基于改进U-Net的视网膜血管分割算法
2024-10-31刘远李柏承吴春波



文章编号:1005-5630(2024)05-0009-08 DOI:10.3969/j.issn.1005-5630.202308280111
摘要:在面对视网膜图像中细小血管时,现有算法存在分割精度低的问题。通过在U-Net中引入残差模块与细节增强注意力机制模块,提出了一种改进的U-Net分割算法。在编解码阶段,用残差模块取代传统的卷积模块,解决了网络随深度增加而退化的问题;同时在编码器和解码器间增加细节增强注意力机制,减少编码器输出中的无用信息,从而提高网络抓取有效特征信息的敏感度。此外,基于标准图像集DRIVE的实验结果表明,所提算法的分割准确率、灵敏度与F1值较U-Net算法分别提高了0.46%,2.14%,1.56%,优于传统分割算法。
关键词:图像分割;视网膜血管;细节增强;残差模块
中图分类号:TP 391文献标志码:A
Retinal blood vessel segmentation algorithm based on improved U-Net
LIU Yuan,LI Baicheng,WU Chunbo
(School of Optical-Electrical and Computer Engineering,University of Shanghai for Science andTechnology,Shanghai 200093,China)
Abstract:The existing algorithms have the problem of low segmentation accuracy when facing small vessels in retinal images.In this paper,an improved U-Net segmentation algorithm is proposed by introducing residual module and detail enhancement attention mechanism module into U-Net network.In the coding and decoding stages,the residual module is used to replace the traditional convolutional module,which solves the problem of network degradation with increasing depth.Meanwhile,a