预训练模型在“你选书,我买单”计算机系统中的应用
2024-07-10谢敏明
谢敏明
摘要:为了解决图书馆“你选书,我买单”计算机系统购书审核存在的问题,文章提出引入人工智能深度学习方法,在原有计算机系统中加入购书审核模型。文章基于预训练模型BERTbase模型、BERT-wwm模型和Xlnet模型,构建“你选书,我买单”购书审核模型,微调训练这3个模型,计算3个模型验证结果,并对3个模型进行了比较。结果表明,BERTbase模型、BERT-wwm模型和Xlnet模型验证结果Accuracy、Precision、Recall 和F1 值达到设计要求,其中BERT-wwm模型和Xlnet模型各项评价指标都高于BERTbase模型。
关键词:图书馆;人工智能;预训练模型
中图分类号:G250;TP181 文献标志码:A
0 引言
近年来,图书利用率低成为高校图书馆面临的一个难题。这个问题的产生有许多原因,其中一个原因是图书采购人员素质、专业知识不够,采购的图书不符合读者的阅读需求。高校图书馆为了让采购的图书能有效契合读者的阅读需求,产生应有的经济效益和社会效益,尝试在图书采购工作中加大读者的话语权和决策权,推出“你选书,我买单” 图书阅读推广活动。在“你选书,我买单”图书阅读推广活动中,读者可以到与图书馆有签约的图书供应商书店内挑选图书,经过查重,只要读者挑选的图书符合图书馆采购原则,读者可以直接带走图书,后续图书结账由图书馆采购人员完成。这活动受到读者的极大欢迎,但也存在许多不足,如活动只能定期举行,不能长期为读者服务;图书馆活动时要派出不少人员等。随着网络的发展,有些图书馆针对这些问题开发了计算机软件。这些软件可以让读者全天候挑选图书,查重读者提交的图书,控制提交图书册数、码洋和种类大类等。然而,这些软件也存在不尽如人意的地方,如不能很好地把握读者所提交图书的学科性和专业性,不能根据图书书名和种类细类做出是否购买判断等。
1 人工智能在图书馆图书采购中的应用和“你选书,我买单”计算机系统解决方案
1.1 人工智能在图书馆图书采购中的应用
人工智能赋能新质生产力。当前人工智能技术快速发展并被广泛应用在各行各业,改变了人类社会的生活、生产和消费模式。图书馆也迫切引入人工智能技术,向智慧图书馆发展。图书馆“你选书,我买单”计算机系统审核读者上报图书和图书馆图书采购中图书审核是类似的,因此,建构图书馆“你选书,我买单”计算机系统图书审核可以借鉴图书馆图书采购所采用的人工智能方法。最近几年,许多研究者探讨了人工智能在智慧图书馆图书采购方面的应用。如:孙雷[1]探讨了高校图书馆图书采购中应用LVQ神经网络,对采购图书书名、分类号等精准控制;周志强[2]探讨了如何建立基于BP网络和基于SVM的高校图书馆图书采购模型;黄小华[3]探讨了基于遗传神经网络建立图书采购模型的方法;尹纪军[4]提出建立基于改进神经网络的图书采购模型,构建图书馆图书采购系统,解决现有人工采购方法存在的许多缺陷;蔡时连[5]利用BP神经网络和Elman神经网络建立模型,解决图书馆图书复本量计算问题;任悦[6]研究了基于SCOR模型建立高校图书供应商服务质量指标体系,有效缓解图书采购过程中优选图书供应商时存在的主观不确定性;林曦等[7]提出智慧采访是图书馆解决当前图书采访困局的有效途径,以人工智能三大基础要素为切入点,实现图书的智慧采访;Wu等[8]使用ALBERT深度学习模型,实现了高校图书馆图书采购的自动化和标准化,提高购书效率。
