基于虚拟数据和旋转目标检测分析的大豆豆荚表型参数测量方法
2024-09-26吴康磊金秀饶元李佳佳王晓波王坦江朝晖












摘要:为解决传统大豆考种过程中人工测量大豆豆荚表型参数耗时费力的问题以及现有的自动化测量方式存在的人工数据标注需求量大、环境适应能力弱、计算代价高等问题,本研究提出一种基于虚拟数据集生成和旋转目标检测分析的豆荚关键表型参数自动化测量方法,重点关注荚长和荚宽的测量。该方法基于YOLOv7-tiny提出一种改进的豆荚检测模型(CSL-YOLOv7-tiny),通过引入环形平滑标签使模型获得对旋转目标的检测能力,提升对无序摆放的狭长豆荚目标检测的质量。为避免人工标注训练数据,采用虚拟图像生成方法得到含标注信息的虚拟豆荚数据集和虚拟硬币与豆荚混合数据集。利用迁移学习策略,将模型从虚拟豆荚数据集迁移至虚拟硬币与豆荚混合数据集,积累模型对豆荚特征的提取能力。设计一种基于K-均值聚类的后处理方法,对检测到的旋转边界框进行分析,得到荚长和荚宽,以减少拍摄环境差异带来的测量误差。试验结果表明,在无任何训练数据标注的条件下,使用虚拟图像训练的CSL-YOLOv7-tiny对硬币和豆荚目标检测的最优mAP0.50和mAP0.50∶0.95分别达到了99.3%和78.0%,其模型大小和推理时间分别仅为12.92 MB和12.5 ms,荚长和荚宽测量的决定系数(R2)分别达到了0.94和0.86,与实际测量均值分别仅相差0.42 mm和0.02 mm。此外,通过对本研究提出的方法进行对比分析,验证了其在模型训练、轻量化部署以及不同考种环境适应能力上的优势。研究结果可为大豆豆荚表型参数的自动化、智能化测量系统的研发提供参考,为加速优质高产大豆的选育进程提供支撑。
关键词:大豆考种;豆荚表型;虚拟数据;旋转目标检测;YOLOv7-tiny
中图分类号:TP391.4文献标识码:A文章编号:1000-4440(2024)07-1245-15Measurement method for soybean pod phenotypic parameters based on virtual data and rotated object detection analysisWU Kanglei1,2,JIN Xiu 1,2,RAO Yuan1,2,LI Jiajia3,WANG Xiaobo3,WANG Tan1,2,JIANG Zhaohui1,2
(1.College of Information and Artificial Intelligence, Anhui Agricultural University, Hefei 230036, China;2.Key Laboratory of Agricultural Sensors, Ministry of Agriculture and Rural Affairs, Hefei 230036, China;3.College of Agronomy, Anhui Agricultural University, Hefei 230036, China)
Abstract:To solve the problems such as time-consuming and labor-intensive of manual measurement for soybean pod phenotypic parameters in traditional soybean seed evaluation processes, as well as the large quantity demand for manual data annotation, weak environmental adaptation and high computational costs in existing automated measurement methods, an automated measurement method for pod key phenotypic parameters which was mainly focused on pod length and width measuring was proposed in this study, based on virtual dataset generation and rotated object detection analysis. An improved pod detection model (CSL-YOLOv7-tiny) was proposed by the method based on YOLOv7-tiny. The Circular Smooth Label was introduced to enable the model to obtain the capability for rotated object detection, and to improve the quality of detecting elongated pod targets in a disorganized arrangement. To avoid manual annotation of training data, virtual image generation method was used to get virtual pod dataset as well as virtual coin and pod mixture dataset containing annotation information. Transfer learning strategy was employed to transfer the model from the virtual pod dataset to the virtual coin and pod mixture dataset, which accumulated the model’s ability in pod features extracting. A post-processing method based on K-means clustering was designed to analyze the detected rotated bounding boxes, and obtained pod length and width, which reduced measurement errors caused by shooting environmental differences. Experimental results showed that under the condition of no training data annotation, CSL-YOLOv7-tiny trained by virtual images obtained the optimal mAP0.50 and mAP0.50∶0.95 for coin and pod targets detection, which were 99.3% and 78.0%, respectively. The model size and inference time were only 12.92 MB and 12.5 ms respectively, and the determination coefficients (R2) for pod length and width measurement reached 0.94 and 0.86 respectively, with only 0.42 mm and 0.02 mm differences compared with actual measurements. Furthermore, by comparative analysis of the proposed method, the advantages in model training, lightweight deployment and adaptation to different breeding environments were validated. The research results can provide reference for development of automated and intelligent measurement system of soybean pod phenotypic parameter and can support the acceleration of high-quality and high-yield soybean breeding.