detail enhancement attention mechanism is added between the encoder and the decoder to reduce the useless information in the output of the encoder,so that the sensitivity of the network to capture valid feature information is improved.In addition,the experimental results based on the standard image set DRIVE reveal that the segmentation accuracy,sensitivity and F1 score of the proposed algorithm are improved by 0.46%,2.14%and 1.56%,respectively compared to the U-Net,which is superior to the traditional segmentation algorithms.
Keywords:image segmentation;retinal vessels;detail enhancement;residual module
引言
视网膜血管是人体微循环的重要组成部分,其血管直径、迂曲度和分支模式等形态学变化特征与青光眼、糖尿病、高血压等疾病的严重程度密切相关。例如,原发性高血压会导致视网膜血管的痉挛和狭窄,血管壁增厚,严重者会导致渗出、出血和棉絮斑。医生利用仪器观察和分析视网膜的血管形状、粗细以及有无增生,可以对眼底疾病进行有效筛查和诊断。由于视网膜血管的厚度变化大、眼科疾病的体征以及光照不平衡等问题,视网膜血管分割具有挑战性。目前临床上需要经验丰富的专家手动分割视网膜区域。这种人工操作方法不仅耗时耗力,分割结果也不理想[1–4]。因此,找到一种高效的自动视网膜血管分割方法辅助医生进行检查和诊断是一项非常重要且有意义的工作。
一般来说,基于机器学习的视网膜血管分割算法可以大致分为两类:无监督方法和有监督方法,两者的区别在于输入数据是否有人工分割的标签。有监督学习需要海量的数据标签,训练周期较长,但具有良好的泛化效果[5]。无监督方法,如匹配滤波[6]、形态学[7]、血管跟踪方法[8]等,可以自动根据现有数据学习和寻找目标的特征信息,找到类似血管的模式或簇。但是当分割图像存在过多的干扰信息时,无监督提取血管分割算法的分割效果欠佳,性能还有待进一步提高。
