一种改进的小样本医学图像分割算法研究
2024-05-31罗兆林宋亚男徐荣华萧飞鹏
罗兆林,宋亚男,徐荣华,萧飞鹏
(广东工业大学,广东 广州 510006)
0 引言
医学图像分割主要目标是从医学图像中准确地识别和分离出感兴趣的结构或区域,如器官、肿瘤、血管网络等。在手术过程中,准确的分割可以提供实时的导航和可视化引导,让手术更加精准和安全[1]。近年来,随着计算机视觉技术的蓬勃发展,深度卷积神经网络越来越多地应用在医学图像分割领域,分割模型的性能也在不断提高。自从U-Net[2]网络的出现,医学图像分割的网络结构发生显著的变化,从之前的单一分支的卷积神经网络,发展为U型结构的网络。此后对U型结构网络的改进喷涌而出,比如重新设计了跳跃连接的UNet++[3]、使用残差卷积块的R2U-Net[4]、引入了注意力机制的Attention U-Net[5]等。这些对U型网络的改进带来了更高的性能,但它们比以往更需要大量带标签数据去训练[6]。
影像医生需要具备深厚的医学知识,特别在计算机断层扫描技术(Computed Tomography,CT)、核磁共振图像(Magnetic Resonance Imaging,MRI)等三维医学图像上,复杂的三维结构让影像医生标注病灶非常耗时,还有患者数据隐私等伦理问题。这些让医学图像具有数量小、标注成本高的特点。针对小样本特性的医学图像分割研究越发重要[7]。
小样本学习早期主要应用于图像分类任务,其利用模型学习到的先验知识,辅助预测只有少量样本的新类别。随着在小样本学习上的研究发展,小样本学习已经用于计算机视觉的机器学习的方方面面。当前,主流的小样本学习方法主要包括元学习(Meta-learning)、数据增强、迁移学习、度量学习等方法[8]。模型无关元学习(Model-agnostic Meta-learning,MAML)[9],是一种著名的元学习方法。它的目标是让模型学习到一个适应性强的初始化参数,面对新任务时,让模型经过少量数据微调参数,即可在该任务下获得较好的性能。MAML与所使用的模型无关,其能用在所有梯度下降法训练的模型,MAML算法应用在图像分类任务上非常广泛。
目前,利用MAML元学习算法在小样本医学图像分割上的研究较少。因此,本文提出了一种小样本医学图像分割算法,在3D U-Net[10]网络的基础上做出如下改进:(1)对3D U-Net的下采样模块进行改进,把每个3D卷积层的批归一化改进为组归一化,增加多一层3D卷积层,从而增加了网络深度与参数量,有利于结合MAML元学习算法,得到更好的调优初始化模型,其次组归一化能优化网络在小批量训练下的精度。(2)引入了Transferomer模块,丰富网络提取的全局信息。(3)在跳跃连接中引入改进的注意力门模块,增加组归一化有助于确保输入分布大致相似,Sigmoid激活函数更换为ReLU函数,减少计算量以及改善梯度消失问题。(4)利用MAML元学习算法训练模型,增强网络在小样本医学图像数据下的表现。最后,与现有的多个方法进行了实验对比分析,对本文算法的有效性进行验证。
1 总体设计
1.1 模型整体结构
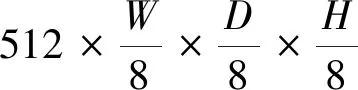

图1 整体网络结构
1.2 下采样模块的改进
3D U-Net的下采样模块使用了2个3D卷积层串联,每个卷积层有一个3×3×3卷积核、批归一化层以及ReLU激活函数,其结构如图2(a)所示,输入Fin经过两层3D卷积层后得到Fout。由于MAML元学习算法是一个训练较优网络初始化参数的过程,适当地加大网络参数,有利于提高网络应用在新的小样本分割任务中的适应能力。文本的下采样模块使用了3个3D卷积层串联,每个卷积层有1个3×3×3卷积核、组归一化层以及ReLU激活函数,上采样网络也是如此,其结构如图2(b)所示。
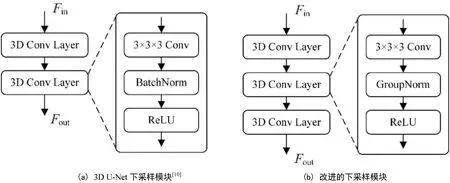
图2 采样模块
