网络故障预测算法的研究与应用
2024-05-31徐建伟
徐建伟
(中海油信息科技有限公司湛江分公司,广东 湛江 524000)
0 引言
随着通信网络的不断发展,网络可靠性和故障预测变得越来越重要。故障的发生会对用户造成严重影响,因此提前预测和预防故障变得至关重要。本研究旨在研究不同的网络故障预测技术,提供了一种基于数学方法的模型来评估它们的性能。文章采用了多种模型,包括线性回归、指数回归、支持向量机回归、神经网络等,引入了深度神经网络与自编码器。此外,还使用连续时间马尔可夫链分析来提供对网络可靠性的额外洞察。
1 研究方法
1.1 概述
本文研究了不同的预测技术,利用数学方法制定了各种瞬态分析模型。为了比较这些技术的性能差异,研究使用了标准化均方根误差(Normalized Root Mean Squared Error,NRMSE)来计算误差。NRMSE是一种常用的度量方法,它将各个残差汇总为一个单一的预测准确性指标。NRMSE具有明显的优势,因为它是均方根误差(RMSE)的无量纲形式,允许比较具有不同单位的RMSE,从而提高了实用性[1]。计算NRMSE的方法是:
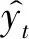
1.2 回归模型
回归模型用作与其他模型进行比较的基准,以评估其他技术的表现。这些模型涉及2个变量:故障发生次数(用n表示)和以小时为单位的故障间隔时间(用τn表示)。数据被分为训练数据(占总数据的3/4)和测试数据(占总数据的1/4)。在MATLAB中,使用曲线拟合工具从训练数据生成了以下方程[2]:
τn=0.003454·n+2.246
指数回归与线性回归类似,但它旨在将数据拟合成具有形式f(x)=a·eb·x的指数函数,而不是线性函数。同样,利用MATLAB中的曲线拟合工具,从训练数据生成的方程是:
τn=2.304·e0.001161·n
1.3 方程
支持向量机(Support Vector Machines,SVM)是一种基于统计学习理论的模型,它将空间中的点映射到一个更高维度的空间,通过超平面来分割这个空间。尽管超平面是线性的,但SVM可以利用该技巧来使用非线性函数,将输入映射到高维度空间[3]。SMATLAB中使用SVM回归,实现了线性epsilon不敏感SVM(E-SVM)回归或L1损失。它训练数据的预测变量和观测响应值。SVM寻找一个函数f(x),它的偏差与每个训练点x的观测响应值yn不超过epsilon值ε,即:
∀n:0≤αn≤C

而二进制粒子群算法[6],速度更新公式不变,含义有所变化。状态空间中的每一个粒子的位置xid值为0或1,选择哪个则取决于vid的大小,即速度为位置取值的概率。分两种情况:① vid较大,xid较大概率取1,较小概率取0;② vid较小,xid较大概率取0,较小概率取1。
其中,G(xn,x)是核函数。在MATLAB中,线性SVM回归的核函数是:
而对于高斯或RBF回归,核函数是:
G(x1,x2)=exp(-|x1-x2|2)
1.4 人工神经网络
人工神经网络(Artificial Neural Networks,ANN)是一种处理单元,接收输入并生成输出。每个神经元分配相关权重给每个输入,可以调整这些权重强度[4]。神经元对输入求和并计算输出,可以数学表示为:
Output=f(i1w1+i2w2+i3w3+…+bias)
本文使用MATLAB中的2个应用程序:神经网络拟合工具和神经网络时间序列工具。这2个应用程序将数据分为70%训练值、15%验证值和15%测试值的集合,每次重复3次,取平均误差。除了不同的神经元数量外,还尝试了2种不同的算法:Levenberg-Marquardt和Bayesian Regulation。结果显示最成功的组合是神经网络具有20个神经元,使用Levenberg-Marquardt进行训练。神经网络拟合工具构建了1个2层的前馈网络,具有1个sigmoid函数作为激活函数[5]。
1.5 深度神经网络
自编码器函数在MATLAB中使用,使用默认的10个神经元的隐藏层。自编码器在测试数据上进行训练,然后转化为神经网络。在测试数据上测试此网络以计算NRMSE和RMSE。自编码器的训练过程基于成本函数的优化,该成本函数测量输入x与其在输出x^处的重建之间的误差。向量x∈D_x被映射到z∈D(1)通过:

其中,上标(2)表示第二层。h(2):Dx→Dx是解码器的传递函数,W(2)∈Dx×D(1)是权重矩阵,b(2)∈Dx是偏置向量。这是一个层的数学表示,但对于自编码器的其他层,数学仍然相同。
1.6 连续时间马尔可夫链分析
连续时间马尔可夫链分析可以提供对蜂窝网络状态的额外洞察,因为它是无记忆的,只有过去故障的关键部分由转移概率捕获,故障间隔时间服从指数分布[6]。
对于连续时间马尔可夫链分析,网络只能存在于2个状态中:健康和次优。故障间隔时间的μ值是1/(均值)。在这种情况下,μ值为0.38625。维护时间的λ值以类似的方式计算,为0.01589。使用这些值,可以计算发生器矩阵Q和速率矩阵R。两状态系统的计算如下:
利用这2个矩阵,可以执行各种瞬态分析。CTMC的行为由Kolmogorov微分方程描述,可以使用生成矩阵Q找到。然后,可以通过P(T)=P(0)×eQ(Γ)来获得概率向量,其中P(0)是初始概率向量。本文采用均匀化方法,因为它导致更高效的计算并具有更高的准确性[7]。使用此方法,可以计算概率向量:
其中,P^是概率转移矩阵,求和可以根据误差公式进行截断:
使用了误差值为0.0001。概率转移矩阵形成了本文中使用的3个性能矩阵的计算基础。第一个是占用时间,通过以下矩阵形式计算:
其中,pij(t)是转移概率矩阵P的元素。
第二个是首次通过时间,这是系统从最佳状态过渡到次优状态所需的预期时间。这使用以下方程:

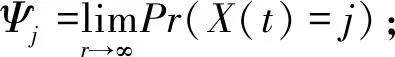
2 结果
模型的结果总结如表1所示。结果表明,除了使用自编码器的深度神经网络外,大多数模型在预测测试数据上的故障间隔时间方面都取得了相对相似的成功。NRMSE显著提高的结果表明,自编码器比所有其他技术都具有更好的故障预测效果。

表1 模型测试结果
CTMC分析提供了整个网络可靠性的关键信息。可以根据新值调整这些分析,计算占用时间、首次故障发生时间和稳态分布的新预期时间[9]。网络从健康状态切换到不健康状态的概率非常高。12小时后,系统处于不健康状态的概率为95%。一天后,次优状态的值保持在0.9605不变。基于这些概率值,制定了一个模型,使用了75%的阈值水平来表示故障发生。模型每隔4小时检查1次,为期1周,预测准确度为27/42,即64.29%。该模型避免了导致最多损害的二型错误。在一个月内(31天),网络平均只会在健康状态下度过1.3天,在次优状态下度过29.7天。这表明,网络需要采取更好的主动方法,以减少故障发生的次数,提高客户的质量。首次通过时间计算为2.589小时,与平均故障间隔时间2.589小时一致,因为CMTC分析基于2个变量都遵循指数分布的事实。在其寿命内,网络只会在健康状态下度过3.95%的时间,而将在次优状态下度过96.05%的时间。这突显了大规模密集化的事实,因此,迫切需要具有在5G蜂窝网络中可靠运行所需的故障预测能力的主动自愈技术,以在订户受到影响之前提前预测网络故障[10]。
3 结语
本研究通过比较不同的网络故障预测技术以及应用数学方法构建的模型,为提前预测和预防网络故障提供了重要的参考。深度神经网络与自编码器在预测效果上表现出色,而线性模型性能较差,突显了网络故障数据的复杂性。此外,连续时间马尔可夫链分析提供了有关网络可靠性的重要信息,强调了需要更主动的方法来减少故障次数。这项研究对于网络运营和维护领域有着重要的实际意义,有助于提高网络的稳定性和用户体验。未来的研究可以进一步改进模型,以更准确地预测网络故障,探索更多先进的预测技术。