Key words:soybean seed evaluation;soybean pod phenotype;virtual data;rotated object detection;YOLOv7-tiny
大豆富含植物油和蛋白质,是一种营养价值极高的农作物[1]。随着中国居民的消费结构转型升级,大豆的需求量明显增加,而受耕地资源限制,大豆的总产量增幅较小,使得大豆的进口依赖度居高不下,这对中国粮食安全构成了潜在威胁[2]。因此培育高产量高质量的新品种大豆,对提高大豆供给能力、解决资源受限问题有着重要意义。优质大豆品种的选育过程中,准确测量大豆表型并进行统计分析是其中的关键环节。传统的大豆表型性状测量以人工观察和手动统计方式为主,然而,人工统计往往存在测量误差大、效率低并且会消耗大量人力和物力等不足[3-5]。因此,实现自动化、高精度的大豆表型测量对于大豆品种精准选育具有重要意义。
随着图像处理和深度学习技术的快速发展,越来越多的研究将其应用于农业领域[6-8] ,这对自动化农业发展作出了巨大贡献。为解决大豆表型人工测量耗时费力的问题,已有许多学者投入到大豆表型性状自动化测量方法的探索中。Uzal等[9]基于CNN模型估算豆荚中的种子数量并实现对大豆豆荚的分类,分类准确率达到了86.20%。闫壮壮等[10]基于搭配Adam优化算法的Vgg16模型实现了对大豆豆荚类别的精准识别,准确率高达98.41%。郭瑞等[11]通过融合K-均值聚类算法与改进的注意力机制模块对YOLOv4目标检测算法进行改进,并用于不同场景下的大豆单株豆荚数的检测。宁姗等[12]基于改进的单步多框检测(SSD)网络和蚁群优化算法提取出完整的大豆植株茎秆和豆荚目标,获得了整株荚数、株高、有效分枝数等表型信息。王跃亭等[13]通过植株分割、骨架提取、主茎节点去噪等操作和HDBSCAN聚类算法对大豆主茎节数进行逐级筛选统计,实现了大豆主茎节数的快速获取。
豆荚表型是大豆表型性状的重要组成部分,其中荚长、荚宽、荚粒数和荚皮色等是关键的豆荚表型参数,与全株荚数、主茎节点数等表型的测量相比,测量荚长和荚宽等表型更为耗时费力。目前,荚长和荚宽的自动化测量方法主要分为3种:第1种为传统图像处理方法,如张小斌等[14]提出的基于计算机图像处理技术的菜用大豆豆荚表型信息采集分析方法,传统图像处理技术可以避免标注数据并拥有较高的检测速度,但其泛化能力和鲁棒性较差[15-16],测量精度易受环境影响;第2种方法为单阶段目标检测方法,如翔云等[17]将基于YOLOv5和图像处理的智能数据采集技术应用于菜用大豆荚型表型的识别,以Yolo系列[18]为代表的单阶段目标检测模型具有较低的计算代价[19],易于部署到实际应用场景中,但在豆荚分布较为集中时基于水平边界框计算荚长与荚宽的方法存在较大的误差;第3种方法为实例分割方法,如Li等[20]基于特征金字塔、主成分分析和实例分割构建了大豆表型测量实例分割(SPM-IS)模型,用于荚长和荚宽等豆荚表型测量,该类方法可得到较高的检测精度,但检测速度较慢且模型体积较大,不利于轻量化部署。总之,上述3种方法尚存在环境适应能力弱、测量误差大、计算代价高等问题。
为满足深度学习模型训练对高质量标注数据的需求,学者们开始尝试设计虚拟图像生成方法以减少人工数据采集与标注[21-23],并以此降低模型训练成本。在训练豆荚检测模型或分割模型时,由于豆荚展现出的狭小形状以及丰富多样的特征,导致豆荚图像数据标注难度高且数量需求大。Yang等[24]通过使用Photoshop从图像中手动提取出单个豆荚,再利用这些豆荚生成虚拟图像,并将其用于实例分割模型的训练以得到豆荚分割模型,该研究验证了生成虚拟图像用于豆荚分割模型训练的可行性,但其虚拟豆荚图像生成过程未实现完全自动化,仍面临人工提取单个豆荚过程的费时问题。因此,设计一种全自动化的虚拟豆荚图像生成算法以生成具有丰富特征的豆荚图像数据集,对于进一步降低人工数据标注代价具有重要意义。
综上所述,为解决当前自动化测量方法面临的人工数据标注依赖性强、精度易受环境变化影响、轻量化程度低等问题,本研究提出一种自动化测量大豆豆荚关键表型参数的方法。为克服深度学习检测模型对大量标注数据的需求,通过从真实图像中自动提取豆荚或硬币图像,与背景结合实现虚拟数据集及相应标注数据的全自动生成。为提高对豆荚的检测性能,利用从虚拟豆荚数据集到虚拟硬币与豆荚混合数据集的迁移学习过程,提升模型对豆荚目标的特征提取能力。引入环形平滑标签改进YOLOv7-tiny模型以实现对无序摆放的狭长豆荚目标的旋转框检测,通过基于K-均值聚类的后处理方法分析硬币和豆荚目标的旋转边界框信息以获得荚长、荚宽。
