基于匹配自主学习的网络信息识别与分类算法
2024-06-30曾光辉
曾光辉
摘要:为提升网络信息的识别与分类准确率,针对海量网络信息的高维、高噪等特点,提出基于匹配自主学习的网络信息识别与分类算法。首先,利用支持向量机对网络信息进行识别;然后,通过奇异值分解算法构建检索矩阵进行奇异值分解、相关性查询;接着,计算网络信息的相似性匹配度,并将匹配度较高的网络信息输入到卷积神经网络中进行学习、训练;最后,输出网络信息分类结果。实验结果显示,该算法网络信息识别准确率达到97.90%以上,针对不同类别网络信息的平均分类准确率为98.04%,证明了该算法在实际应用中的有效性。
关键词:匹配自主学习;网络信息;支持向量机;奇异值分解;卷积神经网络;识别与分类
中图分类号:TP309 文献标志码:A 文章编号:1674-2605(2024)03-0007-06
DOI:10.3969/j.issn.1674-2605.2024.03.007
Network Information Recognition and Classification Algorithm Based on Matching Autonomous Learning
Abstract: To improve the accuracy of network information recognition and classification, a network information recognition and classification algorithm based on matching autonomous learning is proposed to address the high dimensionality, high noise and other characteristics of massive network information. Firstly, using support vector machine to recognize network information; Then, a retrieval matrix is constructed using singular value decomposition algorithm for singular value decomposition and correlation queries; Finally, calculate the similarity matching degree of network information, and input the network information with higher matching degree into the