基于决策树算法的Word格式文件数据抽取方法
2024-12-09庄自会


摘 要:由于Word格式文件数据抽取方法直接对数据自动抽取模型进行构建,没有对数据容量进行自适应处理,因此数据抽取效果较差。本文提出基于决策树算法的Word格式文件数据抽取方法,可对数据容量进行自适应处理,提升数据抽取的效率和准确性。并基于决策树算法构建数据自动抽取模型,输出文件数据抽取策略,进行Word格式文件数据抽取。试验结果表明,该方法提高了抽取效率,降低了系统资源的占用率,从而降低了数据抽取开销。
关键词:决策树算法;Word格式文件;数据抽取方法;自动化处理
中图分类号:TP 39 " " 文献标志码:A
随着信息技术飞速发展,需要对大量数据进行生成、存储和处理。Word格式文件是一种广泛使用的文档格式,承载大量的文本信息[1]。然而,Word文档通常包括多种元素,例如文本、图片和表格等,因此数据抽取非常复杂[2]。并且不同版本和不同设置也会导致文件结构出现差异,影响数据抽取精度和效率。国外研究者注重利用自然语言处理技术和机器学习算法对Word文档进行内容分析和抽取[3]。国内研究更注重结合实际应用场景,开发高效的数据抽取工具和方法[4]。然而,处理大规模、复杂结构的Word文档时,仍存在抽取精度不高、效率较低等问题。
因此,本文提出了一种基于决策树算法的Word格式文件数据抽取方法。决策树算法是一种常用的分类和回归方法,具有直观易懂、计算效率高等优点。本文结合Word文档的结构特征和决策树算法的优势,进行Word文档数据的自动化、高精度抽取,为企业信息管理和数据挖掘等领域提供有效的技术支持。
1 基于决策树算法的Word格式文件数据抽取方法设计
1.1 数据容量自适应处理
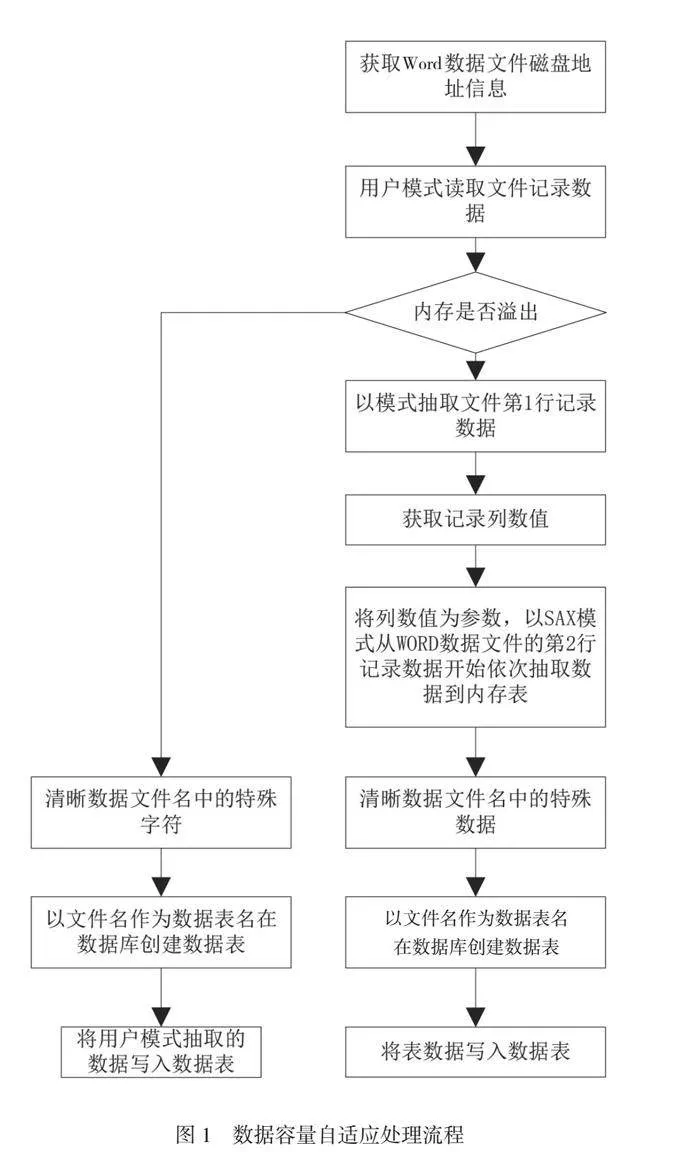
为了从Word数据文件中有效提取数据,通常会采用Apache POI组件的用户模式来访问数据文件。该模式可以二维数据表的形式提取文档中的所有记录数据,并对其进行处理。然而,当数据条目数量达到或超过10000时,传统的处理方式通常会出现内存流错误。对于数据条目数超过30000的大型数据文件(即条目数gt;30000),更无法通过常规策略来成功提取这些数据。因此,本文致力于优化现有的处理策略,以便算法能够自适应地调整数据容量,从而有效处理大型Word文件中的数据。
如果Word数据文件中的条目数量没有超出内存能够处理的阈值,算法会将Word数据格式转换为CSV数据格式,并以SAX模式对数据进行分析。该方法优势是无须将整个文件的所有记录数据一次性加载到内存中并形成二维数据表,而是从记录的数据单元中逐条读取数据,从而可有效避免内存流错误。
