利用技术分类号辅助的无监督专利实体抽取方法研究
2024-10-07陈亮尚玮姣余池牟琳夏春姊葛川











摘要:[目的/意义]无监督的专利实体抽取方法可以有效解决之前方法高度依赖标注资源的痼疾,进而推动智能技术在专利数据上的广泛应用并提升专利信息服务的能力和水平。[方法/过程] 将专利文献固有的技术分类号与主题模型相结合,利用技术分类号指导专利词汇上的主题分配过程,进而提出一种无需实体标注信息的专利实体抽取方法。[结果/结论] 利用硬盘驱动器薄膜磁头领域专利数据集和IPC技术分类体系进行实证分析,实验结果显示,不同层级的技术分类号在实体抽取上效果差异巨大,而基于IPC第五层级技术分类号方法的实体抽取效果远优于常规的SAO方法。
关键词:实体抽取;主题模型;专利挖掘;技术分类号
分类号:G202; TP181
引用格式:陈亮, 尚玮姣, 余池, 等. 利用技术分类号辅助的无监督专利实体抽取方法研究[J/OL]. 知识管理论坛, 2024, 9(4): 422-436 [引用日期]. http://www.kmf.ac.cn/p/403/. (Citation: Chen Liang, Shang Weijiao, Yu Chi, et al. Research on Unsupervised Patent Entity Extraction Method Assisted by Technology ClassifiR+SZbWRDsLlIlfjAu0Is9WR2TEoHsTTruKGGmh3RVHQ=cation Codes[J/OL]. Knowledge Management Forum, 2024, 9(4): 422-436 [cite date]. http://www.kmf.ac.cn/p/403/.)
1 引言/Introduction
当前企业、科研院所等技术创新主体对专利情报的需求不仅包括宏观数据统计,更需要在理解专利内容的基础上,直接为其提供专利侵权风险规避、技术机会发现、技术路线选择等决策支持服务。传统通过人工阅读来理解专利内容的方式,受制于稀缺的专家资源,耗时耗力、效率低下,而作为计算机理解文本内容之根基的信息抽取技术,则凸显出重要的研究价值和广阔的应用前景。
信息抽取旨在将自由文本转化为结构化语义信息,实体抽取是其中的关键环节。然而相比常规文本(如新闻、论文等),专利文本从形式上更加冗长复杂,大量科技术语形式缺乏规范,且新术语层出不穷;从内容上讲,专业知识高度密集,实体类型、数量繁多,语义关系错综复杂,从而导致直接套用面向常规文本的自然语言处理技术会出现一定程度的性能下降;此外,当前效果最好的实体抽取方法均为有监督学习方法,然而标注数据是一种极为稀缺、昂贵的信息资源,尤其以专利挖掘领域为甚,截至目前,可公开获取的专利信息抽取标注数据集仅有3个,即CPC-2014[1]、ChemProt[2]和TFH-2020[3]。不仅如此,由于专利的领域特定(domain-specific)属性,不同技术领域的专利无论技术内容还是语言特性均存在较大差别。以技术内容为例,在硬盘磁头驱动器专利标注数据集TFH-2020中的实体类型包括零件、原材料、形状、功能、物理流、信息流等,而医药化学专利标注数据集ChemProt中的实体类型则是化合物、基因、蛋白质,从而造成不同技术领域的标注数据难以跨领域使用。
在这种情况下,研究者更青睐无标注的实体抽取方法,诸如利用句法解析软件从专利文本中获取词性、句法依存关系等特征,并在此基础上制定相关规则以获取专利实体,从而使专利实体抽取不再受到标注数据的限制。然而,L. Chen等[3]发现,这种方法在专利文本上的实体抽取效果并不尽如人意,在精确匹配标准下实体抽取的F1值仅为1.7%。如何在无标注数据集的条件下提升实体抽取效果,成为一个亟待解决的问题。实际上,专利文献具有丰富的题录数据,如专利家族、法律状态和技术分类号等,尤其技术分类号,指示了当前专利所属的技术领域或所实现的功能应用,当该专利具备多种多技术交叉属性时,会被同时赋予多个技术分类号。这些技术分类号虽然面向整篇专利,但在专利文本中均有相应的技术内容,如果智能算法能将这些技术分类号与专利文本中的技术内容自动对应起来,则可以形成一套无需实体标注信息的专利实体抽取方法。
因此,笔者将专利文献固有的技术分类号与主题模型相结合,利用技术分类号指导专利词汇上的主题分配过程,进而提出一种新的无标注专利实体抽取方法。实验结果表明,在精确匹配标准下该方法将实体抽取的F1值提升至13.2%,而在将停用词去除后F1值能进一步提升至15.4%,提升幅度巨大。本文研究思路如下:①对相关研究内容进行文献调研和梳理;②阐述笔者提出的基于主题模型的专利实体抽取方法;③以TFH-2020数据集为基础,形成扩展数据集TFH-2020-extension,进而展开实证分析;④总结本方法的优势和不足,并对下一步工作进行展望。
2 相关研究/Literature review
2.1 专利实体内涵辨析