convolutional neural network for learning and training, outputting the network information classification results. The experimental results show that the network information recognition accuracy of the algorithm reaches over 97.90%, and the average classification accuracy for different types of network information is 98.04%, which has certain practical application effectiveness.
Keywords: matching autonomous learning; network information; support vector machine; singular value decomposition; convolutional neural network; recognition and classification
0 引言
在当前的信息时代,网络信息呈海量式与爆炸式增长[1]。网络信息不仅涉及多个特征,如文本内容、图像像素、格式类别等,还包含大量的干扰或噪声,如文本拼写错误、图像噪点或失真、网络攻击等,故其应用性与安全性受到相关研究人员的重视。网络信息的识别与分类是提升其应用性与安全性的基础[2-3]。
周家恺等[4]基于朴素贝叶斯对网络信息进行特征识别,识别效率较高,但易受来源数据噪声影响,识别精准度还有一定的提升空间。朱方娥等[5]提出基于分类规则挖掘的数据多标记特征分层识别方法,特征识别及分类的准确度较高,但较为依赖数据来源,需进行更加完善的数据预处理。
本文提出一种基于匹配自主学习的网络信息识别与分类算法。通过支持向量机、奇异值分解算法、卷积神经网络的匹配应用,实现网络信息的识别与分类。
1 算法流程
匹配自主学习算法是指对输入数据进行匹配并比较的自主学习算法。自主学习算法以多智能体深度强化学习类方法为代表,通过构建认知智能体,自动学习和获取复杂系统深层次的规律[6]。
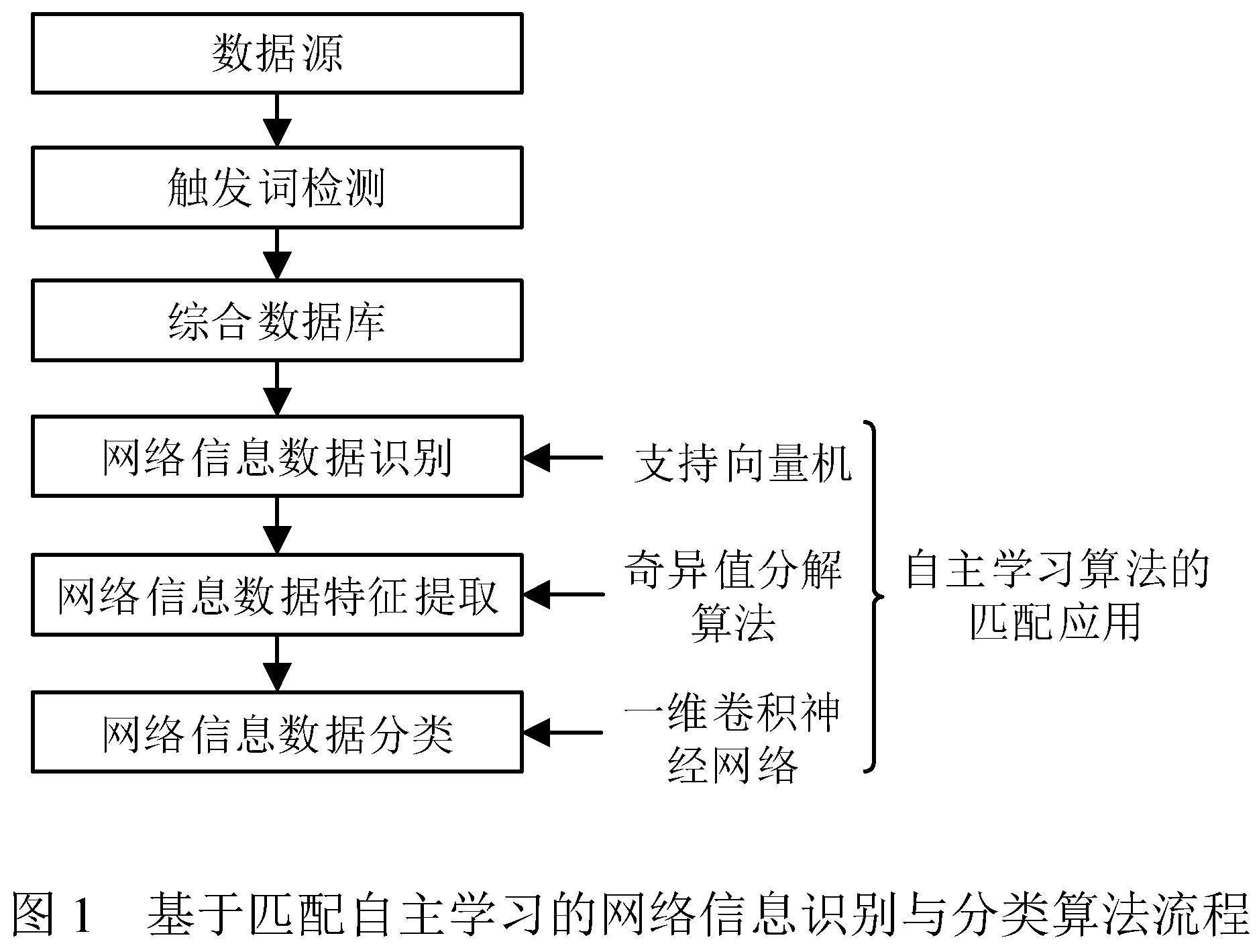
本文引入自主学习算法中的支持向量机、奇异值分解算法、卷积神经网络对网络信息进行识别与分类。基于匹配自主学习的网络信息识别与分类算法流程如图1所示。
本文利用支持向量机实现网络信息的识别;采用奇异值分解算法提取异常网络信息的特征向量;运用一维卷积神经网络算法分类处理异常网络信息[7]。其中,一维卷积神经网络不易出现信息损耗、丢失和信息畸变等问题,可提升网络信息识别与分类的效率。