1材料与方法
1.1数据采集
本研究所需大豆来自安徽农业大学位于宿州埇桥区的皖北综合试验站。图1展示了采集的部分豆荚图像、硬币图像以及硬币与豆荚混合图像。数据采集时,首先使用剪刀将豆荚从植株上剪下,随机摆放在黑色吸光布上。数据采集设备采用佳能6D Mark Ⅱ型相机和Redmi K60手机,相机用于拍摄高质量图像,手机用于拍摄更贴近实际考种应用场景的图像。
如表1所示,数据采集分为4个部分:第1部分为豆荚图像采集,为了得到高质量的豆荚特征,使用佳能6D Mark Ⅱ型相机拍摄获得360张豆荚图像,其中200张图像用于生成虚拟图像,160张图像用于制作测试集;第2部分为硬币图像采集,该部分图像使用Redmi K60手机进行拍摄,最终获得100张硬币图像,用于生成虚拟图像;第3部分为硬币与豆荚混合图像采集,使用Redmi K60手机拍摄获得45张图像,用于制作测试集;第4部分为用于生成数据集的背景图像采集,该部分采用相机和手机各拍摄1张黑色吸光布图像,用于生成虚拟图像。
1.2虚拟数据集生成
本研究提出的全过程自动化生成虚拟图像的方法如图2所示,该方法包括单个豆荚图像提取、单个硬币图像提取和虚拟图像生成2个阶段。
1.2.1单个豆荚和硬币图像的提取在单个豆荚图像、硬币图像提取阶段,先读取1张硬币或豆荚图像,随后对图像进行轮廓点检测,得到若干硬币或豆荚目标的轮廓点信息,通过执行图像与运算的操作来确定1组轮廓点包围的目标区域,然后对目标区域进行裁剪得到单个硬币或豆荚图像,接着判断是否提取了1张硬币图像或豆荚图像中的全部目标,若否,则确定下一组轮廓点包围的目标区域,若是,则完成对1张硬币图像或豆荚图像中单个硬币图像或豆荚图像的提取。
1.2.2虚拟图像生成在虚拟图像生成阶段,分为虚拟豆荚图像生成过程和虚拟硬币与豆荚混合图像生成过程。为生成虚拟硬币与豆荚混合图像,首先读取单个硬币图像,对图像进行随机旋转后,随机移动硬币目标区域(硬币目标区域为对旋转后的硬币图像进行轮廓点检测得到的硬币轮廓点所包围的区域)的像素至背景图上,在完成全部硬币目标的移动后再读取单个豆荚图像,然后随机旋转单个豆荚图像并随机移动豆荚目标区域(豆荚目标区域为对旋转后的豆荚图像进行轮廓点检测得到的豆荚轮廓点所包围的区域)的像素至背景图上,直到完成全部豆荚目标的移动,得到虚拟硬币与豆荚混合图像,最终依据各个硬币和豆荚轮廓点的最小外接矩形坐标信息生成相应的标注文件。虚拟豆荚图像生成过程和虚拟硬币与豆荚混合图像生成过程类似,但为生成仅含豆荚的虚拟图像,该部分未进行硬币目标的移动,仅通过移动豆荚目标像素来得到虚拟豆荚图像与相应的标注文件。
图3展示了生成的虚拟豆荚图像和虚拟硬币与豆荚混合图像。在虚拟豆荚图像中,豆荚之间存在重叠,而在虚拟硬币与豆荚混合图像中硬币和豆荚之间并未重叠。原因在于:虚拟豆荚图像数据集仅作为迁移学习的源域来初步积累模型对豆荚特征的提取能力,因此对豆荚之间是否存在重叠不作要求,而在最终的豆荚和硬币检测模型训练过程中需提取更完整的豆荚和硬币特征,故在虚拟硬币与豆荚混合图像生成过程中,移动目标区域像素时需判断其是否与其他目标的最小外接矩形区域存在重叠。
1.2.3数据处理本研究采用生成的虚拟图像数据集训练模型。如表2所示,虚拟图像数据集分为2类,分别对应迁移学习的源域与目标域。具体而言,一种为虚拟豆荚图像数据集,该数据集仅包含豆荚图像,用于源域的检测模型训练,以积累模型对豆荚特征的提取能力;另一种为虚拟硬币与豆荚混合图像数据集,该数据集包含硬币和豆荚2个目标的图像,用于目标域检测模型的训练,以得到最终的检测模型。为满足试验的需要,本研究通过虚拟数据生成算法分别生成了400张、600张、800张和1 000张图像,用于制作虚拟豆荚图像数据集和虚拟硬币与豆荚混合图像数据集中的训练集和验证集,2种虚拟数据集中训练集和验证集所含图像数量的比例均为8∶2。此外,160张用相机拍摄的豆荚图像用于测试通过虚拟豆荚图像数据集训练得到的模型检测豆荚目标的性能,40张用手机拍摄的硬币与豆荚混合图像用于测试通过虚拟硬币与豆荚混合图像数据集训练得到的模型检测硬币与豆荚目标的性能,剩余5张用手机拍摄的硬币与豆荚混合图像用于测试模型实际考种环境下测量荚长和荚宽的性能。
