基于复合知识蒸馏的骨科影像诊断分类研究
2024-11-07王烤吴钦木
摘要:针对医疗设备存储资源有限的问题,提出一种基于复合知识蒸馏的诊断分类方法,旨在确保骨科影像诊断模型的高精度性能。该方法首先采用自适应直方图均衡化对数据集进行增强;其次引入知识蒸馏,选用EfficientNet\|B7作为教师网络、EfficientNet\|B0作为学生网络,同时对学生网络引入渐进式自蒸馏,以提升特征挖掘和泛化能力。在MURA(MusculoskeletalRadiographs)数据集上进行验证的结果表明,复合知识蒸馏(CKD)模型的准确率为96.26%,其参数量仅为EfficientNet\|B7模型参数量的8.48%,并且在准确率方面仅下降了1.16%,验证了此模型的有效性。
关键词:骨科影像;自适应直方图均衡化;特征挖掘;知识蒸馏;渐进式自蒸馏
中图分类号:TP391文献标志码:A
0引言(Introduction)
X射线影像作为骨科疾病检测的一种经济且高效的工具,其应用广泛但受限于需要专业医师进行耗时诊断,可能会延误诊断和治疗[1]。基于深度学习的诊断模型能在短时间内提供准确的诊断信息,从而有效减轻医生的工作负担并提高诊断效率[2]。然而,骨科影像具有低分辨率、低对比度、多纹理等特点,如果仅使用DNN(DeepNeuralNetwork)对其进行特征提取及分类,可能效果不尽如人意。同时,尽管深度学习在骨科影像识别等领域取得了显著成就,但也面临资源需求高和过拟合等挑战[3]。虽然已有研究者提出如剪枝[4]、量化[5]、知识蒸馏[6]等轻量化的方法用来降低模型的参数量和计算复杂度,但是在分类精度上仍有一定的提升空间。
基于此,提出一种基于复合知识蒸馏的深度学习诊断模型。在预处理阶段,引入了自适应直方图均衡化[7],以处理骨科影像的亮度和对比度变化,以提高骨科影像数据集的质量。在模型构建上,选择EfficientNet[8]模型作为主干网络,其凭借独特的统一缩放复合系数策略,在保持模型性能的同时,又能在一定程度上减少参数量。此外,为了进一步提高分类精度,并尽可能降低模型的参数量,提出一种复合知识蒸馏(CompositeKnowledgeDistillation,CKD)的方法,有效解决了模型性能差和设备存储有限的问题。该方法为深度学习在骨科影像诊断中的应用提供了可靠的解决方案。
1相关工作(Relatedwork)
针对骨科影像的特殊性,研究人员在预处理阶段采用了多种预处理技术,如直方图均衡化[9]、小波变换[10]、非局部均值去噪[11]等方法,旨在降低图像中的噪声水平和改善图像的质量和视觉效果。自适应直方图均衡化已经被证明能在增强图像对比度、亮度的同时,有效应对骨科影像中的变化。
在骨科影像诊断分类方面,有许多研究已经证明CNN(ConvolutionalNeuralNetwork)网络能够对骨科影像进行有效的诊断分类[12\|14]。迁移学习可以将一个领域或任务中学到的知识迁移到另一个相关领域或任务中。最初,使用预先训练的DL(DeepLearning)系统,例如AlexNet[15]、VisualGeometryGroup的DL网络(VGG16和VGG19)[16]和ResNet50[17],通过SoftMax分类器将所选的射线照片图像分类为正常和异常类,类似的还有Inception[18]和DenseNet121[19]。然而,传统的CNN网络往往存在参数量大、计算复杂、优化困难及任务局限等缺点。EfficientNet是对相对传统的CNN网络(如VGG、ResNet、Inception和DenseNet)的一种优化和改进,在平衡深度和宽度方面表现出色,可以通过自动网络搜索获得高效结构。