2 网络信息识别
支持向量机能够处理高维特征空间的分类问题,通过构建最优的超平面来实现数据分类,可有效地处理小样本问题,且对未见过的数据具有较好的泛化能力,减少过拟合风险。首先,对网络信息进行触发词检测预处理,并均等分为训练数据集与测试数据集[8];然后,利用支持向量机对训练数据集中的数据进行训练,构建网络信息识别模型;接着,将测试数据输入到网络信息识别模型,界定网络信息识别阈值;最后,得到网络信息的识别结果。基于支持向量机的网络信息识别流程如图2所示。
网络信息的主要特征表现为海量性与高度开放性[9]。若对全部的网络信息都进行分析处理,将降低网络信息的识别效率,同时分析不重要的网络信息也会提升识别成本。因此在对网络信息进行识别与分类前,采用触发词检测方法对网络信息进行预处理,清除网络信息中的无用信息,减少数据维度。触发词是可最大限度地反映事件的词语。
利用支持向量机训练网络信息识别模型,获得网络信息性能指标曲线与阈值查阅表,由此可获取网络信息识别阈值[10]。基于该网络信息识别阈值对测试数据集的网络信息进行识别,确定其为正常网络信息或异常网络信息。基于支持向量机的网络信息识别,以径向基函数(radial basis function, RBF)为核函数,以接受者操作特性曲线(receiver operating characteristic curve, ROC)与坐标轴围成的面积(area under curve, AUC)为识别参数优化指标,对惩罚系数与核函数进行优化;同时引入交叉验证的方法避免支持向量机出现过拟合。
基于支持向量机的网络信息识别过程描述如下:
设为训练数据集,和分别表示第i个网络信息向量和![]() 的类别标签。以为样本点,构建最优超平面,即网络信息识别模型
的类别标签。以为样本点,构建最优超平面,即网络信息识别模型![]() 的计算过程为
的计算过程为
式中:![]() 为超平面的法向量,
为超平面的法向量,![]() 和
和![]() 分别为惩罚系数与网络信息识别的误项。
分别为惩罚系数与网络信息识别的误项。
其约束条件为
式中:![]() 为超平面的常数项。
为超平面的常数项。
3 网络信息分类
3.1 基于奇异值分解算法的相似性匹配度计算
在网络信息特征分类之前,先对网络信息进行特征提取[11]。将网络信息识别模型输出的识别结果作为输入,采用奇异值分解算法进行特征提取。通过隐含语义提取,清除不相关词汇,得到关键词向量,目标特征描述矩阵向量间的内在属性;对目标特征进行变换与分解处理,得到的相似性匹配结果作为输出,具体过程如下:
1) 构建词条——文档矩阵,对待提取特征的网络信息文档进行处理,清除不相关词汇,获取网络信息文档的关键词向量,维数为n。若网络信息文档包含m个文件,则可获取一个n × m维矩阵。奇异值分解算法将词条——文档矩阵分解为3个不同的矩阵,公式描述为
式中:![]() 描述网络信息文档内不同词条间的相关性[12],
描述网络信息文档内不同词条间的相关性[12],![]() 描述网络信息不同文档间的相关性,
描述网络信息不同文档间的相关性,![]() 与
与![]() 均为正交矩阵;
均为正交矩阵;![]() 为对角矩阵。
为对角矩阵。
考虑到矩阵![]() 和
和![]() 均具有线性独立特性,可通过近似矩阵
均具有线性独立特性,可通过近似矩阵![]() 取代
取代![]() 进行分析,如公式(4)所示。
进行分析,如公式(4)所示。
式中:![]() 和
和![]() 分别为
分别为![]() 和
和![]() 的前K列,
的前K列,![]() 为包含X的前K个最大奇异值,;,由此可提升特征提取效率。
为包含X的前K个最大奇异值,;,由此可提升特征提取效率。
2) 网络信息文档中的若干个关键词通过变换生成一个K维向量![]() ,其代表一个虚文档,将
,其代表一个虚文档,将![]() 与文档相关性矩阵
与文档相关性矩阵![]() 内的文档向量进行对比,得到相似性匹配结果[13]
内的文档向量进行对比,得到相似性匹配结果[13]![]() 的计算公式为
的计算公式为
(5)
![]() 值越大,表明网络信息相似性匹配度越高,分类效果较好;
值越大,表明网络信息相似性匹配度越高,分类效果较好;![]() 值越小,表明网络信息相似性匹配度越低,分类效果较差。
值越小,表明网络信息相似性匹配度越低,分类效果较差。
应用奇异值分解算法进行网络信息特征提取的过程中,在一定程度上去除了网络信息中的噪声或异常点,通过保留主要的奇异值和特征向量,可以恢复经去噪处理后的原始信息,为后续网络信息的精准分类提供保障。
3.2 基于卷积神经网络的网络信息分类
根据网络信息特征建立一维卷积神经网络分类模型,实现网络信息的分类处理。一维卷积神经网络模型包括输入层、卷积层、池化层、全连接层、输出层等,输出层可输出网络信息的分类结果,结构如图3所示。
一维卷积神经网络模型的输入是相似性匹配结果。
卷积层作为一维卷积神经网络的核心,主要负责对网络信息进行稀疏连接[14],降低网络信息特征的参
数量。利用公式(6)确定卷积层的输出![]() 为
为
式中:![]() 和e分别为激活函数和网络信息特征数量,
和e分别为激活函数和网络信息特征数量,![]() 为第j个网络信息数据,
为第j个网络信息数据,![]() 和
和![]() 分别为输出偏置与卷积核尺寸。
分别为输出偏置与卷积核尺寸。
池化层主要负责进一步降低卷积层输出的特征参数,同时保留网络信息的主要特征[15]。利用公式(7)描述最大池化函数为