批归一化是深度学习中非常有效的一个技术,在各种先进的卷积神经网络都能见到其身影。批归一化主要在批(batch)这个维度上进行归一化,其需要用到足够大的批大小。3D U-Net中使用的归一化也是批归一化,但由于本文网络增加了更多的3×3×3卷积核,加上Transformer模块的引入,参数量增多,增加了模型训练难度,对显卡显存的需求加大。在显存有限的条件下,只能使用更小的批次训练,而批量越小,批归一化的误差会快速增大。故本文将下采样模块以及上采样模块中的批归一化更改为组归一化。组归一化把通道分为组,计算每一组之内的均值和方差,以进行归一化。组归一化的计算与批量大小无关,其精度也在各种批量大小下保持稳定。
1.3 Transformer模块
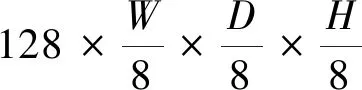
1.4 注意力门模块的改进
Attention U-Net的注意力门有2个输入,一个是来自浅层网络跳跃连接的特征图x,另一个输入来自网络每层上采样的输出g,经过注意力门后得到一个尺寸与x相同的输出x′。2个输入分别经过一个1×1×1的卷积核后,直接相加后输入ReLU激活函数。本文在1×1×1卷积核后面加入了一个组归一化层,通过标准化每个批次的输入数据,有助于确保输入分布大致相似,从而使每个注意力门模块都更容易学习,有助于减轻梯度消失和梯度爆炸问题,提高训练的稳定性。
Attention U-Net的注意力门使用了Sigmoid激活函数对注意力系数进行归一化处理。Sigmoid激活函数具有计算复杂、梯度消失和输出饱和的问题,而使用Softmax激活函数会使输出变的稀疏。本文改进为计算更简单、没有梯度消失问题的ReLU函数。改进后的注意力门结构如图3所示。
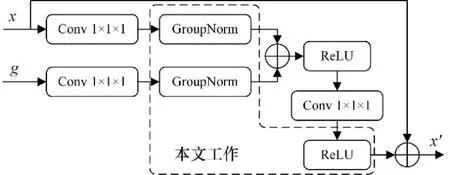
图3 改进的注意力门结构
2 实验与结果分析
2.1 实验数据及预处理
本文实验使用多中心、多供应商和多疾病心脏图像分割挑战赛(Multi-Centre, Multi-Vendor &Multi-Disease Cardiac Image Segmentation Challenge,M &Ms)[12]数据集,该数据集包含320份样本,这些样本使用4台不同的核磁共振仪器采集固有ABCD 4个不同的域的样本。其中,域A有95份样本,域B有125份样本,域C和域D各包含50份样本。该数据集提供了3个真值标签,分别为左心室(Left Ventricle,LV)、右心室(Right Ventricle,RV)和左心室心肌(Myocardium,MYO)。
本文的数据集划分如表1所示,域A与域B的数据用于支持集Ds,域C的数据用于验证集Dv,域D的数据用于测试集Dt。

表1 数据集设置
2.2 损失函数
交叉熵损失是图像分割任务的常用损失函数之一。交叉熵损失会计算图像的每一个像素的类预测,然后取平均值。但部分图像分割任务,例如:医学图像心脏分割,心脏只占了胸腔很小一部分,即图像真值标签只占图像很小一部分,背景占据了更大一部分。在交叉熵损失下,模型学习到了更多的背景类像素,而只学习到很小一部分真值类像素。
Dice损失在医学图像分割任务中比交叉熵损失更为常见。其计算所有像素的真值标签与预测标签的交并比。计算交并比就不会引入大量无关的背景像素,可以极大减缓真值与背景类别不平衡的问题。
考虑上述2种损失函数的优劣,本文使用交叉熵损失和Dice损失的未加权和,其式如式(1)。
L=LCE+LDice
(1)
LCE代表交叉熵损失,LDice代表Dice损失。
这样的复合损失函数被证明在各种分割任务中具有鲁棒性[13]。
2.3 实验环境与参数设置
实验环境:中央处理器(I9-10900K @3.7 GHz,Intel,美国),独立显卡(GeForce 3090 24 GB,Nvidia,美国)。深度学习框架为PyTorch 1.11.1(Linux Foundation,美国),编程语言为Python 3.8.6(Python Software Foundation,美国)。内循环使用学习率为0.5的普通梯度下降方法,外循环为学习率0.0001、权重衰减1e-5的Adam优化器。
