基于NVMe-oF的高速大容量存储系统设计
2024-05-30曹润清黄立桓
臧 兵,赵 谦,花 飞,曹润清,黄立桓
(航空工业西安航空计算技术研究所,陕西 西安 710065)
0 引言
未来是智能为王的时代,计算机设备将向智能化转型,数据作为驱动人工智能技术发展的三驾马车(算法、算力、数据)之一,其资产价值日益凸显。多源传感器系统捕获的环境信息、设备故障预测与健康管理信息和相关过程信息等数据,是综合态势感知的基础,更是人工智能算法训练、进化的基石。随着信息技术的高速发展,未来数据规模和数据类型将持续增长,在这样的背景下,人们对高速大容量存储技术进行深入研究的需求愈发迫切。
固态存储器(Solid State Drive, SSD)又称电子盘,是基于Nand Flash构建的存储设备,凭借较高的存储密度、可靠性、重量轻、体积小、抗震性强、能耗低等特点,已得到广泛的使用[1]。NVMe是针对非易失性存储介质开发的本地高性能存储协议,能够提供更高的带宽、更强的IOPS及更低的端到端延迟,已经成了高性能全闪存储的标准协议[4]。2016年出现的NVMe-oF技术进一步将原本只能通过本地PCIe承载的NVMe协议扩展到网络,以增加不超过10 μs延迟的代价提供了主机与远程NVMe设备的低延迟连接[2]。NVMe-oF技术的应用能够实现计算与存储资源的解耦,方便后期根据需求灵活地对计算和存储资源分别进行升级,避免了传统系统中计算与存储资源绑定所导致的弊端。
本文结合当今的大数据时代背景,面向对海量多源数据的快速记录需求,基于NVMe-oF技术设计了一种高速大容量存储系统,实现了端到端的高带宽、低延迟数据存储,并且相较于传统存储系统实现了计算与存储资源的解耦,能够支撑后期根据需求对计算、存储资源的适应性灵活升级扩容。
1 NVMe-oF技术
传统的NVMe运行在PCIe总线之上,可以将之称为NVMe over PCIe。受限于PCIe总线的扩展性,传统NVMe协议无法用于跨网的远程存储访问。如果将NVMe的承载者由PCIe迁移至网络,便形成了NVMe-oF。NVMe-oF规范定义了一种支持NVMe协议的存储网络架构,包括从前端的存储接口到后端大量的NVMe设备以及远程访问所依赖的网络传输系统。NVMe-oF能够将非易失性存储器连接到网络并提供块存储服务。
在传统的NVMe over PCIe中,NVMe命令和响应被映射到主机的共享内存,通过PCIe接口访问。NVMe-oF与之不同,可将NVMe命令和响应封装成消息,每个消息可以包含一个或多个NVMe命令或响应。当通过网络将负责的消息发送到源端NVMe设备时,为了提高传输效率并降低延迟,可以将多个消息合并为一个长消息发送。
NVMe-oF支持的传输网络选项,包括光纤通道、远程直接内存访问(Remote Direct Memory Access,RDMA)和TCP共3个大类,其中RDMA又可进一步细分为InfiniBand(IB)、RoCEv1、RoCEv2和iWARP。作为一种新兴的跨网内存访问技术,RDMA能够让节点1的网卡直接读写节点2的处理器内存,在实现高带宽、强吞吐、低延迟网络传输的同时降低了对节点CPU的算力消耗,已成为当前NVMe-oF设计中优选的传输网络方案,获得了业界的广泛使用[5]。RDMA的技术优势可以总结如下:
(1)零拷贝。网卡可以直接与应用内存相互传输数据,而不需要将数据拷贝到内核态作处理,降低了传输延迟。
(2)内核旁路。应用无需内核调用即可直接操作设备接口,RDMA请求可从用户空间发送到本地网卡并通过网络传输给远端节点的网卡。
(3)低CPU负载。数据传输完全由网卡操作,不消耗CPU资源。
NVMe-oF基于RDMA技术实现对远端NVMe设备快速、低延迟的访问,把NVMe协议在本地访问时提供的高性能优势进一步发挥到远程的存储互连架构中。RoCEv2是当前最为流行的一种RDMA技术,将IB与以太网进行融合,在保留IB传输层的同时,使用IP和UDP替换掉IB的网络层,从而获得了较强的扩展性和ECMP性能[3]。因此,本文选择RoCEv2开展系统设计,后续提到的RDMA专指RoCEv2。
2 基于NVMe-oF的存储系统架构设计
2.1 系统架构
