基于神经架构搜索的智能电表窃电识别方法研究
2024-12-08李彦





摘 要:本文基于神经架构搜索技术,利用大规模智能电表数据进行训练,自动判断电流、电压和功率特征,旨在提高窃电行为的准确识别度并降低误报率。本文采用神经架构搜索算法构建的窃电识别模型,更精准地识别窃电行为。研究的最终目标在于加强供电公司对窃电行为的监测,提高打击能力,保障电网安全、稳定地运行。该方法的应用十分广泛,可推动智能电表技术的发展,为电力行业提供更高效的管理手段。
关键词:神经架构搜索;智能电表;窃电行为
中图分类号:TM 73 " " " " " " " " 文献标志码:A
传统的窃电识别方法主要是人工检测与统计分析,存在识别准确性低、易受人为因素影响等问题。为了提高窃电行为的识别效果,研究人员开始应用机器学习和深度学习技术。其中,基于神经架构搜索的智能电表窃电识别方法成为研究的热点。
1 问题阐述
本文的主要目标是利用智能电表采集电力用户的真实用电量数据,通过分析数据缺失信息,对窃电行为检测模型进行优化与改良。为实现该目标,本文引入神经架构搜索算法。该算法能够自动定义用电特征并计算窃电嫌疑度,从而将用户分为高或低窃电嫌疑度组别。该算法通过测算用户的窃电嫌疑度,判断该用户是否存在窃电行为。本文设窃电怀疑度为P。当P≥0.5时,表示该用户窃电怀疑度高,其发生窃电行为的概率较大;当Plt;0.5时,表示该用户窃电怀疑度低,通常情况下不存在窃电行为[1]。本文调取中国国家电网中的公开数据,总结了42373个用户在1036天内的用电数据,并通过试验分析,论证了基于该算法构建的切点识别模型的有效性。
2 数据输入
本文将收集的数据转化为m×n数据矩阵,其中n表示用户数量,m表示时间节点数据,如公式(1)所示。
(1)
式中:Xn为第n个用户的用电量数据序列。
本文中,n=42373,m=1029。考虑计算的简便性,剔除最后7天的数据,以便将数据转化为矩阵。在此基础上,利用卷积神经网络,将矩阵X转变为数据张量,即X'(42373×147×7),最终得到Xi'(147×7)。将数列设定为7列,对应一周7天的用电周期,以便进行对比,如公式(2)所示。
(2)
3 基于神经架构搜索的窃电识别方法
随着人工智能技术快速发展,作为深度学习中的一个新兴领域,神经架构搜索被广泛应用于众多场景。窃电识别是电力系统中的关键问题,本文引入神经框架搜索对其进行优化,旨在提高检测精确度和效率。
3.1 基于贝叶斯优化的神经架构搜索方法
在窃电识别的应用中,基于贝叶斯优化的神经架构搜索可以有效缩短模型搜索时间,快速定位到具有高精度识别能力的神经网络结构[2]。本文将一个准确度较高的窃电识别神经网络结构设定为F,成本函数设定为Cost(·),用电数据集D分为训练集Dtrain和测试集Dval。假设存在一个最优神经网络结构f*,如公式(3)、公式(4)所示。
f*=argminf∈FCost(f(θ*),Dval) (3)
θ*=argminθL(f(θ),Dtrain) (4)
式中:θ*为f的结构参数;F为覆盖全部神经架构。
3.2 基于神经架构搜索的窃电识别模型
