LNG富氢尾气在苯加氢装置中的应用分析
2024-12-16李乃厚



摘 要:本研究旨在探讨将“ARIMA+LSTM”模型应用于苯加氢装置中的焦炉煤气制LNG富氢尾气的负荷预测,即采用“ARIMA+LSTM”模型,并将ARIMA模型和LSTM模型的预测结果进行加权融合,从而得到更准确的负荷预测结果。试验结果表明,联合“ARIMA+LSTM”模型能够更准确地捕捉负荷数据的趋势和变化,比单独使用ARIMA或LSTM模型的预测准确性和可靠性更高。证明了“ARIMA+LSTM”模型在焦炉煤气制LNG富氢尾气负荷预测中的有效性和实用性,为压力系统的运行和调度提供了可靠支持,有望在工业生产实践中得到广泛应用。
关键词:富氢尾气;苯加氢;制氢
中图分类号:TQ 116 " " 文献标志码:A
焦炉煤气制LNG富氢尾气在苯加氢装置中的应用具有重要意义。然而负荷数据具有复杂性和不确定性,传统的预测方法通常难以满足实际需求[1]。因此,本文引入了“ARIMA+LSTM”模型,使ARIMA模型和LSTM模型的预测结果相结合,提高负荷预测的准确性和可靠性,并为相关领域的研究和实践提供参考。
1 工艺流程
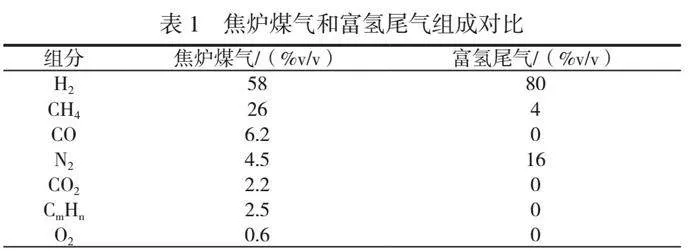
焦炉煤气和富氢尾气组成对比见表1。
2 工艺优化
需要在苯加氢装置中收集历史原料气压缩数据。这些数据包括原料气的压缩量、时间戳和其他相关信息。对这些数据进行清洗、处理和转换,以保证数据质量和准确性。清洗数据包括处理缺失值、异常值和重复值,而数据转换包括对数据进行归一化或标准化,以便更好地适应模型的训练和预测。
2.1 预净化工序流程
焦炉煤气的压力通常为4 kPa~10 kPa,温度为25 ℃~40 ℃,煤气由3台并联的预净化塔进行处理。其中2台是吸附塔,1台是再生塔。在预净化塔中,煤气经过变温吸附后,其中的萘、焦油、苯、氨和硫化氢等杂质被去除。经预净化塔处理后,煤气进入煤气压缩机进行一级压缩升压[2]。一部分压缩后的煤气用作预净化塔的再生气源,应用于再生吸附塔,使其能够持续进行吸附并去除杂质[3];另一部分压缩后的煤气则被送到预处理工序,以进一步净化。
2.2 预处理工序流程
预处理是指进一步处理经一级压缩升压后的预净化气,以脱除其中的萘、焦油、苯、氨和硫化氢等杂质和污染物,提高煤气的纯度和质量[4]。首先,一级压缩升压将煤气压力提升至0.14 MPa~0.16 MPa,为后续的预净化处理创造适当的压力条件,有助于提高处理效率,保证杂质更容易被去除。其次,煤气由预处理塔进行变温吸附的预净化处理,去除萘、焦油、苯、氨和硫化氢等杂质,提高煤气的纯度和质量,减少对后续设备的损害,提高最终产品的安全性和有效性。再次,预处理后的煤气再次经过煤气压缩机进行二、三级压缩升压,压力逐渐提升至1.6 MPa~1.65 MPa,以适应后续处理工序并有效控制设备负荷,保证系统稳定运行。最后,将升压后的煤气送至变压吸附工序,进行深度处理和分离,控制压力变化,选择性地吸附特定成分,为后续的产品提纯和分离奠定基础。