实体抽取任务旨在从文本中识别具有特定意义的实体的边界和类型。在自然语言处理技术通常处理的文本(如新闻、评论)中,常见的实体类型包括地址、人物、机构、货币、百分数、日期、时间等[4-5]。然而专利文本中包含着对发明创新及其技术背景、实现细节和权利要求等内容的描述,其所定义的实体类型会因分析目的和所在领域不同而有所差异,通常有两种定义方式:①根据分析目标划分,比如为识别行业创新方向和可能的技术机会,S. Dewulf[6]、H. Park等[7]将可标记物划分为功能、属性两类,进而从不同专利文本中提取出技术组成、功能效果、新颖性、先进性等核心内容以拼接出技术发展趋势;S. Y. Yang等[8]从工艺流程角度分析技术的发展变化,将机械领域实体类型划分为方法、步骤、方式、属性、实体、值,将实体之间关系划分为动作、包含、前置,实体和关系可进一步细分为实际类型(real)、辅助类型(auxiliary)、领域依赖(dependent)、领域无关(independent)等;S. Choi等[9]侧重实体的句法特征和保存状态,将实体分为概念、主语概念、宾语概念、事实类型、部分事实类型、效果事实类型、概念状态、固体、气体、液体、场等。②根据所在领域的技术特点划分,比如薛驰等[10]将机械领域的可标记物划分为技术系统、流、属性,技术系统分为系统、零部件,流分为物流、能量流、信息流,属性分为性状、位置、方向等;I. Bergmann等[11]针对化学生物专利提出一套包含疾病、蛋白质靶向、行为模式(mode of action, MOA)、公式等12种类型的可标记物划分标准。
2.2 专利实体抽取方法的发展
专利领域的实体抽取方法研究以应用为导向,除了考量方法本身的效率、效果、可解释性、可移植性等,方法执行所需的支撑资源(如句法解析器、领域词表、标注数据集等)和方法的处理对象(专利数据)的特点也在考虑范围之内。由于专利的领域特定特点,即不同技术领域专利的语言特点和描述对象差别较大、标注数据集难以作为训练集跨领域使用,以及标注数据集规模有限、领域覆盖面严重不足等问题,专利实体通常在句法解析工具对专利文本进行句法解析和词性标注的基础上,使用规则匹配加以识别。当然,随着深度学习技术的崛起和成熟,这些方法逐渐被用于进行领域适配或任务适配并应用于专利实体抽取工作中,现已成为重要的研究方向。
(1)基于规则的方法。长期以来,专利实体抽取是在使用句法解析工具、词表资源等对专利文本处理后,采用人工规则筛选出其中的实体信息。这一流程共有技术信息获取、技术信息规范化和技术信息分类3个步骤,具体为:①技术信息获取即从专利文本中初步识别实体边界,具体方法以句法解析工具和规则匹配为主,即使用句法解析工具完成对专利文本的句法解析、词性识别和语义角色标注,进而结合人工规则来获取文本中的实体和语义关系[12-16];②技术信息规范化就是将具有相同、相近含义的技术信息用一种统一的形式表示出来,以消除上一步所获技术信息的不确定性,目前技术信息标准化主要借助领域词典[17]或知识库[18]等信息资源中的层次结构和关系结构来计算两个实体的语义相似度[19],或者将某实体泛化为其上位实体来判断两个实体是否属于同一实体,并进一步推断与之相关的实体组合是否具有相同含义[18,20];③经过上述处理后的实体仍然存在信息粒度不一的问题,即便经过规范化处理后仍然不宜分析解读,因而需要将其进一步分门别类,常见的分类方法包括借助自定义规则,如词汇组合[18]或词性组合[21]将实体划分到对应类别上。
(2)深度学习方法。与自然语言处理领域庞大的实体抽取方法家族不同,专利实体抽取所使用的深度学习方法集中于历经验证的少数经典方法,如BiLSTM(Bidirectional Long Short-Term Memory,双向长短期记忆网络)[22]、BiLSTM-CRF(Bidirectional Long Short-Term Memory-Conditional Random Field,双向长短期记忆网络—条件随机场)[3]、BiLSTM-CNN-CRF(Bidirectional Long Short-Term Memory-Convolutional Neural Networks- Conditional Random Field,双向长短期记忆网络—卷积神经网络—条件随机场)[23]等。在这些方法中专利实体抽取均被作为序列标引问题加以建模,研究者重点探索能够提升专利领域实体识别的特征,并将这些特征集成到深度学习模型之中,L. Chen等[3]发现相比基于新闻、百科等通用语料训练的静态词嵌入向量,基于全领域专利语料训练的静态词嵌入向量并未提升专利实体抽取效果,但用与实证领域相同或者临近领域的专利语料训练的静态词嵌入向量,则可以使专利实体抽取获得0.3%的提升(以加权平均F1值测度);Z. Zhai等[23]发现该结论在化学领域专利上同样成立,相应的提升幅度在0.61%—1.68%之间,不仅如此,还发现针对领域语料优化后的分词器更能适应目标领域专利文本的分词特点,将其集成进来同样可以提升专利实体的识别效果。