在存储设备资源有限且分类精度较低的情况下,HINTON等[20]提出使用基于知识蒸馏的方法将复杂的教师模型的知识转移到简化的学生模型中,提高了学生模型的性能,并降低了模型的复杂性和计算开销,使其适用于移动的设备和资源有限的环境中。随后,研究人员利用特征图[21]、注意力[22]等方法,实现了多种教师模型知识向学生模型的传递。魏淳武等[23]借助知识蒸馏在模型迁移方向上的优势,将带有长时期随访信息的分类任务转换为基于领域知识的模型迁移任务;刘明静[24]采用多个教师辅助模型来进行知识传递;李宜儒等[25]利用知识蒸馏算法训练轻量级学生模型,并引入师生间的注意力机制提高模型性能。然而,学生模型可能过于依赖教师模型的知识,导致在面对与教师模型的训练数据分布不一致的新数据时的表现较差。有研究者尝试将学生网络本身作为教师网络命名为自我知识蒸馏(Self\|KnowledgeDistillation,SKD)[26]。KANG等[27]结合了神经架构搜索和自蒸馏,以改进学生模型在图像分类任务中的性能。ZHANG等[28]研究了深度相互学习策略,该策略不需要强大的静态教师网络,而是采用一组学生网络在训练中相互合作学习。KIM等[29]提出渐进式自蒸馏(ProgressiveSelf\|KnowledgeDistillation,PS\|KD)方法,通过逐渐增大温度参数,实现了渐进性训练,提高了模型的泛化能力、适应性和稳定性。
综上,本文提出了一种复合知识蒸馏(CKD)方法,综合利用知识蒸馏和渐进式自蒸馏两者的优势,可以同时传递详细和抽象的知识,提升模型性能,减少过拟合,并增强模型的适应性。
2算法原理(Algorithmprinciple)
2.1数据增强
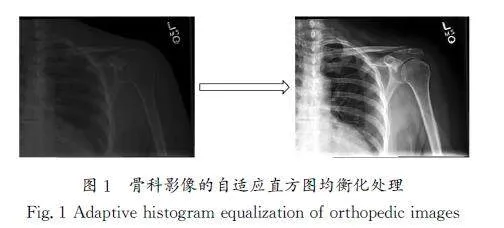
自适应直方图均衡化是医学影像预处理的关键步骤,目的是增强图像的对比度,以便于诊断网络更好地识别细节和结构特征。对输入图像的直方图进行评估、归一化,然后将输入图像转换为输出图像。骨科影像的自适应直方图均衡化处理如图1所示。
2.2主干网络:EfficientNet
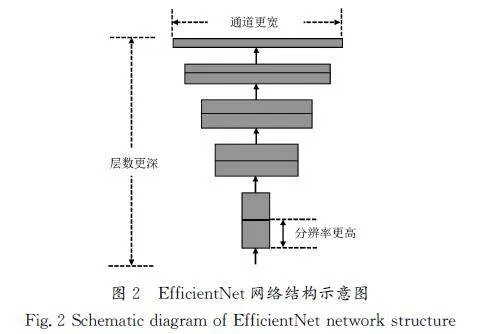
本文在知识蒸馏部分中的教师网络和学生网络分别为EfficientNet\|B7和EfficientNet\|B0,渐进式自蒸馏部分中的教师网络和学生网络同时为EfficientNet\|B0。EfficientNet网络通过协同增加网络的宽度(每层的通道数)、深度(网络的层数)及输入图像的分辨率,实现模型性能的显著提升,其结构示意图如图2所示。
EfficientNet网络的结构以EfficientNet\|B0为基础,通过调整分辨率、通道数和层数,形成一系列从EfficientNet\|B1到EfficientNet\|B7的模型变体。该网络共包含9个阶段,Stage1为步长为2的3×3卷积层(带有批标准化和Swish激活函数),从Stage2到Stage8,采用重复堆叠的MBConv(MobileInvertedBottleneckConvolution)结构,其中每个MBConv后附带数字1或6,表示倍率因子n。每个MBConv包括Depthwise卷积和1×1卷积,其中k3×3或k5×5表示Depthwise卷积核的大小。Channels表示每个阶段输出特征图的通道数。Stage9由一个1×1卷积层、平均池化层和全连接层组成。这种网络设计通过在不同层级上的调整和倍率因子的引入,实现了高效的特征提取和性能优化。