随着计算机视觉领域的快速发展,深度学习技术在图像处理方向发挥了重要作用。深度学习是仿造神经元的结构去模拟人类思考的思维模式,可以快速处理原始数据以提取有效特征和自动学习特征分类。深度学习打破了传统特征选择方法的设计复杂性和局限性,避免了人工选择特征的误差,网络模型可以从海量的数据库中学习最深层的特征。由于深度卷积神经网络(DCNN)的成功,许多分割网络被提出并应用于医学图像领域,如全卷积神经网络(FCN)[9]、Deep Lab[10]、SegNet[11]、U-Net[12]等。通过引入跳跃连接,U-Net能够有效融合图像低层和高层特征,减少语义鸿沟问题,在医学图像上表现出了良好的检测能力。Wang等[13]提出双编码U-Net(DEUNet),显著增强了网络以端到端和像素到像素的方式分割视网膜血管的能力。Yoo等[14]引入注意力机制,增加有用特征信息的权重,减少冗余信息的干扰,进一步提高网络的表达能力。Cherukuri等[15]使用多尺度表示滤波器来处理血管厚度多样性。此外,Yan等[16]提出了一种新的片段级损失,改善了薄血管的分割结果。上述网络模型在视网膜血管分割的研究任务中都可以获取精确的血管轮廓和细节信息,但依然存在以下问题:一方面,在许多边缘区域,低对比度使微小血管与背景难以区分;另一方面,用于模型的样本较少,容易出现过拟合问题。
因此,本文提出一种改进的U-Net视网膜血管分割算法。首先对数据进行通道提取,选取对比度较高的通道作为输入并进行归一化、均衡化等预处理操作;然后用残差模块替代传统卷积,不仅解决了梯度消失和梯度爆炸的问题,还能提高网络的性能;最后在编解码间采用细节增强注意力机制进行跳跃连接,提高网络对微小的血管特征抓取的能力。将残差模块和注意力机制模块与U-Net相结合,能够有效提高模型对血管轮廓分割的准确性以及细节特征识别能力。
1算法原理
1.1改进的U-Net
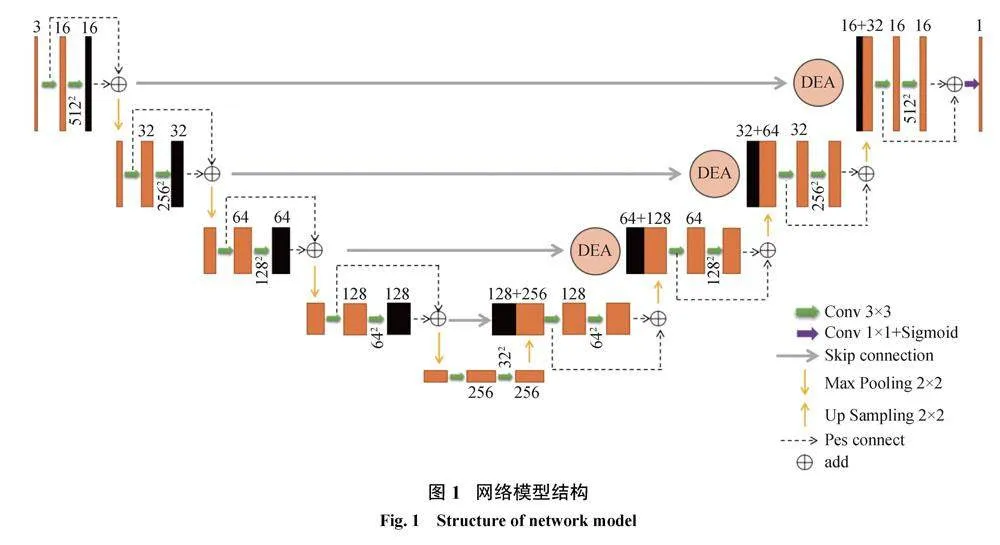
受到ResNet和传统递归网络的启发,并参考了当前基于CNN的U-Net的一些想法,本文对U-Net进行了改进。首先将U-Net编码器和解码器的传统卷积Conv+ReLU结构改为残差模块。由于网络深度的增加,使用残差结构可以避免网络深度增加导致的梯度消失问题。另外在跳跃连接处引入细节增强注意力机制(DEA),可以支持通道之间的复杂相关性,并减少网络深度增加导致的参数数量和计算负担。
