基于改进循环神经网络的半导体质量预测
2024-12-06杨帆胡志栋




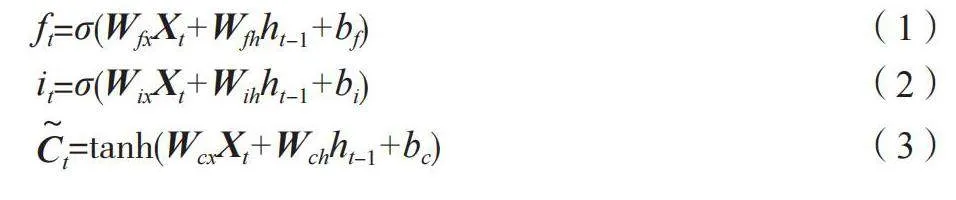

摘要:在复杂的半导体生产过程中,为了减少成本、缩短周期,须优化质量检测过程。本文对半导体的生产特点进行分析,结合数据预测的深度学习理念,构建基于长短期记忆网络(Long Short-Term Memory,LSTM)的质量预测模型。与基础预测模型相比,该模型考虑在复杂加工过程中使用的不同工具,引入工具识别模块。改进后的模型提高了质量预测的准确性和预测能力。对薄膜晶体管液晶显示器(TFT-LCD)的生产数据进行验证,本文方法预测结果更接近真实值,均方根误差(Root Mean Square Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)2类指标均大幅度降低。
关键词:半导体;质量;改进循环神经网络
中图分类号:TP391""""""""" 文献标志码:A
半导体信息化程度、生产成本很高,生产过程、工序十分复杂,因此其生产质量十分重要。本文提出一种基于改进循环神经网络(Recurrent Neural Network,RNN)的质量预测方法,同时加入工具识别模块,能够根据生产数据实时进行质量预测,有助于及时发现质量问题,为调整生产计划留出充足时间。
1半导体质量预测模型
1.1LSTM适配性
长短期记忆网络(Long Short-Term Memory,LSTM)是一种深度学习模型[1],其作用是对序列数据进行建模。利用RNN来存储和检索信息。半导体生产复杂程度高,使用的工具很多,每一道工序都可能对半导体质量造成重大影响。考虑上述情况,因为质量预测期间须考虑的变量较多,所以本文选择了LSTM,其有以下2个优点。1)LSTM具有“记忆单元”结构,可对长时间序列数据进行建模。多工序数据通常具有长期的依赖性和记忆效应,LSTM的内部记忆单元可以存储和检索长期记忆,捕捉长期依赖性,提高模型的性能。2)LSTM每个时间步能够输入多个特征,并处理具有多维特征值的数据,其结构使其能够适应不同的序列长度和数据模式,因此其非常适合处理具有多个特征值的多工序数据。
综上所述,当处理多工序数据的时序和依赖关系时,LSTM的适应性很强,表现优秀,因此本文使用LSTM对半导体质量进行预测。
1.2LSTM模型简介