2.3知识蒸馏
知识蒸馏是结合了迁移学习和模型压缩思想的方法,旨在通过从预先训练的教师模型向未经训练的学生模型传递暗知识,使得学生模型在特定任务中也能表现出色。教师模型使用SoftMax输出每个类别的概率Si,如公式(1)所示,而知识蒸馏的重点在于使用logits表示模型对每个类别的概率预测值,如公式(2)所示:
其中:qi是学生网络学习的软标签,zi是每个类别的输出概率,N是类别数,T是蒸馏温度的超参数。取T为1时,公式(2)退化为SoftMax,按照logits输出各类的概率;若T逐渐增大,则输出结果的分布比较平坦,有助于保持相似的信息。教师网络和学生网络的蒸馏损失如公式(3)所示:
其中:Loss是教师网络和学生网络的总蒸馏损失,α是教师网络和学生网络中二者知识的权重。lossμ和lossν分别表示硬标签(T=1)和软标签(T≠1)的损失,如公式(4)和公式(5)所示:
其中:lossμ表示真实的标签和学生模型预测的交叉熵,lossν表示教师模型和学生模型的软标签预测的相对熵,cj是真实标签,qj是学生模型的输出,pj是教师模型的输出,N是类别数。
2.4渐进式自蒸馏
自蒸馏是指使用学生网络成为教师网络本身,并利用其过去的预测在训练期间具有更多的信息监督,设PSt(x)是来自学生网络在第t轮的关于x的预测。然后在第t轮的目标可以写为
其中:x、y分别为输入和对应的硬标签,超参数α为教师网络的权衡系数。
a1be18f90026d386b15bc0f9c5a3efcd在传统的知识蒸馏(KD)中,教师网络保持不变,因此α通常在训练期间被设置为固定值。然而在渐进式自蒸馏PS\|KD中,应该考虑教师网络的可靠性,这是因为模型通常在训练的早期阶段没有足够的数据知识。为此,可以逐渐增加α的值。第t轮的α计算公式如下:
其中:T是训练的总次数,αT是最后时期的α,在第t轮的目标函数可以写为
2.5&na1be18f90026d386b15bc0f9c5a3efcdbsp;复合知识蒸馏模型
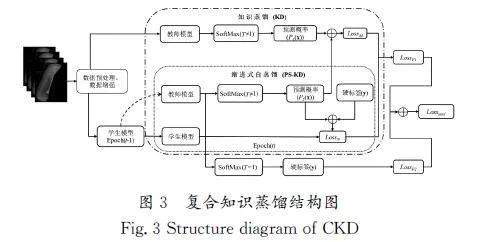
本文融合了知识蒸馏和渐进式自蒸馏的优势,同时弥补了学生网络容易过拟合和过度依赖教师网络的问题,提出了一种复合知识蒸馏的方法。此模型能在进行模型压缩的同时,尽可能提高模型的性能。将EfficientNet作为数据特征提取器,在知识蒸馏部分,教师网络为EfficientNet\|B7,学生网络为EfficientNet\|B0,在渐进式自蒸馏部分,选择EfficientNet\|B0作为学生网络,最终将两个部分的损失之和作为复合蒸馏模型的损失。复合知识蒸馏结构图如图3所示。
复合知识蒸馏分为两个部分,分别为整体框架下的知识蒸馏和局部的渐进式自蒸馏。渐进式自蒸馏部分使用EfficientNet\|B0作为训练网络,整体框架下的知识蒸馏网络的教师网络为EfficientNet\|B7,其学生网络来自同一训练轮次下的渐进式自蒸馏网络。最终复合知识蒸馏网络训练的总损失为Losstotal,分别来自知识蒸馏网络的蒸馏损失LossF1,以及渐进式自蒸馏网络的预测与真实硬标签的损失LossF2。Losstotal的计算公式为
