多层内部语义表示增强的深度文本聚类模型
2024-06-17任丽娜姚茂宣
任丽娜 姚茂宣


摘 要:
为学习更丰富的语义表示以提升聚类效果,文章提出一种多层内部语义表示增强的深度文本聚类(Deep Document Clustering via Multi\|layer Enhanced Internal Semantic Representation, DCISR)模型。首先,设计了一种语义融合策略,将其不同层次的外部结构语义表示逐层融入内部语义表示中。其次,充分利用编码层和解码层对语义补充的作用进行内部语义表示的补充增强。最后,设计了一种三重自监督机制,以监督模型参数更新。实验结果表明,该模型在4个真实文本数据集上的聚类性能均高于对比模型,验证了模型的有效性,可为未来开展相关工作提供参考。
关键词:文本聚类;深度聚类;自编码器;语义表示;图卷积网络
中图分类号:TP391 文献标志码:A
0 引言(Introduction)
近年来,深度文本聚类任务受到普遍关注,成为一个研究热点[1]。人们对文本数据的认识也从基本的文本特征发展为深度的文本语义。随着互联网的快速发展,文本数据的语义表达逐步从文本自身内部单一语义表示向立体的内部和外部全方面语义表达发展。内部文本语义表示传统的文本篇章自身内容语义,外部文本语义表示文本除文本篇章自身内部内容语义之外的外部结构语义。这些内部和外部语义表示为文本聚类带来了新的机遇和挑战。因此,充分考虑内部和外部语义表示,进而准确、快速地从文本中提取出更多有用的语义特征信息尤为重要。
实际上,由于实际文本数据是由文字内容组成的,而其外部结构中的关联文本存在噪声问题,因此文本内部语义表示包含的重要信息要比具有大量噪声的外部结构语义表示丰富。现有深度聚类方法[2\|3]大多没有考虑到这一点,大多利用数据内部语义表示在编码层增强外部结构语义表示,导致文本语义学习不足,进而影响聚类效果。此外,现有方法大多忽略了解码器在语义补足上的作用,导致对外部结构语义信息的指导不足,影响了文本聚类效果。
针对上述问题,本文提出了一种多层内部语义表示增强的深度文本聚类(DCISR)模型,利用多层外部结构语义补充增强内部内容语义表示,以达到文本语义表示学习与聚类划分的联合优化。本文在4个公开文本数据集上进行了一系列的实验,实验结果表明,本文提出的方法相较于其他模型,聚类效果均有明显提升,验证了模型的合理性。
1 相关工作(Related work)
1.1 基于内部语义表示的深度聚类算法
基于内部语义表示的深度聚类算法使用学习到的数据自身内部语义表示进行类簇的划分。YANG等[4]于2017年提出了深度聚类网络(DCN)模型,该模型采用自编码器(AE)学习数据的内部语义表示,然后利用传统的K\|means[5]方法进行聚类。XIE等[6]于2016年提出了深度嵌入聚类(DEC)模型,该模型用KL散度(Kullback\|Leibler Divergence)替代传统的K\|means聚类方法,将聚类与内部语义表示学习相结合。在DEC模型的基础上,GUO等[7]于2017年提出了深度嵌入聚类(IDEC)模型,该模型通过增加数据重构损失对表示进行微调。上述深度聚类模型仅利用了数据自身的内部语义表示,但未考虑数据外部的语义信息对学习数据语义表示的影响。
1.2 基于外部结构语义表示的深度聚类算法
近年来,随着深度神经网络的迅猛发展,图卷积神经网络(GCN)在学习数据深度结构语义表示方面表现优异,以GCN为基础的深度聚类方法[1\|3,8\|10]成功地利用GCN模型学习数据的结构语义表示,取得了出色的聚类效果。例如,KIPF等[8]于2018年提出了图自编码器(GAE)模型和图变分自编码器(VGAE)模型,这两个模型分别利用自动编码器和变分自动编码器的思想,使用两层GCN学习数据外部结构语义表示。为进一步增强外部结构语义表示的学习,BO等[2]于2020年提出了图深度聚类网络(SDCN)模型,该模型利用自动编码器学习到的内部语义表示补充增强了GCN学习到的外部语义表示,以学习更优的外部结构语义表示。PENG等[3]于2021年提出了注意力驱动的图聚类网络(AGCN)模型,该模型利用一个自适应融合模块动态融合数据内部语义表示和外部语义表示,以增强外部结构语义表示的学习。马胜位等[1]于2022年提出了一种多层语义融合的结构化深度文本聚类模型(SDCMS),该模型在SDCN的基础上通过在模型的所有网络层利用自动编码器学习到的内部语义表示逐层补充增强GCN学习到的外部语义表示。