LSTM模型在RNN的基础上增加了3个门控机制,分别为“遗忘门”“输入门”和“输出门”[2]。LSTM单元由单元状态(Ct)、遗忘门(ft)、输入门(it)和输出门(Ot)组成。设t时刻的输入序列为向量Xt,输出序列为ht,3个门以及LSTM单元内部计算过程如公式(1)~公式(6)所示。
式中:ft为遗忘门;i为输入门;Ot为输出门;σ为Sigmoid激活函数;tanh为tanh激活函数;ht、ht-1为时间步的隐藏状态;Wfh、Wih、Woh和Wch分别为3个门和单元状态的互连权重矩阵;Wfx、Wix、Wox和Wcx分别为3个门和单元状态的输入权重矩阵;bf、bi、bo和bc分别为每个门输出相应的偏置项;Ct和Ct-1分别为t和t-1时刻记忆单元中的状态向量;Ct为t时刻候选单元中的状态向量;为矩阵的元素乘积。
2半导体质量预测模型构建
2.1特征选择与数据预处理
在半导体的生产数据中有许多干扰数据,会对模型训练造成困扰。因此,在准备训练深度学习模型的过程中,须处理异常值并对数据进行归一化处理,其目的是将特征数值缩放至统一的范围,加快学习算法的收敛速度,使模型对特征尺度不敏感。本文使用MinMaxScaler模型对数据进行归一化处理,它可以将数据缩放至(0,1),如公式(7)所示。
(7)
式中:min和max分别为数据的最小值和最大值;X为原始数据;X'为统一后的数据。
对序列数据进行处理,须将原始数据重构为序列格式,输入LSTM模型中。将数据集分割为训练集和测试集,本文选择80%训练集和20%测试集。
2.2工具识别
由于该加工过程的复杂程度较高,因此本文首次建立的预测模型预测结果不佳。分析生产数据的特点后,发现其中的“工具”字段有5种分类(不同工具导致的误差棒如图1所示)。因此,增加工具识别模块,对质量预测模型进行优化。
使用检测工具图像或特征来识别其类型和状态,进行预测和决策。为保证模型准确性和鲁棒性,须关注数据分布的均衡性和异常值。由于半导体制造工具精度高,数据须保留至小数点后6位,因此本文在工具识别过程中充分考虑数据精度和变化情况,保证预测结果的准确性和可靠性。
误差棒图是一种常用的数据可视化方法,其作用是显示数据的平均值以及数据值在平均值附近的波动。导入所需的库,从数据框中提取按照“TOOL”分组的数据。本文提取每个分组的“Value”列的数据计算其平均值和标准差。创建1个位置列表,在图中标记每个数据集,创建1个图形,并使用errorbar函数绘制误差棒图。这个函数接受3个参数:位置(即x轴上的标签)、平均值以及标准差。