基于深度学习的教材德目教育文本分类方法
2024-05-30陈浩淼陈军华
陈浩淼 陈军华


摘 要: 对上海中小学教材德目教育文本分类进行研究,提出了基于转换器的双向编码表征(BERT)预训练模型、双向长短期记忆(BiLSTM)网络和注意力机制的模型IoMET_BBA. 通过合成少数类过采样技术(SMOTE)与探索性数据分析(EDA)技术进行数据增强,使用BERT模型生成富含语境信息的语义向量,通过BiLSTM提取特征,并结合注意力机制来获得词语权重信息,通过全连接层进行分类. 对比实验的结果表明,IoMET_BBA的F1度量值达到了86.14%,优于其他模型,可以精确地评估教材德目教育文本.
关键词: 德目指标; 中文文本分类; 基于转换器的双向编码表征(BERT)模型; 双向长短期记忆(BiLSTM)网络; 注意力机制
中图分类号: TP 391.1 文献标志码: A 文章编号: 1000-5137(2024)02-0172-09
Text classification method for textbook moral education based on deep learning
CHEN Haomiao, CHEN Junhua*
(College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,Shanghai 201418,China)
Abstract: The classification of moral education texts in Shanghai primary and secondary school textbooks was studied and an IoMET_BBA(Indicators of moral education target based on BERT, BiLSTM and attention) model was proposed based on bidirectional encoder representations from transformer(BERT) pre-training model, bidirectional long short-term memory (BiLSTM) network, and attention mechanism. Firstly, data augmentation was performed using synthetic minority oversampling technique(SMOTE)and exploratory data analysis (EDA). Secondly, BERT was used to generate semantic vectors with rich contextual information. Thirdly, BiLSTM was adopted to extract features, and attention mechanism was combined to obtain word weight information. Finally, classification was performed through a fully connected layer. The comparative experimental results indicated that F1 measurement value of IoMET_BBA reached 86.14%, which was higher than other models and could accurately evaluate the moral education texts of textbooks.
Key words: moral education index; chinese text classification; bidirectional encoder representations from transformer(BERT) model; bidirectional long short-term memory (BiLSTM) network; attention mechanism
德目教育是指將道德或品格的条目通过一定方式传授给学生的教育活动[1]. 德目教育的目标是帮助个体形成正确的道德判断,培养个人的道德观念、价值观和道德行为,进而推动整个社会形成道德共识.近年来,国内对德目教育的研究已经有了很多成熟的理论与实践模式,但对于教材文本的德目指标评估大部分是依靠人工完成的,结论较为主观,且效率较低[2].
文本分类是自然语言处理(NLP)领域中的一项关键任务,它把文本数据归入不同的预先定义类别,在数字化图书馆、新闻推荐、社交网络等领域起到重要的作用. JOACHIMS[3]首次采用支持向量机方法将文本转化成向量,将文本分类任务转变成多个二元分类任务. KIM[4]提出了基于卷积神经网络(CNN)的TextCNN方法,在多个任务中取得了良好的效果. 徐军等[5]运用朴素贝叶斯和最大熵等算法,实现了中文新闻和评论文本的自动分类. 冯多等[6]提出了基于CNN的中文微博情感分类模型,并运用于社交场景.
由于教材文本数据具有稀疏性,使用传统的分类算法进行建模时很难考虑上下文和顺序信息,并且数据集不平衡,不同指标的文本条数差异较大. 之前的相关研究[7-8]主要基于静态词向量(GloVe,Word2Vec)与CNN进行建模,所获得的词向量表示与上下文无关,也不能解决一词多义问题,且CNN只能提取局部空间特征,无法捕捉长距离的位置信息. 本文作者采用深度学习方法,对教材短文本数据进行分类,首先采用合成少数类过采样技术(SMOTE)和easy data augmentation(EDA)技术获得更平衡、更充分的文本数据集,提出基于深度学习的教材德目教育文本分类模型(IoMET_BBA),使用基于转换器的双向编码表征(BERT)预训练模型来生成富含语境信息的语义向量,然后使用双向长短期记忆网络(BiLSTM)和注意力机制来进一步进行特征提取,充分考虑上下文和位置信息,从而提高分类任务的准确性. 实验证明:相比于传统模型,IoMET_BBA模型的准确率与F1值提升明显,可高效准确地完成大规模的教材德目教育文本分类任务.