其中:β为二者损失的权衡参数,知识蒸馏网络的蒸馏损失LossF1由LossM和LossN两个部分组成,LossM为知识蒸馏网络在蒸馏温度为T时的蒸馏损失,LossN为渐进式自蒸馏网络中Epoch=t且蒸馏温度T≠1时与硬标签y之间的损失;LossF2为渐进式自蒸馏网络中Epoch=t-1且蒸馏温度T=1时与硬标签y之间的损失。相应的计算公式如下:
其中:x为输入图像,y为图像的真实硬标签。PT1j(x)、PT2j(x)分别为教师模型和学生模型在蒸馏温度为T时的软标签预测值,N为类别数,H表示交叉熵。αT为渐进式自蒸馏中软标签和硬标签之间损失的权衡系数,PSt、PSt-1分别表示学生网络中第t轮、t-1轮的预测结果。
3实验结果与分析(Experimentresultsandanalysis)
3.1数据集及预处理
MURA(MusculoskeletalRadiographs)是由美国斯坦福大学研究人员创建的,旨在帮助开发自动化算法检测和诊断骨骼系统肌肉骨骼影像中的关节疾病。MURA数据集包含超过40000张X射线图像,分布在大约14800个患者上,涵盖7个主要的关节类别,如肘关节、指关节、肱关节、肩关节、尺关节、掌关节、腕关节,MURA数据集样本展示如图4所示。原MURA的数据集共有1560张肱关节图片,通过随机水平翻转、随机旋转和高斯模糊技术对数据集进行数据增强,将数据集的数量增加了3倍,达到4680张。为了更有效地评估模型性能,同时重新划分训练集和测试集的比例,按照8∶2的比例将数据集划分为训练集和测试集,数量分别为3744张和936张。
3.2实验参数配置
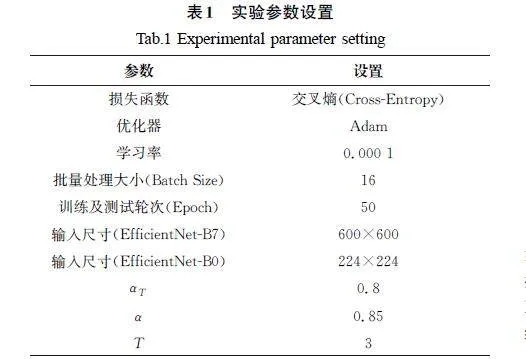
使用Python语言在GPU加速环境中进行实验,采用Pytorch深度学习框架,电脑配置为Windows11系统、128GB内存、NVIDIARTXGeforce4090显卡、48GB显存。表1列出了本实验的部分参数设置。
3.3实验评价指标
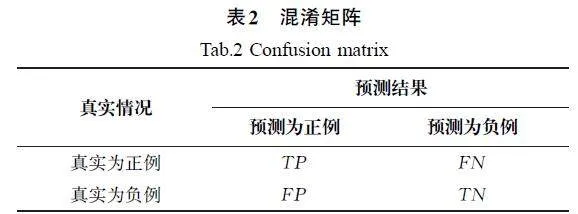
计算机辅助诊断系统的诊断性能通常用准确率(Accuracy)、召回率(Recall)、精确率(Precision)3个指标来衡量,这些指标可通过混淆矩阵计算获得,混淆矩阵主要用于比较真实情况和预测结果,如表2所示。
对于医学图像的ROI(RegionofInterest)区域,可以用阳性或阴性描述病变或非病变,其判断的正确性可以用真或假表示。准确率、召回率、精确率的公式表示如下:
Accuracy=[(TP+TN)/(TP+TN+FP+FN)]×100%[JZ)][JY](14)
Recall=TPR=[TP/(TP+FN)]×100%[JZ)][JY](15)
Precision=[TP/(TP+FP)]×100%[JZ)][JY](16)
3.4模型对比分析
本文使用4种不同的分类网络(VGG16、InceptionV3、ResNet50、DenseNet121)验证在经过数据增强之后的MURA当中肱关节的分类识别效果。训练过程和训练超参数在所有网络上保持完全一致,并保存了每个网络的最佳模型。接着,使用肱关节数据集对这些模型进行训练,使用相同的参数设置,包括BatchSize为16、Epoch为50、学习率为0.0001,均使用交叉熵损失函数和Adam优化器。
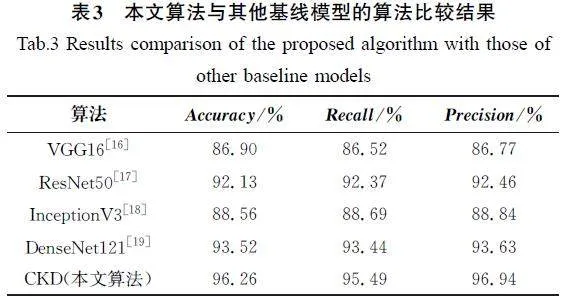