1.3基于旋转目标检测的CSL-YOLOv7-tiny模型构建YOLOv7[25]作为当前主流的目标检测模型之一,被广泛地应用于各个领域。模型采用了包括增强高效层聚合网络(E-ELAN)、复合模型缩放等新方法,同时引入多头框架和辅助头部进行深度监督,通过软标签训练,实现更有效的学习。为了便于轻量化部署,YOLOv7衍生出了轻量化版本——YOLOv7-tiny,其具有更低的模型参数量和计算复杂度,更易于部署到边缘设备中。为缓解目前豆荚表型参数测量方法存在的计算代价高的问题,本研究采用YOLOv7-tiny模型作为豆荚识别基础模型进行改进。
尽管角度回归在旋转目标检测中表现出色,但普遍存在边界不连续的问题,这导致模型在角度边界处损失值急剧增加,主要是由于角度预测结果超出了定义的范围[26]。为了应对这一问题,Yang等[26]设计出环形平滑标签(CSL),将角度回归问题转变为分类问题,将角度划分为0°到179°之间的180个角度标签类别。
如图4所示,为更有效地检测形状弯曲且狭窄的豆荚目标,本研究采用环形平滑标签改进YOLOv7-tiny模型,使其获得旋转检测目标的能力,以更好地适应豆荚的形状特征并为荚长和荚宽的测量奠定基础。具体地,环形平滑标签被用于在训练前预处理数据集中的角度标签,将角度映射为180个值作为输入网络的角度标签,并在计算损失函数时使用二值交叉熵损失计算角度损失。环形平滑标签(CSL)的表达式如公式(1)所示:
1.4荚长与荚宽自动化测量方法
本研究在得到模型的检测结果后,通过一系列后处理操作实现豆荚荚长与荚宽的准确测量。其中,先对检测得到的硬币目标旋转边界框进行分析来得到检测图中单位像素对应的毫米值,再对豆荚目标旋转边界框进行分析得到最终的荚长和荚宽表型参数值。
1.4.1单位像素对应毫米值的计算取硬币目标旋转边界框的长度和宽度之和的平均值,再用硬币真实直径除以计算得到的长宽均值作为单位像素对应的毫米值,计算方法如公式(3)所示:
1.4.2荚长与荚宽的计算为更精准高效地测量荚长和荚宽,本研究提出了1种基于K-均值聚类的荚长和荚宽测量方法。采用该方法测量1个目标豆荚荚长和荚宽的过程如图5所示,首先灰度化完成检测的豆荚图像并生成目标豆荚边界框区域掩码,通过掩码与灰度图的运算提取目标豆荚区域,然后裁剪目标豆荚区域,以目标豆荚边界框的短边为底旋转整个区域;将区域内的每一像素点与其所在的列索引进行组合,形成以列索引为横坐标、像素值为纵坐标的一系列二维坐标数据。使用K-均值聚类算法对二维坐标数据样本进行聚类,簇的数目设为2,迭代次数设为10。聚类结束后得到2类数据,对2类数据中的像素值分别进行求和,以像素值求和结果较大的类别对应的像素点作为前景,即属于豆荚的像素,结果较小的类别对应的像素点作为背景,形成1幅二值图像。
荚宽的计算:对K-均值聚类后形成的二值图像进行距离变换,计算豆荚区域每一像素点到背景像素点的最短距离,以距离变换中最短距离最大的像素点作为圆心,以该像素点与背景像素点的最短距离作为半径得到豆荚区域内的最大圆,将该圆的直径与单位像素对应的毫米值相乘得到目标豆荚的真实荚宽,计算过程如公式(4)和公式(5)所示:
荚长的计算:移除K-均值聚类后形成的二值图像中行向量全为背景像素的行,将处理后的二值图像的长度与单位像素对应的毫米值相乘,得到目标豆荚的真实荚长。
2.1试验环境配置与网络参数设置
本研究模型训练和测试环境为Centos7.9 64位操作系统,服务器配置为Intel Xeon Gold 5118(2.30 GHz)12核CPU(中央处理器),NVIDIA RTX2080Ti GPU(图形处理器),显存11 GB,深度学习框架PyTorch1.10,开发语言Python 3.7,并行计算框架CUDA 11.2和加速库cuDNN7.6.5。本研究所有模型对比试验均在该硬件配置条件下进行。模型训练轮数设置为300轮,学习率设置为0.01,批大小设置为16。
2.2评价标准
本研究采用平均检测精度(AP)、平均检测精度均值(mAP)、模型大小和模型推理速度作为检测模型的评价指标,采用决定系数(R2)、平均绝对误差(MAE)和均方根误差(RMSE)作为豆荚表型参数自动化测量方法的评价指标。
2.3虚拟豆荚数据集有效性分析
