基于RapidMiner 决策树的学生学习策略预测分析
2024-06-26孙振华
孙振华

摘要: 文章利用RapidMiner工具决策树算法,对学生学习策略进行预测分析,并从中找到有价值的信息。通过对学习策略数据集的预处理、模型选择和模型评估等步骤,获得了一个准确率较高的决策树模型。该模型对学生的学习策略进行了分类,并揭示了不同分类和成绩之间存在的关联。实验结果表明,决策树算法在学习策略预测方面具有较高的价值,并为教育工作者提供了指导学生学习策略的新方法。
关键词:数据挖掘;RapidMiner;决策树;学习策略
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)14-0070-03 开放科学(资源服务)标识码(OSID) :
0 引言
如何提高学生的学习成绩是教师和家长普遍关心的问题。除了正确的学习方法、端正的学习态度、良好的学习习惯,学习策略也是影响其学习成绩和学习效果的重要因素之一。以镇江高职校信息工程系专业为例,学生的学习除课堂教学外,还包括课前预习、课后复习、网络学习平台中的微课、模拟仿真、在线自测等。然而,不同的学生学习策略不相同,取得的成绩也不同。为了更好地进行研究,随机选取信息系物联网专业22级的30名学生,通过问卷调查收集学生一个月以来的学习策略数据,并进行研究前后两次难度相当的综合测试。根据学生两次测试成绩的变化来判断学习策略是否有效果。利用RapidMiner 工具进行数据挖掘,对学习策略进行预测分析,探究不同学习策略对学习成绩的影响。
1 数据分析及算法选择
数据分析是数据挖掘中数据准备过程的重要一环,是数据预处理的前提[1]。学习策略数据通过前期的问卷星调研形成数据集,并导出为Excel表格。表格字段包括序号、姓名、性别、课前、课后复习等6项。另外,研究前的原始成绩、对比成绩也录入表格中。在数据集中,序号、姓名、性别以及两次测试的成绩不属于学习策略,而两次成绩前后的差异作为预测目标,判断学生是否进步还是无进步。所以在后续的数据预处理阶段,应将序号、姓名、性别字段去除,将两次成绩进行比对、生成一个新列存放“进步”或“无进步”。在算法选择方面,由于数据集呈现离散化特征,可归纳为分类问题,选择RapidMiner决策树中的ID3 算法相对合适。ID3算法以信息增益为指标判别决策树各层次节点上数据的特征属性[2]。信息增益越高,意味着划分后的子节点纯度越高,对于分类的贡献越大。因此,ID3算法须选择信息增益最大的节点作为父节点[3]。ID3算法对于小型数据集的处理有着较高的计算效率,在小型数据集上运行速度较快。
2 RapidMiner 数据挖掘过程
2.1 数据预处理
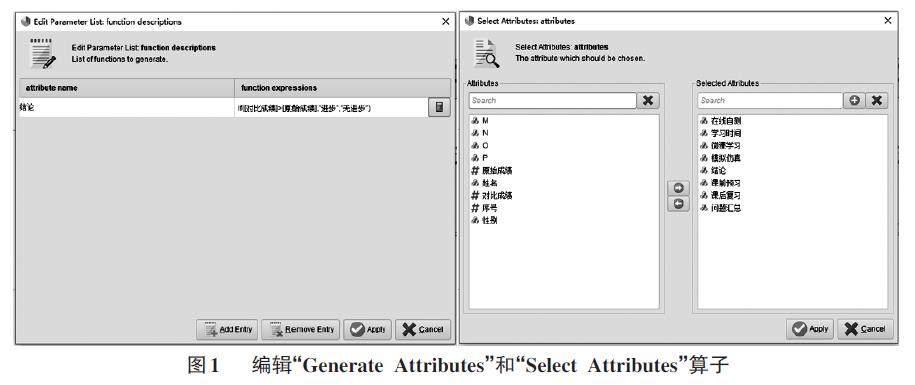
数据预处理是数据挖掘中的重要步骤,主要包括数据清洗、数据集成、数据变换、和数据规约。数据清洗可以将数据集中的异常数据,如空值、重复值、缺失值等进行处理;数据集成可以将多个数据集整合成一个数据集;数据变换可以将数据进行离散化、标准化等转换;数据规约可以对大数据集进行精简,保证数据完整性的基础上形成规模更小的新数据集。在学习策略数据集中,数据较为规范,只需对数据进行清洗、变换即可满足算法要求。具体操作如下:1) 导入数据。