1.2 “你选书,我买单”计算机系统解决方案
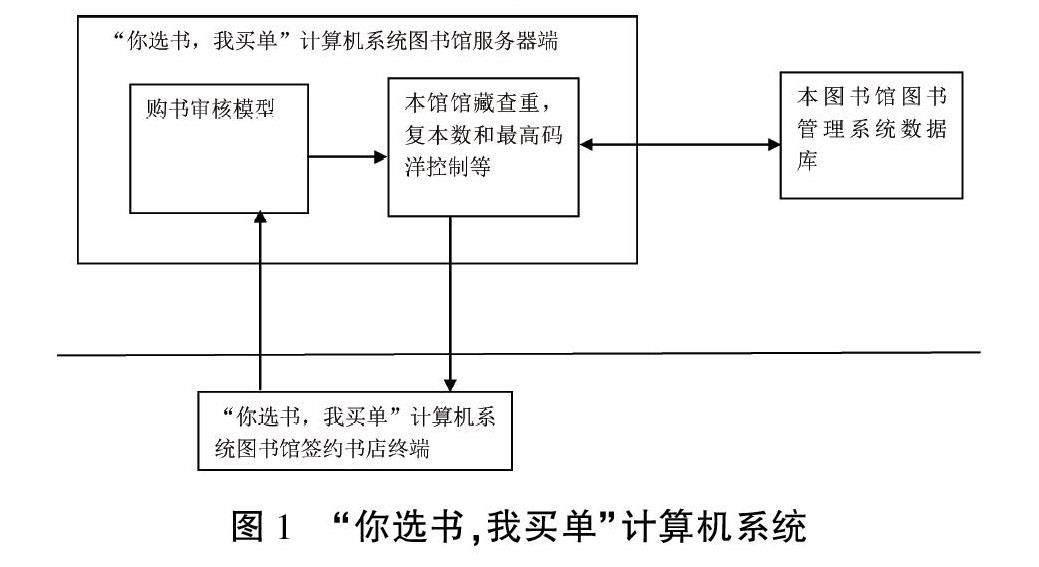
图书馆“你选书,我买单”计算机系统解决方案多是实现图书馆和书店的网络连接,利用本馆馆藏查重读者上报图书,按一些简单规则控制上报图书的种类大类,控制图书书款和复本数不超过最高书款和最高复本数。在本文方案中,图书馆“你选书,我买单”计算机系统除了实现上述功能外,还增加一个购书审核模型(见图1)。该模型能综合判断读者上报图书书名和分类号,提出图书馆采购意见,决定是否批准购买。本文尝试利用人工智能深度学习技术,以基于预训练模型微调训练而成的购书审核模型作为“你选书,我买单”计算机系统后台一部分,审核读者上传图书书名和种类细类。“你选书,我买单”计算机系统采用CLIENT/SERVER架构,购书审核模型部署在图书馆“你选书,我买单”计算机系统的服务器端,而该系统终端可以使用书店网页浏览器或读者手机。在开放时间里,读者随时到与图书馆签约书店选择图书,登录“你选书,我买单”计算机系统终端,通过身份认证,上报所选图书到“你选书,我买单”计算机系统服务器端。服务器上的购书审核模型随时审核读者上报的图书,并查重图书馆馆藏。图书审核通过后,读者马上在书店办理该图书的借阅手续,即时带走图书,过后该图书结账手续由图书馆采购人员定期办理,读者只要在规定的时间内到图书馆借阅服务部门办理图书退借手续即可。
本文采用基于人工智能的深度学习预训练模型方法解决图书馆“你选书,我买单”图书推广活动所遇到的问题,这也是人工智能在智慧图书馆应用的不断尝试。
2 预训练语言模型:BERTbase(BERT的基本模型)模型、BERT-wwm模型和Xlnet模型
构建购书审核模型处理读者上报图书是一种自然语言处理分类任务。早期构建自然语言处理模型比较简单,所用神经网络规模比较小,采用监督学习训练模型,而监督学习所用训练数据集的每个训练样本都有一个输入特征和对应的标注。随着神经网络规模越来越大,监督学习方法需要大量标注样本。但是样本标注成本昂贵,构建大规模的标注数据集耗费大量人力、物力和时间。相反,构建大规模无标注语料库相对容易,因此,研究者推出大规模无监督学习结合特定数据集微调训练的预训练模型方法,从而推动神经概率语言模型向预训练语言模型(Pre-trained Language Models,PLMs)发展[9]。
预训练模型是一种人工智能深度学习模型。在自然语言处理应用中,构建预训练模型过程分为2个阶段:预训练阶段和微调阶段。在预训练阶段,预训练模型使用大规模的无标注数据进行学习训练,学习文本中的语法、语义和上下文信息,学习语言的统计规律和语义信息。在这一阶段,预训练模型由大机构开发完成,一般使用者只要在这些预训练模型的基础上微调训练即可。在微调阶段,一般使用者为了完成特定的任务,选择和所要完成任务相适宜的预训练模型。在这过程中,使用者采用预训练阶段得到的模型参数作为初始状态,使用一定数量标注数据集进一步微调训练模型,通过反向传播算法和优化方法,根据目标任务的损失函数来调整模型的参数,使得模型能够快速适应新的任务并取得优异的性能。