为了验证生成的虚拟豆荚数据集的有效性,并探究YOLOv7-tiny模型的优势和CSL-YOLOv7-tiny模型的性能,本研究对比分析了两阶段的Faster R-CNN[27]模型和一阶段的YOLOv5n、YOLOv7-tiny与CSL-YOLOv7-tiny模型分别在400张、600张、800张和1 000张虚拟豆荚图像组成的数据集下训练后的性能(表3)。值得注意的是,训练模型使用的训练集和验证集由虚拟豆荚图像组成,而为了测试模型在真实场景下的检测精度,测试集由真实拍摄的图像构成。此外,模型大小和推理时间为各个模型在1 000张虚拟豆荚图像组成的数据集下训练得到的结果。
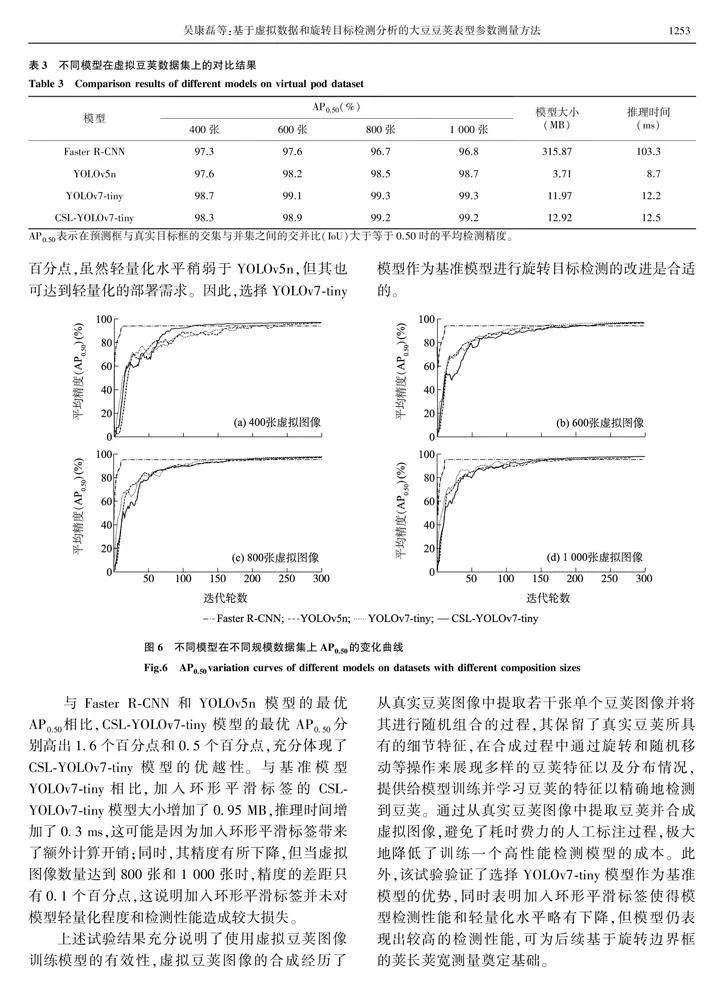
从表3可以看出,使用虚拟豆荚图像训练的各个模型均取得了较高的检测精度,且模型的精度随虚拟豆荚数据集规模的增大而逐渐增加并趋于稳定。如图6所示,随着迭代轮数的增加,各个模型在400张、600张、800张和1 000张虚拟图像组成的数据集下训练取得的AP0.50也逐渐增加,并最终呈现收敛的情况,未出现过拟合或者欠拟合的情况。因此,虚拟豆荚数据集可以有效地用于模型的训练,避免了训练模型前耗时费力的数据标注工作。
在400张、600张、800张和1 000张虚拟豆荚图像组成的数据集下,与Faster R-CNN模型相比,YOLOv7-tiny的AP0.50分别高出了1.4个百分点、1.5个百分点、2.6个百分点和2.5个百分点,且拥有更轻量化的模型结构以及更快的推理时间;与YOLOv5n相比,YOLOv7-tiny的AP0.50分别高出了1.1个百分点、0.9个百分点、0.8个百分点和0.6个百分点,虽然轻量化水平稍弱于YOLOv5n,但其也可达到轻量化的部署需求。因此,选择YOLOv7-tiny模型作为基准模型进行旋转目标检测的改进是合适的。
与Faster R-CNN和YOLOv5n 模型的最优AP0.50相比,CSL-YOLOv7-tiny模型的最优AP0.50分别高出1.6个百分点和0.5个百分点,充分体现了CSL-YOLOv7-tiny模型的优越性。与基准模型YOLOv7-tiny相比,加入环形平滑标签的CSL-YOLOv7-tiny模型大小增加了0.95 MB,推理时间增加了0.3 ms,这可能是因为加入环形平滑标签带来了额外计算开销;同时,其精度有所下降,但当虚拟图像数量达到800张和1 000张时,精度的差距只有0.1个百分点,这说明加入环形平滑标签并未对模型轻量化程度和检测性能造成较大损失。
上述试验结果充分说明了使用虚拟豆荚图像训练模型的有效性,虚拟豆荚图像的合成经历了从真实豆荚图像中提取若干张单个豆荚图像并将其进行随机组合的过程,其保留了真实豆荚所具有的细节特征,在合成过程中通过旋转和随机移动等操作来展现多样的豆荚特征以及分布情况,提供给模型训练并学习豆荚的特征以精确地检测到豆荚。通过从真实豆荚图像中提取豆荚并合成虚拟图像,避免了耗时费力的人工标注过程,极大地降低了训练一个高性能检测模型的成本。此外,该试验验证了选择YOLOv7-tiny模型作为基准模型的优势,同时表明加入环形平滑标签使得模型检测性能和轻量化水平略有下降,但模型仍表现出较高的检测性能,可为后续基于旋转边界框的荚长荚宽测量奠定基础。2.4检测模型不同训练方法分析
为了评估迁移学习的效果,并验证虚拟硬币与豆荚混合数据集的有效性,本研究以CSL-YOLOv7-tiny模型为基础,对比了在由400张、600张、800张和1 000张虚拟硬币与豆荚混合图像组成的数据集下使用迁移学习和未使用迁移学习训练模型后的性能。由于在2.3节试验中CSL-YOLOv7-tiny模型在1 000张虚拟豆荚图像组成的数据集下训练后得到的模型性能最优,因此使用其得到的模型权重进行迁移学习。
如表4所示,使用迁移学习与未使用迁移学习训练得到的模型的mAP0.50指标相差不大,且随着虚拟图像数量的增加,其数值变化不大,这说明在不考虑检测边界框质量的情况下,通过上述2种方式在不同规模的虚拟硬币与豆荚混合数据集下训练得到的模型均能准确检测到豆荚和硬币,且检测精度稳定。而在更严格的mAP0.50∶0.95指标下,使用迁移学习和未使用迁移学习在不同规模的虚拟硬币与豆荚混合数据集下训练的结果均存在较大差异,具体来说,在400张、600张、800张和1 000张虚拟硬币与豆荚混合图像组成的数据集下训练模型,使用迁移学习比未使用迁移学习得到的mAP0.50∶0.95分别高出了2.4个百分点、5.5个百分点、2.6个百分点和1.2个百分点,这表明在进一步考虑检测到的边界框质量的情况下,采用迁移学习方法训练模型具有明显优势。
