基于大语言模型和RAG技术的高校知识库智能问答系统构建与评价
2024-12-12高雅奇
关键词:高校知识服务;智能问答系统;检索增强生成;机器学习
0 引言
随着信息技术的迅猛发展和高校知识服务需求的日益增长,传统的知识检索方式已难以满足用户需求。在此背景下,智能问答系统凭借其高效、精准、便捷等优势,成为提升高校知识服务水平的重要途径[1]。然而,将这些先进技术应用于高校知识库智能问答系统仍面临诸多挑战,例如高校知识的复杂性、用户查询的多样性以及系统性能的保障等。
为了解决上述挑战,本文提出了一种基于大语言模型(Large Language Models, LLM) 和检索增强生成(Retrieval-Augmented Generation, RAG) 技术的高校知识库智能问答系统。该系统旨在为高校师生提供高效、准确、个性化的知识服务。本文首先对相关技术进行分析,然后介绍系统的架构设计和功能模块,最后通过实验评估系统性能,并探讨未来的研究方向。
1 相关工作
本研究的相关研究工作分为知识源构建、智能问答技术和高校信息服务三个部分。
1.1 高校智能问答知识源构建
高校智能问答系统的核心在于其丰富、准确且结构化的知识源。知识源的构建过程,包括数据收集、文档处理、内容提取和知识组织等关键步骤。
1.1.1 知识源数据收集
高校智能问答知识源主要来源包括但不限于以下几个方面:
1) 教学资料:课程大纲、教学计划、讲义、试卷等。
2) 科研文献:学术论文、研究报告、专利文档等。3) 管理文件:规章制度、通知公告、会议纪要等。4) 学生服务:学生手册、就业指南、心理健康资料等。5) 校园生活:校历、活动安排、设施使用说明等。这些来源文件可能以多种格式存在,如纯文本(. txt)、PDF文件(.pdf)、Word文档(.doc/.docx)、HTML网页及图片等。
1.1.2 文档预处理
文档预处理是构建高质量知识源的关键步骤,主要包括以下几个方面:1) 文本清洗:使用正则表达式和自定义规则去除无关的标记、特殊字符和冗余信息。2) 格式标准化:将不同来源的文档转换为统一的UTF-8编码,便于后续处理。3) 元数据提取:从文档中提取标题、作者、日期等元信息,用于后续的知识组织和检索。
1.1.3 内容提取与分段
由于大语言模型(如Chat-GPT、BERT、文心一言等)通常有输入长度限制,需要对较长文档进行切分处理。目前几种主流开源框架(如LangChain、Lla⁃ maIndex、Haystack等)都提供了文本分割器。以目前使用率最高的LangChain框架为例[2],基本的文档分割器包括:1) 基于字符数的分割器:CharacterTextSplit⁃ tSeprl;it2te) r递;3归) 基字于符令文牌本数分进割行器分:割R器ec:uTrsoikveenCTheaxratScptelirtTteerx。
基于这些基本文档分割器构建的系统往往还达不到实际应用的需要,LangChain还提供了进阶文档分割器,如:1) 多维向量检索器:MultiVectorRetriever;2) 基于上下文压缩检索器:Contextual compression;3) 自查询检索器:Self-querying;4) 混合检索器:En⁃ semble Retriever。
1.1.4 方法比较与分析
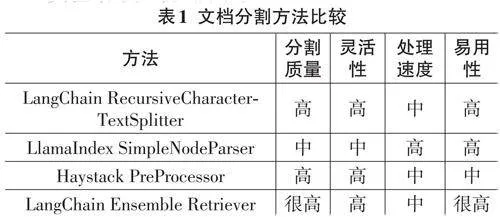
为了找到适合构建高校智能问答系统的文档分割器,研究设计了一组评估指标并进行了实验。评估指标包括:1) 保持语义完整性的能力;2) 适应不同类型文档的能力;3) 处理大量文档的效率;4) API的友好程度和使用难度。
实验结果如表1所示。
LangChain 的RecursiveCharacterTextSplitter 在保持语义完整性和灵活性方面表现出色,但在处理大量文档时速度相对较慢。相对而言,LlamaIndex 的SimpleNodeParser 则以处理速度快和易于使用而著称,但在面对复杂文档结构时可能缺乏足够的灵活性[3]。Haystack的PreProcessor提供了丰富的预处理选项,适合处理多样化文档,但其配置过程相对复杂[4]。本文使用的LangChain Ensemble Retriever在分割质量和易用性方面表现最佳,尽管其实现复杂度较高且处理速度处于中等水平。