(7)
式中:![]() 和
和![]() 分别为池化层移动步长和池化尺寸。
分别为池化层移动步长和池化尺寸。
在卷积层与池化层的逐渐堆叠下,不仅能够提取网络信息的深层特征,还能够显著降低参数量。
将提取的网络信息特征转换为一维向量,并输出至全连接层进行分类,其中![]() 为最后一层池化层的神经节点数量。
为最后一层池化层的神经节点数量。
输出层是一维卷积神经网络的最后一层,其输出的结果即为网络信息所属类别![]() :
:
式中:![]() 为全连接层的输出,
为全连接层的输出,![]() 和
和![]() 分别为网络信息类别的索引和全部网络信息的数量。
分别为网络信息类别的索引和全部网络信息的数量。
4 实验分析
4.1 实验准备
为验证本文算法在实际网络信息识别与分类中的效果,分别对网络信息识别、特征向量提取、网络信息分类的性能进行测试。
实验环境为Ubuntu 18.04操作系统,Python3.7编程语言,TensorFlow2.0开发框架,具备GPU加速功能的NVIDIA GeForce RTX 2080 Ti。计算资源方面,Intel Core i7-8700K CPU @ 3.70 GHz的计算机,32 GB内存。触发词匹配阈值设定为0.7,当网络信息中某个词与触发词的相似度高于0.7时,将该词输入到综合数据库中以待后续处理;当网络信息中某个词与触发词的相似度低于0.7时,忽略或丢弃该词。奇异值分解降维维度设置为100维,卷积核大小设置为3、5和7,以便对不同尺度的网络信息进行特征提取,利用最大池化对网络信息特征进行降维。
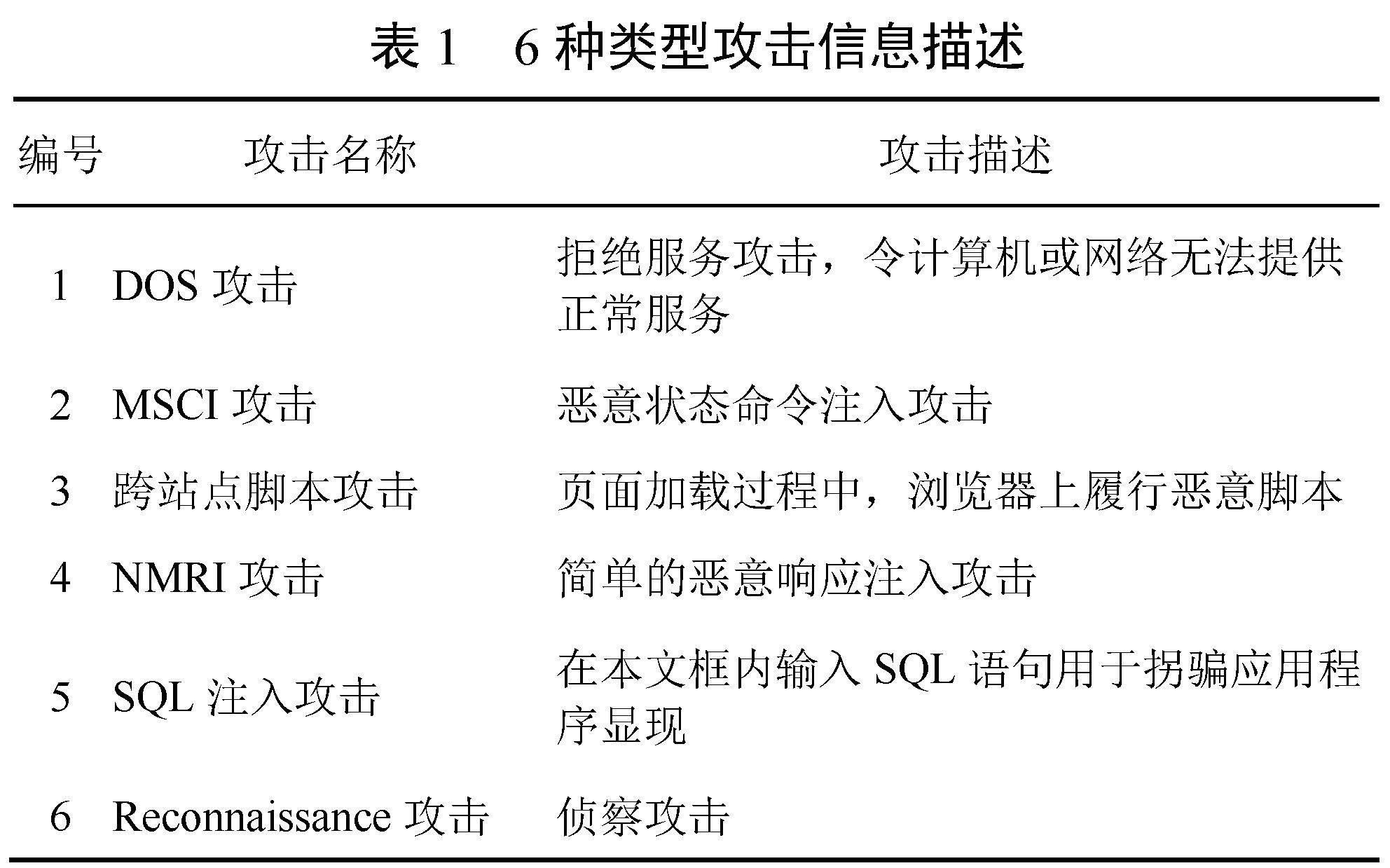
实验数据集选取KDD cup 99数据集,包括正常网络信息(文本信息、图片信息、视频信息)、异常网络信息(虚假信息、攻击信息)共4 909 542条。其中,攻击信息包含6种类型,如表1所示。
4.2 支持向量机训练
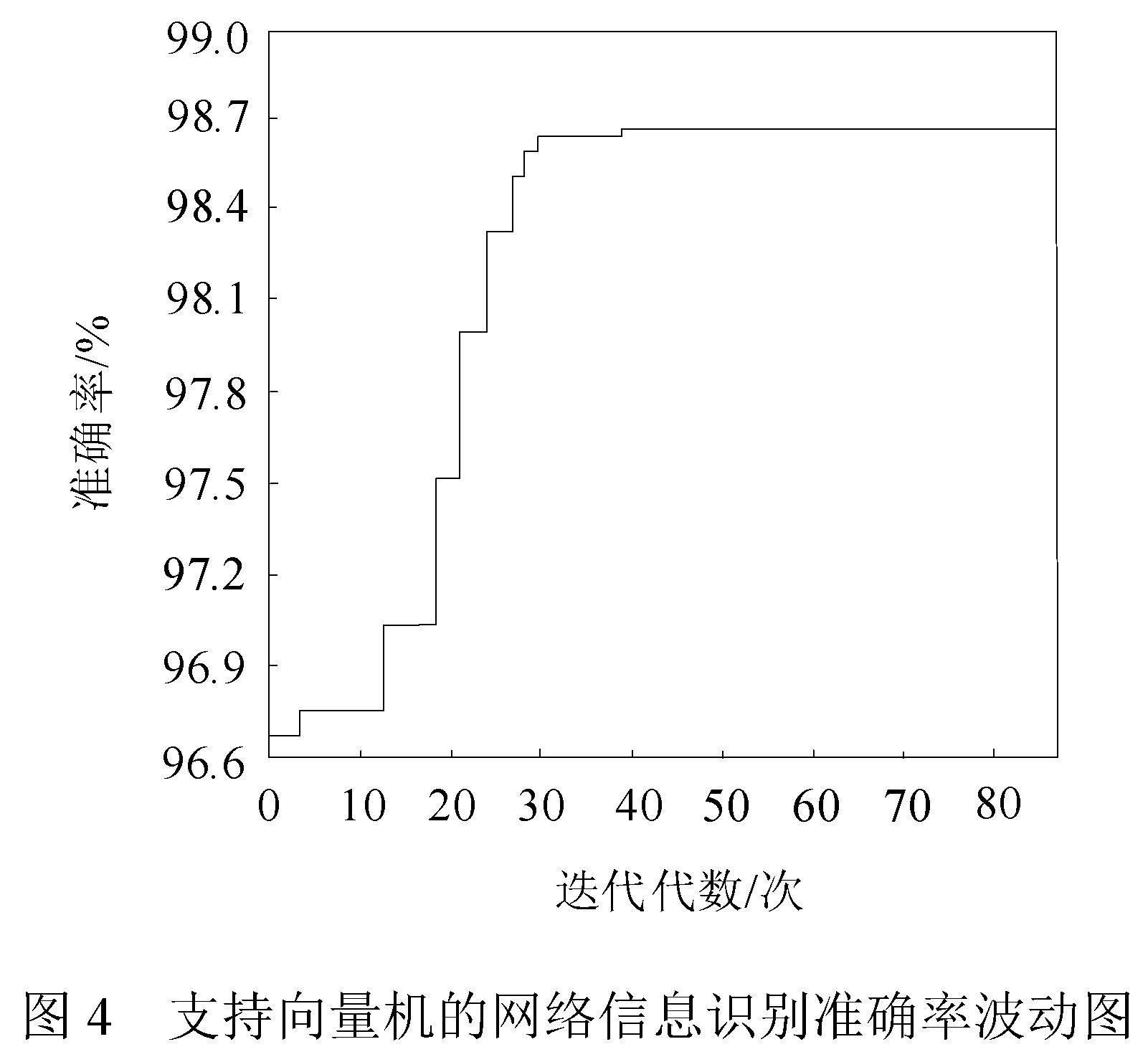
选取KDD cup 99数据集的50%,即2 454 771条网络信息作为训练样本进行训练,得到支持向量机的网络信息识别准确率波动图如图4所示。
由图4可知:随着支持向量机迭代次数的增加,网络信息识别准确率也逐渐提高,当迭代次数小于30次时,识别准确率提高速度较快;当迭代次数大于30次时,识别准确率提高速度逐渐趋于平缓;当迭代次数达到40次时,识别准确率稳定在98.70%左右。至此,完成网络信息识别模型的训练。
4.3 实验结果与分析
4.3.1 网络信息识别性能测试