本研究中豆荚荚长和荚宽参数的测量是基于对豆荚检测边界框的进一步处理来实现的,因此有必要关注检测边界框的质量,评估模型性能时,mAP0.50和mAP0.50∶0.90均具有参考价值。本研究发现,迁移学习的应用有效提升了豆荚目标边界框的质量,充分表明其在实际考种场景中对于荚长和荚宽准确测量的潜力。
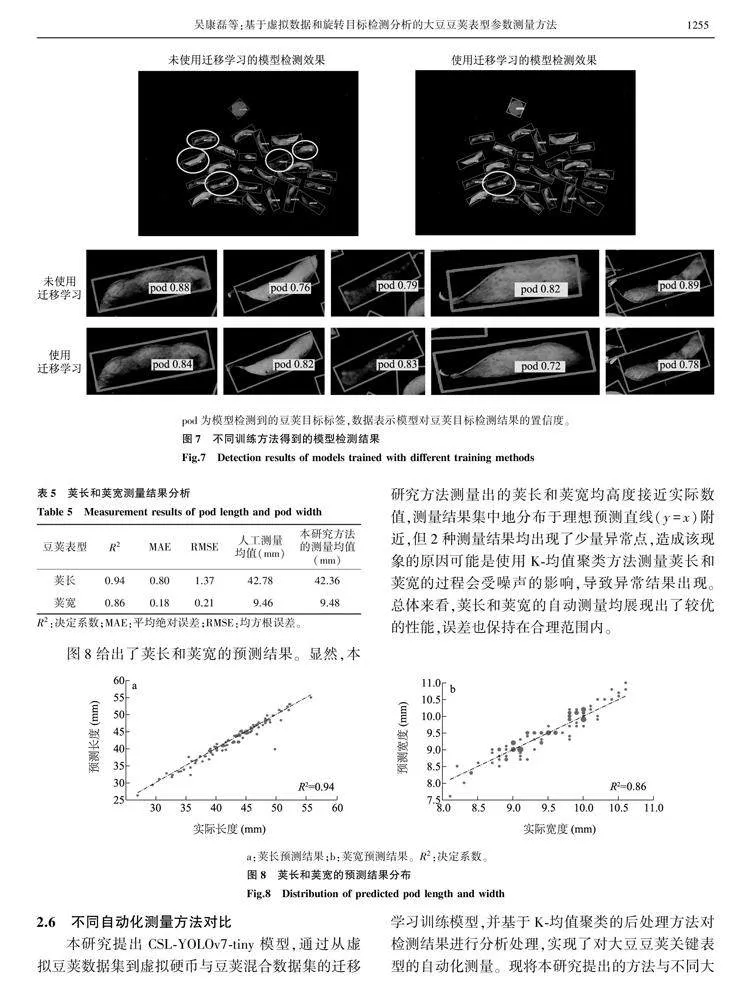
为进一步验证使用迁移学习方法训练模型的优势,图7展示了2种训练方法得到的模型检测结果。图中圆圈框出的为低质量的检测边界框,放大了未使用迁移学习的模型检测结果中的低质量检测边界框以及使用迁移学习的模型检测结果中的对应检测边界框,可以看出低质量的检测边界框无法将整个豆荚目标很好地框选出来。2种训练方法得到的模型都能够检测到所有的豆荚目标,但均存在检测边界框质量较差的情况。未使用迁移学习得到的模型出现低质量检测边界框的次数更多,比使用迁移学习得到的模型多4个。由于计算荚长与荚宽需要依赖检测边界框信息,低质量的豆荚检测边界框会造成荚长和荚宽测量误差,相较于不使用迁移学习训练模型,使用迁移学习进行模型训练可以得到更优的检测结果。
2.5豆荚长宽测量结果分析
为了进一步评估本研究提出的荚长和荚宽自动化测量方法在实际考种场景下的测量性能,本研究使用5张手机拍摄的图像进行测试,每张图像各包含20个豆荚目标,共包含100个豆荚目标。对这100个豆荚目标的荚长和荚宽进行人工测量,并与本研究提出的方法得到的测量值进行对比,采用R2、MAE和RMSE评价指标来评估该方法的测量性能。
如表5所示,在荚长测量方面,本研究提出的自动化测量方法表现出色,R2达到0.94,MAE为0.80,RMSE为1.37,显示出与实际观测值间的良好拟合度和准确性。而在荚宽预测方面,虽然R2为0.86,但MAE和RMSE都保持在相对较低的水平,分别为0.18和0.21。这表明所提出的方法对荚宽表型的预测同样具有较高的准确性。此外,荚长的人工测量均值和本研究方法的测量均值相差0.42 mm,荚宽的人工测量均值和本研究方法的测量均值相差0.02 mm,本研究方法的测量结果与人工测量结果基本一致,进一步验证了本研究所提出的测量方法的可靠性。pod为模型检测到的豆荚目标标签,数据表示模型对豆荚目标检测结果的置信度。
图8给出了荚长和荚宽的预测结果。显然,本研究方法测量出的荚长和荚宽均高度接近实际数值,测量结果集中地分布于理想预测直线(y=x)附近,但2种测量结果均出现了少量异常点,造成该现象的原因可能是使用K-均值聚类方法测量荚长和荚宽的过程会受噪声的影响,导致异常结果出现。总体来看,荚长和荚宽的自动测量均展现出了较优的性能,误差也保持在合理范围内。
2.6不同自动化测量方法对比
本研究提出CSL-YOLOv7-tiny模型,通过从虚拟豆荚数据集到虚拟硬币与豆荚混合数据集的迁移学习训练模型,并基于K-均值聚类的后处理方法对检测结果进行分析处理,实现了对大豆豆荚关键表型的自动化测量。现将本研究提出的方法与不同大豆豆荚表型的自动化测量方法进行对比,分析本研究所提出的测量方法的有效性。
2.6.1基于传统图像处理的方法图9展示了实际的典型考种环境中不同光照条件下传统图像处理方法和本研究设计的测量方法的结果对比。传统图像处理方法往往依赖于图像二值化,可以看到,在正常亮度的测试图像下二值化效果最佳,而在亮度较低的条件下二值化后会丢失大量豆荚目标像素信息,在亮度较高的条件下二值化后会造成大量的噪声。二值化往往需要设定阈值来达到预期效果,受环境影响显著,当拍摄环境发生变化时,使用传统图像处理方法来测量荚长和荚宽会造成较大的误差。本研究设计的方法采用CSL-YOLOv7-tiny旋转目标检测模型和基于K-均值聚类的后处理过程来得到荚长和荚宽,在3种典型考种环境下的测量结果未出现较大的误差,有效地避免了环境变化带来的影响,具有较强的考种环境适应能力。
2.6.2基于实例分割的方法在本研究的试验中,基于两阶段的检测模型Faster R-CNN的模型大小为315.87 MB,推理时间为103.3 ms,而CSL-YOLOv7-tiny模型大小仅有12.92 MB,推理时间为12.5 ms,与Faster R-CNN模型相比分别降低了95.9%、87.9%。此外,文献[24]采用Mask R-CNN进行豆荚图像分割,在使用相同主干网络的情况下,其模型参数量高于Faster R-CNN,实际部署应用困难。本研究设计的CSL-YOLOv7-tiny模型具有更小的体积和更短的推理时间,更易于在实际大豆考种过程中的边缘端部署应用。