图1为本文改进的U-Net框架,由编码器、解码器、带有细节增强注意力机制的跳跃连接三部分组成。编码器包含4组下采样层和残差卷积模块,解码器由4组上采样和残差卷积模块以及最高层1×1的卷积层组成,用来恢复特征大小,将通道数降为一维并通过Sigmoid激活函数输出分割结果。编解码器之间由带有注意力机制的跳跃层连接,用以在提高网络分割精度的同时捕获到视网膜血管的更多细节特征。
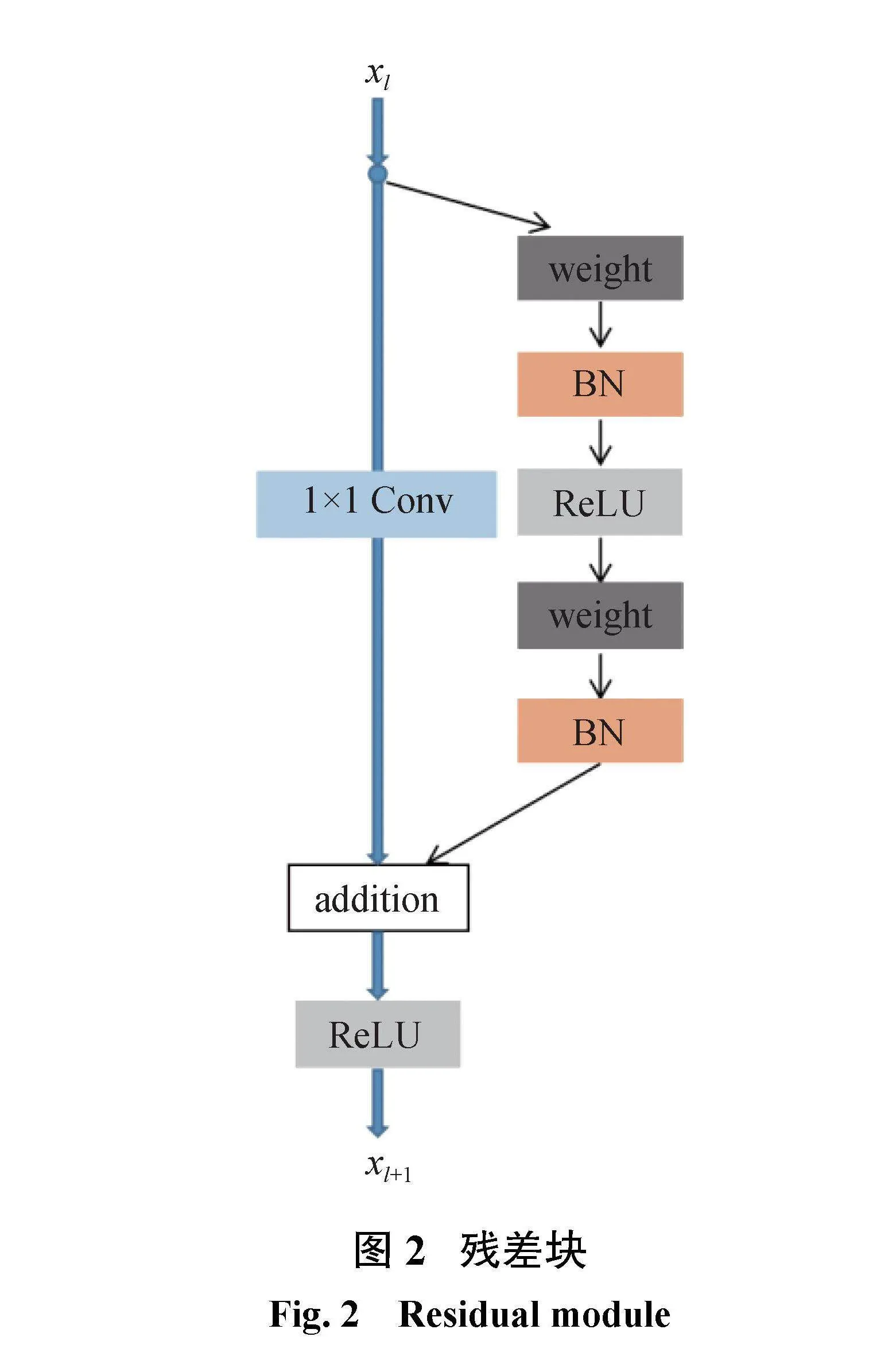
1.2残差模块
在深度学习的模型搭建过程中,网络层次的不断加深会导致梯度消失和梯度爆炸。虽然使用数据的初始化和正则化可以有效解决梯度问题,但是模型的性能也会受到影响。因为网络模型的不断加深,模型训练难度越来越大,训练的错误会先减少后增多,模型的性能会明显下降。He等[17]提出残差ResNet模块可以有效解决梯度消失和梯度爆炸问题,通过shortcut操作将输入恒等映射到输出,保证信息传递的完整性,使深层网络更易训练。即使网络模型层次再深,训练结果也可以表现优越。
在原始的U-Net网络模型中,传统的卷积层由两个Conv-BN-ReLU组成。频繁的卷积和冷却操作会产生大量的噪声信息。批量归一化(BN)方法可以规范隐藏层神经的激活值,防止出现基本信息,并提高模型的表达能力。ReLU可以降低模型的复杂性,加快收敛速度。
ResNet网络由一系列的残差模块构成。如图2所示,一个残差块可以表示为
xl+1=xl+F(xl;Wl)(1)
残差块由直接映射和残差结构两个环节构成。其中h(xl)是直接映射,F(xl;Wl)是残差部分,可由2个或者3个卷积层组成。图2左边部分代表直接映射,图2中右侧包含卷积的部分代表残差结构,weight在网络中是指卷积操作,addition是指单位加操作。
在卷积网络中,xl可能和xl+1的Feature Map的数量不一致,因此需要使用1×1卷积减少或者扩增参数达到统一。此时,残差块表示为
xl+1=h(xl)+F(xl;Wl)
其中h(xl)=Wl、x,Wl、是1×1卷积操作。
1.3注意力机制
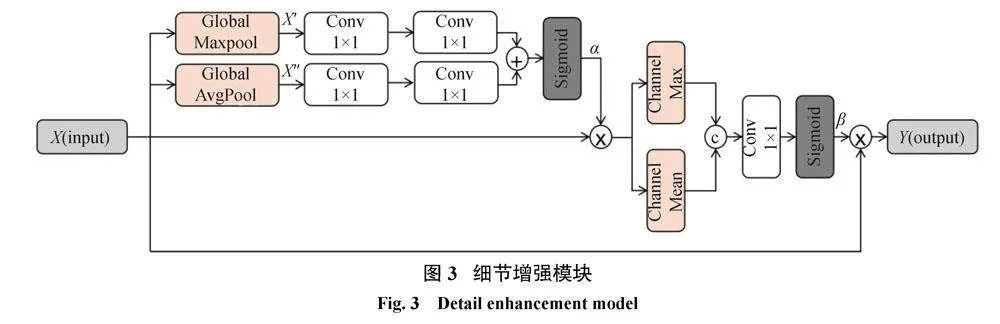
虽然在特征提取部分引入了残差模块,可以提取丰富的上下文特征,但在连续的下采样操作中,会丢失大量微小对象的特征。对于U-Net体系结构,简单的跳跃连接只能在一定程度上减轻池化层导致的信息丢失问题对整体分割精度的影响。为了使分割网络获取视网膜血管的更多细节,提出一种细节增强注意力(detail enhancement attention,DEA)机制来代替简单的跳跃连接。DEA是一个进行图像恢复编码端到解码端的模型,当编码端以不同尺寸的卷积核提取到不同深度的信息时,通过注意力机制增强感兴趣的区域,再对增强的信息进行融合,得到增强后的结果。
