基于改进SegFormer网络的路面裂缝分割算法
2024-05-23唐源董绍江刘超闫凯波
唐源 董绍江 刘超 闫凯波


文章编号:2096-398X2024)03-0166-08
(重庆交通大学 机电与车辆工程学院, 重庆 400074)
摘 要:针对现有网络执行路面裂缝分割任务时,特征利用不充分、高层语义信息提取不足的问题,提出了一种改进SegFormer网络的路面裂缝分割算法.首先,为充分利用提取到的特征,摒弃了原网络以多层感知机(Multilayer Perceptron,MLP)作为解码器的方案,重新设计了融合不同尺度特征的解码器,并在特征融合时引入注意力模块为其提供信息融合指导,加强了高低层特征间的联系;其次,为弥补高层语义信息不足,设计了结合部分卷积(Partial Convolution,PConv)的空间高效卷积池化模块(Space Efficient Convolutional Pooling Module,SECPM),提升了模型对不同尺度裂缝的分割性能;最后,针对路面裂缝不受位置、形状等方面限制的特点,提出了一种新的数据增强方法,提高了模型的泛化性能.在公开数据集Crack500进行实验,相较于原网络,改进模型的F1和mIoU分别提升了1.03%、1.32%,本文提出的方法能更好地适应路面裂缝分割任务.
关键词:语义分割; 特征融合; 路面裂缝; 部分卷积
中图分类号:U418.6+6 文献标志码: A
An improved pavement crack segmentation algorithm based on SegFormer network
TANG Yuan, DONG Shao-jiang*, LIU Chao, YAN ai-bo
School of Mechantronics and Vehicle Engineering, Chongqing Jiaotong University, Chongqing 400074, China)
Abstract:Aiming at the problems of inadequate feature utilization and insufficient extraction of high-level semantic information in pavement crack segmentation by existing networks,an improved pavement crack segmentation algorithm based on SegFormer network was proposed.Firstly,in order to make full use of the extracted features,the original scheme of using Multilayer Perceptron MLP) as decoder was abandoned,and the decoder fused different scale features was redesigned.The attention module was introduced to provide information fusion guidance during feature fusion,and the relationship between high and low features was strengthened.Secondly,in order to make up for the lack of high-level semantic information,a Space Efficient Convolutional Pooling Module SECPM) combined with Partial Convolution PConv) was designed.The segmentation performance of the model for cracks of different scales is improved.Finally,a new data enhancement method was proposed to improve the generalization performance of the pavement crack,which was not limited by location,shape,etc.Experiments were carried out on Crack500,and compared with the original network,F1 and mIoU of the improved model improved by 1.03% and 1.32%,respectively.The method proposed in this paper can better adapt to the task of pavement crack segmentation.
Key words:semantic segmentation; feature fusion; pavement cracks; partial convolution
0 引言
裂缝是路面最为常见的缺陷之一[1],当路面出现大量裂缝时,影响路面美观,同时也会影响行驶安全,故而定期检查并发现路面裂缝是道路管理部门的一项重要工作.近年来,随着深度学习在图像、语音等方面的广泛应用,深度学习表现出了极为强大的特征提取能力和泛化能力[2].因此,不少研究人员将深度学习应用到路面裂缝检测任务当中.
深度学习在路面裂缝的应用可大致分为三个阶段:第1个阶段是利用卷积神经网络滑动窗口,实现裂缝的分类[3];第2个阶段是图像目標检测技术,实现路面裂缝精确定位[4];第3个阶段则是利用像素级语义分割技术,实现路面裂缝形态特征的精确提取[5].相较于前两阶段,裂缝像素级语义分割技术有着无可比拟的优势,不仅能够输出目标类别,还能够准确展现目标在图像当中的位置形态,通过此技术可为以后实现路面受损程度的自动评估提供帮助[6].
为实现像素级语义分割技术,涌现出了一批优秀的分割网络.Long等[7]提出全卷积神经网络(Fully Convolutional Networks,FCN),首先使用卷积层实现像素级别上端到端的预测;Hou等[8]改进了编码器与解码器对称的多尺度特征融合结构U-Net,引入多尺度密集扩张卷积网络将低层次的细节信息与高层语义信息融合,提升了图像分割效果;Chen 等[9]提出了DeepLabV3网络并设计了空洞空间金字塔池化层(Atrous Spatial Pyramid Pooling,ASPP)来增加特征提取网络的感受野,加强高层语义特征,之后的DeepLabV3+在此基础上引入了编解码合结构[10],提高了分割边界准确度;heng 等[11]在编码器引入Vision Transformer结构进行全局上下文建模,提出了SETR网络模型,为语义分割任务提供了新的思路.翟军治等[12]在网络结构中设计了一种多语义特征关联模块,实现不同语义信息的特征融合增强,但高层语义挖掘不充分;Xie 等[13]提出了无位置编码、输出多尺度特征的SegFormer网络,编码器仅使用多层感知机,执行效率较高,但忽略了特征层间联系,特征利用不充分.而在实际工程中面临着路面裂缝尺度变化大、形状各异等挑战,上述网络存在特征利用不充分、高层语义信息不足等问题,执行路面裂缝分割任务时往往表现不佳.