将本文提出的模型经训练后,对20%的样本进行测试,训练和测试过程的Loss曲线如图5所示。从图5中可知,模型经过训练,在训练集和测试集上都展现出了较好的学习能力,损失曲线逐渐下降并趋于稳定。尽管在测试集上的损失略高于训练集,差距仅为0.2,表明模型在未见过的数据上仍然保持了相对良好的泛化能力。为了验证本文算法的有效性和优越性,将本文所提出的模型与其他基线模型进行对比和消融实验对比。首先在同一数据集上分别与传统的基线模型VGG16、InceptionV3、ResNet50、DenseNet121进行对比,表3为本文算法与其他基线模型的算法比较结果。
从表3中的数据可以看出,本文方法性能表现出显著优势,准确率达到96.26%、召回率达到95.49%,精确率达到96.94%。准确率比基线模型VGG16、InceptionV3、ResNet50、DenseNet121依次提高了10.77%、8.69%、4.48%、2.93%。
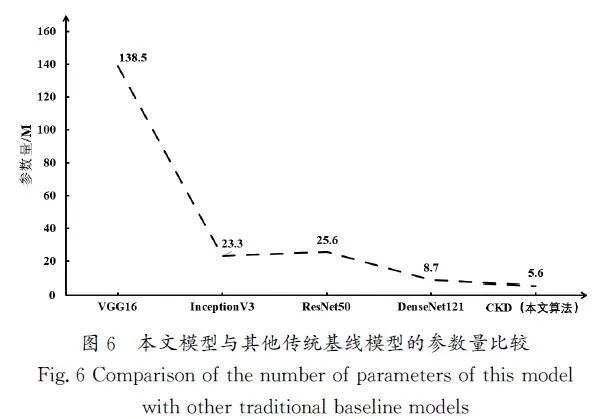
从图6中可以看出,针对模型参数量而言,VGG16的参数量最大,本文模型参数量仅是它的4.04%,相对于其他模型而言,参数量也较小,这得益于EfficientNet网络本身及复合知识蒸馏的效果,充分验证了本文模型的有效性。
上述实验仅仅对MURA当中的肱关节数据集进行实验对比,为了更好地验证所提出模型在其他数据集上的迁移能力和性能,以同样的方法,对MURA当中的其他类别的数据集进行了训练和测试。
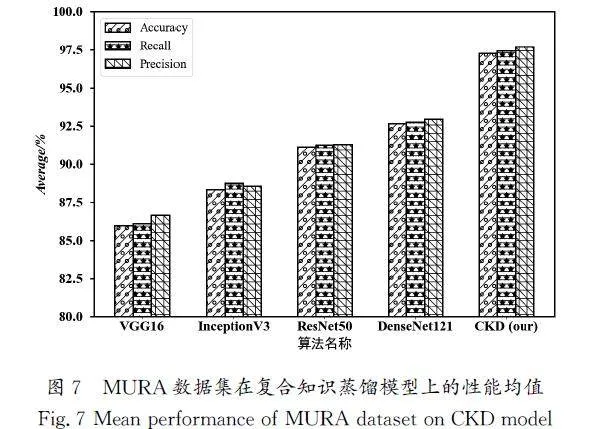
为了全面评估本文模型的性能,将其应用于MURA数据集中的其他多个关节部位,包括指关节、肘关节、腕关节、尺关节、肩关节和掌关节进行训练和测试,求出每一种数据集的相关测试评价指标的数值。将该模型在每一种数据集上针对相同的评价指标得到的数值做平均,即该模型在不同数据集上针对相同评价指标的测试结果的均值。采用同样的方法求得VGG16、InceptionV3、ResNet50、DenseNet121在MURA的其他数据集上的均值,如图7所示,总体性能情况与单一肱关节数据集的测试结果一致,本文模型依然能够表现出优异的迁移能力和性能。
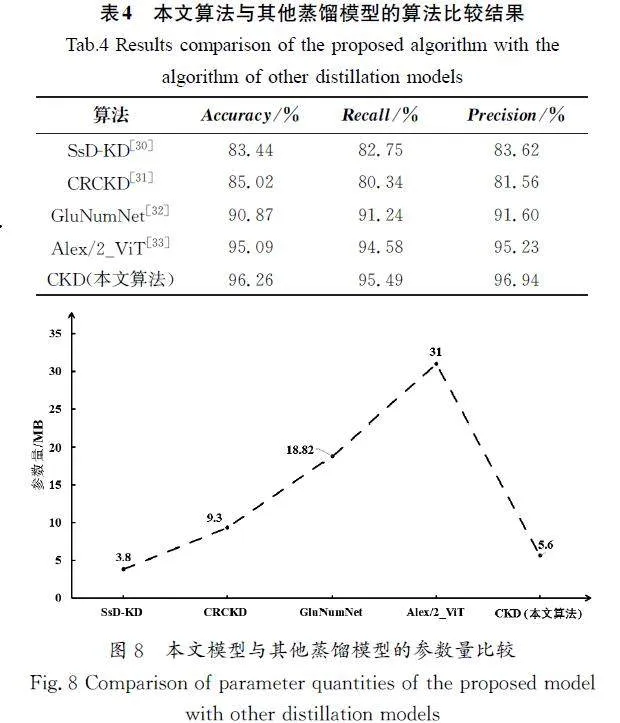
将本文的复合知识蒸馏(CKD)方法与当前其他先进的蒸馏方法在肱关节数据集上进行实验比较,结果如表4所示。相较于SsD\|KD[30]、CRCKD[31]、GluNumNet[32]、Alex/2_ViT[33],本文算法的准确率、召回率、精确率都具有明显的提升,其中准确率相较于它们依次提高了15.36%、13.22%、5.93%、1.23%。由图8可知,与SsD\|KD相比,本文算法的模型参数量增加了约0.5倍;与CRCKD、GluNumNet、Alex/2_ViT相比,本文算法的参数量有明显的降低,参数量减少了39.78%、70.24%、81.94%,并且在降低模型参数量的同时提升了模型的性能。
3.5消融实验
为进一步分析各个模块的作用,分别用EfficientNet\|B0、EfficientNet\|B7、自蒸馏(SKD)、知识蒸馏(KD)以及本文方法复合知识蒸馏(CKD)对同一数据集(肱关节数据集)进行消融实验,并利用相关评价指标对实验结果进行对比,结果如表5所示。从表5中的数据可以看出,EfficientNet\|B0是EfficientNet系列中参数量最低的网络,其准确率达到了较好的水平,结果为85.86%。EfficientNet\|B0通过自蒸馏,得以充分利用单模型训练,节约了计算的内存和资源。