1 相关技术
1.1 深度学习分类模型
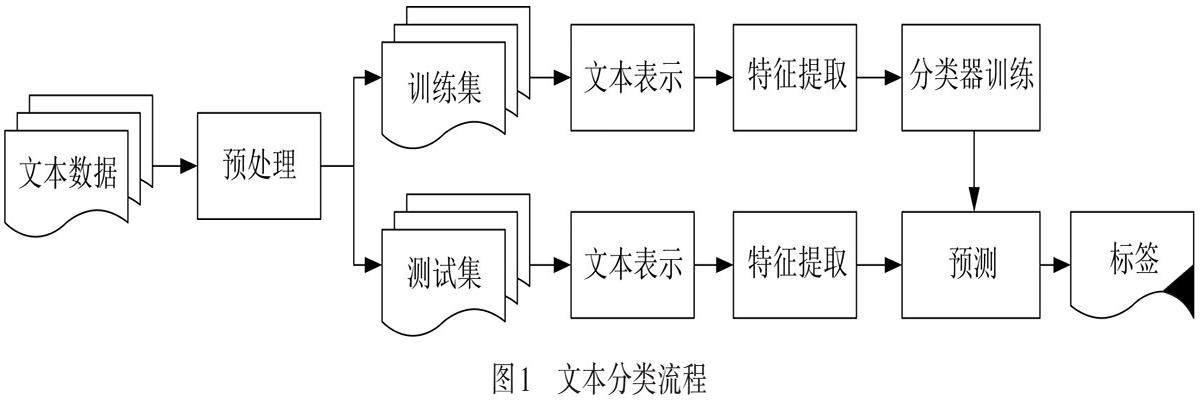
文本分类需要使用已标注的训练数据来构建分类模型. 常见的文本分类流程如图1所示. 在进行文本分类之前,通常需要对原始数据进行预处理,包括分词、去除停用词、词干提取等.
文本分类可以使用多种算法进行建模. 传统的机器学习分类模型,如朴素贝叶斯[9]、Kmeans[10]、支持向量机[3]、决策树[11]等,通常需要依靠人工来获取样本特征,忽略了文本数据的上下文信息和自然顺序. 近年来,基于神经网络的深度学习方法成为研究的热点. 这种方法主要包含两个关键任务:通过构建词向量来表示文本、使用一定的模型来提取特征并进行分类.
计算机不能理解人类的语言,因此在NLP任务中,首先要将单词或词语表示成向量. 独热编码将词转化为长向量,向量维度与词数量相同,每个向量中某一维度的值是1,其余值都是0. 独热编码虽然简单,但不能体现出词与词之间的关系,并且当词量过大时,会出现维度灾难及向量十分稀疏的情况. 分布式的表示方法则可以将词表示为固定长度、稠密、互相存在语义关系的向量,这类方法也称为词嵌入. MIKOLOV等[12]提出了Word2Vec框架,包含Skip-Gram和Cbow算法,分别用单词来预测上下文和用上下文来预测单词. PENNINGTON 等[13]提出的GloVe方法,同时考虑到了局部信息和全局统计信息,根据词与词之间的共现矩阵来表示词向量.
深度学习方法已经成为文本分类的主流方法. KIM等[4]使用包含卷积结构的CNN来分类文本,将文本映射成向量,并将向量输入到模型,通过卷积层提取特征、池化层对特征采样,但CNN没有时序性,忽略了局部信息之间的依赖关系. 循环神经网络(RNN)则从左到右浏览每个词向量,保留每个词的数据,可以为模型提供整个文本的上下文信息,但RNN计算速度较慢,且存在梯度消失等问题. 作为RNN的一种变体,长短期记忆网络(LSTM)通过过滤无效信息,有效缓解了梯度消失问题,更好地捕获长距离的依赖关系. 而BiLSTM由一个前向的LSTM和一个后向的LSTM组成,能够捕获双向语义依赖.
1.2 BERT预训练模型
同一個词在不同环境中可能蕴含不同的意义,而使用Word2Vec,GloVe等方法获得的词向量都是静态的,即这类模型对于同一个词的表示始终相同,因此无法准确应对一词多义的情况. 为了解决这一问题,基于语言模型的动态词向量表示方法应运而生.