BERTbase模型、BERT-wwm模型和Xlnet模型都是预训练模型,而BERT-wwm模型和Xlnet模型是BERT模型的改进优化模型。
2.1 BERTbase预训练语言模型
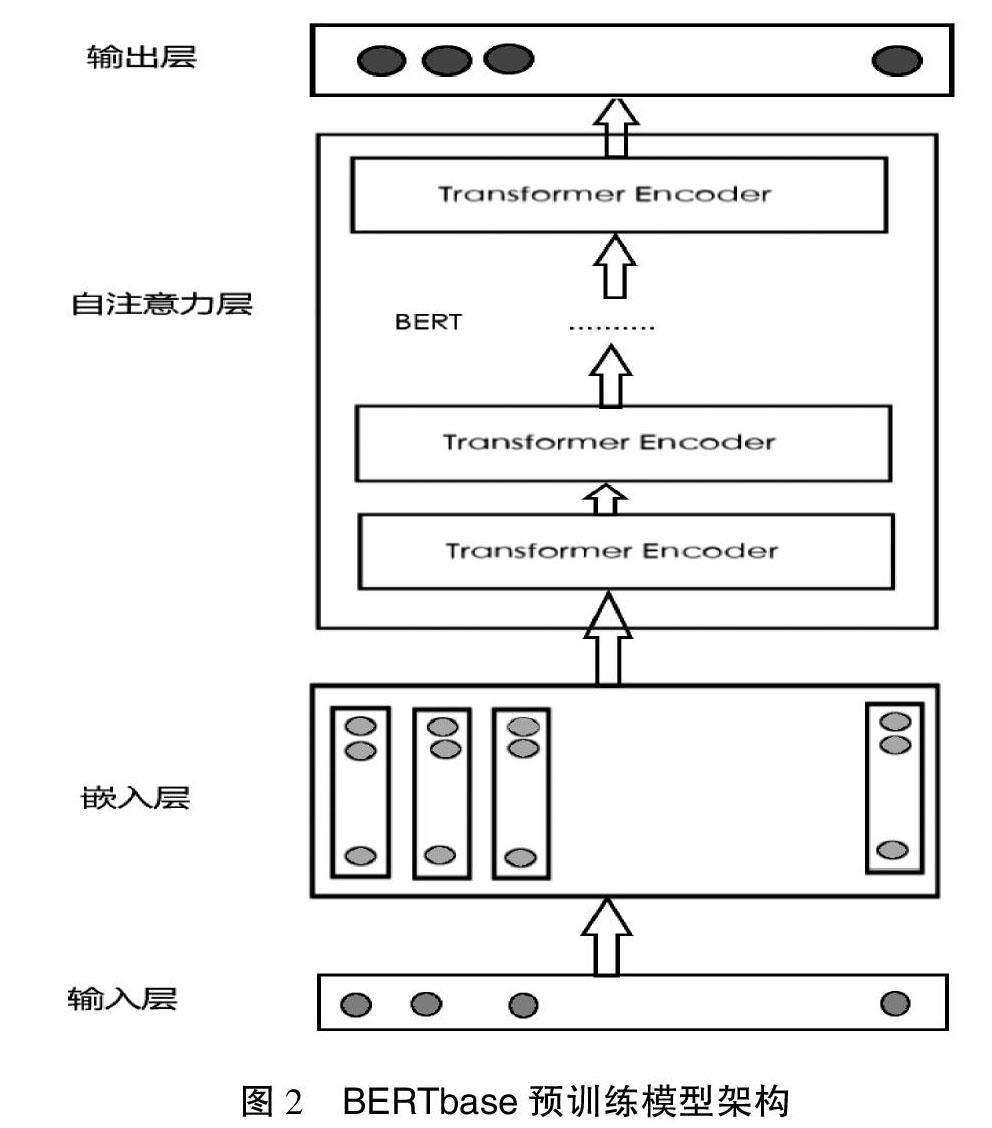
BERT[10](Bidirectional Encoder Representations from Transformers,来自Transformers 的双向编码器表示)是一个面向自然语言处理任务的无监督预训练语言模型。BERTbase模型自注意力层采用Transformer中的编码器(Transformer Encoder)叠加而成;借鉴双向编码思想,使得字序列里面的每一个字都含有这个字前面的信息和后面的信息;使用 Masked LM(MLM)双向训练方法,通过随机遮盖输入文本序列的部分词语,在输出层获得该位置的概率分布,进而极大化似然概率来调整模型参数[11]。
BERT预训练模型架构如图2所示,由输入层、嵌入层、自注意力层和输出层组成。
在输入层,为了更好地表达输入文本句子段信息和字位置信息,输入文本用2个特殊的标志[CLS]和[SEP]表示句子的开始和句子之间的分隔。
在嵌入层,把输入文本转化为向量(实数矩阵I)。该向量是输入文本的字嵌入、段嵌入和位置嵌入向量和,即:
I=Token_embed + Sentence_embed + Position_embed [12] (1)
Token_embed、Sentence_embed和Position_embed分别表示字嵌入、段嵌入和位置嵌入。字嵌入在嵌入之前,原来输入文本除了已经加入的[CLS]和[SEP]标志外,还随机遮盖一些单字,并用[MASK]替代。
自注意力层由多个Transformer编码器叠加而成。每个编码器由多头自注意力子层、若干规范层和前馈网络层组成。多头自注意力子层可分为多个头(一般为8头),对每个头计算注意力Attention,即把自注意力的Q、K、V均分成几份,分别计算其注意力,最后把各头注意力结果Concat合并输出,计算公式如下:
headi=Attention(QWQi、KWKi、VWVi)(2)
MultiHead(Q,K,V)=Concat(headi,…,headi)w0[13](3)
其中,WQi、WKi、WVi分别是第i个头的查询、键、值矩阵,Attention是注意力计算函数。在规范层对多头注意力子层的输入和输出做规范化,使得特征数值在合理的范围内。规范化后的结果进入前馈网络层,在这里进行前向传播。编码器最后还加上一个规范层,再做一次规范化。规范化的结果作为整个编码器的输出。