综上所述,尽管以上方法取得了较好的聚类效果,但它们未考虑实际文本数据中内部语义与外部语义所具有的信息重要性不同的问题,也未考虑解码器在文本语义补足上的作用。
2 DCISR模型(DCISR model)
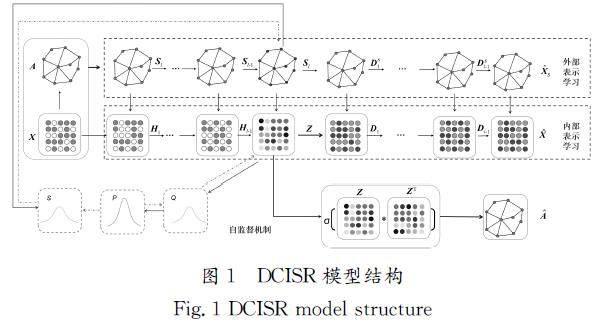
本文提出的DCISR模型的总体框架由3个模块组成:文本外部语义表示学习模块、文本内部语义表示学习模块和文本聚类模块。DCISR模型结构如图1所示,文本外部语义表示学习模块用于学习文本的外部结构语义表示,文本内部语义表示学习模块用于学习通过融合了外部语义表示而增强的内部语义表示,文本聚类模块用于学习文本的类簇划分。
2.1 外部语义表示学习模块
图卷积神经网络在结构语义学习方面的表现优异,为学习不同层次的文本外部结构语义信息,DCISR模型在外部语义表示学习模块采用多层图卷积网络学习文本的外部结构语义表示,具体可以分为编码层和解码层,其中编码层网络公式如下所示:
2.2 内部语义表示学习模块
DCISR模型在内部语义表示学习模块使用自编码器学习文本不同层次的内部语义表示,其中编码层网络公式如下所示:
[WTHX]H[WTBX]l=φe([WTHX]W[WTBX]le[WTHX]H[WTBX]l-1+[WTHX]b[WTBX]le)[JZ)][JY](7)
其中:φe是激活函数,[WTHX]W[WTBX]le和[WTHX]b[WTBX]le分别为权重矩阵和偏置矩阵。值得注意的是,该模块编码层第1层的输入为文本数据[WTHX]X[WTBX],第L层输出的低维内部语义表示[WTHX]Z[WTBX]。解码层网络公式如下所示:
[WTHX]D[WTBX]l=φd([WTHX]W[WTBX]ld[WTHX]D[WTBX]l-1+[WTHX]b[WTBX]ld)[JZ)][JY](8)
其中:φd是激活函数,[WTHX]W[WTBX]ld和[WTHX]b[WTBX]ld分别为权重矩阵和偏置矩阵。该模块解码层第1层的输入为编码层的输出[WTHX]Z[WTBX],解码层第L层的输出为重构文本数据[WTHX][AKX^][WTBX]d。
本模块设计了一种语义融合策略,其将不同层次的外部结构语义表示逐层融入内部语义表示中用以充分增强文本内部语义表示。其中,编码层具体的融合策略公式如下所示:
[WTHX]H[WTBX]′[KG-1mm]l-1=λ1[WTHX]H[WTBX]l-1+(1-λ1)[WTHX]S[WTBX]l-1[JZ)][JY](9)
其中,λ1为编码层内部语义表示和外部语义表示的融合控制参数。以此为基础,原编码层可以变更如下:
[WTHX]H[WTBX]l=φ([WTHX]W[WTBX]le[WTHX]H[WTBX]′[KG-1mm]l-1+[WTHX]b[WTBX]le)[JZ)][JY](10)
解码层的融合策略公式如下所示:
[WTHX]D[WTBX]′[KG-1mm]l-1=λ2[WTHX]D[WTBX]l-1+(1-λ2)[WTHX]D[WTBX]sl-1[JZ)][JY](11)
其中,λ2为解码层内部语义表示和外部语义表示的融合控制参数,用以平衡两种表示的学习。以此为基础,原解码层可以变更如下:
[WTHX]D[WTBX]l=φd([WTHX]W[WTBX]ld[WTHX]D[WTBX]′[KG-1mm]l-1+[WTHX]b[WTBX]ld)[JZ)][JY](12)
因此,最后一层重构的文本数据可以表示如下:
[WTHX][AKX^6][WTBX]=λ2[WTHX][AKX^6][WTBX]d+(1-λ2)[WTHX][AKX^6][WTBX]s[JZ)][JY](13)
通过内部语义学习模块,可以将不同层次的外部结构语义表示逐层融入内部语义表示中,充分利用编码层和解码层对语义补充的作用进行内部语义表示的补充增强。
2.3 文本聚类模块