视网膜血管具有不同的厚度结构,与眼底图像中的其他结构相比,这些结构通常相对较小,尤其是薄的视网膜血管。对于U-Net,来自编码器单元的特征映射包含丰富而重要的空间细节信息,但也包含一些图像噪声。本文提出DEA模块的目的是捕获视网膜血管的空间信息并减小图像噪声的影响,模型提取的有效特征可以与编码器特征充分融合,从而避免上采样过程中一些微小血管与边缘信息丢失的情况。对编码层输出执行全局池化操作,并计算注意力向量来校准特征信息的权重,从而提高网络对血管特征的敏感性。详细的细节增强注意力机制的原理如图3所示。
首先对特征图X分别进行全局最大池化和平均池化得到输出X、和X、、;其次将X、和X、、分别进行两次1×1卷积操作后融合,再经过Sigmoid激活函数得到权重系数α;然后用权重系数α校准特征图得到输出α×X,再将特征图α×X分别进行通道最大和平均操作后融合;经过1×1卷积、Sigmoid函数得到通道系数β;最后将特征图X用通道系数β校准得到最终输出特征图Y。
2实验结果与分析
2.1数据集与预处理
为了全面评估和测试提出的改进U-Net的分割性能,本文在DRIVE公共数据集上进行实验。DRIVE数据集作为视网膜血管分割常用的公共数据集,包含40幅三通道彩色图像,每幅图像的图像大小为584 pixel×565 pixel。由于DRIVE数据集数据量很小,为了避免模型在训练过程中产生过拟合现象,需要对DRIVE数据集进行数据增强。首先将预处理后的图像进行−90°到90°随机旋转;然后将图片随机进行水平或垂直翻转,概率各为50%;最后采用滑窗方式对图像进行随机切片。模型训练和测试分为两部分,比例为1∶1。20幅图像用于训练,其余部分用于模型测试。
眼底图像通常包含噪声和不均匀光照,需要在训练前进行图像预处理操作。通过实验发现,RGB三通道的绿色通道的血管与背景的对比度高,图片可以表现更细节的血管特征。因此,在预处理操作中首先提取绿色通道视网膜图片作为输入;然后对图片进行归一化处理和CLAHE算法(对比度受限自适应直方图均衡化)进一步提高视网膜血管特征与背景的对比度;最后在不影响亮度较强部分的图像质量的情况下,用伽马变换算法增强眼底视网膜图像中亮度较暗的血管部分。由于数据集数量不足容易引发过拟合问题,本文采用图像随机翻转、旋转、剪裁的数据增强技术应用于眼底图像,以构建更多的训练数据。
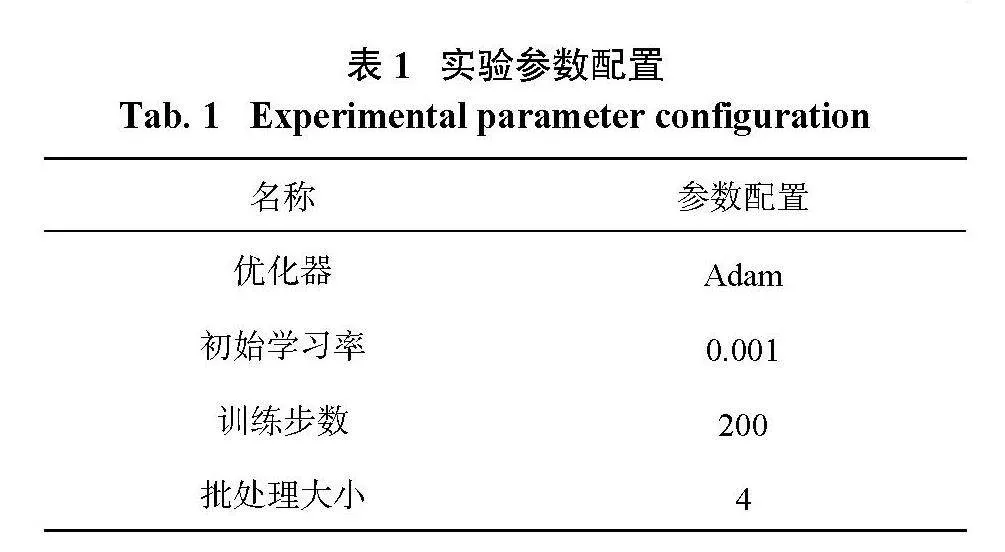
在个人计算机MAC13.1操作系统、8 GB内存、PyTorch1.13上搭建实验平台,实验操作参数如表1所示。