但词汇本身具有一词多义现象,且其含义也会随着上下文语境不同而有所差别,静态词嵌入向量将词汇映射到某个固定向量的做法并不符合这一词汇特点,而BERT(Bidirectional Encoder Representations from Transformers,双向基于变形器网络的编码器表示)、GPT(Generative Pre-Training,生成式预训练网络)、ELMo(Embeddings from Language Models,基于语言模型的词嵌入网络)等所产生的动态词嵌入向量则可以捕捉到同一词汇在不同语境的差异,因此具有更加强大的实体抽取能力。Z. Zhai等[23]发现,当将基于CNN(Convolutional Neural Networks,卷积神经网络)所获取的静态词嵌入向量替换为基于ELMo所产生的动态词嵌入向量后,专利实体抽取在BioSemantics[24]和Reaxys Gold[25]上分别取得了1.3%和4.8%的提升(以微平均F1值测度)。邢晓昭等[26]以类脑智能领域专利为例,通过消融实验发现当将基于通用语料训练的BERT与BiLSTM-CRF模型拼接后,专利实体抽取效果从72%急剧提升至78%(以加权平均F1值测度),而将上述BERT替换为使用专利语料的BERT-for-Patents后,这一效果上升到80%。
虽然利用深度学习技术开展专利实体抽取的研究日渐增多,但这种技术需要高质量标注数据集来保障其强大的实体识别能力[27-28],而标注高质量数据集需要耗费大量时间和人力,成本高昂,同时不同技术领域的实体类型也互不相同,这使得高质量标注数据集难以跨领域共用。针对这些困难,学者们尝试各种方法,以期在减少标注数据的条件下开展专利实体抽取。例如,白如江等[29]利用提示模板将专利实体识别任务包装为问题,通过向大语言模型ChatGPT提问以实现基于小样本标注数据的专利实体抽取;原之安等[30]提出一种基于预训练模型的半监督专利实体抽取方法,即让预训练模型先在小样本标注数据上识别实体,之后将识别结果中的高置信度实体合并到标注数据中以提升实体识别效果。但这些方法并未充分利用专利本身富含题录信息的优势,同时也没有使用公开数据基准进行方法评测,方法效果的可复现性和方法先进性的可验证程度上存在一定不足。
3 方法/Methodology
3.1 基本思想
笔者将专利所包含的技术分类号作为类别标签、将技术分类号在技术分类体系中的相关节点作为主题标签,以指导专利文本的主题分配进而抽取专利实体(见图1)。具体步骤如下:①利用专利语料库训练主题模型PC-LDA(Patent Classification - Latent Dirichlet Allocation,专利分类—潜在狄里克莱分配)[15],获取每个主题标签对应的主题—词汇概率分布;②当对一篇专利进行实体抽取时,首先获取这个专利的类别标签和主题标签,以CN107427363B及其IPC(International Patent Classification,国际专利分类)号码为例,其类别标签包括A61F2/18、A61F11/00、A61F11/04、H01R25/00,而主题标签A61F2/18、A61F11/00、A61F11/04、H01R25/00及其上层的A61F2、A61F11、H01R25、A61F、H01R、A61、H01、A、H;
③利用训练好的PC-LDA对这个专利执行折入查询(fold-in query),即计算这个专利中每个词汇在各个主题标签下的概率值;④对每个主题标签下的词汇按照概率降序排列;⑤按照主题标签层次分配该专利中词汇的主题,进而识别专利实体。
3.2 PC-LDA模型
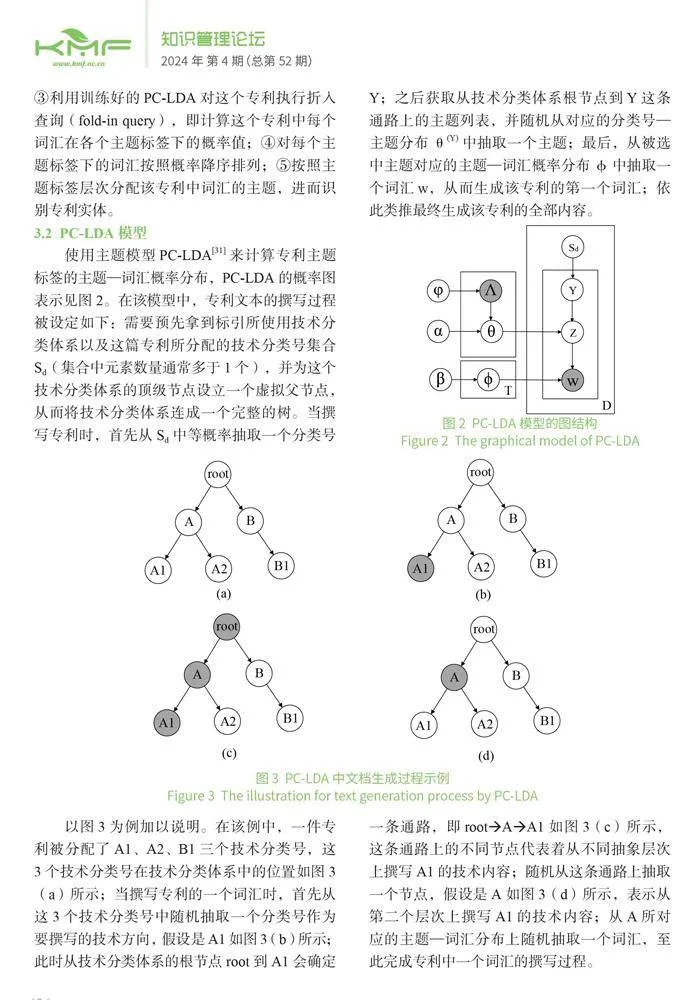
使用主题模型PC-LDA[31]来计算专利主题标签的主题—词汇概率分布,PC-LDA的概率图表示见图2。在该模型中,专利文本的撰写过程被设定如下:需要预先拿到标引所使用技术分类体系以及这篇专利所分配的技术分类号集合Sd(集合中元素数量通常多于1个),并为这个技术分类体系的顶级节点设立一个虚拟父节点,从而将技术分类体系连成一个完整的树。当撰写专利时,首先从Sd中等概率抽取一个分类号Y;之后获取从技术分类体系根节点到Y这条通路上的主题列表,并随机从对应的分类号—主题分布θ(Y)中抽取一个主题;最后,从被选中主题对应的主题—词汇概率分布φ中抽取一个词汇w,从而生成该专利的第一个词汇;依此类推最终生成该专利的全部内容。
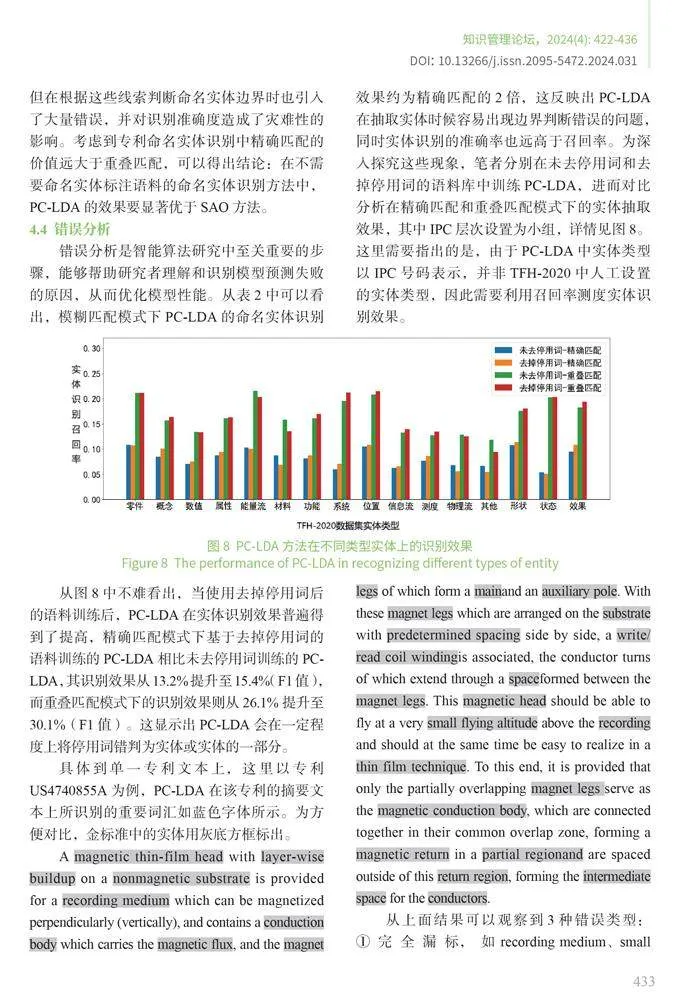
以图3为例加以说明。在该例中,一件专利被分配了A1、A2、B1三个技术分类号,这3个技术分类号在技术分类体系中的位置如图3(a)所示;当撰写专利的一个词汇时,首先从这3个技术分类号中随机抽取一个分类号作为要撰写的技术方向,假设是A1如图3(b)所示;此时从技术分类体系的根节点root到A1会确定一条通路,即rootAA1如图3(c)所示,这条通路上的不同节点代表着从不同抽象层次上撰写A1的技术内容;随机从这条通路上抽取一个节点,假设是A如图3(d)所示,表示从第二个层次上撰写A1的技术内容;从A所对应的主题—词汇分布上随机抽取一个词汇,至此完成专利中一个词汇的撰写过程。