在输出层,最后一个编码器的输出作为整个 BERT 模型的最终输出,这输出是输入各字对应的融合全文语义信息后的向量表示。在做分类任务时输入[CLS]对应的第一个输出C可作为模型输入分类结果。
2.2 BERT-wwm模型
BERT-wwm[14](BERT-Whole Word Masking)是谷歌在2019年5月31号发布的一项BERT升级版本。它相对于BERT的改进是用Mask标签替换一个完整的词而不是字词。中文和英文不同,英文最小的token是一个单词,而中文中最小的token却是字。词是由一个或多个字组成,且每个词之间没有明显的分割,包含更多信息的是词,对全词mask就是对整个词都通过mask进行掩码。哈工大讯飞联合实验室推出的hfl/chinese-bert-wwm-ext是个全词覆盖的中文预训练模型,是BERT-wwm的一个升级版。相比BERT-wwm,hfl/chinese-bert-wwm-ext增加了训练数据集和训练步数。本文方案采用hfl/chinese-bert-wwm-ext。
2.3 Xlnet模型
Xlnet[15]是一种泛自回归模型,融合了自回归和降噪自编码2种方法的优点。Xlnet提出排列语言模型(Permutation Language Model,PLM)训练方法,解决掩码语言模型(MLM)训练方法中[MASK]带来的负面影响;提出双流注意力机制(Two-Stream Self-Attention)配合PLM训练。由于BERT所采用的MLM训练方法在预训练时需要用[mask]字符替换掉一部分输入,忽略了被mask位置之间的依赖关系,而在微调时却没有,这导致预训练与微调的不一致。Xlnet采用排列语言建模(PLM),在预训练阶段,不加入人为的[MASK]符号,在内部对单词的位置进行重排列,对所有排列方式进行随机采样,用少数的排列顺序进行训练,解决自回归语言模型中无法同时使用双向上下文信息的缺陷。对于之后出现的2个新问题:其一,基于传统参数形式的排序语言模型会退化成词袋模型,这便需要用单词在原始句子中的位置信息对模型进行再参数化;其二,某个单词的隐状态在预测自身和预测其他单词之间存在矛盾,对此Xlnet引入双流自注意力机制。此外,Xlnet还使用Transformer-XL替代Transformer,解决Transformer对文档长度限制[16]。
3 购书审核模型微调训练和验证结果分析
3.1 购书审核模型微调训练
本文购书审核模型微调训练方案选择Hugging face网站上Bert-base-chinese、hfl/chinese-bert-wwm-ext和hfl/chinese-xlnet-mid 3种预训练模型,在这3种预训练模型基础上分别进行微调训练和验证,并对验证结果进行分析;采用PyTorch开源深度学习库搭建购书审核模型和进行微调训练;采用Python作为编程语言,PyCharm作为开发环境。