2.2评价指标
本文使用目前分割算法中常见的性能指标,敏感性(Sensitivity)、特异性(Specificity)、准确性(Accuracy)、F1值(F1-score)来评估算法的性能,各项指标的具体定义如表2所示。TP:被正确分割的血管像素数量;FP:错误分割的血管像素数量;TN:正确分割的背景像素数量;FN:错误分割的背景像素数量。
2.3实验结果与分析
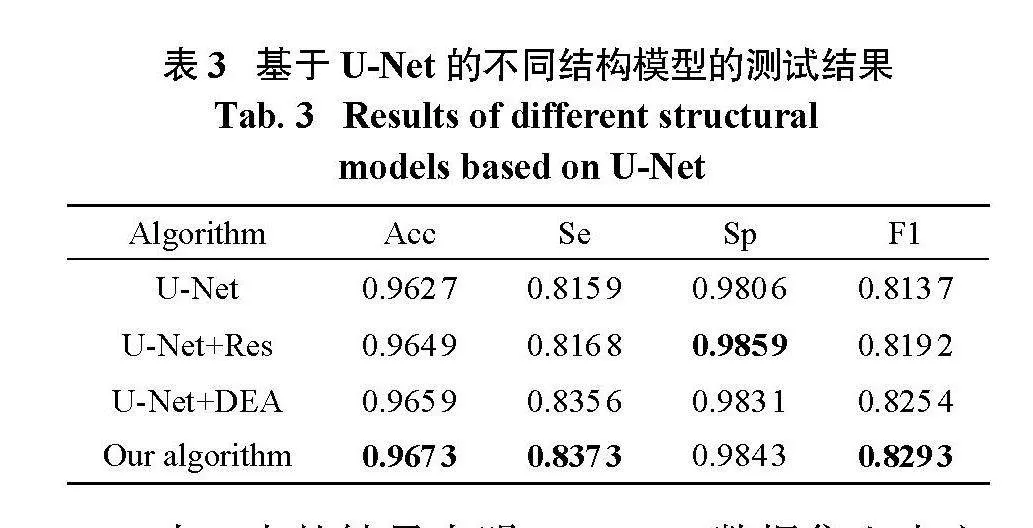
为了验证本文所提网络框架的性能,分析了不同模型的分割结果。在实验中,不同的模型训练使用相同的实验配置、参数和训练集的数量。在DRIVE数据集上进行了U-Net、U-Net+Res、U-Net+DEA以及本文算法的实验。比较了实验结果,如表3所示。
表3中的结果表明,DRIVE数据集上本文所提算法的Acc、Se和F1值高于U-Net、U-Net+Res和U-Net+DEA模型,分别为0.967 3、0.837 3和0.829 3。Sp值0.984 3高于U-Net和U-Net+DEA模型,但略低于U-Net+Res模型。整体来看,本文算法在分割结果方面优于其他3个模型。实验证明,在跳跃连接中添加细节增强模块以及在编解码路径中添加残差模块可以更好地提取视网膜血管的文本特征。
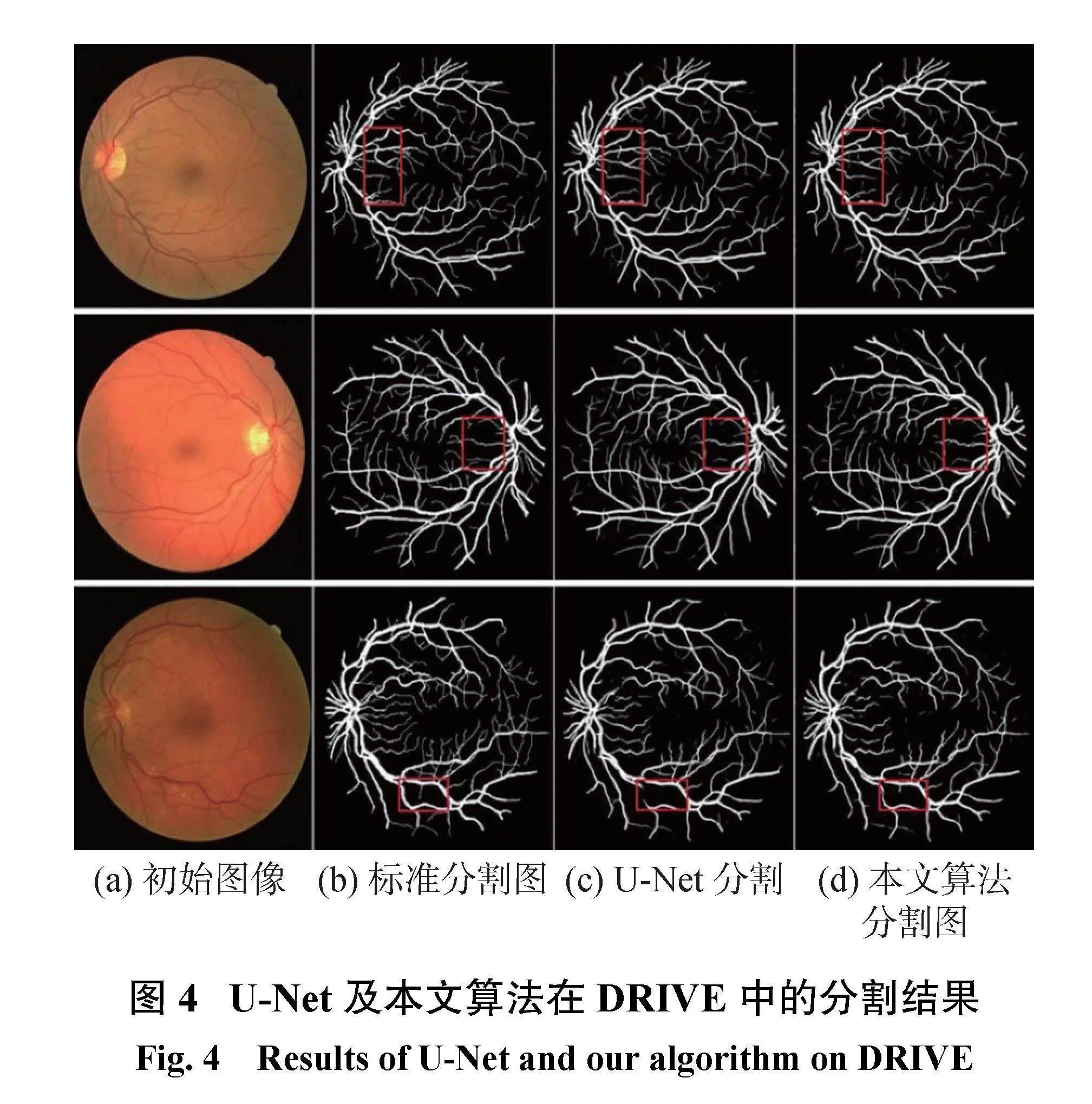
根据视网膜血管图像分割可视化图的分析结果,图4显示了U-Net和本文算法在DRIVE测试数据集上的血管分割结果。其中,图4(a)列为视网膜初始图像,图4(b)为专家标准分割图,图4(c)为U-Net模型分割结果图,图4(d)为本文算法分割结果图。实验结果验证了本文所提算法的可行性,分割结果优于U-Net模型。
图5是视网膜血管局部分割对比图,每一行包括原始图像、标准图像、U-Net分割图像和本文算法分割结果图像,并且相同局部区域的图像被放大。通过实验对比可以发现U-Net模型虽然可以检测大部分视网膜血管,但血管连接部分的检测效果较差。如分割图的第1行所示,上侧两个大血管分叉的连接处断开,并且U-Net分割结果的中间部分直接忽略了模糊小血管的分割。这表明本文提出的算法模型比U-Net模型具有更强的特征提取能力,并且可以正确地分割血管像素。
2.4不同算法指标对比