在SAX模式下,可以灵活设置Word数据文件中的条目数。该策略赋予了算法对大容量Word数据文件的自适应处理能力,允许算法根据数据容量动态调整处理策略。数据容量的调整过程如图1所示。
这种自适应处理机制是算法能够高效、稳定地处理各种规模的Word数据文件,提升了数据抽取的效率和准确性。
1.2 基于决策树算法的数据自动抽取模型构建
决策树算法是一种基于树形结构的监督学习方法,构建树状模型可对数据进行分类或回归。抽取Word格式文件的数据时,决策树算法能够根据文件的特征和结构自动构建用于数据抽取的模型。
首先,对Word文档进行预处理,提取出文档中的关键信息。其次,基于这些信息构建特征向量,将这些特征向量作为决策树模型输入,利用决策树算法训练这些特征向量,并生成决策树模型。在训练过程中,算法会根据特征向量的不同取值自动选择最优的划分策略,构建层次化的树形结构。
训练完成后可得一个可用于数据自动抽取的决策树模型。当输入新的Word文档时,模型会根据文档的特征向量,在决策树中进行编辑,最终找到对应的抽取规则,从而实现数据的自动提取。首先,算法对Word文件进行预处理,清洗数据并转换为数值型格式,为后续的特征提取奠定基础。其次,算法从文本中提取关键词、统计特征和结构特征等,这些特征共同构成了决策树的构建基础。构建决策树时,算法根据特征的重要性和信息增益选择根节点,并递归地构建子树,直到达到抽取目标或预设的终止条件。再次,完成模型构建后,算法使用标注数据进行训练,调整模型参数以优化性能。最后,对于新的Word文件数据,算法通过遍历决策树,根据每个节点的特征值做出决策,并从叶节点提取出抽取结果,最终实现了Word格式文件数据的自动化精准抽取。进而不断优化模型,可以进一步提高抽取的准确性和效率,为实际应用提供有力支持。
在基于决策树算法构建数据自动抽取模型的过程中,需要确保每个非结构化语义向量文档的可能状态能够准确反映在当前和先前的数据声明中。非结构化表格文档的文档数据应该与表格文件的结构兼容,以便能够正确抽取信息。在GIA过程中,可以对BiRNA进行编码,从而获取文本先前和后续阶段的信息。其中,主动单元在处理长期存储网络训练过程中的不完全梯度过程中发挥了重要作用。
计算非结构化表格文档的权重时,通常会得到一个权重向量E,包括元素e1,e2,...,em。隐藏层在特定时间段t中的权值如公式(1)~公式(3)所示。
(1)
Eh=gh⊕Eh-1+jh⊕dh " " " " " " " " " " (2)
th=Uh⊕tant(Eh) " " " " " " " " " " " " "(3)
式中:jh为输入层;gh为遗忘门层;Uh为输出层;dh为遗忘门权重矩阵;Eh为遗忘门隐藏状态;th为遗忘门输出值。