预训练语言模型在大规模未标注数据上进行预训练,通过微调的方式在特定任务上进行训练.DEVLIN 等[14]提出了BERT模型,它拥有极强的泛化能力和稳健性,在多类NLP问题中表现优异.
BERT模型本质是一种语言表示模型,通过在大规模无标注语料上的自监督学习,为词学习到良好的特征表示,并且可以通过微调,适应不同任务的需求. BERT模型采用多层双向Transformer结构,在建模时,Transformer结构使用了自注意力机制,取代传统深度学习中的CNN和RNN,有效地解决了长距离依赖问题,并通过并行计算提高计算效率. 通过计算每一个单词与句中其他单词之间的关联程度来调整其权重. BERT模型的结构如图2所示.
图2中,![]() ,
,![]() ,
,![]() ,
,![]() 表示文本中的字符;
表示文本中的字符;![]() 表示Transformer编码器;
表示Transformer编码器;![]() ,
,![]() ,
,![]() ,
,![]() 是字符通过多层双向Transformer编码后得到的词向量. 在面对具体任务时,可以将BERT模型获得的特征表示进行微调来作为词嵌入. 在文本分类任务中,BERT模型既可以作为训练分类器模型的直接工具,又可以与其他模型相结合,充当词嵌入层.
是字符通过多层双向Transformer编码后得到的词向量. 在面对具体任务时,可以将BERT模型获得的特征表示进行微调来作为词嵌入. 在文本分类任务中,BERT模型既可以作为训练分类器模型的直接工具,又可以与其他模型相结合,充当词嵌入层.
2 IoMET_BBA建模
针对上海中小学教材德目教育文本分类任务,本文作者提出IoMET_BBA模型,主要由BERT层、BiLSTM层、Attention层及分类输出层构成,如图3所示. 教材文本进入模型前先进行文本预处理,通过数据增强来获得一个平衡的新数据集,将增强后的文本输入BERT模型层获得词向量,通过BiLSTM层提取特征,通过Attention层分配特征权重,将每条文本经过全连接层分类输出.
2.1 文本预处理
文本数据在进入模型前通常要进行一些预处理操作,才能符合后续训练模型时所需要的文本格式. 文本预处理主要包含数据清洗、分词、去停用词等环节. 教材短文本中包含一些语气助词、特殊符号等对分类没有意义的信息,需要去掉这些影响分类效率的噪声信息. BERT模型在处理中文时,按字将文本用空格分割,不需要人工去除停用词,避免了丢失上下文语义的情况. 因此,对教材文本进行简单的数据清洗,使之符合BERT模型输入的要求即可. 在对照实验组中,使用Jieba中文分词工具来分词,通過自建停用词表来去除停用词.
2.2 文本数据增强
数据增强的目标是在尽可能保持标签语义不变的情况下,使用部分有标注的数据来生成更多有标注的数据. 本研究所处理的原始教材文本数据集具有数据不平衡、数据量较少的问题,因此需使用数据增强技术来生成一个更平衡、更多样的数据集,以提升模型的泛化能力.
为了解决数据不均衡的问题,可以使用过采样、欠采样、类别加权等方法. SMOTE算法是一种过采样技术,其核心是合成产生更多的少数类样本. 对每个少数类中的样本![]() ,计算其到其他少数类样本的欧氏距离,获得
,计算其到其他少数类样本的欧氏距离,获得![]() 个近邻样本,依据样本的不平衡率来确定采样的比例,在样本
个近邻样本,依据样本的不平衡率来确定采样的比例,在样本![]() 的
的![]() 近邻中随机选取若干个近邻样本,对于每个近邻样本
近邻中随机选取若干个近邻样本,对于每个近邻样本![]() ,构造新的少数类样本
,构造新的少数类样本
![]() . (1)
. (1)
文本数据扩充的方法有EDA、回译、文本语境增强等. EDA是一种简单通用的数据增强技术,包含 4 种简单的操作:同义词替换(SR)、随机插入(RI)、随机交换(RS)、随机删除(RD). 通过生成与原数据相似但添加了噪声的增强数据,EDA可以防止模型出现过拟合的情况.
对于所使用的教材文本数据集不均衡、数据量不足的问题,本文作者使用SMOTE算法实现少数类别过采样操作,使用EDA扩充文本数据来获得更平衡的数据集,从而提升模型的泛化能力.