2.3节已证明本文算法模型在视网膜血管分割中比U-Net模型具有更好的性能。为了进一步证明本文算法在视网膜血管分割中的性能,在DRIVE数据集上将本文算法与现有医学图像分割领域的先进方法进行了定量对比,如表4所示。在DRIVE数据集中,所提出的算法比其他算法取得了更好的结果。与其他算法相比,本文算法Se和F1值明显优于其他方法。图6为不同算法指标对比的折线图,从图6可以明显看到,本文算法的4个性能指标明显高于大多数方法。其他算法由于未对毛细血管处进行细节增强处理,对末端细小血管的特征提取并不到位,会出现不同程度的欠分割和不连续的情况。因此,本文算法能够准确分割视网膜血管,捕获到视网膜血管的更多细节,具有良好的性能。
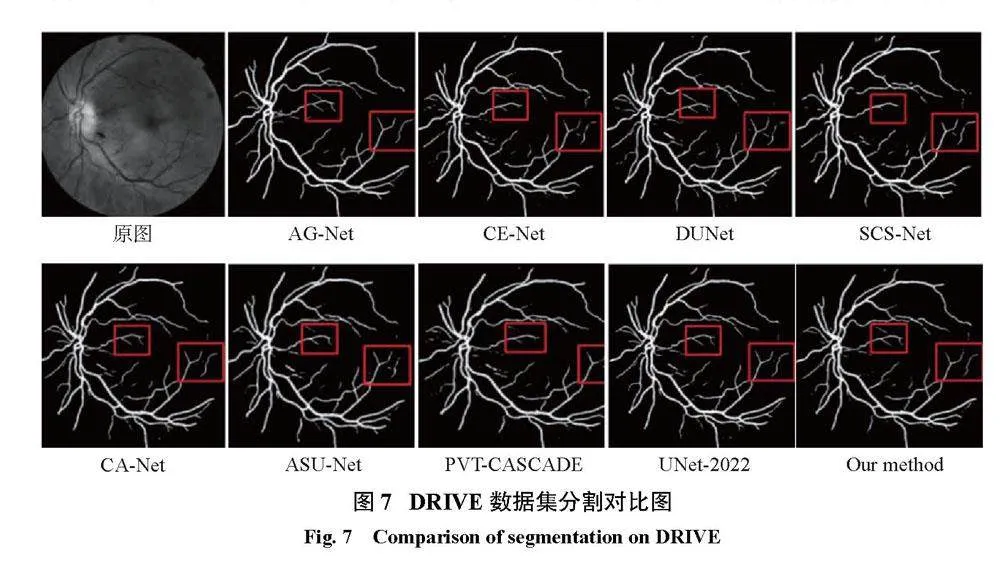
为了能更加直观地对比本文算法与其他网络的结果,现将分割图进行对比,如图7所示。从图7可以看到,在红框部分其他网络在分割血管末端时出现了不同程度的断裂和噪点,而改进的U-Net不仅完整地分割到了末端血管且未出现噪点,分割结果干净完整。这再次说明本文算法的分割结果是优于其他8个网络的。但本文算1b17b1444f295f535994dd1ba13343695240e377d9a92d54b2541948edbd9168法框架相比其他方法更为复杂,仍需致力于保持高网络分割精度的同时降低算法复杂度。
3结论
本文算法结合了ResNet和注意力机制,提出一种改进的U-Net分割模型。以U-Net为基础,先将原始的传统卷积替换为残差卷积,又引入了细节增强模块(DEA),降低下采样所导致的细小血管信息丢失的可能性。在DRIVE数据集上进行测试,得到的准确性、敏感性、特异性和F1值分别为96.73%、83.73%、98.43%和82.93%。相比传统算法,本文算法分割结果可观,整体性能较优。
参考文献:
[1]GUO Q,DUFFY S P,MATTHEWS K,et al.Microfluidic analysis of red blood cell deformability[J].Journal of Biomechanics,2014,47(8):1767–1776.
[2]CHEUNG C Y L,IKRAM M K,CHEN C,et al.Imaging retina to study dementia and stroke[J].Progress in Retinal and Eye Research,2017,57:89–107.
[3]YU L F,QIN Z,ZHUANG T M,et al.A framework for hierarchical division of retinal vascular networks[J].Neurocomputing,2020,392:221–232.