在Matplotlib库中,o是一个Marker参数,表示使用圆点作为数据点的标记符。capsize是1个参数,其作用是设置误差棒的大小。误差棒是一种常用的可视化方法,表示数据点的不确定性或误差。capsize参数控制误差棒的大小,单位为点数。本文设capsize=5即将误差棒的大小设为5点数。须展示每个“TOOL”中“Value”列数据的分布情况以及与平均值相比这些数据的波动,误差棒能够直观展示这些信息。使用不同工具,数据集的预测值明显不同,因此,有必要加入工具识别模块。
2.3算法优化
自适应矩估计算法(Adaptive Moment Estimation,Adam)是一种优化算法,也是改进的随机梯度下降(Stochastic Gradient Descent,SGD)方法,其结合动量和自适应学习率进行调整,能够加速模型收敛,提高训练效果。本文采用Adam来最小化LSTM模型的损失函数。Adam的优势主要包括以下2点。1)加速收敛,利用动量和自适应学习率进行调整,可以缩短训练时间。2)适用于大规模数据,扩展性较好,能够处理海量数据并进行优化。将Adam与半导体数据的质量预测模型进行结合,训练并优化模型参数,提高预测准确性和效率。这种方法可以有效应用于半导体数据的质量预测,利用模型评估和可视化结果对模型性能进行分析和优化。
更新模型参数,计算过程如公式(8)所示。
(8)
式中:θt为当前模型参数的更新值;θt-1为模型参数在时间步的值;gi(θt-1)为第i个样本的梯度;m为样本数;α为学习率。
2.4模型训练
本文利用阿里天池工业AI大赛-智能制造质量预测中薄膜晶体管液晶显示器(TFT-LCD)的生产数据来检验提出的多工序产品质量预测模型。TFT-LCD半导体智能制造质量预测数据集包括反应机台的温度、气体、液体流量、功率以及制成时间等因子,根据影响因子设计模型,准确预测与其对应的特性数值[3]。
本文使用多模型训练方法对每个工具的数据集分别建立模型进行训练。这种方法可以充分利用每个工具数据集的特点,提高模型的泛化能力和预测精度。为每个数据集量身定制1个模型,当处理相应数据时,保证模型具有较高的准确性和可靠性。同时,多模型训练还可以增加模型的鲁棒性,降低单个模型在训练过程中可能出现的过拟合或欠拟合风险。
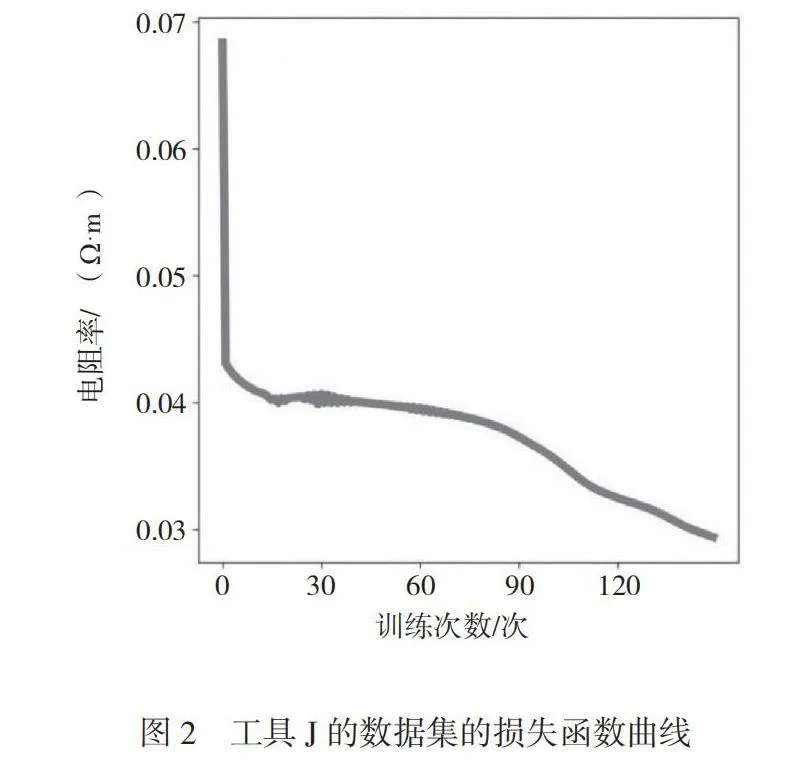
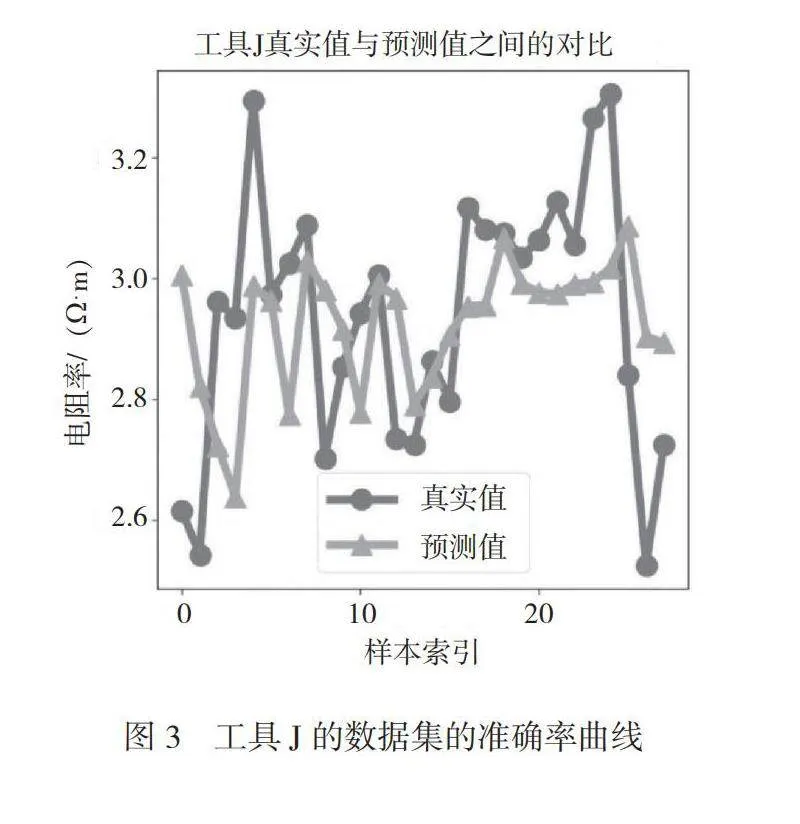