利用训练好的网络信息识别模型对KDD cup 99数据集剩余的50%,即2 454 771条网络信息进行识别,判断网络信息状态。为验证本文算法的性能,选取文献[4]的基于朴素贝叶斯方法和文献[5]的基于分类规则挖掘方法进行对比实验,结果如表2所示。
由表2可知:随着测试样本数据量的增加,3种方法的识别准确率均有所下降,在测试样本数据量为10 000条时,本文算法、基于朴素贝叶斯方法、基于分类规则挖掘方法的识别准确率最高,分别为99.21%、97.87%、95.79%;在测试样本数据量为2 454 771条时,3种方法的识别准确率最低,分别为97.90%、95.73%、93.57%,表明测试样本数据量对准确率造成影响,且本文算法具有较高的网络信息识别性能。
4.3.2 特征向量提取性能测试
对于相同的网络信息,不同方法提取的特征向量会有所差异。采用本文算法与基于朴素贝叶斯方法、基于分类规则挖掘方法分别进行网络信息特征向量
提取性能对比实验,以方差、偏度、峰度为评估指标。其中,方差越大,说明样本数据在这一维度上的差异性越大,数据包含大量的噪声或异常值;偏度用于衡量数据分布的不对称性,正值表示数据右偏,负值表示数据左偏,接近0表示数据近似对称;峰度正值表示尖峭峰,即比正态分布更集中,而负值表示平坦峰,即比正态分布更平缓,峰值大说明存在极端值。3种评估指标的计算公式为
式中:![]() 为整体的样本数据,
为整体的样本数据,![]() 为样本数量,
为样本数量,![]() 为第i个样本数据,
为第i个样本数据,![]() 为样本均值。
为样本均值。
本文算法与基于朴素贝叶斯方法、基于分类规则挖掘方法的特征向量提取性能对比结果如表3所示。
由表3可知:随着关键词数量逐渐增加,3种方法的特征向量方差也逐渐增大,说明关键词数量越多,特征提取的难度越大,越容易存在噪声;在不同关键词数量下,3种方法均保持较小且接近0的偏度,表明特征向量分布相对对称,本文算法的偏度值稳定且偏负,显示特征向量分布可能略向左偏,相比之下,另外2种方法在关键词数量增多时偏度值增加,说明其分布偏斜较大;本文算法特征向量的峰度相对另外2种方法较低,说明特征提取后,极端值较少,特征向量提取效果较好。
4.3.3 网络信息分类性能测试
采用本文算法、基于朴素贝叶斯方法、基于分类规则挖掘方法对识别的2 454 771条网络信息进行分类处理,结果如表4所示。
由表4可知:本文算法的平均分类准确率为98.04%;基于朴素贝叶斯方法和基于分类规则挖掘方法的平均分类准确率分别为95.29%和92.44%,验证了本文算法对网络信息的分类准确率较高、分类处理性能较好。对异常网络信息的精准分类能够更好地对攻击信息采取相应的防御措施。
5 结论