[4]FRAZ M M,WELIKALA R A,RUDNICKA A R,et al.QUARTZ:quantitative analysis of retinal vessel topology and size–an automated system for quantification of retinal vessels morphology[J].Expert Systems with Applications,2015,42(20):7221–7234.
[5]LI J,ZHANG T,ZHAO Y,et al.MC-UNet:multimodule concatenation based on U-shape network for retinal bloodvessels segmentation[J].ComputationalIntelligence and Neuroscience,2022,2022:9917691.
[6]CHAUDHURI S,CHATTERJEE S,KATZ N,et al.Detection of bloodvessels in retinal images using two-dimensional matched filters[J].IEEE Transactions on Medical Imaging,1989,8(3):263–269.
[7]ZANA F,KLEIN J C.Segmentation of vessel-like patterns using mathematical morphology and curvature evaluation[J].IEEE Transactions on Image Processing,2001,10(7):1010–1019.
[8]CHUTATAPE O,ZHENG L,KRISHNAN S M.Retinal bloodvessel detection and tracking by matched Gaussian and Kalman filters[C]//Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society.Hong Kong,China:IEEE,1998:3144−3149.
[9]JI J,LU X C,LUO M,et al.Parallel fully convolutional network for semantic segmentation[J].IEEE Access,2021,9:673–682.
[10]YUAN H B,ZHU J J,WANG Q F,et al.An improved DeepLab v3+741d5aac680d80411c9d70d13af1883e7ac2591ee3cb1f43ffdce9449a694e8edeep learning network applied to the segmentation of grape leaf black rot spots[J].Frontiersin Plant Science,2022,13:795410.
[11]BADRINARAYANAN V,KENDALL A,CIPOLLA R.SegNet:a deep convolutional encoder-decoder architecture for image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(12):2481–2495.
[12]RONNEBERGER O,FISCHER P,BROX T.U-Net:convolutional networks for biomedical image segmentation[C]//18th International Conference on Medical Image Computing and Computer-Assisted Intervention.Munich,Germany:Springer,2015:234−241.
[13]WANG B,QIU S,HE H G.Dual encoding U-Net for retinal vessel segmentation[C]//22nd International Conference on Medical Image Computing and Computer Assisted Intervention.Shenzhen,China:Springer,2019:84−92.
[14]YOO D,PARK S,LEE J Y,et al.AttentionNet:aggregating weak directions for accurate object detection[C]//2015 IEEE International Conference on Computer Vision(ICCV).Santiago,Chile:IEEE,2015:2659−2667.
[15]CHERUKURI V,KUMAR B G V,BALA R,et al.Deep retinal image segmentation with regularization under geometric priors[J].IEEE Transactions on Image Processing,2020,29:2552–2567.
[16]YAN Z Q,YANG X,CHENG K T.Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation[J].IEEE Transactions on Biomedical Engineering,2018,65(9):1912–1923.
[17]HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas,NV,USA:IEEE,2016:770−778.
[18]ZHANG S H,FU H Z,YAN Y G,et al.Attentionguided network for retinal image segmentation[C]//22nd International Conference on Medical Image Computing and Computer Assisted Intervention.Shenzhen,China:Springer,2019:797−805.
[19]GU Z W,CHENG J,FU H Z,et al.CE-Net:context encoder network for 2D medical image segmentation[J].IEEE Transactions on Medical Imaging,2019,38(10):2281–2292.
[20]JIN Q G,MENG Z P,PHAM T D,et al.DUNet:a deformable network for retinal vessel segmentation[J].Knowledge-Based Systems,2019,178:149–162.
[21]WU H S,WANG W,ZHONG J F,et al.SCS-Net:a scale and context sensitive network for retinal vessel segmentation[J].Medical Image Analysis,2021,70:102025.
[22]GU R,WANG G T,SONG T,et al.CA-Net:comprehensive attention convolutional neural networks for explainable medical image segmentation[J].IEEE Transactions on Medical Imaging,2021,40(2):699–711.
[23]SUN K X,XIN Y L,MA Y D,et al.ASU-Net:U-shape adaptive scale network for mass segmentation in mammograms[J].Journal of Intelligent&Fuzzy Systems:Applications in Engineering and Technology,2022,42(4):4205–4220.
[24]RAHMAN M M,MARCULESCU R.Medical image segmentation via cascaded attention decoding[C]//2023 IEEE/CVF Winter Conference on Applications of Computer Vision(WACV).Waikoloa,HI,USA:IEEE,2023:6211−6220.
[25]GUO J S,ZHOU H Y,WANG L S,et al.UNet-2022:exploring dynamics in non-isomorphic architecture[EB/OL].[2022-10-27].https://doi.org/10.48550/arXiv.2210.15566.
(编辑:张磊)