可更新的候选向量分别为d和β。每个段落的计算处理都应精确无误,以确保数据抽取的准确性和效率。
编码框架是文档处理问题的常见分析形式,具有广泛的应用。在本文中,该系统被应用于从非结构化表格文件中抽取数据。在将非结构化表格文档从分类表X转换到Y的过程中,需要指定非结构化表格文档,并在解码器系统中创建平均语义向量xj。
非结构化表格文档Y包括元素y1,y2,...,yn。使用非线性变换D对文档Y进行编码,以描述条目Y的变换,并通过解码器来生成x1,x2,…,xj-1,从而构建当前的平均向量输出xj,该过程如公式(4)所示。
xj=f(D,x1,x2,…,xj-1) " " " " " " " " " " "(4)
考虑非结构化数据表中的差异,编码框架会导出解码器所需的平均语义向量,这些向量是模型求解所必需的。在这个过程中,编码器会将输入的非结构化数据转换为内部表示,而解码器则根据这些内部表示生成所需的输出。该模型引入了注意力机制,能够更准确地关注非结构化数据表中的关键信息,从而提高数据抽取的准确性和效率。
1.3 输出文件数据抽取策略
考虑信息类别的多样性和可用时间的差异,从LexisNexis数据库中导出Word格式文件,优化数据收集操作,并基于决策树算法构建数据自动抽取模型。本文制定了多种Word格式文件抽取策略。
这些策略将指定磁盘上需要获取的Word系列数据文件复制到一个工作目录中。在子目录结构中配置与Word数据文件相关的各种信息。根据该目录结构获取所有Word文件的地址信息,这些信息是由绝对路径名和文件名组成的字符串。将每个Word文件的地址信息写入XML文件进行存储。
本文使用XML文件存储的目的是为后续阶段的自动读取提供单个文件的地址信息。在数据提取的最新阶段,根据需要对数据进行编码、归一化或标准化处理,以便模型能够更好地学习数据的内在模式。使用提取的特征和对应的目标变量(即需要抽取的数据)来训练决策树模型。在训练过程中,模型会学习如何根据特征将数据划分为不同类别或回归值。将训练好的决策树模型应用于新的Word格式文件数据,根据模型所学规则进行自动抽取。扫描完所有文件列表并处理变量选项后,即表示批量文件的自动恢复和读取工作已经完成。
接下来需要对Word格式文件进行自动化信息抽取。开启Word处理程序,读取文件内容至内存,并去除其中的空行和总索引信息头,以净化数据。准确抽取文件的格式、时间和长度等关键信息,并对正文内容进行精细抽取。特别关注图片引源信息标记和正文结束标记的搜索,确保信息的完整性和准确性。如果文件处理未结束,策略将自动返回关键信息抽取环节,继续处理剩余内容。完成单个文件处理后,抽取的数据将被输入数据处理系统,用于构建或更新模型,以支持后续的信息处理与分析工作。与此同时还可利用自动搜索功能连续处理多个目标文件,提升批量处理效率。