本文构建的窃电识别模型由卷积层、全连接层和输出层组成。卷积层负责从输入的电表数据中自动提取有用的局部特征。全连接层负责将这些特征进行整合,可将提取的多维特征向量压缩为一个更低维度的特征空间,从而用于最终的分类或回归任务[3]。输出层负责对整合后的特征进行加权求和,并输出一个表示窃电嫌疑度的数值。该层会使用Sigmoid或者Softmax作为激活函数,以便输出1个0~1的概率值。
3.3 窃电检测流程
需要收集足够的电力使用数据,包括正常使用和窃电情况。数据需要经过清洗、归一化和标注等预处理步骤,使其适用于后续的模型训练。在此阶段,本文应用神经框架搜索进行模型自动搜索。利用贝叶斯优化或其他策略,系统会自动评估并选择最佳的神经网络架构。选定最佳网络架构后,使用标注的数据进行模型训练。利用深度学习技术,模型会学习到窃电和正常用电间的区别。一旦模型训练完成,就可以使用该模型对新的电力使用数据进行窃电识别[4]。
4 性能评估
4.1 数据集
本文将数据集导入窃电识别模型,去除数据中显示为“Nan”的数据,剩余数据均为真实有效的用电数据。对有效数据进行预处理,最终得到窃电识别数据(见表1)。
4.2 数据预处理
不同用户的用电量差异巨大,为避免出现甲用户与乙用户在单位时间内用电量下降比例不同,需要对过滤后的有效数据进行归一化运算,将原始数据转变为无纲数,如公式(5)所示。
(5)
式中:W为原始数据序列;W'为经过归一化处理的数据序列。
4.3 验证方法
本文引入多折交叉验证模型。该模型适用于仅有一个预测目的场景,与本文研究的“预测用户是否为窃电用户”的目标一致。
4.4 性能指标
通常情况下,在一个大的供电区域中,有窃电行为的用户数量极少,因此在利用用户用电数据判断窃电行为的过程中,正常用电数据与窃电用户的用电数据比例差异悬殊,如果采用传统的准确率比较,就容易出现误差。其原因在于绝大用户被判定为“非窃电用户”,该判断的准确率通常会超过90%,但该判断结果无法准确反映本文设计的窃电识别算法的性能。因此,本文引入精准率评价指标、召回率评价指标以及综合评价指数F1,将3项指标代入折交叉验证法中,进而印证基于神经网络搜索算法的窃电识别模型的有效性[5]。这3项指标的计算过程如公式(6)~公式(8)所示。
(6)
(7)
(8)
式中:Precision为精准评价指数;Recall为召回率评价指数;TP为“窃电用户集”中被判定为窃电用户的用户数;EP为“正常用户集”中被判定为窃电用户的用户数;FN为“窃电用户集”中被判定为正常用户的用户数。
窃电检测工作的核心是确保准确性和查全率。如果检测方法不够准确,可能会导致误判,从而引发不必要的人力和物力投入,甚至可能侵害无辜消费者的权益。相反,如果检测方法查全率低,可能会导致许多窃电行为逍遥法外,从而加剧电力公司的经济损失。因此,本文引入F1分数作为评价指标。该指标是查全率(召回率)和查准率(精确率)的调和平均值。查全率反映了检测方法查出所有窃电行为的能力,查准率则反映了被检测出来的窃电行为中真实窃电行为的比例。F1分数综合考虑了这2个方面,为相关研究人员提供了一个全面、准确的评估工具。通过不断优化窃电检测方法,提高F1分数,电力公司能更有效地打击窃电行为,确保诚信和公平。
4.5 试验结果
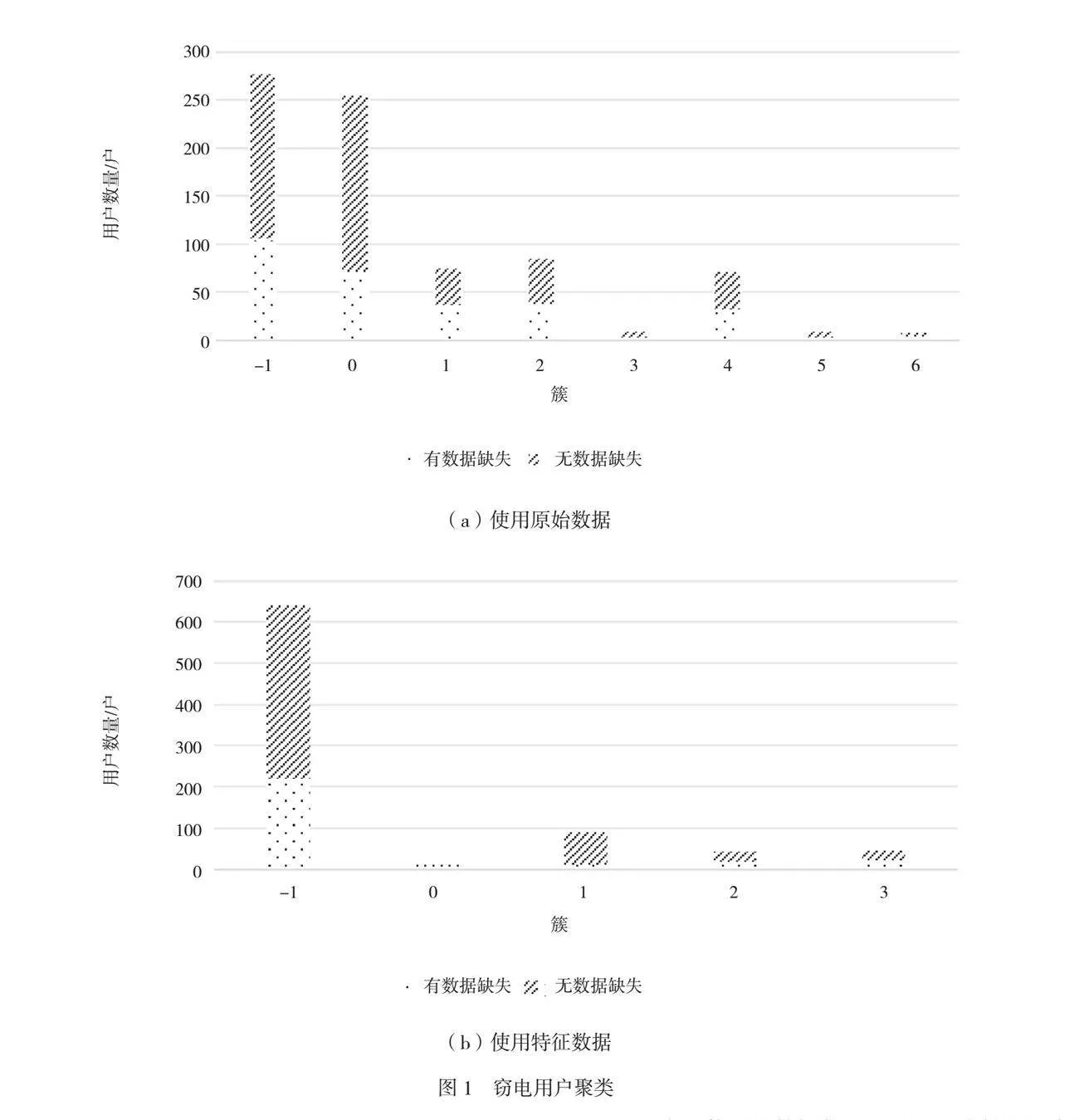