自蒸馏使得学生模型可以从自己的输出中学习到教师模型的知识,并逐渐提高了自身的性能,准确率也提升至92.74%,从而在资源有限的设备上实现较好的性能,但容易造成过拟合的现象。通过知识蒸馏,本实验采用的离线蒸馏将训练好的模型用作测试,并将其迁移至移动设备上,能够大大节省设备的占用资源,对于自蒸馏而言,知识蒸馏的准确率也提升至93.53%。学生模型在训练时充分利用了教师模型的知识,提高学生模型的泛化能力,尤其在数据较少的情况下的表现更好,但是存在学生模型过于依赖教师模型的现象。因此,本文提出的复合知识蒸馏方法结合了二者的优势,并弥补了各自的不足。蒸馏模型的共同点均是利用小模型达到大模型所具有的优势,从而实现模型压缩与效能提升的双重目标。
消融实验各模型参数量比较如图9所示,本文提出的复合知识蒸馏方法较Efficient\|Net\|B0、自蒸馏、知识蒸馏的模型参数量略微增加,但其模型性能却有了明显的提升,准确率达到了96.26%,较EfficientNet\|B0、自蒸馏、知识蒸馏分别提高了12.11%、3.80%和2.92%。此外,本文提出的复合知识蒸馏方法的模型参数量仅为EfficientNet\|B7的8.48%,但其准确率却只相差1.16%,模型性能可与之相媲美。
3.6不同的超参数对模型性能的影响
蒸馏模型的性能在很大程度上受到超参数α和蒸馏温度T的影响,同时本文提出的复合知识蒸馏方法中含有自蒸馏模型,其中采用的是渐进式自蒸馏模型,超参数α是随着训练的次数变化而变化的,受αT和Epoch的影响,设置αT为0.8,设置Epoch为50。为了对比不同的超参数对蒸馏模型性能的影响,上述实验是在α=0.85、T=3的条件下进行测试的。同理,在肱关节数据集上对本文模型进行对比,可以在一定范围内得出最佳的性能,如表6所示。从表6中的数据可知,随着α和蒸馏温度T的不断增大,其模型的测试准确率大致呈现逐渐上升的趋势,但也发现,超参数不是越大越好,在蒸馏温度为7时,蒸馏效果就不如3和5。其中,当蒸馏温度为5、α为0.85时,本文模型的准确率高达97.13%,与EfficientNet\|B7相媲美。同时,表6中的数据是在有限的参数设定下的结果,要想探索更优的效果,可以采用更加系统的方法进行搜索,如网格搜索法等。
4结论(Conclusion)
针对医学影像诊断领域因设备存储有限等导致模型诊断结果不理想的问题,本文提出一种复合知识蒸馏方法。选用EfficientNet作为主干网络,为了提高模型的性能和减少设备资源占用,引入了知识蒸馏的思想,选用模型较大、性能优的EfficientNet\|B7作为教师模型,选用模型较小、性能优的EfficientNet\|B0作为学生模型。此外,研究人员对学生模型采用了渐进式自蒸馏方法,旨在更好地挖掘数据特征。本文综合了二者的优势,知识蒸馏使得复杂模型的精华能够被传递给学生模型,使得简单模型能够在保持较低计算资源消耗的情况下,达到接近复杂模型的性能。渐进式自蒸馏则通过引入“伪标签”进行自我训练,不断地提升模型在未标记数据上的表现,从而加强了其泛化能力。然而,本文方法也存在一些缺陷,主要是本文模型的性能与超参数(T、α、αT等)的设置有紧密联系,但在选择和调整超参数时方法相对局限,因此未来工作应重点解决如何通过更加简单有效的方法调整超参数以获得最佳性能。此外,还可以探索更好的模型轻量化方法,不断提升模型的性能和降低模型的复杂度。
参考文献(References)
[1]赵晓阳,许树林,潘为领,等.公共人工智能平台在膝关节骨性关节炎分期中的应用[J].实用临床医药杂志,2022,26(8):22\|26.