2.6.3基于目标检测的方法与实例分割模型相比,目标检测模型的轻量化程度更高,但由于豆荚特殊的狭长形状,采用基于水平边界框的目标检测模型测量荚长和荚宽会产生很大的误差,往往需要加入后处理的过程才能进一步准确地测量,然而后处理操作需避免噪声干扰,若区域内噪声较多则会影响后处理过程。如图10所示,基于水平目标检测得到的边界框区域范围较广,在一个豆荚目标边界框区域内会出现其他豆荚目标的部分像素,而采用旋转目标检测可以有效地避免该问题,并减轻密集分布的豆荚间的干扰,可以更好地对豆荚区域采取进一步处理来获得更精确的荚长和荚宽。
2.6.4基于深度学习方法的训练数据获取基于深度学习的检测与分割模型训练往往需要依赖大量数据标注,如图11所示,目标检测任务需要对物体进行边界框标注,实例分割任务需要对物体进行轮廓点标注,然而数据标注过程十分耗时,且对于豆荚这类形状不定的目标,标注过程较为困难,从而导致训练1个豆荚检测模型或分割模型的成本较高。本研究提出的虚拟数据集生成方法有效地缓解了该问题,在未使用任何人工标注数据的条件下,使用虚拟豆荚图像和虚拟硬币与豆荚混合图像训练的模型在实际拍摄的图像上均取得了较高的检测精度,与文献[24]的结果相比,本研究设计的虚拟数据生成方法避免了从真实图片中人工提取单个豆荚的过程,输入真实图片后无需人工干预即可得到带有标注信息的虚拟图像,实现了端到端式的虚拟豆荚图像生成,用生成的虚拟数据训练模型,在得到了高精度的同时最大程度地降低了模型的训练成本。
pod为模型检测到的豆荚目标标签,数据表示模型对豆荚目标检测结果的置信度。
3结论
本研究提出了虚拟豆荚数据集、虚拟硬币与豆荚混合数据集生成方法,通过迁移学习方法训练CSL-YOLOv7-tiny模型,并设计基于K-均值聚类的后处理方法对检测结果进行分析,实现了大豆豆荚表型参数自动测量,主要结论如下:
(1)通过采用不同规模虚拟豆荚数据集进行训练, CSL-YOLOv7-tiny模型取得的AP0.50最优值为99.2%;通过采用不同规模虚拟硬币与豆荚混合数据集进行训练, CSL-YOLOv7-tiny模型取得的最优mAP0.50 和mAP0.50∶0.95分别达到了99.3%和78.0%。本研究设计的虚拟图像生成方法实现了端到端式的虚拟图像生成,使用虚拟图像训练得到的模型均取得了较高的检测精度,且完全避免了数据人工标注,降低了模型训练的成本。
(2)CSL-YOLOv7-tiny模型在虚拟豆荚数据集上训练得到的最优AP0.50分别比Faster R-CNN和YOLOv5n模型高1.6个百分点和0.5个百分点;通过使用迁移学习,模型在不同规模虚拟硬币与豆荚混合数据集上训练得到的mAP0.50∶0.95较未使用迁移学习训练得到的模型均具有明显的提升,在迁移学习过程中,模型积累了复杂豆荚特征的提取能力,与未使用迁移学习方法训练的模型相比具有更高的检测边界框质量。此外,CSL-YOLOv7-tiny模型大小仅有12.92 MB,推理速度达到了12.5 ms,更易于轻量化部署及应用。
(3)利用基于K-均值聚类的后处理方法测量荚长和荚宽,决定系数(R2)分别达到了0.94和0.86,与实际测量均值分别相差0.42 mm和0.02 mm,本研究设计的荚长和荚宽测量方法获得了较高的测量精度,且具有较强的考种环境适应能力,该方法为大豆豆荚表型信息的准确、自动智能获取提供了技术支撑,有助于提高育种专家对优质大豆品种的选育效率。
在未来的工作中,可尝试结合大模型对更多农作物的种子、果实进行表型测量,如玉米、麦穗和花生等,以建立一个具有强泛化能力的通用表型测量模型,并通过不断优化算法和轻量化模型来实现更全面的应用,为育种专家进行更广泛的农作物育种工作提供帮助。
参考文献:
[1]PADALKAR G, MANDLIK R, SUDHAKARAN S, et al. Necessity and challenges for exploration of nutritional potential of staple-food grade soybean[J]. Journal of Food Composition and Analysis,2023,117:105093.
