如曝光过于严重以及某些地方没有加强。增强低照度图像的全局特征可以提供关于图像整体属性和结构的信息,这些信息可以在模型学习的过程中作为参考,帮助模型更好地理解图像并确定哪些区域需要多加强,哪些区域需要适度加强。具体步骤如下。
2.2.1 降维卷积
NLM模块利用1×1卷积层将输入特征图的通道数减半,以降低计算复杂度。
2.2.2 展平和转置
将降维后的特征图展平并转置,以计算自相似度。
2.2.3 自相似度计算
先计算特征图中所有像素之间的相似度,然后利用Sigmoid激活函数进行处理,使结果为0~1,生成相似度矩阵。
2.2.4 特征重建
根据相似度矩阵对降维后的特征图进行加权求和,重建特征图。
2.2.5 恢复维度
利用1×1卷积层将特征图的通道数恢复为原始维度,并与输入特征图相加,融合全局上下文信息。
2.3 改进后的整体网络模型
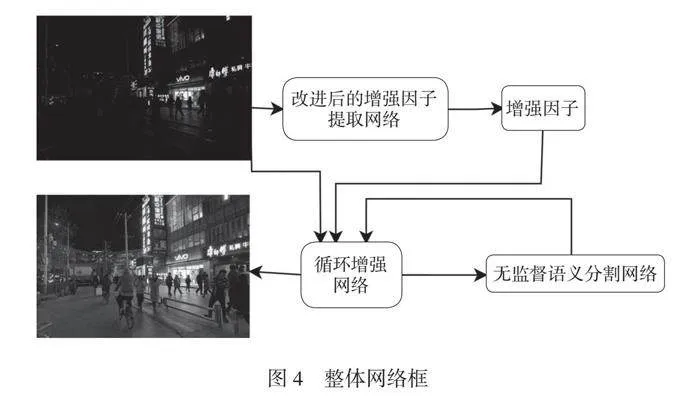
将SE模块与非局部均值模块串联至EFE网络的卷积层中,得到改进的增强因子提取网络,如图3所示。融合SE通道注意力机制模块和非局部均值模块的语义引导低照度图像增强。NSG-LLIE整体网络框如图4所示。
3 试验与结果分析
本文模型使用深度学习框架Pytorch在单个NVIDIA 4060Ti GPU中进行100批次的训练,初始学习率为0.000 1。批处理大小为6,需要约3 h来进行收敛。在每个训练迭代中进行前向传播。将低光照图像输入增强网络,经过一系列卷积层、SE block、Non-Local Means和光照模块,输出增强后的图像,前向传播过程是计算网络对输入图像进行处理并生成输出图像的过程。采用反向传播算法计算损失的梯度,并使用Adam优化器更新网络参数。反向传播过程是计算损失函数对网络参数的梯度来调整网络参数的过程,使损失逐渐降低,模型性能逐渐优化。
3.1 数据集
在DarkFace数据集中有6 000 张在极端低光照条件中拍摄的图像,因为光照不足,所以不能准确检测和识别这些图像中的人脸。图像在街道、商店和家庭等多种场景中拍摄,其具有多样性,为评估低光照图像增强算法的鲁棒性和通用性提供了良好的测试环境。
3.2 试验结果
本文从DarkFace数据集中选择400张低光图像作为测试数据,低照度图像与改进前后增强的图像如图5所示,观察增强图像的灯笼、店铺牌可知改进后曝光情况减少,观察树周围可知改进后噪声情况减少。试验结果表明需要提升亮度与对比度,也要减少噪声、曝光与失真的情况。
将本文模型与2018年至今的热门的低照度图像增强模型进行比较,包括基础模型SGZ、Retinex-net、KinD、Zero-DCE++和DID。使用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似指数(Structural Similarity Index,SSIM)和无参考图像质量评估器(Natural Image Quality Evaluator,NIQE)来评估模型的性能。不同模型评价指标见表1。由表1可知,DID的PSNR最高为23.99,本文模型PSNR为23.29,并没有获得最好的效果,在图像的细节保持程度上还有不足。由于PSNR不能完整地反映图像的好坏,还需要利用其他指标或者图像增强后的视觉效果来评判图像的质量,因此得到的增强后的图像整体保真度较高,噪声较小。本文模型的SSIM最高,为0.92,说明增强前后图像在结构上非常相似。本文模型的NIQE也最高,为3.27,该指标可以较好地模拟人眼对低照度图像质量的判断,说明本文图像视觉效果较好。
4 结语
本文针对基础模型中出现的噪声和曝光问题提出一种基于SE通道注意力机制模块和非局部均值模块的语义引导低照度图像增强的模型(NSG-LLIE)。试验结果表明,与原模型相比,PSNR、SSIM和NIQE分别提高了1.93、0.07和0.37,低照度图像视觉效果更好。增强后的图像可以在后续人脸识别、目标检测[4]和夜间驾驶[5]等领域中发挥重要作用。
参考文献
[1]JIANG Y,GONG X,LIU D,et al.Enlightengan:Deep light
enhancement without paired supervision[J].IEEE Transactions on image
processing,2021(30):2340-2349.
[2] LI C,GUO C,LOY C C.Learning to enhance low-light image
via zero-reference deep curve estimation[J].IEEE Transactions on pattern
analysis and machine intelligence,2021,44(8):4225-4238.
[3]张亚邦,李佳悦,王满利.基于HSV空间的煤矿井下低光照图像增强方法[J].红外技术,2024,46(1):74-83.
[4]陈科圻,朱志亮,邓小明,等.多尺度目标检测的深度学习研究综述[J].软件学报,2021,32(4):1201-1227.
[5]祝文斌,苑晶,朱书豪,等.低光照场景下基于序列增强的移动机器人人体检测与姿态识别[J].机器人,2022,44(3):299-309.