2.4 评价指标
本文性能度量指标选取戴斯相似性系数(Dice Similarity Coefficient,DSC)以及豪斯多夫距离(Hausdorff Distance,HD)评估每个模型的分割精度。DSC可以衡量手动注释和预测结果之间的重叠程度。HD可以评价模型预测结果与手动注释的形状相似度,其值越小越相似,最小值为0。为了评估模型在2个指标下的综合表现,本文提出了融合指标COMBINE,其公式如式(3)。
(2)
该指标为DSC的一半与(100-HD)一半的和,DSC越大,HD越小,融合指标越高。反之,DSC越小,HD越大,融合指标越低。
2.5 实验结果与分析
表2测试了主流医学图像分割网络3D U-Net、UNETR[14]、RegUNet[15]、TransBTS以及Attention U-Net。实验结果表明,本文算法在不使用MAML算法下,对比主流分割网络,有更好的性能。MAML+3D U-Net网络比基线3D U-Net网络,DSC分数提高的同时,HD分数也下降了,表明网络通过MAML算法训练后,分割结果不但与真值重合度高,而且分割结果的形状与真值更接近,MAML算法带来的提升在Attention U-Net以及本文算法上,均有所体现。本文算法结合MAML算法后,得到了测试中最高的平均DSC得分以及最低的平均HD分数。

表2 实验评估结果
图4展示了各个方法在测试集某个样本的分割结果可视化,图4右下角真值图片标注了右心室(RV)、左心室(LV)、左心室心肌(MYO)对应的真值掩码。UNETR在测试集下分割效果较差,结合表2该网络的数据,表明该网络在测试集与训练集域不一致环境下,适应性较差。在测试样本下,Attention U-Net的分割效果会比本文的模型稍好,右心室区域过度分割的更少。在结合MAML元学习算法之后,本文的网络分割效果最为接近真值标签。图4纵向对比3个网络有无使用MAML算法的结果,能看到MAML算法并非都能起到作用,对于3D U-Net网络,使用MAML算法后,右心室区域的过度分割更加严重。对于本文的网络,MAML算法起到了良好的效果,改善了原本右心室区域的过度分割。
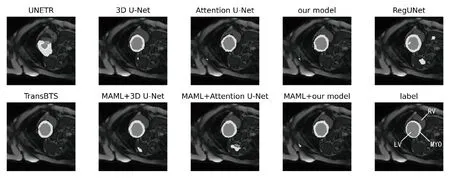
图4 分割结果可视化对比
2.6 消融实验
为了验证引入Transformer模块以及注意力门改进带来的效果,本文进行了各模块的消融实验。各个模块消融实验模型使用了相同的数据集和参数训练,3D U-Net+Transformer是单独在3D U-Net引入Transformer模块,3D U-Net+改进注意力门是单独引入改进注意力门模块。实验结果如表3所示。
实验结果可以看出:
(1)在引入Transformer模块后的3D U-Net网络,能取得比基线更好的分割效果,DSC系数得到了
提升的同时,HD也有所下降,证明Transformer在数据量有限的小样本任务下,也能给模型带来精度的提升。
(2)在单独引入注意力门模块后,模型性能对比3D U-Net基线得到了提升,注意力门能帮助模型消除来自浅层网络的噪声,提高对任务相关信息的专注度。
3 结语
本文在3D U-Net网络的基础上,对其下采样模块增多了一层3D卷积层,将其中的批归一化替换为了组归一化;将该网络编解码器连接处替换为Transformer,又在跳跃连接处,引入了改进的注意力门模块;利用MAML元学习算法训练网络,提升网络在小样本任务上的泛化能力。在公开数据集M&Ms上的实验表明,与多个现有方法相比,本文的算法表现出更好的分割性能。但本文方法增加了卷积核、Transformer以及注意力门模块,增加了算法的复杂度以及推理速度,下一步探索轻量化算法,实现分割精度和算法复杂度平衡,在其他医学图像数据集上进行推广改进,提高方法的普适性。