[2]JOSHID,SINGHTP.AsurveyoffracturedetectiontechniquesinboneX\|rayimages[J].Artificialintelligencereview,2020,53(6):4475\|4517.
[3]HGEM,WHLINGT,NOWAKW.Aprimerformodelselection:thedecisiveroleofmodelcomplexity[J].Waterresourcesresearch,2018,54(3):1688\|1715.
[4]LISL,ZHANGXJ.ResearchonorthopedicauxiliaryclassificationandpredictionmodelbasedonXGBoostalgorithm[J].Neuralcomputingandapplications,2020,32(7):1971\|1979.
[5]SEIBOLDM,MAURERS,HOCHA,etal.Real\|timeacousticsensingandartificialintelligenceforerrorpreventioninorthopedicsurgery[J].Scientificreports,2021,11(1):3993.
[6]DIPALMAJ,SURIAWINATAAA,TAFELJ,etal.Resolution\|baseddistillationforefficienthistologyimageclassification[J].Artificialintelligenceinmedicine,2021,119:102136.
[7]PIZERSM,AMBURNEP,AUSTINJD,etal.Adaptivehistogramequalizationanditsvariations[J].Computervision,graphics,andimageprocessing,1987,39(3):355\|368.
[8]TANMX,LEQV.EfficientNet:Rethinkingmodelscalingforconvolutionalneuralnetworks[EB/OL].(2020\|09\|11)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1905.11946.
[9]WANGJJ,LUOJW,HOUNYEAH,etal.Adecoupledgenerativeadversarialnetworkforanteriorcruciateligamenttearlocalizationandquantification[J].Neuralcomputingandapplications,2023,35(26):19351\|19364.
[10]RINISHAB,SULOCHANAW,KUMARAW.Awavelettransformandneuralnetworkbasedsegmentationclassificationsystemforbonefracturedetection[J].Optik,2021,236:166687.
[11]SEZERA,SEZERHB.Deepconvolutionalneuralnetwork\|basedautomaticclassificationofneonatalhipultrasoundimages:anoveldataaugmentationapproachwithspecklenoisereduction[J].Ultrasoundinmedicine&biology,2020,46(3):735\|749.
[12]BIENN,RAJPURKARP,BALLRL,etal.Deep\|learning\|assisteddiagnosisforkneemagneticresonanceimaging:developmentandretrospectivevalidationofMRNet[J].PLoSmedicine,2018,15(11):e1002699.
[13]LINL,DOUQ,JINYM,etal.DeeplearningforautomatedcontouringofprimarytumorvolumesbyMRIfornasopharyngealcarcinoma[J].Radiology,2019,291(3):677\|686.
[14]AKCAYS,KUNDEGORSKIME,WILLCOCKSCG,etal.UsingdeepconvolutionalneuralnetworkarchitecturesforobjectclassificationanddetectionwithinX\|raybaggagesecurityimagery[J].IEEEtransactionsoninformationforensicsandsecurity,2018,13(9):2203\|2215.
[15]KRIZHEVSKYA,SUTSKEVERI,HINTONGE.ImageNetclassificationwithdeepconvolutionalneuralnetworks[J].CommunicationsoftheACM,2017,60(6):84\|90.
[16]SIMONYANK,ZISSERMANA.Verydeepconvolutionalnetworksforlarge\|scaleimagerecognition[EB/OL].(2015\|04\|10)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1409.1556.