为了联合学习文本语义表示和划分文本类簇,本模块设计了一种三重自监督机制,用于监督模型参数更新。该自监督机制由文本内外部语义表示重构损失、内部和外部语义表示低维语义空间分布一致性损失构成。其中,文本内部和外部语义表示重构损失公式如下所示:
3 实验与分析(Experiment and analysis)
3.1 实验数据
为验证本文提出的DCISR模型的有效性,本文选择了两类共计4个通用的公开真实文本数据集进行实验分析。一类为带有共同作者、共同引用文献等关系结构图的文本数据集(Citeseer、Cora),另一类为KNN构图的文本数据集(Abstract、BBC)。文本数据集如表1所示。
(1)Abstract[11]:由4 306篇论文摘要构成。该数据集可分为信息通信、数据库和图形3类。
(2)BBC[1]:由2 225篇BBC(British Broadcasting Corporation)新闻网站的文本构成,该数据集可分为商业、娱乐、政治、科技、运动5类。
(3)Citeseer[2]:由3 327篇会议论文构成,论文间存在引用关系。该数据集可分为Agents、AI、DB、IR、ML、HCI六类。
(4)Cora[12]:由2 708篇机器学习论文构成,论文间存在引用关系。该数据集可分为基于案例、遗传算法、神经网络、概率方法、强化学习、规则学习、理论7类。
3.2 对比方法
为验证DCISR模型的性能,本文将其与3类共计8个聚类方法进行了对比分析,分别包括传统聚类方法(K\|means)、深度聚类方法(AE、DEC、IDEC)和基于增强语义表示的聚类方法(GAE、SDCN、AGCN、SDCMS)。
3.3 评价指标[HJ1.7mm]
为更好地评估聚类性能,本文选用聚类精度(ACC)、正则互信息量(NMI)与调整兰德系数(ARI)三个常用的聚类指标。ACC、NMI、ARI三个聚类指标的取值范围均为[0,1],聚类指标的数值越大,其聚类效果越好。
3.4 参数设置
为更好地进行实验效果的对比,本文的内部和外部语义学习模块维度设置与DEC模型的设置相同,具体为d\|500\|500\|2000\|10\|2000\|500\|500\|d,其中d是输入的文本数据的维度。实验使用Ranger优化器进行优化,学习率设置为1e-4。参数λ1和λ2分别设置为0.5、0.5,β、β1和β2分别设置为1、0.1、0.01,ν设置为1。模型迭代次数设置为3 000次。
3.5 对比实验结果分析
为验证本文提出的DCISR模型的有效性,本实验将DCISR模型与全部对比模型分别在全部4个文本数据集上进行对比,对比实验结果如表2所示。
通过表2可以得到以下结论。
(1)本文提出的DCISR模型在全部数据集上均取得了最优聚类性能。相较于其他对比模型,DCISR模型在3个聚类指标上均有明显的提升,特别是在Cora数据集上,DCISR模型相较于最优的对比模型在ACC、NMI、ARI上分别提升了12.76%、21.97%、29.46%,其原因是DCISR模型在考虑实际文本数据中内部语义与外部语义所具有的信息重要性不同的同时,充分利用编码层和解码层对语义补充的作用,提升了文本聚类效果。
(2)基于外部结构语义表示的深度聚类方法的聚类结果普遍高于基于内部语义表示的深度聚类方法,其原因为基于外部结构语义表示的深度聚类方法通过GCN学习到文本外部结构语义表示时,既考虑了文本的外部图结构信息,又考虑了文本自身特征。实验结果证明了增强文本语义表示对最终文本聚类效果提升的作用。
(3)对比学习增强的结构语义表示的SDCMS模型和学习增强的内部语义表示的DCISR模型,其结果可以证明实际文本数据中内部语义与外部语义所具有的信息重要性不同,在实际文本数据中内部语义表示具有更丰富的、有价值的语义信息。对比充分利用了编码层和解码层补充语义表示的SDCMS、DCISR模型与仅利用了编码层补充语义表示的SDCN、AGCN模型,其结果可以证明解码层对语义补充的作用。由此可以进一步验证DCISR模型的有效性。
3.6 消融实验结果分析
DCISR模型主要设计了内部语义表示学习模块、外部语义表示模块和文本聚类模块三大模块,用以解决现有方法没有考虑到实际文本数据中内部内容语义表示比外部结构语义表示具有更多重要信息的问题,以及忽略了解码器在语义补足上发挥的作用。为了探究3个模块的有效性,本文设置了以下消融模型。