在PC-LDA中有两类待估参数,分别是S个分类号—主题概率分布θ和T个主题—词汇概率分布φ。使用惯常的坍缩吉布斯采样方法(Collapsed Gibbs Sampling)进行参数估计,具体采样公式见公式(1)、公式(2)、公式(3),各个模型符号的含义见表1。
3.3 折入查询和词汇排序
在利用PC-LDA抽取专利中的实体时设立一个假设:专利中的实体偏向于具体内容的描述,而非对技术领域的总体概括,举例来说,实体并非“人类生活必需品”“智能技术”“运输”这种高度抽象的概括性内容,而是“裤子”“深度神经网络”“直升飞机”这种指向明确物品(无论物理物品还是虚拟物品)的实词,这些实词所对应的技术分类号标签通常处于技术分类体系的较低层次。基于该假设,当对一个新专利进行实体抽取时,需要执行两个子步骤:①获取该专利在各个主题标签上的主题分布,即折入查询;②在不同主题标签下对该专利中的词汇进行重要性排序,进而将层次较低主题标签下较为重要的词汇标识出来。由于层次越低的主题标签(或技术分类号)越具有明确、具体的技术指向,而在该技术分类号下越重要的词汇,它的技术指向就越明确、越具体,越可能是表示技术内容的实体。因此,当将技术分类体系最低层次标签下的所有重要词汇都被标识出来后,就获取了这一专利上的实体列表。
在折叠查询上,相比将新专利加入训练集重新运行主题模型的做法,笔者提出的策略更加高效:固定主题—词汇概率分布不变,只在新文档上应用坍缩吉布斯采样方法,来产生每个词汇所分配的主题和分类号。在PC-LDA中,新文档包括专利文本及其所属分类号,首先将新文档中各个词汇随机分配到其所属分类号及其相关主题上,然后利用坍缩吉布斯采样方法对这些词汇抽取其所属分类号及其相关主题,抽样公式同样是公式(1),在专利m中,主题标签z下词汇w的重要性计算方法如公式(4)所示:
其含义是获取专利m中的3类概率分布,即专利—技术标签分布、技术标签—主题标签分布、主题标签—词汇分布,进而在将主题标签和词汇设定为z和w的条件下对不同技术标签下的概率值进行累加,以消除技术标签变量s并得到t=z和w=w时的联合概率分布。
3.4 模型评价
在主题模型评价上,除了常规用于语言模型的困惑度评价指标外,鉴于本文专利实体抽取任务的特殊性,笔者采用另外一种模型评价方法,即对照实体标注数据的评价方法。
(1)困惑度(perplexity)评价方法。困惑度是评价语言模型泛化能力的标准指标,其通用公式为(5),困惑度越小的模型泛化能力越强[32]。具体到PC-LDA模型中,对测试集中文档Dtest的困惑度计算公式为(6)。其中G是坍缩吉布斯采样方法的重复执行次数,通过多次执行坍缩吉布斯采样方法然后求平均,以使困惑度结果相对稳定;|Dtest|是测试集的文档数量;|Sm|是测试文档m所包含的技术分类号数量;θijg是在第g次折叠查询时所推导出在技术分类号i上主题j的概率值。
(2)对照实体标注的评价方法。随着可公开获取的专利文本标注数据集的日益增多,以专利实体标注作为金标准的评价方法成为可能。本文提供两种匹配策略:①精确匹配,只有标注实体和主题词完全一致时,才被认为是一次正确识别;②重叠匹配,只要标注实体和主题词存在重叠词汇,就被认为是一次正确识别。为清楚起见,以图4中的句子为例加以说明,该句子包含3个实体,即inductive head、leading write pole、and trailing write pole. 根据精确匹配策略,只有inductive head被正确识别, 但当标准换成重叠匹配时,3个实体均被认为被正确识别出来。
金标准 The inductive head includes a leading write pole and a trailing write pole
主题词 The inductive head includes a leading write pole and atrailing write pole
4 实证分析/Experiment and result analysis
4.1 实验数据准备
为验证笔者提出的专利实体抽取方法的效果,本研究基于硬盘磁头领域的专利标注数据集TFH-2020[3]展开实证分析,该数据集由美国专利商标局的1 010篇专利摘要经过人工精心标注而成。但由于该数据集中仅包含1 010篇专利摘要,数量偏少,又从美国专利商标局检索平台上另外检索得到硬盘磁头相关专利10 000件,将其中信息缺失、内容重复专利去除后,得到有效专利8 648件,将其作为训练集,TFH-2020作为测试集,形成最终包含9 658条记录的英文专利数据集TFH-2020-extention。