微调训练需要一定数量标注训练数据集和验证数据集。这些数据集是在原始数据基础上,通过清洗整理而成。本文收集原始数据即图书馆采购数据56570条,事先对这些采购数据清洗。这些采购数据不仅有正样本数据,即要订购的数据,还有一定比例负样本数据,即不要订购的数据。打乱上述采购数据顺序,并将其随机分成训练集46570条和验证集1万条。本文选择上述训练集和验证集中书名和分类号作为样本特征,选择上述训练集和验证集中是否订购作为标本标注。把标本特征书名和分类号拼接在一起作为模型输入,根据BERTbase、BERT-wwm和Xlnet的不同输入拼接要求,对于Bert-base-chineset和hfl/chinese-bert-wwm-ext模型输入拼接为:[CLS]+书名+分类号+[SEP][17],而对于hfl/chinese-xlnet-mid则是:书名+分类号+[SEP]+[CLS][18]。
超参数是模型微调训练过程中控制模型行为的参数,通常需要通过试验和调整来找到最佳值。每种模型训练3次,迭代次数(Epoch)分别取3、6、9;批次大小(Batch_Size):16;学习率:1E-5;优化器:Adam;最大序列长度:200;dropout:0.1。
3.2 验证结果评价指标及验证结果分析
3.2.1 验证结果评价指标
模型验证是评估模型性能的过程。在这过程中,使用独立于训练数据集的验证数据集来评估模型在未使用过数据上的表现,可以帮助了解模型的泛化能力和性能,并进行模型选择和调优。本文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-Score)作为模型训练结果评价指标。以下公式中,TP表示实际为正且被预测为正的样本数量;FP表示实际为负但被预测为正的样本数量;FN表示实际为正但被预测为负的样本的数量;TN表示实际为负被预测为负的样本的数量。
Accuracy=(TP+TN)/(TP+TN+FP+FN)
Precision=TP/(TP+FP)
Recall=TP/(TP+FN)
F1-Score=(2×Precision×Recall)/(Precision+Recall)[19]
3.2.2 验证结果分析
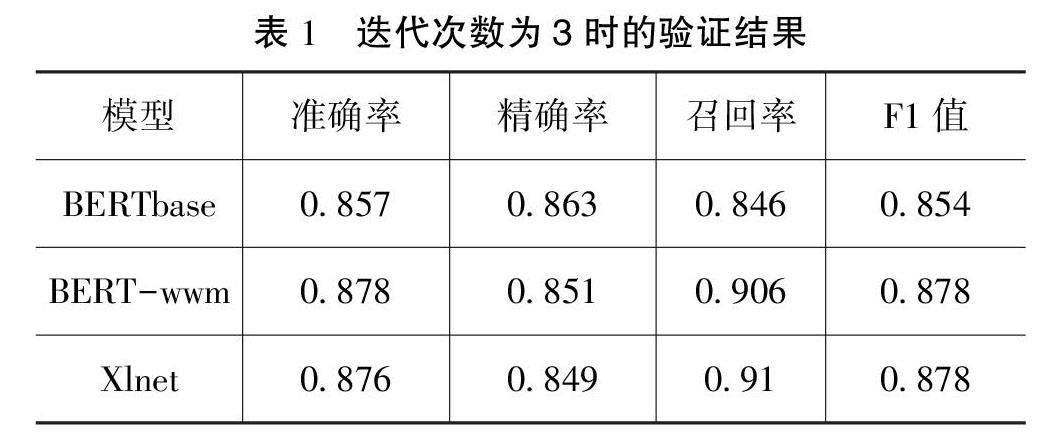
验证结果如表1—3和图3—6所示。
从上面验证结果看出:BERT-wwm模型和Xlnet模型验证结果评价指标准确率、精确率、召回率和F1值全部大于BERTbase模型。BERTbase模型准确率、精确率和F1值在3Epoch后向下走低,并小于BERT-wwm模型和Xlnet模型;召回率向上稍微提升,但6Epoch后呈水平直线,并几乎全程小于BERT-wwm模型和Xlnet模型。作为精确率和召回率的加权平均值F1值,BERT-wwm模型和Xlnet模型都高于BERTbase模型。
4 结语
验证结果表明,BERTbase、BERT-wwm和Xlnet 3种模型验证训练结果评价指标都大于83%以上,基本能满足本文方案要求。但BERT-wwm模型和Xlnet模型各项评价指标都高于BERTbase模型,可以得出基于BERT-wwm模型和Xlnet模型训练出来的模型优于基于BERTbase训练出来的模型。
参考文献
[1]孙雷.LVQ神经网络在高校图书馆图书采购中的应用研究[J].现代情报,2011(10):166-168.