Ensemble Retriever可以集成多个检索器,结合稀疏检索器(如BM25检索器)与密集检索器(如FAISS 检索器)。BM25检索器在根据关键词查找相关文档方面表现优异,而FAISS检索器则在基于语义相似度查找相关文档方面更加突出。算法会对检索到的多个文档进行排名,并结合两种算法的权重设置,以找到最相关的文档,从而为用户提供准确的答案。
在实际的实现与优化过程中,还需要根据实时反馈调整分割参数(如chunk_size和overlap参数),并进行质量控制,以实现基于语义相似度的检查,确保文档切分不会破坏关键语义单元。通过上述策略和优化措施,我们在实验中实现了比单一方法高近15%的F1分数,同时保持了可接受的处理速度。这为后续的知识提取和问答系统奠定了坚实的基础。
1.2 基于RAG 的智能问答技术
智能问答技术的发展经历了基于规则、基于检索及基于神经网络多个阶段。随着大规模预训练语言模型的快速发展,智能问答系统的性能得到了显著提升。ChatGPT、Claude等模型展现了惊人的自然语言理解和生成能力,为问答系统带来了新的可能性。但这些系统仍然面临着知识时效性、事实准确性和计算资源消耗等挑战。
为了解决这些问题,RAG技术应运而生。RAG模型不仅通过结合外部知识检索和语言生成,显著提高了回答的准确性和可靠性,还通过在解码阶段融合多个检索结果,进一步提升了问答质量。
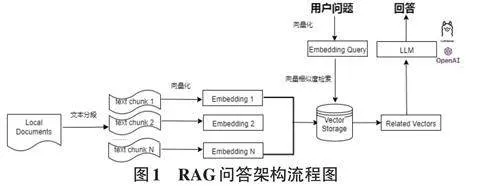
1.2.1 RAG 问答架构基本思路
RAG问答架构的核心思想是将外部知识库与生成模型相结合,以提高问答系统的准确性和可解释性。其基本流程如图1所示,主要包括以下步骤:1) 向量化用户问题:对用户输入的问题进行向量化,以便系统能理解语义和识别意图。2) 相似度检索:通过对问题的向量化表示,从预先构建的知识库中检索相关信息。3) 上下文融合:将检索到的信息与原始问题进行融合,形成增强的上下文。4) 答案生成:利用大规模语言模型,基于增强上下文生成最终答案。
上述流程通过结合检索与生成的优势,不仅提高了智能问答的准确性,也提升了系统的整体性能和用户体验。
1.2.2 RAG 问答架构优势
相比于传统的问答方法和纯生成模型,RAG架构在知识时效性、事实准确性、可解释性、领域适应性、计算效率、隐私保护以及持续学习能力等方面具有显著优势,从而为智能问答技术的发展开辟了新的方向。RAG技术结合了大语言模型(LLM) 的生成能力和知识库的专业性,能够有效解决LLM在特定领域知识不足的问题,因此近年来被广泛应用于智能客服、医疗诊断、教育辅助等领域。
1.3 高校信息服务
高校信息服务的智能化是近年来的研究热点。Li 等[5]设计了一个基于知识图谱的高校教务咨询系统,通过语义分析提高了查询的准确率。Zhao等[6]则探索了个性化学习助手的构建,利用强化学习技术优化了对话策略,从而提升了用户体验。然而,现有研究多聚焦于特定领域或单一功能,缺乏对高校全局知识的综合考虑。此外,如何有效整合最新的LLM和RAG技术以适应高校场景,仍是一个亟待解决的问题。
2 高校知识库智能问答系统设计、实现与性能评估
基于对RAG架构的分析,本文设计并实现了一种高校知识库智能问答系统,该系统旨在为高校师生提供高效、准确的知识服务,同时满足高校管理的特殊需求。主要模块包括用户接口模块、问题解析模块、知识检索模块、答案生成模块、知识库管理模块以及日志与监控模块。
2.1 用户接口模块
用户接口模块是系统与用户交互的前端,其设计直接影响用户体验和系统使用效率。该模块采用响应式设计,确保在不同设备上提供一致的体验。主要功能包括:
1) 多模态输入:支持文本、语音和图像等多种输入方式。
2) 对话管理:实现多轮对话功能,维护上下文信息。
3) 个性化界面:根据用户角色动态调整界面和功能权限。
4) 结果展示:采用分层结构展示答案,并支持源文档链接和相关推荐。
实现方式:本系统采用响应式设计,使用Streamlit 框架构建前端,利用WebSocket实现实时通信,并集成了开源引擎edge_tts以支持语音输入和输出。
效果:该模块确保了用户在不同设备上的一致性体验,提高了系统的适用性和易用性,并增强了系统的实时性能。
2.2 问题解析模块
功能描述: 问题解析模块是智能问答系统的关键环节,直接影响后续检索和生成过程的质量。主要功能包括输入清洗、分词和向量编码。
实现方式: 采用基于HuggingFace框架的自然语言处理模型,使用基于BERT的多标签分类模型[7]和bge-large-zh模型[8]构建多阶段、高精度的问题解析流程。具体步骤包括:1) 输入清洗:去除特殊字符、统一标点符号等。2) 分词:使用jieba分词器进行中文分词,保留原始词序信息。3) 向量编码:使用bge-large- zh模型获取向量表示。