在TFH-2020-extention中,用于标注的IPC号码共8 781个,上钻到大组、小类、大类、部层级后,分别包含IPC号码2 360个、488个、129个和8个。以图3为例加以说明,在该例中专利被分配了A1、A2、B1三个原始分类号,当将其上钻到第二层级时该专利的分类号是A、B,继续上钻后分类号归并为root。从中看到不同IPC号码上的专利分布严重不均衡,以部层级为例,A-H中包含的专利数量分别为585个、2 092个、1 062个、79个、79个、273个、3 311个;下探到大类、小类、大组、小组后的专利分布情况如图5(a)-(d)所示,其中横轴是包含同一IPC号的专利数量,纵轴是具有相同专利数量的IPC号的数量。举例来说,假设4个专利包含的IPC号分别是(A,B,C)、(B,C、D)、(A,C、D)、(D),那么包含A、B、C、D的专利数量就对应着横轴坐标上的2、2、3、3,而具有相同专利数量2的IPC号的数量为2,具有相同专利数量3的IPC号的数量也为2,它们对应着纵轴上的相应坐标。从图中可以看到,在这4个层次上大多数IPC只存在于5件专利以内,存在于1 000件专利以上的IPC数量在10以下。
4.2 模型设置
为探索各个主题模型在不同IPC层级上的效果,除了使用原始IPC标签,笔者同时将IPC标签上钻到大组、小类级别,形成了IPC大组标签和IPC小类标签,以在不同层次分类号的处理策略下分别展开实证分析。在模型超参数设置上,按照惯例将α、β分别设置为0.5和0.1,迭代轮次设置为100。由于对照实体标注的评价方法需要将主题标签分配到原始文本的每个词汇,以识别命名实体并与金标准进行比对,所以文本预处理仅去除标点符号,不再执行删除停用词、低频词、抽词干等常规操作。
4.3 模型评价
4.3.1 困惑度评价
在不同层次技术分类号的处理策略下,PC-LDA模型的困惑度变化曲线见图6。可见随着IPC上钻层次的提升,困惑度在不断增长。IPC上钻层次越高,专利中所包含的IPC号码就越少,而困惑度通常会随主题数量的减少而增长,反映到单一主题上来说,就是随着IPC上钻层次的提升,主题的指向愈发抽象、模糊,内容逐渐混杂。
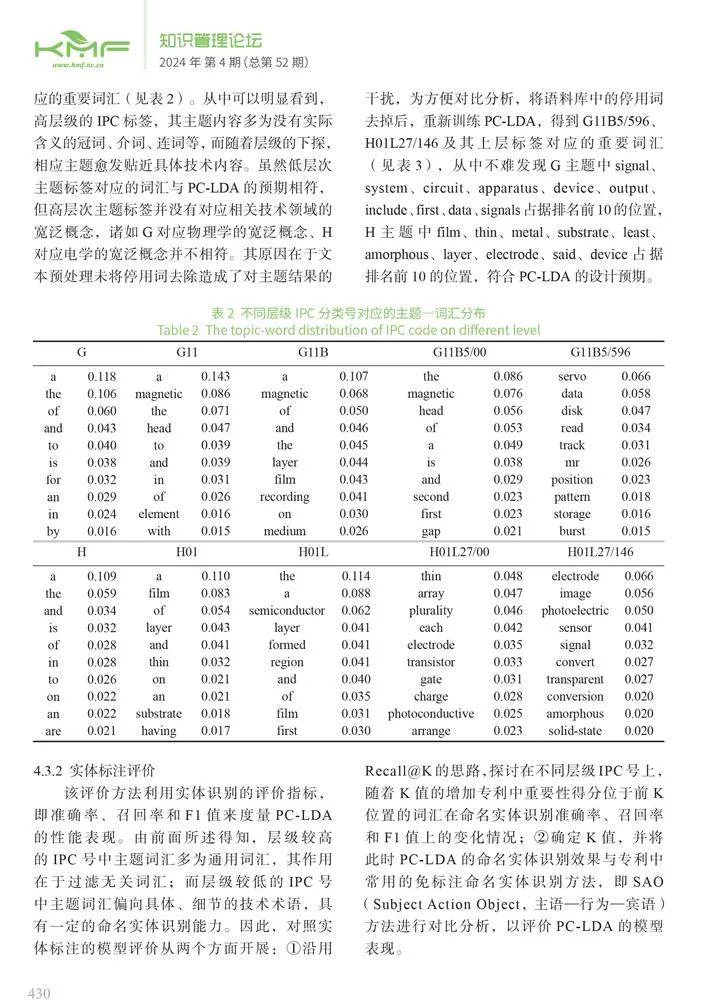
为进一步探索PC-LDA的主题抽取效果,随机选出两个技术标签G11B5/596、H01L27/146及其上层标签,并输出这些标签对应的重要词汇(见表2)。从中可以明显看到,高层级的IPC标签,其主题内容多为没有实际含义的冠词、介词、连词等,而随着层级的下探,相应主题愈发贴近具体技术内容。虽然低层次主题标签对应的词汇与PC-LDA的预期相符,但高层次主题标签并没有对应相关技术领域的宽泛概念,诸如G对应物理学的宽泛概念、H对应电学的宽泛概念并不相符。其原因在于文本预处理未将停用词去除造成了对主题结果的干扰,为方便对比分析,将语料库中的停用词去掉后,重新训练PC-LDA,得到G11B5/596、H01L27/146及其上层标签对应的重要词汇(见表3),从中不难发现G主题中signal、system、circuit、apparatus、device、output、include、first、data、signals占据排名前10的位置,H主题中film、thin、metal、substrate、least、amorphous、layer、electrode、said、device占据排名前10的位置,符合PC-LDA的设计预期。
4.3.2 实体标注评价
该评价方法利用实体识别的评价指标,即准确率、召回率和F1值来度量PC-LDA的性能表现。由前面所述得知,层级较高的IPC号中主题词汇多为通用词汇,其作用在于过滤无关词汇;而层级较低的IPC号中主题词汇偏向具体、细节的技术术语,具有一定的命名实体识别能力。因此,对照实体标注的模型评价从两个方面开展:①沿用Recall@K的思路,探讨在不同层级IPC号上,随着K值的增加专利中重要性得分位于前K位置的词汇在命名实体识别准确率、召回率和F1值上的变化情况;②确定K值,并将此时PC-LDA的命名实体识别效果与专利中常用的免标注命名实体识别方法,即SAO(Subject Action Object,主语—行为—宾语)方法进行对比分析,以评价PC-LDA的模型表现。
(1)不同层级IPC号的命名实体识别。由于部、大类层级较高,所抽主题中无实际含义的词汇较多,笔者将分析目标限定在层级较低的小类、大组、小组上(见图7)。其中,精确匹配策略下命名实体识别的准确率、召回率和F1值随K值变化情况见图7(a)-(c),重叠匹配策略下的对应情况见图7(d)-(f)。从中可见,无论是精确匹配策略还是重叠匹配策略,小类、大组层级的命名实体识别效果均相差细微,不仅如此,它们随K值的变化情况也高度一致;与此相对,小类层级的命名实体识别效果要明显优于前两者。从匹配策略上来说,不同匹配策略下命名实体识别效果的差别不大,以小组层级为例,它在精确匹配下的最优召回率和F1值分别为9.73%和13.2%,而在重叠匹配下的最优召回率和F1值分别为19.2%和26.1%,约为前者的2倍。由于小组准确率在重叠匹配策略和精确匹配下变化趋势不同,所以这里不做比较。