[17]HEKM,ZHANGXY,RENSQ,etal.Deepresidual&nbdRHaOJtq8GNN55+t29kdY4b8gAUIKn+2z1cHgDXawM=bsp;learningforimagerecognition[C]∥IEEE.ProceedingsoftheIEEE:2016IEEEConferenceonComputerVisionandPatternRecognition.Piscataway:IEEE,2016:770\|778.
[18]SZEGEDYC,LIUW,JIAYQ,etal.Goingdeeperwithconvolutions[C]∥IEEE.ProceedingsoftheIEEE:2015IEEEConferenceonComputerVisionandPatternRecognition.Piscataway:IEEE,2015:1\|9.
[19]HUANGG,LIUZ,VANDML,etal.Densely ;connectedconvolutionalnetworks[C]∥IEEE.ProceedingsoftheIEEE:2017IEEEConferenceonComputerVisionandPatternRecognition.Piscataway:IEEE,2017:2261\|2269.
[20]HINTONG,VINYALSO,DEANJ.Distillingtheknowledgeinaneuralnetwork[EB/OL].(2015\|03\|09)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1503.02531.
[21]ROMEROA,BALLASN,KAHOUSE,etal.Fitnets:Hintsforthindeepnets[EB/OL].(2015\|03\|27)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1412.6550.
[22]ZAGORUYKOS,KOMODAKISN.Payingmoreattentiontoattention:Improvingtheperformanceofconvolutionalneuralnetworksviaattentiontransfer[EB/OL].(2017\|02\|12)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1612.03928.
[23]魏淳武,赵涓涓,唐笑先,等.基于多时期蒸馏网络的随访数据知识提取方法[J].计算机应用,2021,41(10):2871\|2878.
[24]刘明静.基于多教师知识蒸馏改进策略的医学图像分类方法研究[D].天津:天津大学,2020.
[25][JP3]李宜儒,罗健旭.一种基于师生间注意力的AD诊断模型[J].华东理工大学学报(自然科学版),2023,49(4):583\|588.
[26]HAHNS,CHOIH.Self\|knowledgedistillationinnaturallanguageprocessing[EB/OL].(2019\|08\|02)[2024\|02\|04].https:∥doi.org/10.48550/arXiv.1908.01851.
[27]KANGM,MUNJ,HANB.Towardsoracleknowledgedistillationwithneuralarchitecturesearch[J].ProceedingsoftheAAAIconferenceonartificialintelligence,2020,34(4):4404\|4411.
[28]ZHANGHB,LIANGWN,LICX,etal.DCML:deepcontrastivemutuallearningforCOVID\|19recognition[J].Biomedicalsignalprocessingandcontrol,2022,77:103770.
[29]KIMK,JIB,YOOND,etal.Self\|knowledgedistillationwithprogressiverefinementoftargets[C]∥IEEE.ProceedingsoftheIEEE:2021IEEE/CVFInternationalConferenceonComputerVision.Piscataway:IEEE,2021:6547\|6556.
[30]WANGYW,WANGYH,CAIJY,etal.SSD\|KD:aself\|superviseddiverseknowledgedistillationmethodforlightweightskinlesionclassificationusingdermoscopicimages[J].Medicalimageanalysis,2023,84:102693.
[31]XINGX,HOUY,LIH,etal.Categoricalrelationpreservingcontrastiveknowledgedistillationformedicalimageclassification[C]∥Springer.ProceedingsoftheSpringer:MedicalImageComputingandComputerAssistedIntervention\|MICCAI2021:24thInternationalConference,Strasbourg,France,September27\|October1,2021,Proceedings,PartV.Piscataway:SpringerInternationalPublishing,2021:163\|173.
[32]LIGY,WANGXH.Multi\|branchlightweightresidualnetworksforhandwrittencharacterrecognition[J].Computerengineeringandapplications,2023,59(5):115\|121.
[33]LENGB,LENGM,GEMF,etal.Knowledgedistillation\|baseddeeplearningclassificationnetworkforperipheralbloodleukocytes[J].Biomedicalsignalprocessingandcontrol,2022,75:103590.
作者简介:
王烤(1998\|),男,硕士生。研究领域:控制理论与应用,深度学习,图像处理。
吴钦木(1975\|),男,博士,教授。研究领域:控制理论与应用,电动汽车传动控制,电驱动系统效率优化和故障诊断,深度学习。