效果:这种查询扩展方法平均提高了10.5%的召回率,同时保持了较高的精确度。
2.3 知识检索模块
功能描述: 知识检索模块负责从海量知识库中快速、准确地检索相关信息。它采用多阶段的混合检索策略,结合语义检索和关键词检索的优势。
实现方式:
1) 向量索引构建:使用bge-large-zh模型对文档进行编码,并采用Faiss库构[9]建向量索引。
2) 语义检索:采用两阶段检索策略:①粗检索:使用HNSW索引快速返回Top-6候选文档;②精检索:对候选文档进行精确的余弦相似度计算,重新排序并返回Top-2结果。
效果: 与单阶段检索相比,两阶段策略在保持相近召回率的同时,将检索时间减少了40%。
2.4 答案生成模块
功能描述: 答案生成模块负责将检索到的相关信息转化为连贯、准确的自然语言回答。
实现方式: 该模块采用基于大规模预训练语言模型的生成式方法,结合多文档摘要和实体关联技术。选用qwen:72b-chat[10]作为基础生成模型,该模型具有720亿参数,并对中英双语对话的支持度较高。
效果: 在系统性能评估中,答案的准确率达到了87.8%。
2.5 知识库管理模块
功能描述: 知识库管理模块负责知识的存储、更新和质量控制,以保证系统的长期有效运行。
实现方式:
1) 存储结构:采用FAISS向量数据库存储结构化数据。
2) 知识抽取与更新:设计基于规则和机器学习的混合知识抽取管道,包括系统对接、文本分类和信息抽取。
3) 质量控制机制:实施多层次质量控制,包括自动化检查、众包标注和版本控制[11]。
效果: 通过上述机制,问答的准确率从初始的72.3%提升至87.8%。
2.6 日志与监控模块
功能描述: 日志与监控模块负责系统运行状态的实时监控、性能分析和异常检测,从而保障系统的稳定性和持续优化。
实现方式: 该模块设计了用户反馈收集和分析系统,在每次问答交互后收集用户满意度评分和文本反馈,并利用机器学习算法持续优化问答质量。
效果: 用户满意度在6个月内从初始的78%提升至91%。
2.7 系统性能评估
为全面评估系统性能,研究团队设计了包括准确性、响应时间和F1分数等在内的多维度评估指标。在某高校进行的为期3个月的试点应用中,系统展现出优异的性能:
1) 准确性:对1 000个随机选取的问题进行系统输出答案与标准答案的相似度计算,这是评估智能问答系统准确性的关键指标。测试使用了Levenshtein 距离计算生成答案与正确答案之间的相似度,答案的准确率达到87.8%。
2) 响应时间:90%的查询在2秒内完成,满足实时交互需求。
3) F1分数:通过计算,平均精确度为81.8%,平均召回率为87.9%,平均F1分数为84.1%。
与传统基于检索的问答系统相比,本系统在复杂问题处理和知识推理能力上表现出明显优势。然而,我们也发现系统在处理跨领域问题和低频专业术语时仍有提升空间。
3 总结与展望
本文围绕高校智能问答系统的设计与实现展开,提出了一种基于大语言模型和RAG技术的智能问答系统。该系统为高校信息服务提供了新的范式,同时也为智能问答技术在特定领域的应用提供了借鉴。以下总结了主要研究成果及未来研究方向。
3.1 主要研究成果
1) 开发了融合向量检索和关键词检索的混合策略,优化了知识检索效率,检索时间减短了40%。
2) 实现了基于qwen:72b-chat的答案生成模块,结合RAG技术显著提升了模型性能,问答准确率和用户满意度分别提升了15.5和13个百分点。
3) 构建了FAISS向量库存储架构,并设计了自动化与人工审核相结合的知识更新流程,使知识库的准确率提升至97.1%。
4) 设计了用户反馈分析系统,利用机器学习算法持续优化问答质量。
3.2 研究局限性
尽管本研究取得了一定成果,但仍存在以下局限性:
1) 知识更新的实时性:知识抽取和更新机制存在滞后性,难以满足快速变化信息的即时更新需求。
2) 多模态交互:当前系统主要基于文本交互,缺乏对图像、语音等多模态信息的处理能力。
3) 跨语言能力:系统主要针对中英文环境进行优化,对多语言和跨语言问答的支持有限。
3.3 未来研究方向
基于上述局限性以及智能问答技术的发展趋势,提出以下未来研究方向为:
1) 引入多模态知识表示,提升系统对图片、视频等非文本信息的理解能力。
2) 探索基于知识图谱的推理机制,增强系统的逻辑推理能力。
3) 实现知识库的自动更新和质量控制机制,确保知识的时效性和准确性。
4) 研究个性化问答技术,根据用户背景和偏好定制答案生成策略。