打开RapidMiner,新建一个空白流程(Process) ,点击存储区域(Repository) 中的“Import Data”按钮,选择学习策略数据集导入存储区。2) 生成新属性列。将数据集拖入到流程中,选择算法区(Operators) 中的生成属性“Generate Attributes”算子,将数据集out端连接“Generate Attributes”算子的exa端。打开“GenerateAttributes”算子的编辑参数列表对话框,在生成的新列中输入“结论”,函数表达式中输入“if([对比成绩]>[原始成绩],"进步","无进步")”。通过“Generate Attri?butes”算子生成的新属性列,能将两次成绩对比并进行变换,生成“进步”和“无进步”两类,实现成绩数据的离散化。3) 去除无用列。在算法区中拖入“SelectAttributes”算子到流程中,连接“Generate Attributes”和“Select Attributes”算子的exa 端。双击“Select Attri?butes”算子打开选择属性对话框,在左侧属性列表中选择需要到的属性至右侧列表。算子的编辑,如图1 所示。
2.2 模型建立
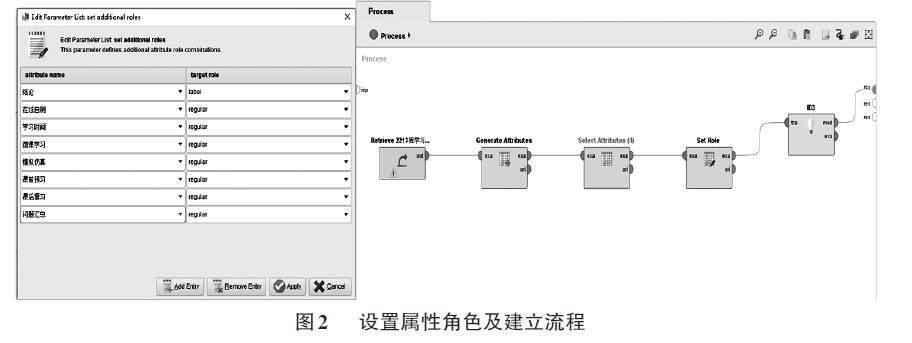
数据预处理完成之后,进入到建模阶段。本实验采用的ID3算法的决策树模型,按照分类准则(如信息增益、基尼指数等)从数据集所有可选属性列中选择一个最佳的属性,作为当前节点,将数据集分成多个子集,对于每个子集,重复上述步骤直至满足终止条件。决策树模型与一般统计方法中的分类模型的主要区别在于决策树的分类是基于逻辑的分类,而一般统计方法的分类模型是基于非逻辑的分类[4]。在决策树模型中通常存在两类变量:一类是自变量(也称特征或属性),另一是因变量(也称目标变量),通过自变量的分类来预测结果。在RapidMiner 算法区中的“Attri?butes”和“Trees”列表中,分别找到“set role”算子和“ID3”算子并拖入至流程中,连接“Select Attributes”算子和“set role”算子的exa 端、“set role”算子的exa端和“ID3”算子的tra 端,最后将“ID3”算子的mod 端连接res 输出端。“set role”算子用来设置数据集中属性的角色,在编辑参数列表中,将“ 在线自测”“学习时间”“微课学习”等属性设置为自变量“regular”角色,将“结论”设置为因变量“label”角色,并建立流程,如图2 所示。
2.3 模型分析及评估
模型建立完成后,点击RapidMiner 工具栏中的“运行”按钮,决策树模型开始构建,并在“Re?sults”面板中输出结果。在决策树中,包含了各个节点以及判断条件,如图3所示。图中每一个矩形方框表示一个节点,箭头表示分支,叶子节点表示预测结果。可以看出,决策树的根节点为“课前预习”,根据“已预习”和“未预习”进行分支,“模拟仿真”和“问题汇总”分别作为它的子节点,然后再根据条件进行分支直到叶子节点。从决策树的根节点出发,沿着某个箭头逐步走到叶子节点,即为该条分支的预测结果。例如,已进行“课前预习”已进行“模拟仿真”的学生容易进步;已进行“课前预习”未进行“模拟仿真”但“学习时间”大于2小时的学生容易进步。