神经框架搜索算法窃电识别模型混淆矩阵见表2,其中TN为“正常用户集”中被判定为正常用户的用户数量。分析表2中的数据可以发现,FN的280个用户被划入“窃电用户集”的主要原因在于这部分用户缺失值信息较少,该模型无法利用缺失值信息对其进行准确识别。被该模型识别为窃电用户与非窃电用户的电力用户数量分布如图1所示。
随机从“使用原始数据”的簇和“使用特征提取”的簇中调取9位用户的用电数据,并对该数据进行可视化转化(如图2所示)。
图2中,横轴为用电天数,纵轴为月数,其中黄色部分为“有数据缺失”的用电数据。分析图2可以明显看出,未被该模型识别为“窃电用户”的缺失值很少,其平均数量仅为6;而被判定为“窃电用户”的数据中,存在数据缺失的数据数量较多,平均为539个。由此可以证明,利用数据缺失信息能够较准确地判断用户是否存在窃电行为。
需要注意的是,上述试验采集数据的间隔为1天。如果用户采用打开电表盖子的方式进行窃电且“开盖→修改数据”行为发生在一天之内,则模型不会读取到该用户存在数据缺失的问题。因此,如果仅使用缺失值信息来判断用户是否有窃电行为,则无法检测出使用开盖修改数据方式进行窃电活动的用户。针对该问题,本文尝试将开盖数据与存在缺失值的数据进行融合,令该模型能够覆盖绝大多数窃电行为判断场景。此外,对“正常用户集”中被判断为“窃电用户”的81个用户进行深入分析可知,产生误判的主要原因如下。1)在采集数据过程中会有一定的数据包丢失概率,导致该用户的用电数据不完整,进而导致模型判断错误。2)集中器发生故障,导致用户的用电数据丢失,被模型判断为“窃电用户”。
5 结论
本文采用基于神经架构搜索的方法对智能电表进行窃电识别,取得了一定成果。该成果揭示了在电能窃取行为中,基于神经架构搜索的模型具有较好的性能和高效的特征学习能力。在理论方面,本文深入挖掘了神经架构搜索的潜力,为智能电表窃电识别领域提供了新的思路和方法。自动搜索合适的神经网络结构可以大幅减少人工设计模型的工作量,并能获得更好的性能。在实际应用方面,基于神经架构搜索的智能电表窃电识别方法具有实际应用价值。准确识别电能窃取行为可以帮助电力公司及时发现非法窃电行为,有效降低电网安全风险和经济损失。未来可以进一步优化搜索算法、提高效率,并结合硬件优化等技术进行应用。此外,本文使用的数据集也可以进一步扩充和完善,以提高模型的泛化能力和适用性,为电力系统的安全与管理做出更大贡献。
参考文献
[1]汤渊,吴裕宙,苏盛,等.基于改进深度极限学习机的光伏扩容用户识别方法[J].电力系统及其自动化学报,2022,35(11):13-16.
[2]邹念,张颖,苏盛,等.基于小时尺度周期特征自编码器的用户窃电识别方法[J].电网技术,2023,47(6):2558-2567.
[3]冯小峰,姚诚智,杨俊华.基于Stacking集成学习的窃电检测研究[J].电测与仪表,2023,12(8):10-12.
[4]刘文浩,冯玥,姜东良.基于AMI数据驱动的窃电用户识别研究[J].制造业自动化,2022,44(11):5-8.
[5]夏睿,高云鹏,朱彦卿,等.基于SE-CNN模型的窃电检测方法研究[J].电力系统保护与控制,2022,50(20):117-126.