[2]周志强.基于混合智能算法的高校图书馆图书采购模型研究[D].呼和浩特:内蒙古大学,2019.
[3]黄小华.基于改进遗传神经网络的图书采购模型研究[J].现代情报,2009(9):162-165.
[4]尹纪军.基于改进遗传神经网络的图书采购系统研究[D].镇江:江苏大学,2007.
[5]蔡时连.BP神经网络和Elman神经网络模型的图书复本量预测分析[J].图书情报工作,2014(6):157-159.
[6]任悦.基于SCOR模型的高校图书馆供应商服务选择研究[J].情报探索,2022(3):117-122.
[7]林曦,赵大志.基于人工智能的高校图书馆图书智慧采访研究[J].山东图书馆学刊,2022(4):30-37.
[8]WU Y J,WANG X X,YU P L,et al.ALBERT-BPF:A book purchase forecast model for university library by using ALBERT for text feature extraction[J].Aslib Journal of Information Management,2022(4):673-687.
[9]王乃钰,叶育鑫,刘露,等.基于深度学习的语言模型研究进展[J].软件学报,2021(4):1082-1115.
[10]DEVLIN J,CHANG M W,LEE K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[J].arXiv,2018(10):48-50.
[11]张云秋,汪洋,李博诚.基于RoBERTa-wwm动态融合模型的中文电子病历命名实体识别[J].数据分析与知识发现,2022(2/3):242-250.
[12]瓜子paw.Bert学习笔记[EB/OL].(2022-09-01)[2024-01-28].https://blog.csdn.net.
[13]杨丹的博客.BERT基础(一):self_attention自注意力详解[EB/OL].(2019-11-05)[2024-01-28].https://blog.csdn.net.
[14]CUI Y,CHE W,LIU T,et al.Pre-training with whole word masking for Chinese BERT[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2021(29):3504-3514.
[15]YANG Z,DAI Z,YANG Y,et al.Xlnet:generalized autoregressive pretraining for language understanding[C].Proceeding of the 31th Conference on Advances in Neural Information Processing Systems,Long Beach:IEEE,2019:5754-5764.
[16]邵浩,刘一烽.预训练语言模型[M].北京:电子工业出版社,2021.
[17]AI让世界更懂你.转战pytorch—XLNet初体验(5)[EB/OL].(2020-11-15)[2024-01-28].https://blog.csdn.net.
[18]超级无敌陈大佬的跟班.[深度学习]模型评价指标[EB/OL].(2021-09-10)[2024-01-28].https://blog.csdn.net.
(编辑 王雪芬)
Application of pre-training model in computer system of “You choose the book, I pay the bill”XIE Minming
(Library, Xiamen University of Technology, Xiamen 361024, China)
Abstract: In order to solve the problems existing in the book purchase audit of the librarys “You choose books, I pay the bill” computer system, this paper puts forward the introduction of artificial intelligence deep learning method, and adds the book purchase audit model to the original computer system. Based on the pre-training model BERTbase model, BERT-wwm model and Xlnet model, the “You choose books, I pay the bill” book purchase audit model was constructed, and the three models were fine-tuned for training, and the verification results of the three models were calculated and compared. The accuracy, precision, recall and F1 values of BERTbase model, BERT-wwm model and Xlnet model meet the design requirements, and the evaluation indexes of BERT-wwm model and Xlnet model are higher than BERTbase model.
Key words: library; artificial intelligence; pre-trained language models