通过上述压缩升压步骤,煤气的压力逐渐升高,最终升至1.6 MPa~1.65 MPa。升压后的煤气被送至变压吸附工序,用于后续的处理和分离。适当的压力有助于提高吸附效率,使杂质更易去除。进而煤气进入5个并行工作的吸附塔,在此过程中,除氢气以外的杂质均被有效吸附,氢气的纯度得到提高,这是该工序的核心步骤。处理后得到的半产品氢气纯度约为99.9%,氧气含量仅为0.1%,表明吸附过程具有有效性,并为后续应用奠定了良好基础。最后,半产品氢气被送至脱氧干燥工序进行进一步处理,以去除残余的氧气和水分,保证氢气在后续应用中的质量和稳定性。
脱氧干燥工序的主要步骤包括半产品氢气的加热、进入脱氧器、反应过程、冷却与水分离、干燥处理、缓冲罐存储以及最终产品的获得。首先,半产品氢气在脱氧加热器中被加热至50 ℃~100 ℃,以提高气体温度,促进后续反应并增强催化剂活性。加热后的气体进入脱氧器,在钯催化剂的作用下,氧气与氢气发生反应并生成水,从而有效去除氧气,提升氢气的纯度。其次,气体通过冷却器和预水分离器,使水蒸气凝结为液态水,并将其分离,以保证氢气的干燥程度,减少后续处理负担。最后,脱氧后的氢气进入干燥器,进一步去除微量水分,以保证最终产品的质量。干燥后的氢气被送入产品氢气缓冲罐,以平衡气体的压力和流量,保障系统的安全性和稳定性。经过这一系列处理,最终的产品氢气纯度为99.99%,表明脱氧干燥工序具有有效性,能够满足各种工业和科研应用的需求。
3 具体应用
3.1 原始数据
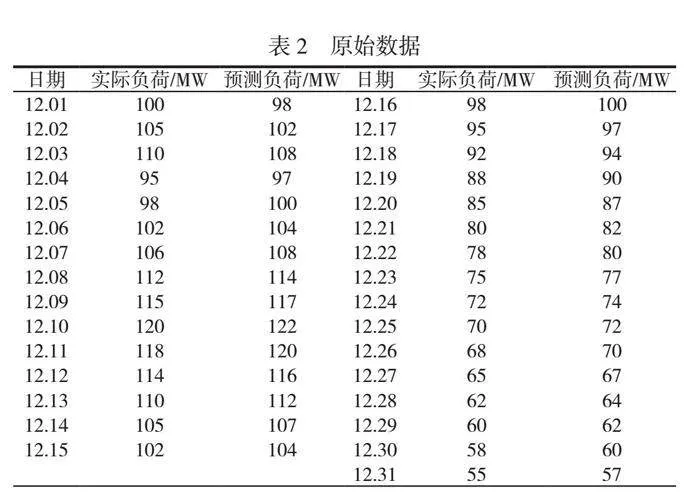
选用某地2022年12月共31天的“焦炉煤气制LNG富氢尾气在苯加氢装置中的应用”负荷数据,见表2。这些负荷数据为每小时检测一次,因此每天会有24个数据点。
3.2 ARIMA模型预测结果
建立ARIMA模型前,需要使用历史数据来构建模型,包括ARIMA模型的阶数和参数,这些参数将影响模型的预测能力。确定ARIMA模型的阶数和参数是关键步骤,需要对数据的自相关性和偏自相关性进行分析,选择合适的模型进行建模和预测。在建立ARIMA模型的过程中,需要考虑焦炉煤气制LNG富氢尾气的含氢量可能受多种因素的影响,例如生产工艺、原料质量和操作条件等。
首先,对选定的负荷数据进行预处理和分析,包括数据清洗、处理缺失值/异常值、数据转换和归一化等操作。其次,构建ARIMA模型,确定模型的阶数和参数,对负荷数据的时间序列进行建模和预测。由负荷数据的自相关与偏自相关分析结果可知,当阶数为6时,系数接近于0,并且后续阶数基本落在2倍标准差范围内。因此,可建立一个ARIMA(6,1,6)模型,对压力负荷的趋势进行预测。但是预测结果的幅值存在明显偏移,最大预测误差绝对值为287 MW。出现该偏差的原因是原始负荷数据中存在较多非周期成分,导致ARIMA模型适用性下降。非周期成分是指在负荷数据中无法被周期性模式或趋势模式解释的部分[3],该部分由天气、节假日和特殊事件等因素引起[4]。ARIMA模型主要适用于具有明显周期性和趋势性的数据,对于含有较多非周期成分的数据,其预测效果会受到限制。
3.3 LSTM模型预测结果
设计LSTM模型的网络结构是关键步骤之一,包括确定输入层、隐藏层、输出层和每个层的神经元数量,并确定激活函数。此外,还需要确定神经网络的参数,以便捕捉原料气压缩的时间序列特征。输入层的数量应该与时间序列数据的维度相匹配;隐藏层的数量和神经元数量需要根据数据复杂度和模型的训练效果来进行调整;输出层的数量为1,用于预测含氢量的数值。在捕捉焦炉煤气制LNG富氢尾气的含氢量时间序列特征过程中,激活函数包括ReLU、Sigmoid和Tanh等。