为方便进行处理与训练,本文对现实的工具工序进行了数据层面的抽象定义,使用5种工具的数据划分数据集,其中一种工具J的数据集的损失函数曲线如图2所示,准确率曲线如图3所示,由图2、图3可知,该工具的损失函数下降明显。
2.5结果与分析
为验证改进循环神经网络的质量预测模型的准确性,本文采用均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)对结果进行量化评估。从结果可以看出,使用这些因子优化后的模型预测准确率明显上升,能够准确预测产品质量。
优化前模型MSE为5.436306136454508,RMSE为2.3315887580048305;优化后模型MSE为0.06469379271560773,RMSE为0.25434974487034134。
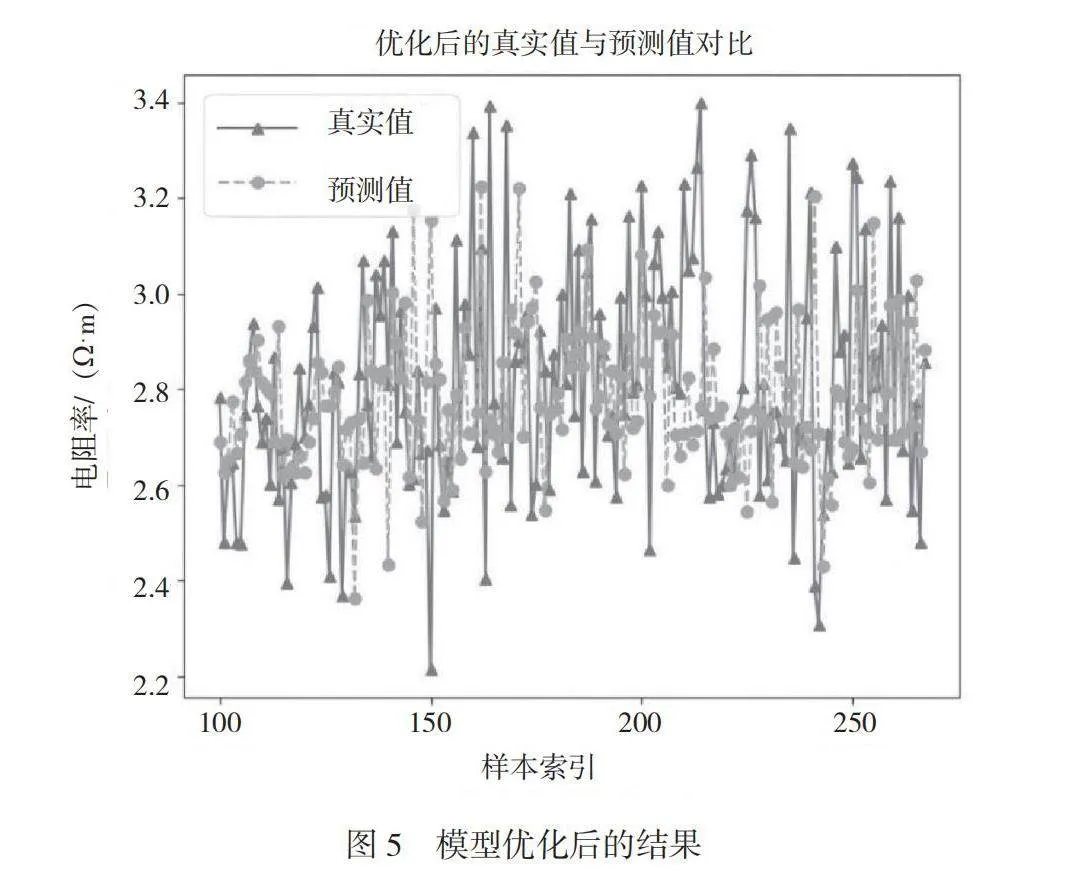
模型优化前的结果如图4所示。虽然预测模型能够根据半导体生产数据的大致趋势进行变化,但是在具体的表现上,无论是上升还是下降都不够明显,与半导体生产数据的真实值之间存在一定的差距。模型优化后的结果如图5所示,由图5可知,优化后的模型能够更加紧密地贴合半导体生产数据的真实值,鲁棒性和泛化能力更强,说明模型能够更好地适应复杂多变的半导体生产数据,预测准确性较高。
3结论
本文根据半导体生产数据特点进行分析,结合数据预测 的深度学习理念构建了基于LSTM的质量预测模型,为其他复杂产品的质量预测提供参考。本文使用分类思想,针对模型在使用过程中的不同工具进行识别,分类预测思想可以大幅度提高预测准确性。
使用本文提出的方法能够实时监控并预警生产过程,提前发现当前工序的问题,防止问题传递至后续工序[4],减少生产资源浪费,提高产品合格率。工艺人员能够基于预测模型获取的关键参数针对性能表现较差的产品进行问题追溯,调整关键的影响因子,加快不良问题的处理速度,提升整体工艺水平。
参考文献
[1]周朝营. 基于LSTM模型的桥梁监测信号恢复方法研究[D]. 重庆:重庆交通大学,2023.
[2]涂新前. 基于神经网络模型的永安市小流域水环境质量预测的研究[J]. 皮革制作与环保科技,2023,4(20):75-78.
[3]王译可. 基于改进BiLSTM和FBN的多工序产品质量预测与控制研究[D]. 沈阳:沈阳大学,2022.
[4]杨少华. 一种基于XGBoost的智能制造质量预测模型[J]. 科学技术创新,2021(11):18-20.