(2)PC-LDA与SAO的对比分析。选定K=100来获取PC-LDA模型在命名实体识别上固定的准确率、召回率和F1值,以开展对比分析。之所以选择K为100,是因为当取该值时除重叠匹配策略下的准确率外,PC-LDA在其他命名实体识别指标的得分均为最优值。同时,笔者也用基线方法(SAO方法)对测试集进行命名实体识别,这些实验结果汇总见表4。从中可见,与PC-LDA模型完全不同,SAO方法在不同匹配策略下的命名实体识别效果存在极大差异。在精确匹配策略下,SAO方法在3种命名实体识别指标上的得分均在4%以下;但在重叠匹配策略下,SAO方法却在准确率和F1值上取得了最高值,即74.2%和41.4%。
SAO方法的这种矛盾性表现反映了两个事实:①命名实体的组成方式灵活多样,但SAO方法仅将部分组成方式纳入考量范围,从而造成抽取结果准确率高、召回率低;②SAO方法虽然能有效识别存在于专利中的命名实体线索,
但在根据这些线索判断命名实体边界时也引入了大量错误,并对识别准确度造成了灾难性的影响。考虑到专利命名实体识别中精确匹配的价值远大于重叠匹配,可以得出结论:在不需要命名实体标注语料的命名实体识别方法中,PC-LDA的效果要显著优于SAO方法。
4.4 错误分析
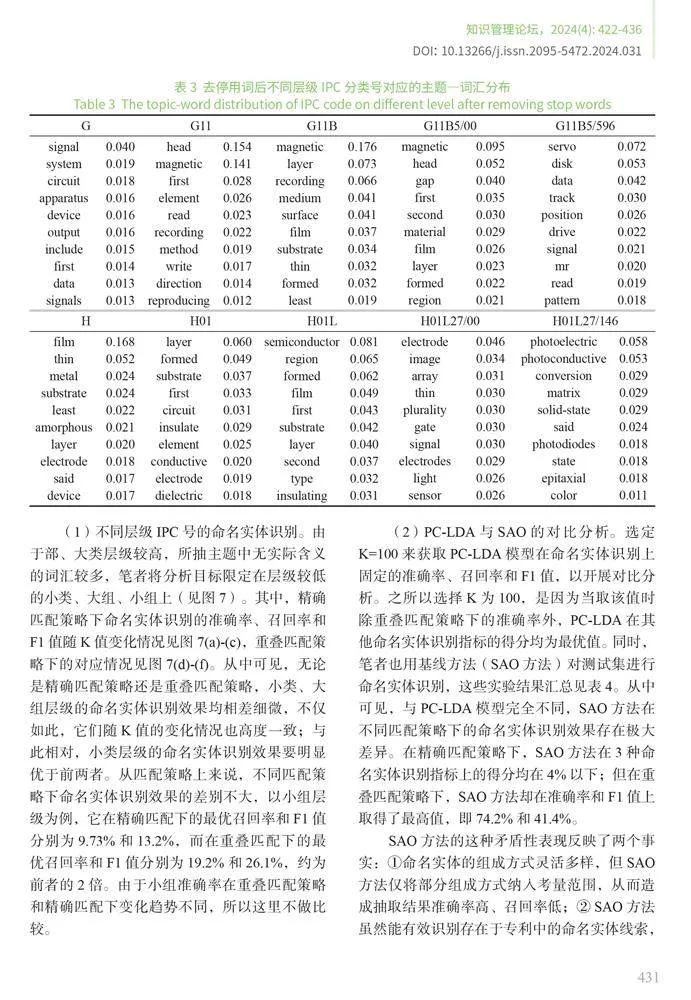
错误分析是智能算法研究中至关重要的步骤,能够帮助研究者理解和识别模型预测失败的原因,从而优化模型性能。从表2中可以看出,模糊匹配模式下PC-LDA的命名实体识别效果约为精确匹配的2倍,这反映出PC-LDA在抽取实体时候容易出现边界判断错误的问题,同时实体识别的准确率也远高于召回率。为深入探究这些现象,笔者分别在未去停用词和去掉停用词的语料库中训练PC-LDA,进而对比分析在精确匹配和重叠匹配模式下的实体抽取效果,其中IPC层次设置为小组,详情见图8。这里需要指出的是,由于PC-LDA中实体类型以IPC号码表示,并非TFH-2020中人工设置的实体类型,因此需要利用召回率测度实体识别效果。
从图8中不难看出,当使用去掉停用词后的语料训练后,PC-LDA在实体识别效果普遍得到了提高,精确匹配模式下基于去掉停用词的语料训练的PC-LDA相比未去停用词训练的PC-LDA,其识别效果从13.2%提升至15.4%(F1值),而重叠匹配模式下的识别效果则从26.1%提升至30.1%(F1值)。这显示出PC-LDA会在一定程度上将停用词错判为实体或实体的一部分。
具体到单一专利文本上,这里以专利US4740855A为例,PC-LDA在该专利的摘要文本上所识别的重要词汇如蓝色字体所示。为方便对比,金标准中的实体用灰底方框标出。
A magnetic thin-film head with layer-wise buildup on a nonmagnetic substrate is provided for a recording medium which can be magnetized perpendicularly (vertically), and contains a conduction body which carries the magnetic flux, and the magnet legs of which form a mainand an auxiliary pole. With these magnet legs which are arranged on the substrate with predetermined spacing side by side, a write/read coil windingis associated, the conductor turns of which extend through a spaceformed between the magnet legs. This magnetic head should be able to fly at a very small flying altitude above the recording and should at the same time be easy to realize in a thin film technique. To this end, it is provided that only the partially overlapping magnet legs serve as the magnetic conduction body, which are connected together in their common overlap zone, forming a magnetic return in a partial regionand are spaced outside of this return region, forming the intermediate space for the conductors.