(1)DCISR\|H:在DCISR模型的基础上,去除内部语义表示学习模块。
(2)DCISR\|S:在DCISR模型的基础上,去除外部语义表示学习模块,此时模型等同于IDEC。
(3)DCISR\|C:在DCISR模型的基础上,去除文本聚类模块,利用K\|means代替本文的自监督损失函数。
消融实验结果如表3所示,模型DCISR\|H与DCISR\|S相比,在4个数据集上的各评价指标均较低,证明实际文本数据中内部内容语义表示比外部结构语义表示具有更多重要信息,通过模型学习到的内部语义表示中的有用信息多于外部语义表示;从DCISR与DCISR\|C的对比结果可看出,本文在文本聚类模块提出的自监督机制可以有效监督模型的参数更新,从而获得更优的聚类效果;从DCISR与DCISR\|H和DCISR\|S模型的对比结果可以看出,两个模块的融合可以解决现有方法没有考虑到实际文本数据中内部内容语义表示比外部结构语义表示具有更多重要信息的问题,以及忽略了解码器在语义补足上发挥的作用。
3.7 编码层和解码层对语义补充作用的分析
DCISR模型主要基于多层内部语义表示增强方法解决如何补充学习更多的文本语义表示的问题。因此,为了探究编码层和解码层对语义补充的作用,本文设置了以下消融模型。
(1)DCISR\|Sen:在DCISR模型的基础上,去除外部语义表示学习模块中的编码层部分对内部语义表示的补充增强,只在解码层逐层进行内部语义表示补充增强。
(2)DCISR\|Sde:在DCISR模型的基础上,去除外部语义表示学习模块中的解码层部分对内部语义表示的补充增强,只在编码层逐层进行内部语义表示补充增强。
(3)DCISR\|S:在DCISR模型的基础上,去除外部语义表示学习模块。
本实验随机选取Citeseer数据集进行实验分析,Citeseer数据集的实验结果如图2所示。从图2可以发现,模型DCISR\|Sde与DCISR\|Sen相比于DCISR\|S,在Citeseer数据集上的各评价指标均有所提升,证明编码层和解码层对补充文本语义信息有所帮助;模型DCISR相比模型DCISR\|Sde与DCISR\|Sen,在Citeseer数据集上的各评价指标均有明显提升,证明模型融合利用了编码层和解码层对语义补充所起到的作用,学习到更加丰富的语义信息,从而获得更优的文本聚类效果。
3.8 聚类可视化结果分析
基于t\|SNE(t\|Distributed Stochastic Neighbor Embedding)方法,本文在Cora文本数据集上对原始数据和DCISR模型进行2D可视化,以更直观地展示模型的聚类效果。图3展示了具体的2D可视化结果,其中图3(a)为原始文本分布情况;图3(b)为DCISR模型的聚类情况。
从图3可以发现,通过将不同层次的外部结构语义表示逐层融入内部语义表示,利用补充增强后的内部语义表示进行聚类,Cora数据集相比于原始数据集有了明显的类簇结构,各类簇内部样本更加稠密,簇与簇之间的距离更大,类簇分类更明显,从而证明了本模型的有效性。
4 结论(Conclusion)
为学习更丰富的语义表示以提升聚类效果,本文提出了一种多层内部语义表示增强的深度文本聚类(DCISR)模型。该模型利用多层外部结构语义补充增强内部内容语义,实现了文本语义表示学习与聚类划分的联合优化。实验结果表明,DCISR方法在性能上优于当前已有的多种主流深度文本聚类算法,证明该模型在考虑实际文本数据中内部与外部语义所具有的信息重要性不同的同时,充分利用了编码层和解码层对语义补充起到的作用,可为未来开展相关工作提供参考。
[LL] 参考文献(References)[HJ1.7mm]
[1] 马胜位,黄瑞章,任丽娜,等. 基于多层语义融合的结构化深度文本聚类模型[J]. 计算机应用,2023,43(8):2364\|2369.
[2] BO D Y,WANG X,SHI C,et al. Structural deep clustering network[C]∥ACM. Proceedings of The Web Conference 2020. New York:ACM,2020:1400\|1410.