基于NVMe-oF的存储系统架构概念视图如图1所示。高速大容量存储设备(Data Storage Equipment, DSE)与前端的多个数据源节点通过高速RDMA网络实现互联,将多源异构数据进行统一记录与管理。DSE提供在线检索查询功能,并支持以手持数据卡(Portable Data Card, PDC)的形式通过数据解析设备完成数据卸载导出。将导出后的记录数据汇总起来构建数据湖,数据湖中的宝贵数据可以作为历史回溯数据,支撑智能算法的训练、基于历史数据的环境态势预测以及设备的故障分析和维护保障等。
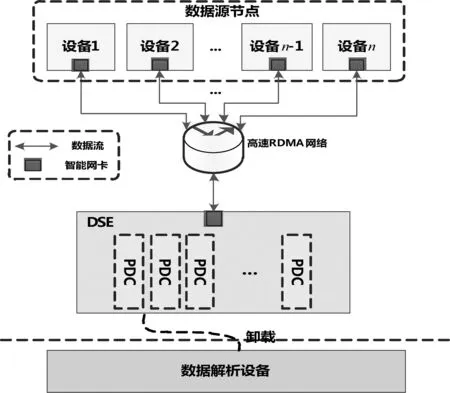
图1 基于NVMe-oF的存储系统架构
2.2 存储数据流向分析
系统存储数据流可以分为上行与下行2种,分别对应于数据读取与存储2种场景。以下行链路为例,NVMe存储由各数据源节点的Host CPU发起,接着由NVMe-oF Initiator负责NVMe到NVMe-oF的命令转换,之后以RDMA消息的形式传往DSE的NVMe-oF Target转换为NVMe命令,执行后续的落盘存储过程,将待存数据写入Nand Flash。为了方便对PDC中数据的管理,在Host CPU中运行文件系统,以文件的形式组织数据。上行传输为下行传输的逆过程:当源节点发起数据读取命令后,目标数据由Nand Flash搬移至PDC的DDR,之后经RDMA网络送至源节点进行处理。系统的存储数据流向如图2所示。
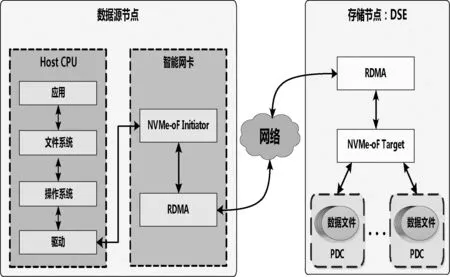
图2 系统存储数据流向
2.3 数据存储形式
DSE将多块PDC集中放置组成电子盘阵列,基于NVMe-oF向前端的数据源节点提供块存储服务。考虑到NVMe-oF前端数据源节点与后端存储节点一一绑定的技术特点,因此本系统在投入使用前首先需要根据各数据源节点的数据类型、工作时长等参数估算出需要存储的数据总量,并以此作为先验信息预先对PDC阵列进行逻辑分区,做存储资源的划分与对应。源节点与PDC逻辑分区的对应关系如图3所示。
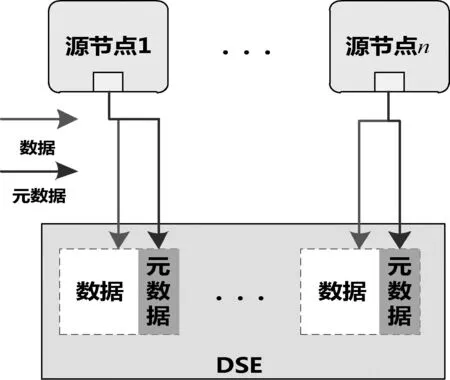
图3 PDC逻辑分区
3 DES设计
如图4所示,DSE由中央处理模块(CPM)、电源模块(PSM)、PDC阵列以及高速底板、结构件等部组件组成。其中,CPM提供整机的高速网络接入和存储所需的处理资源;PSM提供整机的电源转换、掉电储能;PDC作为实际记录信息的存储资源,提供对全盘数据的快速物理销毁,并支持便捷拔插功能。DSE由1路28VDC供电,对外提供调试串口、网口以及指示灯,整机内部通过PCIe 3.0互连。

图4 DSE硬件架构
3.1 CPM设计
CPM完成DSE整机的25 Gbps高速以太网接入,并通过全卸载的方式实现RDMA和NVMe-oF Target侧的全部功能。基于上述考虑,CPM以FPGA和CPU为核心进行构建。FPGA提供DSE所需的网络接口及协议卸载,并通过自带的PCIe 3.0硬核挂载PDC,实现对PDC的高速访问;CPU用于完成模块的相关配置并对网络运行状态进行监控。FPGA以硬核形式提供6个PCIe3.0×16接口,支持76个32.75 Gbps的GTY,支持DDR4控制器接口。CPU处理器为双核ARM V8架构,单核最高工作主频为1 GHz。提供72 bit的DDR3高速存储器,支持ECC校验;提供多种对外接口。
3.2 PDC设计
PDC由主控制器芯片、Nand Flash阵列、电源转换电路以及毁钥电路组成。主控芯片完成NVMe协议解析、Flash管理以及磨损均衡、坏块管理、垃圾回收等;电源转换电路完成二次电源转换,提供控制器I/O、控制器内核等供电;毁钥电路主要用于硬件烧毁Nand Flash颗粒。主控支持PCIe 3.0 x4和NVMe 1.3c协议标准,有8个Flash通道,每通道支持8CE;支持ONFI和Toggle接口Flash;最大读速度可达3.5 GB/s,最大写速度可达3.4 GB/s。
4 结语
面对智能化发展过程中日益增长的数据存储需求,本文基于NVMe-oF设计了一种高速大容量存储系统。该系统能够提供端到端的高带宽、低延迟数据存储,实现了计算与存储资源的解耦,支撑后期根据需求灵活地对计算和存储资源进行适应性的升级扩容。