从上面结果可以观察到3种错误类型:①完全漏标,如recording medium、small flying altitude、conductors等。②部分漏标,如magnetic thin-film head,其中head被遗漏;nonmagnetic substrate,其中substrate被遗漏。③将非实体的形容词、副词、动词等标注出来,如main、vertically、fly、carries等。对于第前两种错误类型,其原因在于使用IPC小组(在本专利US4740855A中,即G11B5/31和G11B5/127)对应的词汇分布进行实体标注,使得标注内容更加关注技术具体细节,但实际上有些实体(如recording medium、conductor)由较为宏观、上位的词汇构成,而这些词汇存在于表1中G11B对应的词汇或者表2的G、G11、G11B对应的词汇列表中,因此在实体识别时,需要将不同层次技术分类号对应的重要词汇进行综合考量后,才能覆盖更多不同特点的实体;对于第三种错误,其原因在于主题模型本身并未考虑词汇的词性属性,但词汇在构成实体时需要遵从一定的规则,比如实体必须是名词或名词性短语,形容词、副词、动词无法独自构成实体,因此在基于PC-LDA模型进行实体抽取时,需要辅以规则方法、通过后处理将不符合实体构成要求的识别结果排除掉。
5 总结和前瞻/Conclusions and future work
对专利文本进行实体识别以反映发明创新的实质内容是技术情报分析的基础工作之一,然而在当前实体识别范式下,识别工作需要代价高昂的标注数据做支持才能获得良好的效果,而且不同技术领域的标注数据也难以跨领域共用,从而限制了专利实体识别技术的应用和推广。针对该问题,笔者利用PC-LDA主题模型抽取不同层次技术分类号所对应的主题—词汇概率分布的特点,提出一种无需实体标注信息也可以进行专利实体抽取的方法,即利用低层级技术分类号所对应的重要词汇中富含具体技术和实现细节的现象,将这些词汇提取并拼接起来以实现无标注信息的专利文本实体自动识别。
在基于公开专利数据基准TFH-2020的实证分析中,基于PC-LDA的实体识别方法展示出远优于SAO的性能;同时研究发现,低层级技术分类号所训练出的PC-LDA在困惑度上要低于高层级技术分类号,而最低层级技术分类号(即IPC的小组层级)在这方面尤为明显,基于最低技术分类号所训练出的PC-LDA在实体识别正确率上也远超其他层次技术分类号所训练的PC-LDA。这也从一个侧面反映出随着技术层级分类体系的复杂化,最低层级技术分类号提供的信息量要远大于其他层级,在这一层级上准确标注和识别出对应实体尤为重要。
不过,基于PC-LDA的无标注专利实体识别方法的识别效果还有较大提升空间,尤其在实体识别召回率上,通过错误分析发现,其原因一方面在于部分实体由较为宏观、上位的词汇构成,这些词汇并没有出现在低层级技术分类号所对应的重要词汇中,而是存在于其上位技术分类号所对应的重要词汇中,因此在实体识别时,需要将不同层次技术分类号对应的重要词汇综合考量后,才能覆盖更多不同特点的实体;另一方面,PC-LDA会将一些形容词、副词、动词和无实际含义的虚词识别为实体或实体的组成部分,因此需要使用规则或词表方法来辅助PC-LDA方法,以进一步提升方法效果,这也是下一步工作的重点方向。
参考文献/References:
[1] AKHONDI S A, KLENNER A G, TYRCHAN C, et al. Annotated chemical patent corpus: a gold standard for text mining[J]. Plos one, 2014, 9(9): 1-8.
[2] PÉREZ-PÉREZ M, PÉREZ-RODRÍGUEZ G, VAZQUEZ M, et al. Evaluation of chemical and gene/protein entity recognition systems at BioCreative V.5: the CEMP and GPRO patents tracks[EB/OL].[2024-07-22]. https://biocreative.bioinformatics.udel.edu/media/store/files/2017/BioCreative_V5_paper2.pdf.
[3] CHEN L, XU S, ZHU L, et al. A deep learning based method for extracting semantic information from patent documents[J]. Scientometrics, 2020, 125(1): 289-312.
[4] The Stanford Natural Language Processing Group. Stanford Named Entity Recognizer (NER)[EB/OL].[2024-06-08].http://nlp.stanford.edu/software/CRF-NER.shtml.
[5] 英格索尔, 莫顿, 法里斯.驾驭文本:文本的发现、组织和处理[M].王斌, 译.北京:电子工业出版社, 2015. (INGERSOLL G S, MORTON T S, FARRIS A L. Taming text: how to find, organize and manipulate it[M].Shelter Island: Manning Publications.)
[6] DEWULF S. Directed variation of properties for new or improved function product DNA: a base for connect and develop[J]. Procedia engineering, 2011(9): 646-652.
[7] PARK H, YOON J, KIM K. Identifying patent infringement using SAO based semantic technological similarities[J]. Scientometrics, 2012, 90(2): 515-529.
[8] YANG S Y, SOO V W. Extract conceptual graphs from plain texts in patent claims[J]. Engineering applications of artificial intelligence, 2012, 25(4): 874-887.
[9] CHOI S, KANG D, LIM J, et al. A fact-oriented ontological approach to SAO-based function modeling of patents for implementing function-based technology database[J]. Expert system with application, 2012, 39(10): 9129-9140.
[10] 薛驰, 邱清盈, 冯培恩, 等. 机械产品专利作用结构知识提取方法研究[J]. 农业机械学报, 2013, 44(1): 222-229. (XUE C, QIU Q Y, FENG P E, et al. Acquisition method for principle solution of mechanical patent[J]. Transactions of the Chinese Society for Agricultural Machinery, 2013, 44(1): 222-229.)
[11] BERGMANN I, BUTZKE D, WALTER L, et al. Evaluating the risk of patent infringement by means of semantic patent analysis: the case of DNA chips[J]. R&D management, 2008, 38(5): 550-562.
[12] YANG C, ZHU D, WANG X, et al. Requirement-oriented core technological components’ identification based on SAO analysis[J]. Scientometrics, 2017, 112(3): 1229-1248.
[13] MOEHRLE M G, WALTER L, GERITZ A, et al. Patent‐based inventor profiles as a basis for human resource decisions in research and development[J]. R&d management, 2005, 35(5): 513-524.
[14] GUO J, WANG X, LI Q, et al. Subject-action-object-based morphology analysis for determining the direction of technological change[J]. Technological forecasting and social change, 2016, 105:27-40.
[15] AN J, KIM K, MORTARA L, et al. Deriving technology intelligence from patents: preposition-based semantic analysis[J]. Journal of informetrics, 2018, 12(1): 217-236.
[16] 胡菊香, 吕学强, 刘秀磊, 等.专利技术功效短语获取研究[J].科学技术与工程, 2016, 16(14): 228-235.(HU J X, LV X Q, LIU X L, et al. Extracting technologies efficacy phrases of patent for research[J]. Science technology and engineering, 2016, 16(14): 228-235.)
[17]马建红, 张明月, 赵亚男.面向创新设计的专利知识抽取方法[J].计算机应用, 2016, 36(2): 465-471.(MA J H, ZHANG M Y, ZHAO Y N. Patent knowledge extraction method for innovation design[J]. Journal of computer applications , 2016, 36(2): 465-471.)
[18] YOON J, KO N, KIM J. A function-based knowledge base for technology intelligence[J].Industrial engineering & management systems, 2015, 14(1): 73-87.