[2]陈雨生,江一帆,张瑛. 中国大豆生产格局变化及其影响因素[J]. 经济地理,2022,42(3):87-94.
[3]宋晨旭,于翀宇,邢永超,等. 基于OpenCV的大豆籽粒多表型参数获取算法[J]. 农业工程学报,2022,38(20):156-163.
[4]XIANG S, WANG S Y, XU M, et al. YOLO POD:a fast and accurate multi-task model for dense Soybean Pod counting[J]. Plant Methods,2023,19(1):8.
[5]ZHOU W, CHEN Y J, LI W H, et al. SPP-extractor:automatic phenotype extraction for densely grown soybean plants[J]. The Crop Journal,2023,11(5):1569-1578.
[6]周华茂,王婧,殷华,等. 基于改进Mask R-CNN模型的秀珍菇表型参数自动测量方法[J]. 智慧农业,2023,5(4):117-126.
[7]CHEN S, ZOU X J, ZHOU X Z, et al. Study on fusion clustering and improved yolov5 algorithm based on multiple occlusion of Camellia oleifera fruit[J]. Computers and Electronics in Agriculture,2023,206:107706.
[8]RONG J C, ZHOU H, ZHANG F, et al. Tomato cluster detection and counting using improved YOLOv5 based on RGB-D fusion[J]. Computers and Electronics in Agriculture,2023,207:107741.
[9]UZAL L C, GRINBLAT G L, NAMíAS R, et al. Seed-per-pod estimation for plant breeding using deep learning[J]. Computers and Electronics in Agriculture,2018,150:196-204.
[10]闫壮壮, 闫学慧,石嘉, 等. 基于深度学习的大豆豆荚类别识别研究[J]. 作物学报,2020,46(11):1771-1779.
[11]郭瑞,于翀宇,贺红,等. 采用改进YOLOv4算法的大豆单株豆荚数检测方法[J]. 农业工程学报,2021,37(18):179-187.
[12]宁姗,陈海涛,赵秋多,等. 基于IM-SSD+ACO算法的整株大豆表型信息提取[J]. 农业机械学报,2021,52(12):182-190.
[13]王跃亭,王敏娟,孙石,等. 基于图像处理和聚类算法的待考种大豆主茎节数统计[J]. 农业机械学报,2020,51(12):229-237.
[14]张小斌,谢宝良,朱怡航,等. 基于图像处理技术的菜用大豆豆荚高通量表型采集与分析[J]. 核农学报,2022,36(3):602-612.
[15]赵岩,张人天,董春旺,等. 采用改进Unet网络的茶园导航路径识别方法[J]. 农业工程学报,2022,38(19):162-171.
[16]杨蜀秦,王帅,王鹏飞,等. 改进YOLOX检测单位面积麦穗[J]. 农业工程学报,2022,38(15):143-149.
[17]翔云,陈其军,宋栩杰,等. 基于深度学习的菜用大豆荚型表型识别方法[J]. 核农学报,2022,36(12):2391-2399.
[18]JIANG P Y, ERGU D, LIU F Y, et al. A review of Yolo algorithm developments[J]. Procedia Computer Science,2022,199:1066-1073.
[19]DIWAN T, ANIRUDH G, TEMBHURNE J V. Object detection using YOLO:challenges, architectural successors, datasets and applications[J]. Multimedia Tools and Applications,2023,82(6):9243-9275.
[20]LI S, YAN Z Z, GUO Y X, et al. SPM-IS:an auto-algorithm to acquire a mature soybean phenotype based on instance segmentation[J]. The Crop Journal,2022,10(5):1412-1423.
[21]JUNG Y, BYUN S, KIM B, et al. Harnessing synthetic data for enhanced detection of Pine Wilt Disease:an image classification approach[J]. Computers and Electronics in Agriculture,2024,218:108690.
[22]BARRIENTOS-ESPILLCO F, GASC E, LPEZ-GONZLEZ C I, et al. Semantic segmentation based on deep learning for the detection of Cyanobacterial harmful algal blooms (CyanoHABs) using synthetic images[J]. Applied Soft Computing,2023,141:110315.
[23]ABBAS A, JAIN S, GOUR M, et al. Tomato plant disease detection using transfer learning with C-GAN synthetic images[J]. Computers and Electronics in Agriculture,2021,187:106279.
[24]YANG S, ZHENG L H, YANG H J, et al. A synthetic datasets based instance segmentation network for high-throughput soybean pods phenotype investigation[J]. Expert Systems with Applications,2022,192:116403.
[25]WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7:trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. Vancouver:IEEE,2023:7464-7475.
[26]YANG X, YAN J C. Arbitrary-oriented object detection with circular smooth label[C]. Glasgow:Springer,2020:677-694.
[27]GIRSHICK R. Fast r-cnn[C]. Santiago:IEEE,2015:1440-1448.
(责任编辑:陈海霞)