2.3 BERT词嵌入层
BERT模型的输入由三个部分构成:标记嵌入、片段嵌入、位置嵌入. 标记嵌入是将文本序列中的每个标记表示为向量,在中文文本分类场景中,BERT模型首先将文本按字用空格分割,然后通过查询字向量表,将每一个字转变成一个一维向量;片段嵌入是为了区分字所在的句子,用于捕捉所在片段的语义信息;位置嵌入是将字所处的位置信息表示为向量,可弥补Transformer编码器不能捕获顺序信息的缺陷.
如图4所示,在教材文本分类任务中,BERT模型的输入是教材文本中每个字初始的词向量,其中[CLS]标签表示用于文本分类任务,[SEP]标签表示两个句子的分隔边界. 最终输出教材文本中融合了语义信息的向量.
2.4 BiLSTM层
教材短文本数据在经过BERT预训练模型后,已经被表示为包含丰富语义信息的动态词向量,要想获得良好的文本分类结果,还需要充分考虑上下文信息. LSTM是一种特殊的循环神经网络,它引入了记忆细胞、输入门、输出门、遗忘门等概念,可以有效捕获序列中的长时间依赖性. 在LSTM中,输入序列经过神经网络,每一个单元被映射到一个隐藏状态向量,然后由另一个神经网络层对向量进行解码输出,但这种方法无法编码从后到前的信息. 使用BERT模型生成的词向量作为嵌入层,通过BiLSTM网络与注意力机制进行教材文本的上下文特征提取.
如图5所示,BiLSTM有两个独立的LSTM层,分别按照时间顺序和倒序处理输入. 正向LSTM层中,每个时间步的隐藏状态![]() 和单元状态分别如下:
和单元状态分别如下:
![]() , (2)
, (2)
![]() , (3)
, (3)
![]() , (4)
, (4)
![]() , (5)
, (5)
![]() , (6)
, (6)
![]() , (7)
, (7)
其中,![]() ,
,![]() ,
,![]() ,
,![]() 分別为时刻
分別为时刻![]() 的输入门、遗忘门、输出门及记忆细胞的激活向量;
的输入门、遗忘门、输出门及记忆细胞的激活向量;![]() 表示时刻
表示时刻![]() 的输入;
的输入;![]() 为权重矩阵;
为权重矩阵;![]() 为偏置向量;
为偏置向量;![]() 为Sigmoid函数. 类似地,反向LSTM按时间倒序处理序列,可计算出每个时间步的隐藏状态
为Sigmoid函数. 类似地,反向LSTM按时间倒序处理序列,可计算出每个时间步的隐藏状态![]() 和单元状态
和单元状态![]() . 最后输出层对两个方向的状态进行拼接,得到最终输出:
. 最后输出层对两个方向的状态进行拼接,得到最终输出:
![]() . (8)
. (8)
2.5 Attention層
在教材文本数据中,并非所有词语都用于文本的语义表达,某些关键词往往更能体现语义的类别倾向,因此,采用注意力机制(attention mechanism)来提取重要信息,从而进行准确的分类. 注意力机制早期由图像领域的研究者提出,通过模仿人类的视觉注意力来给不同区域分配权重. 引入注意力机制可以让神经网络具备选择关注输入关键信息的能力,从而提高模型的性能. MNIH等[15]在RNN的基础上,添加了注意力机制来改进图像分类效果,BAHDANAU等[16]首次将注意力机制运用到NLP任务中.
注意力机制算法可以分成:先计算查询Q和键K之间的相似性,获得权重系数![]() ,经过Softmax函数归一化处理后,再将
,经过Softmax函数归一化处理后,再将![]() 与对应的值V加权求和,
与对应的值V加权求和,
![]() , (9)
, (9)
其中,![]() 表示词向量的维度;
表示词向量的维度;![]() 表示Softmax层运算.
表示Softmax层运算.
2.6 分类输出层
本模型的分类输出层由全连接层和Softmax层组成. 原始数据经过BERT词嵌入层、BiLSTM层、注意力机制层后,输出的向量包含多样化语义、上下文信息和词语权重信息. 将Attention层输出的特征向量作为全连接层的输入,通过多个神经元和ReLU激活函数的运算,产生新的输出,通过Softmax层将其映射为各个类别的分布概率
![]() , (10)
, (10)
其中,![]() 是输入的特征向量;
是输入的特征向量;![]() 是权重矩阵;
是权重矩阵;![]() 是偏置项.