[19] HOI S, PARK H, KANG D, et al. An SAO-based text mining approach to building a technology tree for technology planning[J].Expert system with application, 2012, 39(13): 11443-11455.
[20] 王琰炎, 王裴岩, 蔡东风.一种用于专利实体的实体消歧方法[J].沈阳航空航天大学学报, 2015, 32(1): 77-83.(WANG Y Y, WANG P Y, CAI D F. An entity disambiguation method for patent entity[J].Journal of Shenyang Aerospace University, 2015, 32(1): 77-83.)
[21] WANG X, QIU P, ZHU D, et al. Identification of technology development trends based on subject-action-object analysis: the case of dye-sensitized solar cells[J].Technological forecasting and social change, 2015, 98: 24-46.
[22] SAAD F. Named entity recognition for biomedical patent text using Bi-LSTM variants[C]//Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services. New York: ACM Press, 2019: 617-621.
[23] ZHAI Z, NGUYEN D Q, AKHONDI S A, et al. Improving chemical named entity recognition in patents with contextualized word embeddings[J]. arXiv preprint, 2019, arXiv:1907.02679.
[24] SABER A, ALEXANDER G K, CHRISTIAN T, et al. Annotated chemical patent corpus: a gold standard for text mining[J]. Plos one, 2014, 9(9): e107477.
[25] SABER A, HINNERK R, MARKUS S, et al. Automatic identification of relevant chemical compounds from patents[EB/OL]. [2024-06-30]. https://academic.oup.com/database/article-pdf/doi/10.1093/database/baz001/27636778/baz001.pdf.
[26] 邢晓昭, 苑朋彬, 陈亮, 等.面向技术识别的专利实体抽取研究——以类脑智能领域为例[J].情报杂志, 2024, 43(6): 126-133, 144.(XING X Z, YUAN P B, CHEN L, et al. Research on patent entity extraction for technology recognition: a case study of brain-inspired intelligence[J].Journal of intelligence, 2024, 43(6): 126-133, 144.)
[27] ZHANG H, ZHANG C, WANG Y, et al. Revealing the technology development of natural language processing: a scientific entity-centric perspective[J]. Information processing and management, 2024, 61(1): 103574.
[28] 章成志, 谢雨欣, 张恒, 等.学术文献全文内容中的方法实体细粒度抽取及演化分析研究[J].情报学报, 2023, 42(8): 952-966. (ZHANG C Z, XIE Y X, ZHANG H, et al. Extraction and evolution analysis of fine-grained method entities from full text of academic articles[J]. Journal of the China Society for Scientific and Technical Information, 2023, 42(8): 952-966.)
[29] 白如江, 陈启明, 张玉洁, 等.基于ChatGPT+Prompt的专利技术功效实体自动生成研究[J].数据分析与知识发现, 2024, 8(4): 14-25. ( BAI R J, CHEN Q M, ZHANG Y J, et al. Generating effectiveness entities of patent technology based on ChatGPT+Prompt[J]. Data analysis and knowledge discovery, 2024, 8(4): 14-25.)
[30] 原之安, 彭甫镕, 谷波, 等. 面向标注数据稀缺专利文献的科技实体抽取[J].郑州大学学报(理学版), 2021, 53(4): 61-68. (YUAN Z A, PENG F R, GU B, et al. Technology entity extraction of patent literature with limited annotated data[J]. Journal of Zhengzhou University(natural science edition), 2021, 53(4): 61-68.)
[31] 陈亮. 面向专利分析的Patent Classification LDA模型[J]. 情报学报, 2016, 35(8): 864-874. (CHEN L. Patent classification LDA: topic model for patent analysis[J]. Journal of the China Society for Scientific and Technical Information, 2016, 35(8): 864-874.)
[32] JELINEK F, MERCER R L, BAHL L R, et al. Perplexity: a measure of the difficulty of speech recognition tasks[J]. The journal of the Acoustical Society of America, 1977, 62(S1): S63-S63.
作者贡献说明/Author contributions:
陈 亮:论文构思与方法设计,文献调研,代码编写,实证分析和论文撰写;
尚玮姣:论文思路梳理,实验数据整理与分析,论文撰写;
余 池:文献调研,材料整理和论文撰写;
牟 琳:文献调研,专利数据集整理和统计,论文撰写;
夏春姊:文章审阅,提出修改意见及论文修改;
葛 川:实体抽取相关算法的调研和梳理。
Research on Unsupervised Patent Entity Extraction Method Assisted by Technology Classification Codes
Chen Liang Shang Weijiao Yu Chi Mou Lin Xia Chunzi Ge Chuan
1Institute of Scientific and Technical Information of China, Beijing 100038
2Research Institute of Forestry Policy and Information, Chinese Academy of Forestry, Beijing 100091
3Shanxi Center of Science and Technology Intelligence and Strategic Studies, Taiyuan 030032
Abstract: [Purpose/Significance] Unsupervised method of patent entity extraction is capable of addressing the issue of previous methods that are highly dependent on labeled resources, thus promoting the widespread of artificial intelligence technology in the intellectual property field and improving the ability of patent information service. [Method/Process] By combining the inherent technology classification codes of patent documents with topic modeling, this study proposed a new method that utilizes patent classification code to guide the topic allocation process in patent text, thus extracting entities without annotation dataset. [Result/Conclusion] To demonstrate the advantages of our method, the empirical analysis was conducted using a patent dataset from the field of thin-film magnetic heads in hard disk drives, along with the IPC technology classification system. The experimental results show that there is a significant difference in the performance of entity extraction for different levels of technology classifications. Moreover, the entity extraction performance based on the fifth-level IPC technology classification code is far superior to the conventional Subject-Action-Object (SAO) method.
Keywords: entity extraction topic model patent mining patent classification code
Fund project(s): This work is supported by Shanxi Province Science and Technology Cooperation and Communication Special Project titled “Research and Development of Shanxi Province Research Project Similarity Monitoring Technology Based on Big Data and its Application Demonstration” (Granted No. 202204041101034).
Author(s): Chen Liang, associate research fellow, PhD; Shang Weijiao, engineer, master; Yu Chi, master candidate; Mou Lin, senior engineer, PhD; Xia Chunzi, assistant research fellow, master; Ge Chuan, research fellow, master, corresponding author, E-mail: 10600491@qq.com.
Received: 2024-03-12 Published: 2024-08-29