2 试验论证
为了验证基于决策树算法的Word格式文件数据抽取方法的抽取效果,本文建立了一个试验平台,并与传统方法1和传统方法2进行比较,试验如下。
2.1 试验准备
本文采用Java编程语言进行了一系列对比试验,为了有效管理和存储试验数据,利用SQL Server 2008 R2构建了一个功能强大的数据库系统。同时利用Apache POI 3.17版本库,对Word文件进行精确读取与高效写入,以确保数据处理的准确性。
试验的测试环境为Windows 7(64位)操作系统,其稳定、可靠的性能为试验提供了良好的运行环境。此外,还配备了Intel Core i5 CPU和12GB内存,为试验提供强大的计算能力和充足的数据存储空间。
在试验过程中,从LexisNexis数据库中精心选取与Word文件相关的15个数据样本,将其作为测试对象。这些样本数据涵盖多种类型和场景,具有广泛的代表性。按照分类说明对这些样本进行详细分类,以便在后续试验中进行有针对性的比较和分析。样本分类见表1。
表1展示了根据分类标准对样本文件进行分区的结果。分区信息文件是基于生产时间来分类的,以确保数据的时序性和相关性。每个示例文件包括多个消息文章,所有示例文件中的消息文章总数为2210篇。
2.2 对比试验
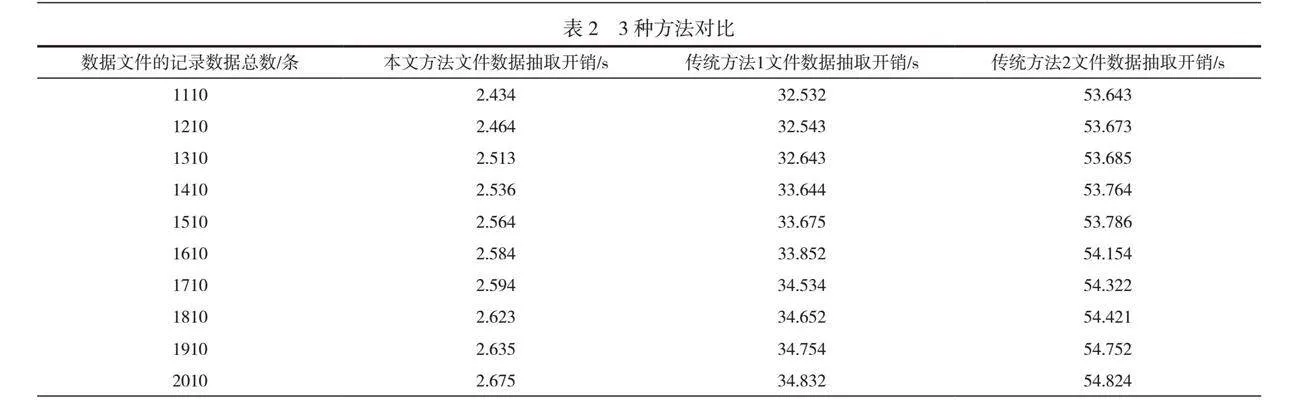
在上述试验环境构建的基础上进行对比试验,每个数据文件测试10次,以确保试验结果的可靠性。试验结果见表2,表2展示了采用3种方法抽取Word格式文件数据时的开销对比情况。
试验结果表明,本文设计的数据抽取方法在文件数据抽取开销方面表现出显著优势。与传统方法相比,本文方法抽取相同数量数据所需开销明显减少。试验结果表明,该方法改进了数据抽取算法和流程,提高了抽取效率,降低了系统资源的占用率和数据抽取开销。
3 结语
本文深入研究了基于决策树算法的Word格式文件数据抽取方法,取得了一系列重要的研究成果。该方法不仅有效解决了Word文档数据抽取中的诸多困境,还在实际应用中展现出了较高的抽取效率。
参考文献
[1]宋君妍,司念亭,陶思亮,等.基于Bert的面向海洋油气生产安全领域非结构化数据的抽取方法讨论[J].中国石油和化工标准与质量,2024,44(2):100-102.
[2]石怀明,曾浩洋,梁国泉,等.基于数据中台的药品安全舆情数据分析及实现[J].软件导刊,2024,23(2):92-98.
[3]何芳州,王祉淇.基于知识图谱的多数据集成抽取方法仿真[J].计算机仿真,2023,40(12):422-427.
[4]吴天钒,周磊,赵栋.基于统一超混沌系统的彩色图像加密算法研究[J].价值工程,2023,42(33):109-111.
