基于Spark 的商品推荐系统的设计与实现
2024-06-26胡绍方高光
胡绍方 高光


摘要:随着电商平台的普及,商品推荐系统实现了用户的个性化推荐,帮助用户过滤掉无用的信息,提供更感兴趣的商品,既提升了用户体验,也增加了平台收益,实现了用户和平台的双赢。文章归纳了推荐算法和推荐系统研究中的关键技术,并利用Spark技术完成推荐系统的设计。该推荐系统包括离线推荐和实时推荐两大部分。离线推荐为用户提供离线推荐、最近热门商品、历史热门商品和相似商品的推荐结果;实时推荐根据用户的实时评分行为给出实时的推荐结果。系统推荐结果表现良好。
关键词:Spark;协同过滤算法;隐语义模型;推荐系统
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)14-0001-03 开放科学(资源服务)标识码(OSID) :
0 引言
在大数据时代下,各领域的数据量呈现爆炸式增长。在信息接收过程中,更多的是充斥着无用的信息,电商购物时也会遇到这个问题。面对海量的商品数据,如何高效准确地把用户感兴趣的商品推送到用户面前,大数据推荐系统的研究显得尤为重要。
1 相关算法基础
1.1 推荐算法
1.1.1 基于内容的推荐算法
该算法通过提取用户历史购买物品的特征信息,提取商品标签或描述文本中的关键词作为特征信息,发现物品或内容的相关性,根据特征信息匹配相似内容的商品,提供推荐结果[1]。
1.1.2 基于协同过滤的推荐算法
1) 基于用户的协同过滤推荐算法:根据用户历史行为数据,例如搜索、购买、评分数据,进行归纳分析,计算用户之间的相似度矩阵,根据与用户相似度高的其他用户的历史评分记录,找出喜好程度高的物品进行推荐[2]。
2) 基于物品的协同过滤推荐算法:其主要是计算物品之间的相似度矩阵。根据用户对商品的历史评分找出喜好程度高的商品,找到与它相似的其他物品,向用户推荐。
3) 基于模型的协同过滤算法:使用一些机器学习算法进行训练,对每一个用户建立模型,来预测用户对物品的喜爱程度。在大数据的情况下,当用户与商品成千上万时,矩阵会很大,而且会有许多空白,计算机处理这样的矩阵时,会浪费计算资源,且浪费时间,这就是稀疏矩阵的问题。
1.1.3 基于深度学习的推荐算法
ALS(Alternating Least Squares) 算法虽然解决了稀疏矩阵的问题,但仍存在“冷启动”的问题,即当系统中用户的数据较少时,无法准确地判断新用户的偏好[3]。针对这种问题,就有了基于深度学习的推荐算法。基于CNN(Convolutional Neural Network) 的深度学习方法分析文本特征进行分类,因为使用了深度学习的模型进行自动文本特征提取,相对于传统的文本分类,文本分类的速度更快且效果更优[4]。
1.2 隐语义模型
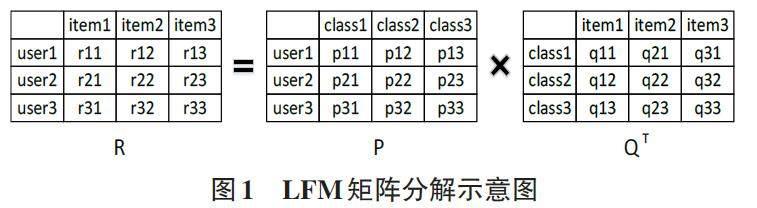
基于隐语义模型(Latent Factor Model,LFM) 的推荐算法是一种源于基于模型的推荐算法的思想[5]。LFM是通过降维把原先的用户物品评分矩阵分为两个矩阵,一个表示用户潜在关联的维度,一个表示物品潜在关联的维度,每一个维度对应着一个隐性特征,这种隐性特征难以清楚地解释,但可以作为一种用户偏好和物品特征的隐含语义去描述。LFM矩阵分解示意图如图1所示。
假设一个用户物品评分的m×n矩阵为R,基于隐语义矩阵的分解是要找出两个矩阵的乘积R?可以和矩阵R来近似,如公式(1) 所示:
上式中,Puk表示用户对隐含因子k 的关联度,Qki表示物品对隐含因子k 的关联度。为了更好地理解,以用户user1为例,user1对隐含因子k1、k2、k3的关联度用P11、P12、P13来表示,物品item1对隐含因子k1、k2、k3的关联度用Q11、Q12、Q13来表示。user1对item1的偏好值如公式(2) 所示:
隐语义模型是根据这种联系分析建立用户偏好特征模型,形成推荐结果[6]。
2 系统体系设计
2.1 系统业务设计
基于Spark的商品推荐系统包含了离线部分和实时部分,离线推荐部分包括统计推荐、基于内容的推荐和基于物品的协同过滤推荐,实时推荐部分则使用基于模型的推荐算法。该系统实现了前端应用、后台服务、算法设计实现和平台部署的业务。
用户可视化部分使用AngularJS2进行实现,通过可视化为用户提供系统的前端交互和数据展示。综合业务服务部分主要通过Spring进行构建,负责从数据库加载或写入数据,也负责埋点对评分数据采集日志,为离线推荐和实时推荐提供数据支持。系统的业务流程图如图2所示。
2.2 系统数据设计
2.2.1 系统初始化部分
通过Spark SQL 将数据集数据加载到MongoDB 中。数据来自经过修改的真实中文亚马逊电商数据集,该数据集分为商品数据表和评分数据表,分别包含1 000个商品和44 852条评分记录。每个商品包含商品ID、商品名称、商品所属类别、商品图片的URL 和商品的用户评价标签,每条评分记录包含用户ID、商品ID、商品评分分值和评分时间。
2.2.2 离线部分
离线统计服务从数据库加载数据,统计商品的评分数据,根据商品的评分个数多少,结果可作为历史热门推荐结果;按时间顺序统计商品的评分个数,结果作为最近热门的商品推荐[7]。离线推荐服务从数据库中加载数据,使用基于ALS的隐语义模型协同过滤推荐算法,获得用户的离线推荐结果,同时也计算出商品相似度矩阵,可以为实时推荐做准备。
2.2.3 实时部分
综合业务服务会埋点记录下用户对商品的打分数据,存入日志文件。Flume监听日志文件,将日志信息更新到Kafka队列,Kafka Stream程序会对所收集的日志信息进行过滤处理,将格式化后的数据流发送给另一个Kafka 队列。Spark Streaming 通过监听这个Kafka队列,将收集的评分数据流存储在Redis中,并进行实时推荐算法的计算,将得到的实时推荐结果合并到数据库中原有的推荐结果。
2.2.4 综合业务系统部分
将数据库中推荐结果进行展示。将用户在页面上的操作记录进数据库中,会将数据传输到Redis缓存[8],同时也将埋点采集的评分数据传输到Tomcat的日志中,为实时推荐部分服务。
3 系统实现
3.1 首页推荐
登录进入系统主界面中的4个推荐部分。顶栏中有快速链接可以进行首页以及各个推荐结果页面的跳转,右上方还可进行账号的退出操作。首页主界面有实时推荐、离线推荐、最近热门商品和好物推荐4个模块。
实时推荐:首先连接数据库,加载商品相似度矩阵,创建Kafka和Kafka Stream,对Kafka Stream进行处理,产生评分数据流,经过Spark Streaming的处理,从Redis中取出用户最近的n次评分,计算每个备选商品的推荐优先级,最后将数据写回数据库。
离线推荐:首先连接数据库,加载商品评分表,使用MLlib的ALS算法训练隐语义模型,获取预测评分矩阵,根据该矩阵得到用户的推荐列表,利用商品的特征向量,两两商品计算余弦相似度得出商品的相似度矩阵,最后将数据写回数据库。
最近热门商品和好物推荐:连接数据库,加载商品评分表,Spark SQL做不同的统计,统计评分个数后降序排序可得到好物推荐的结果,将日期格式化后,先加上一个按日期的降序排序后再排序可得到最近热门商品的结果,统计商品的评分后计算商品的平均分,将商品平均分表写回数据库。
3.2 商品相似推荐
商品详情页面的主界面上有两个部分,第一部分是该商品的相关信息。用户可以在这里给商品进行打分,表示用户对该商品的喜爱程度。商品的标签是根据大部分买家的评价所产生的,代表着这个商品的特征属性,这些标签可以作为基于内容推荐中商品的内容特征向量。第二部分是商品相似推荐,分为两块,用于展示该商品协同过滤推荐结果和内容推荐结果,实现流程如下:
商品评分:在Spring MVC的Service层中设计评分方法来给Controller响应前端发送来的商品评分请求,Service层会连接MongoDB,将评分数据(用户ID、商品ID、评分和时间戳)保存或更新到MongoDB和Redis数据库中。在响应评分请求后,会将该记录写入日志文件中。
基于内容的相似推荐:先用空格将标签进行分词,定义一个HashingTF工具计算词汇频次,定义一个IDF计算TF-IDF,训练出IDF模型,得出特征向量,将数据进行转换,两两商品配对计算余弦相似度得出商品的相似度矩阵,计算出推荐列表,结果写回数据库中。
基于物品的协同过滤推荐:首先统计商品的评分个数,将评分个数通过商品ID连接到原来的评分表上,将评分表按照用户ID进行两两配对,统计两个商品被同一个用户评分的次数,对两个商品做group by,统计用户ID的数量,即对两个商品同时评分的人数。之后计算商品的相似度矩阵,得到推荐列表,将结果写回数据库。
结果分析:可以直观地看到基于内容的推荐结果数量较少,基于物品的协同过滤推荐的推荐结果较多。这是因为商品的数据集规模较小,在计算标签词汇的频次时,特征数量会比较少,所以在进行商品标签的特征向量提取后,进行商品推荐时,对商品的特征向量的相似判断上要求会比较苛刻;而基于物品的协同过滤推荐,推荐结果依据的是购买商品的用户群体,当两个用户群体拥有比较高的相似度时,两个商品的相似度也可能会比较高,根据这个思路进行推荐,所以基于物品的协同过滤推荐结果数量会比较多。
4 总结
推荐系统是当下热门的一个研究方向,推荐系统的研究从2012年开始起步,十多年间,推荐系统逐渐完善、丰富、多样化。对电商企业来说,一个良好的推荐系统能为电商企业和用户带来切实的收益,企业能增加销售额,用户能获得愉快的购物体验。基于Spark的商品推荐系统对电商平台上推荐系统的应用进行了模拟,通过部署在Tomcat的综合业务服务,连接前端和后台,分别进行了离线推荐和实时推荐,满足电商平台不同需求的商品推荐。
参考文献:
[1] 马小添.基于Hadoop的推荐系统设计与实现[D].成都:电子科技大学,2020.
[2] 焦健.基于Spark的协同过滤推荐算法研究[J].电脑编程技巧与维护,2020(3):40-41,73.
[3] 张明敏.基于Spark平台的协同过滤推荐算法的研究与实现[D].南京:南京理工大学,2015.
[4] 刘建国,周涛,郭强,等.个性化推荐系统评价方法综述[J].复杂系统与复杂性科学,2009,6(3):1-10.
[5] SAVESKI M,MANTRACH A.Item cold-start recommendations:learning local collective embeddings[C]//Proceedings of the 8th ACM Conference on Recommender systems.Foster City,Silicon Valley California USA.ACM,2014.
[6] KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences[J]. arXiv preprint arXiv:1404.2188,2014.
[7] 徐启东.基于隐语义模型的个性化推荐系统研究[D].广州:广东工业大学,2019.
[8] 薛琳兰.基于隐语义模型的电商推荐系统的设计与实现[J].数字通信世界,2020(7):99,229.
【通联编辑:谢媛媛】
基金项目:周口师范学院应用型课程项目(项目编号:YYKC-2024027) ;周口师范学院课程思政教育教学改革研究项目