是偏置项.
模型的训练采用收敛较快的交叉熵损失函数作为目标函数,某一类别的损失函数
![]() , (11)
, (11)
其中,![]() 为样本的标签;
为样本的标签;![]() 为预测标签. 对一个批次(batch),损失函数为:
为预测标签. 对一个批次(batch),损失函数为:
![]() , (12)
, (12)
其中,![]() 为batch的大小;
为batch的大小;![]() 为类别数;
为类别数;![]() 为样本标签;
为样本标签;![]() 为预测标签.
为预测标签.
3 实验
3.1 实验数据集
本实验原始数据集选取自上海中小学教材,分为16个类别(表1),包含33 360条文本数据. 原始数据集存在数据不平衡的问题,使用2.2节所述方法对教材文本数据进行增强,新的均衡数据集包含109 754 条短文本. 根据8∶2的比例随机划分成训练集和测试集.
3.2 实验环境
所用设备的操作系统为Windows10,CPU为AMD Ryzen7,5 800 Hz, GPU为NVIDIA GeForce RTX3060,编程语言为 Python,框架为Pytorch.
3.3 模型参数设置
本实验中所用BERT模型的具体参数如下:注意力机制头数为12,Transformer 编码器层数为12,隐藏层单元数为 768. BiLSTM模型训练参数如表2所示.
3.4 评价指标
通过准确率A以及度量值F1对模型表现进行评估,
![]() , (13)
, (13)
![]() , (14)
, (14)
![]() , (15)
, (15)
![]() , (16)
, (16)
其中,![]() 为召回率;
为召回率;![]() 为精确率;
为精确率;![]() ,
,![]() ,
,![]() 和
和![]() 分别为真阳性、真阴性、假阳性和假阴性的数量.
分别为真阳性、真阴性、假阳性和假阴性的数量.
3.5 实验结果与分析
为了探究本模型的有效性,把增强之后的数据集和原数据集分别输入IoMET_BBA模型中,计算F1来对比分类效果,如图6所示.
图6证明了数据增强后,训练效果在每个分类上都有了明显提升,模型整体的F1提升了约22%,验证了数据增强方法的有效性.
为了探究BERT模型作为词向量嵌入层在教材德目教育文本分类任务的有效性,运用Word2Vec,GloVe,BERT三种模型方法来表示词向量,并分别结合CNN与BiLSTM两种模型进行实验,结果如表3所示.
从表3中能够看出,在结合CNN进行特征提取时,使用BERT模型训练词向量比使用GloVe模型的F1提升了7.01%;在结合BiLSTM进行特征提取时,使用BERT模型训练词向量比使用GloVe模型的F1提升了4.22%. 因此,使用BERT模型作為教材德目文本分类任务的词向量表示,可以获得更丰富的语义信息,取得更好的训练效果,从而提高分类的准确性. 另外,由表3可知,BiLSTM的特征提取效果优于CNN.
为了验证所提出的IoMET_BBA模型在进行教材德目文本分类时的整体有效性,选取了表现较好的BERT_CNN与BERT_BiLSTM进行比较,并且使用单纯的BERT模型和加入注意力机制的BERT_CNN_ATT模型相对比,实验结果如表4所示.
从表4可知,虽然单纯BERT模型可以获得较好的分类结果,但结合CNN或BiLSTM后,模型可以取得更好的效果. 另外,在添加注意力机制后,各种模型的分类效果均有所提升,表明引入注意力机制可以使文本分类模型关注重要信息,从而提升模型性能. 综合来看,IoMET_BBA模型在教材德目教育文本分类任务中表现更好.
4 結论
本文作者提出了IoMET_BBA模型,在16个分类上进行数据增强的验证实验,并对比了不同分类模型的性能,以探究IoMET_BBA模型的有效性. 实验结果显示:
(1) 模型的数据增强方法有效解决了数据不均衡的问题;
(2) 使用包含自注意力机制的BERT模型来获取上下文语义,可以避开静态词向量模型无法表示一词多义、不能体现上下文语境的缺点;
(3) 结合CNN或BiLSTM模型,BERT模型能取得更好的结果,通过Attention层获得词语权重信息,可以进一步改进模型性能.