模型评估就是评估算法模型对挖掘分析和预测结果的准确性影响,根据预测结果是否在置信区间、误差是否可以接受,判定结果是否达到目的[5]。在本实验中,由于学习策略数据集来自一个班30名学生的数据,数据规模较小、数据分布不均匀、容易产生过拟合的情况,因此采用交叉验证的方式对模型进行评估,并连接Performance算子查看模型的性能指标,如准确率、精确率、召回率等。在RapidMiner算法区中的验证(validation) 列表下找到“Cross validation”算子并拖入流程中,“Cross validation”算子exa端连接预处理后的数据集,per端连接res输出端。双击“Cross validation”算子进入子流程配置,在子流程的训练集(Training) 和测试集(Testing) 中分别添加“ID3”“Apply Model”“Perfor?mance”算子并进行连接,如图4所示。
其中,左侧决策树模型通过训练样本进行训练,右侧是对模型进行测试,并进行评估。在训练过程中“Apply Model”算子将训练好的模型应用到测试样本中进行预测,并用“Performance”算子评估模型性能。为了更准确地评估模型,设置“Cross validation”的折数(number of folds) 为10,即数据集分成10个部分,其中9个部分用于训练模型,另一个部分用于测试模型,每次使用不同部分重复10次测试。点击“运行”,评估结果如图5所示。从图中看到,对“进步”预测的准确率约为82.35%,对“无进步”预测的准确率为84.62%,平均准确率为83.33%。
3 预测结果对学习策略的指导
预测结果可以揭示哪些学习策略对成绩的提升相关性较高、哪些策略对成绩提升无帮助。基于这些结果,教师可以向学生推荐使用效果良好的学习策略,鼓励学生积极进行课前复习、参与模拟仿真实验、有意识地进行问题汇总、合理规划学习时间等。通过定期分析预测结果,教师可以了解学生的学习情况是否符合预期,是否需要调整学习策略。要注意的是,预测结果只是一种参考,能帮助教师和学生更好地了解学习情况,但不能完全取代教师和学生的判断和决策。在实际工作中,仍需要综合考虑其他因素制定适合学生特点的学习策略。
4 结束语
在本次实验中,采用了RapidMiner 决策树模型对学生学习策略进行数据挖掘和建模预测分析,使用交叉验证方法进行评估,得到了平均准确率约为83.33% 的预测结果。这表明决策树模型在学生学习策略预测方面具有一定的可靠性和有效性。当然,预测结果只是学生学习策略制定的辅助工具,教师需要从多方面综合考虑,制定最适合的学习策略,提升学生成绩和学习效果。
参考文献:
[1] 李冠利.基于RapidMiner数据挖掘技术的NCRE成绩预测分析[J].南京广播电视大学学报,2018(4):80-82.
[2] 吴金桃,丁鑫龙.基于ID3决策树算法高校经管类虚拟仿真实验平台[J].佳木斯大学学报(自然科学版),2023,41(6):48-51.
[3] 陈韬宇,安海燕,陈杰.基于ID3算法对农民工城市融入影响因素分析[J].软件工程,2023,26(10):45-48.
[4] 马月.数据挖掘技术在教育信息化中的应用研究[D].西安:西安邮电大学,2014:38.
[5] 刘文开,焦飞.基于RapidMiner的校园一卡通数据挖掘与预测[J].电脑知识与技术,2021,17(28):34-36.
【通联编辑:闻翔军】