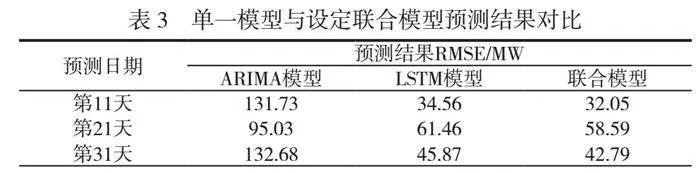
对数据进行预处理,包括归一化、序列化等操作,以便输入LSTM模型并进行训练和预测。经过试验和调整,本文发现LSTM模型能够对压力负荷进行一定预测。试验比较了2种不同类型的LSTM模型,一种是带有重置网络的LSTM模型,另一种是没有重置网络的LSTM模型。结果显示,带有重置网络的LSTM模型的预测结果比没有重置网络的LSTM模型更贴近实际的负荷曲线。重置网络是LSTM模型中的一种机制,能帮助模型更好地捕捉时间序列数据中的长期依赖关系和非线性特征。引入重置网络后,LSTM模型能够更准确地预测负荷数据的趋势和变化。单一模型与设定联合模型预测结果对比见表3。
3.4 基于“ARIMA+LSTM”的联合模型预测结果
使用“ARIMA+LSTM”模型对焦炉煤气制LNG富氢尾气的含氢量进行预测,帮助苯加氢装置操作人员提前了解尾气中氢气的含量,从而调整苯加氢反应的参数和条件。
在模型训练中,有ARIMA模型得到的负荷序列a、LSTM模型得到的负荷序列b以及相应的实际负荷序列s,均包括n个采样点[5]。为了综合利用ARIMA和LSTM模型的预测结果,对它们的负荷序列分别赋予权重ω1和ω2,其中ω1表示对LSTM模型负荷序列的重要性,ω2表示对ARIMA模型负荷序列的重要性。这2个权重需要满足ω1+ω2=1,以保证权重的总和为1,则训练过程中联合预测模型的误差ε如公式(1)所示。
ε=s-ω1a-ω2b=s-ω1b-(1-ω1)b " " " " " " "(1)
以联合预测模型误差最小化作为优化目标求解权重ω1*,如公式(2)所示。
ω1*=argmin|ε|=argmin[s-ω1b-(1-ω1)b] " " " " " " (2)
为寻求最优联合模型权重,利用随机优化搜索算法进行寻找。设目标函数为g(ω1),如公式(3)所示。
(3)
式中:bi为第i个LSTM模型得到的负荷序列;si为第i个实际负荷序列。
变异操作是基于3个随机个体Ar1、Ar2和Ar3进行的,第q个个体的第k次迭代Vq(k)如公式(4)所示。
Vq(k)=Ar1(k)+F·(Ar2(k)-Ar3(k)) (4)
式中:Ar1(k)、Ar2(k)和Ar3(k)分别为3个随机个体的第k次迭代;F为缩放因子。
交叉操作是将有N维分量的第q个个体的第u分量进行交叉,其结果Rqu(k)如公式(5)所示。
(5)
式中:Vqu(k)为第q个个体的第k次迭代的第u分量交叉结果;rand(0,1)为一个生成随机数的函数,通常用于生成一个在0~1均匀分布的随机数,在许多算法中,尤其是进化算法或遗传算法中,这个随机数用于引入随机性,以增加搜索空间的多样性;C为交叉率;j为随机整数;rand(1,N)为用于生成一个在1~N的随机整数的函数;N为个体的数量或某个特定的范围,用于选择随机个体或进行其他操作;Aqu(k)为随机个体的第u分量交叉结果。