[3] PENG Z H,LIU H,JIA Y H,et al. Attention\|driven graph clustering network[C]∥ACM. Proceedings of the 29th ACM International Conference on Multimedia. New York:ACM,2021:935\|943.
[4] YANG B,FU X,SIDIROPOULOS N D,et al. Towards K\|means\|friendly spaces:simultaneous deep learning and clustering[C]∥ACM. Proceedings of the 34th International Conference on Machine Learning \| Volume 70. New York:ACM,2017:3861\|3870.
[5] HARTIGAN J A,WONG M A. Algorithm AS 136:a K\|means clustering algorithm[J]. Applied statistics,1979,28(1):100.
[6] XIE J Y,GIRSHICK R,FARHADI A. Unsupervised deep embedding for clustering analysis[C]∥ACM. Proceedings of the 33rd International Conference on International Conference on Machine Learning \| Volume 48. New York:ACM,2016:478\|487.
[7] GUO X F,GAO L,LIU X W,et al. Improved deep embedded clustering with local structure preservation[C]∥ACM. Proceedings of the 26th International Joint Conference on Artificial Intelligence. New York:ACM,2017:1753\|1759.
[8]KIPF T N,WELLING M. Variational Graph Auto\|Encoders[J]. Mathematical sciences,2016,1050:21.
[9] REN L N,QIN Y B,CHEN Y P,et al. Deep structural enhanced network for document clustering[J]. Applied intelligence,2023,53(10):12163\|12178.
[10] REN L,QIN Y,CHEN Y,et al. Deep document clustering via adaptive hybrid representation learning[J]. Knowledge\|based systems,2023,281:111058.
[11] BAI R N,HUANG R Z,CHEN Y P,et al. Deep multi\|view document clustering with enhanced semantic embedding[J]. Information sciences,2021,564:273\|287.
[12] CUI G Q,ZHOU J,YANG C,et al. Adaptive graph encoder for attributed graph embedding[C]∥ACM. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York:ACM,2020:976\|985.
作者简介:
任丽娜(1987\|),女,博士生,讲师。研究领域:人工智能,文本挖掘,机器学习。
姚茂宣(1986\|),男,硕士,信息系统项目管理师。研究领域:数据挖掘,文本挖掘,机器学习和软件开发。