实验结果显示,所提出的IoMET_BBA模型在性能上表现更好,在教材文本分类任务中取得良好的结果,对于教材德目教育的评估具有一定意义. 未来的研究方向包括改进模型的数据预处理与数据增强方法,通过更多对比实验,进一步优化词向量的表示及神经网络的结构,以进一步提升模型性能.
参考文献:
[1] 陈菊恋. 德目教育存在的问题与超越:以勇敢教育为例 [J]. 基础教育研究, 2011(23):11-12.
[2] 姜献辉, 刘兵. 基础德目教育研究综述 [J]. 成功(教育), 2010(1):116-117.
[3] JOACHIMS T. Text Categorization with Support Vector Machines: Learning with Many Relevant Features [M]. Heidelberg: Springer, 1998.
[4] KIM Y. Convolutional neural networks for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha: ACL, 2014:1-6.
[5] 徐军, 丁宇新, 王晓龙. 使用机器学习方法进行新闻的情感自动分类 [J]. 中文信息学报, 2007(6):95-100.
XU J, DING Y X, WANG X L. Sentiment classification for Chinese news using machine learning methods [J]. Journal of Chinese Information Processing, 2007(6):95-100.
[6] 冯多, 林政, 付鹏, 等. 基于卷积神经网络的中文微博情感分类 [J]. 计算机应用与软件, 2017,34(4):157-164.
FENG D, LIN Z, FU P, et al. Chinese micro-blog emotion classification based on CNN [J]. Computer Applications and Software, 2017,34(4):157-164.
[7] 郭书武, 陈军华. 基于深度学习的教材德目分类方法 [J]. 计算机与现代化, 2021(9):106-112.
GUO S W, CHEN J H. Textbook classification method of index of moral education based on deep learning [J].Computer and Modernization, 2021(9):106-112.
[8] 张雨婷, 陈军华. 基于深度学习的教材德目分类评测方法 [J]. 计算机应用与软件, 2021, 38(10):209-215.
ZHANG Y T, CHEN J H. Research on indicators of moral education target in textbooks based on deep learning [J]. Computer Applications and Software, 2021, 38(10):209-215.
[9] MARON M E. Automatic indexing: an experimental inquiry [J]. Journal of the ACM, 1961,8(3):404-417.
[10] COVER T, HART P. Nearest neighbor pattern classification [J]. IEEE Transactions on Information Theory, 1967,13(1): 21-27.
[11] BREIMAN L, FRIEDMAN J, OLSHEN R A, et al. Classification and Regression Trees [M]. New York: Routledge, 1984.
[12] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [J/OL]. arXiv:1301.3781, 2013[2023-10-10]. https:// arxiv.org/abs/1301.3781v1.
[13] PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha: ACL, 2014:1532-1543.
[14] DEVLIN J, CHANG M, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [J/OL]. arXiv:1810.04805, 2018 [2023-10-10]. https:// arxiv.org/abs/1810.04805v2.
[15] MNIH V, HEESS N, GRAVES A. Recurrent models of visual attention [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal: ACM, 2014:2204-2212.
[16] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[J]. arXiv:1409.0473, 2014 [2023-10-10]. https:// arxiv.org/abs/1409.0473.
(責任编辑:包震宇,顾浩然)
DOI: 10.3969/J.ISSN.1000-5137.2024.02.005
收稿日期: 2023-12-23
基金项目: 国家社会科学基金(13JZD046)
作者简介: 陈浩淼(1997—), 男, 硕士研究生, 主要从事数据处理、自然语言处理方面的研究. E-mail: 1000513338@smail.shnu.edu.cn
* 通信作者: 陈军华(1968—), 男, 副教授, 主要从事数据信息处理技术及数据库信息系统等方面的研究. E-mail: chenjh@shnu.edu.cn
引用格式: 陈浩淼, 陈军华. 基于深度学习的教材德目教育文本分类方法 [J]. 上海师范大学学报 (自然科学版中英文), 2024,53(2):172?180.
Citation format: CHEN H M, CHEN J H. Text classification method for textbook moral education based on deep learning [J]. Journal of Shanghai Normal University (Natural Sciences), 2024,53(2):172?180.