对ARIMA模型和LSTM模型进行训练,训练过程需要调整反向传播算法和优化器,以最大程度地减少模型误差。将ARIMA模型和LSTM模型的预测结果进行集成,以综合利用其各自优势。采用加权平均等方法,将2个模型的预测结果相结合,得到更准确、稳定的预测结果。利用测试集数据对集成模型进行评估和验证,以评估模型的预测精度和稳定性。比较模型的预测结果和实际观测值,可以评估模型的准确性和可靠性,从而为模型的改进和优化提供参考依据。
基于尾气含氢量的预测结果,对苯加氢反应装置的操作参数进行优化。例如,根据尾气中氢气的含量调整催化剂的投入量和反应温度,以提高反应的效率和产物的质量。
联合模型预测方法流程如图1所示。实时监测焦炉煤气制LNG富氢尾气的含氢量,并与预测结果进行比较,及时发现苯加氢装置中的异常情况并调整反应条件,防止能源浪费和产品质量下降。焦炉煤气制LNG富氢尾气中的氢气是一种宝贵的能源。合理利用尾气中的氢气,例如将其作为还原剂或能源供应,能够提高能源利用效率,减少能源消耗和环境污染。对尾气含氢量进行预测和调控,以控制苯加氢反应的产物质量,保证产品符合规定的标准和要求。基于第11天的ARIMA模型和带有重置网络的LSTM模型的预测结果,进行联合模型权重系数寻优。采用优化算法,将数据带入公式(1)~公式(5),得出计算结果,得到权重系数ω1=0.9081和ω2=0.0919。进而利用这些优化的权重系数进一步得出第11天、第21天和第31天的联合模型预测结果。
单一模型与联合模型预测性能对比结果见表4。联合“ARIMA+LSTM”模型的预测结果与实际曲线非常接近,预测误差较小。将ARIMA模型和LSTM模型的预测结果进行加权融合,能够充分利用2种模型的优势,提高预测的准确性和可靠性。特别是在第11天、第21天和第31天的预测中,联合“ARIMA+LSTM”模型能够更准确地捕捉负荷数据的趋势和变化。将ARIMA模型和带有重置网络的LSTM模型进行融合,能够得到更可靠的负荷预测结果。这种联合模型的优势在于综合了2种不同模型的特点和优势,克服了单一模型的局限性。权衡不同模型的预测结果能够得到更全面、准确的负荷预测结果,优化能源利用并提高生产效率,为压力系统的运行和调度提供有力支持。
4 结语
本文基于“ARIMA+LSTM”模型,研究了焦炉煤气制LNG富氢尾气在苯加氢装置中的具体应用。将ARIMA模型和LSTM模型的预测结果进行加权融合,提高了负荷预测的准确性和可靠性。试验结果表明,联合模型能够更准确地捕捉负荷数据的趋势和变化,为压力系统的运行和调度提供有力支持。本研究对优化能源利用和提高生产效率具有重要意义,并为相关领域的研究和实践提供了有益参考。
参考文献
[1]翁小平,袁海雷,杨飞.先进控制和优化技术在苯加氢装置中的应用[J].燃料与化工,2023,54(4):45-48.
[2]张凯,栾义涛,付恩祥,等.优化苯加氢装置萃取剂再生塔运行的工艺研究[J].化工管理,2023(35):142-144.
[3]赵丽文,刘桂莲.苯加氢制环己烯装置能量系统集成及催化剂再生周期优化[J].化工学报,2022,73(12):5494-5503.
[4]姚良雨、张颂、刘伟.临涣焦化苯加氢装置废气处理工艺简介[J].燃料与化工,2020,51(6):48-49.
[5]关红燕.苯加氢装置产能挖潜改造实践与分析[J].煤化工,2023,51(2):94-96.