本文研究基于匹配自主学习的网络信息识别与分类算法,利用自主学习算法中的支持向量机、奇异值分解算法、一维卷积神经网络实现网络信息的识别与分类。实验结果显示,该算法的网络信息识别准确率、特征向量提取性能以及网络信息分类准确率均较高,说明该算法具有较好的应用性能。在本文算法研究的过程中,受时间与经费的限制,在处理大规模网络信息时,算法的运行效率受到一定程度的限制。因此,未来将会探索更高效和可扩展的算法形式,以应对大规模网络信息的识别与分类。
参考文献
[1] 周毅,张雪.网络信息内容生态安全风险整体智治的理论框架与实现策略研究[J].图书情报工作,2022,66(5):44-52.
[2] 韩正彪,马毛宁,翟冉冉.网络学术信息搜索中用户情感的识别及变化研究[J].情报学报,2022,41(3):314-324.
[3] 蒋岑,吴迪.隐蔽无线通信网络传输信息云存储密文检索[J].计算机仿真,2021,38(6):125-128;137.
[4] 周家恺,綦方中.网络流量时延特征数据的识别方法仿真[J].计算机仿真,2022,39(5):398-401;460.
[5] 朱方娥,郭建方,曹丽娜.基于分类规则挖掘的数据多标记特征分层识别[J].计算机仿真,2021,38(4):310-314.
[6] 朱晓慧,钱丽萍,傅伟.基于生成对抗网络增强恶意代码的方法[J].计算机工程与设计,2021,42(11):3034-3042.
[7] 高昂,郭齐胜,董志明,等.基于EAS+MAD RL的多无人车体系效能评估方法研究[J].系统工程与电子技术,2021,43(12): 3643-3651.
[8] 蒋丽,黄仕建,严文娟.基于低秩行为信息和多尺度卷积神经网络的人体行为识别方法[J].计算机应用,2021,41(3):721-726.
[9] 陆晓松,王国庆,李勖之,等.场地环境大数据采集和机器学习方法在污染智能识别中的应用研究进展[J].生态与农村环境学报,2022,38(9):1101-1111.
[10] 张泽锋,毛存礼,余正涛,等.融入领域术语词典的司法舆情敏感信息识别[J].中文信息学报,2022,36(9):76-83;92.
[11] 陈思佳,罗志增.基于长短时记忆和卷积神经网络的手势肌电识别研究[J].仪器仪表学报,2021,42(2):162-170.
[12] 向志华,梁玉英.基于机器学习的视频识别与自适应推送算法[J].沈阳工业大学学报,2022,44(3):336-340.
[13] 张玲,卫传征,林臻彪,等.一种基于机器学习的Tor网络识别探测技术[J].电子技术应用,2021,47(4):54-58.
[14] 华萌萌,尹君,胡召玲,等.基于机器学习的历史气候重建论文智能识别与数据挖掘初探[J].第四纪研究,2021,41(2): 550-561.
[15] 宋雅文,杨志豪,罗凌,等.基于字符卷积神经网络的生物医学变异实体识别方法[J].中文信息学报,2021,35(5):63-69.