因此,为更好地适应路面裂缝分割任务,本文提出了一种改进SegFormer网络的路面裂缝分割算法,改进工作具体如下:
1)为解决特征利用不充分的问题,利用SegFormer网络编码器MiT-B1实现图像裂缝的特征提取,而解码器摒弃了原网络以多层感知机作为解码器的方案,采用本文所设计的特征融合網络(Feature Fusion Network,FFN)作为解码器.同时,为抑制融合时产生的冗余信息,利用通道注意力模块(Channel Attention Module,CAM)为高低层提供信息融合指导,加强了特征层之间的联系.
2)为弥补高层语义信息不足的问题,设计了一种结合部分卷积PConv[14]算子的空间高效卷积池化模块用于强化高层特征信息,提高模型对不同尺度裂缝的分割性能.
3)针对裂缝不受位置、形状等方面限制的特点,提出了一种新的数据增强方法,用于提高模型泛化性能.
1 SegFormer网络简介
如图1所示,SegFormer网络包括编码器和解码器两部分.编码器整个结构由4个Transformer Block堆叠而成,利用重叠块合并(Overlap Patch Merging,OPM)结构设计卷积核大小和步幅,实现对输入图像的缩放,从而形成分层特征.然后将OPM得到的特征层依次输入高效自注意力(Efficient Self-Attention,ESA)层、混合前馈网络(Mix Feed Forward Network,MixFFN)层进行特征增强,同时,为获取到更丰富的语义特征信息,将多个ESA和MixFFN进行叠加,使得特征提取网络加深,提高特征提取效率.图像经编码器的4个Transformer Block处理后分别输出不同分辨率的特征图,而后特征图经MLP统一调整输出通道数C为256,并通过双线性插值上采样调整特征图的宽高至原图像宽高的1/4,然后将不同层所处理后得到的特征图拼接起来,得到通道数为1 024的特征图,将其通过两个卷积核为1×1的卷积模块处理后输出预测的语义分割图像.
2 改进模型
2.1 模型整体结构
本文所改进的模型采取编码器-解码器的架构.其中编码器为原网络的MiT-B1,其主要超参数如表1所示.
其中Embed dims为不同阶段输出特征图的通道数.Num heads为每一阶段中N的值,即ESA和MixFFN叠加重复的次数.Mlp ratios为每一阶段MixFFN利用多层感知机输出通道与输入通道维数的比例系数,Sr ratios为每一阶段高效自注意力层ESA计算、V参数矩阵尺寸的缩放系数.
为解决特征层利用不充分、高层语义信息不足的问题,改进模型的解码器采用自行设计的FFN.模型整体结构如图2所示.
输入图像经编码器Transformer Block处理后分别输出不同分辨率的特征图,直接将特征图上采样至同等分辨率后再整合在一起进行特征提取,容易丢失细节特征信息.因此,为更好地提取存在于不同分辨率的特征图信息,本文利用CAM和SECPM设计了多尺度特征融合的解码器结构FFN.
首先将从Transformer Block4得到的高层特征图X4∈R512×H32×W32输入到SECPM调整特征图通道数为256.经SECPM处理后产生两个分支,一个分支直接上采样输出至Feature map,另一个分支利用卷积核为1×1的卷积模块CBL由标准卷积、批归一化、ReLU构成)调整通道数为256,再通过双线性插值上采样改变特征图分辨率,得到X3∈R256×H16×W16,后与上一层输出的特征图进行特征融合,利用CAM作特征信息融合指导,同时调整特征图通道数为256.对其他Transformer Block输出的特征图做类似处理,最后在Feature map上得到由4个分支上采样拼接而成的特征图M∈R1 024×H4×W4,对得到的特征图经两次卷积核大小为1×1的卷积调整其输出通道后,再上采样至原图大小,最后输出语义分割图像.
2.2 空间高效卷积池化模块
为弥补网络高层语义信息不足的问题,常常扩大感受野,增加卷积时对特征层映射区域的范围,但同时也带来了运算效率的降低.而本文在特征顶层引入部分卷积算子构造了空间高效卷积池化模块,可挖掘更丰富的高层语义信息,同时并不会影响运行效率.
部分卷积算子结构原理如图3所示.PConv将输入特征在通道维度上划分r份(r=4),并对第1份通道进行尺寸不变的卷积特征提取,而为通道形状不发生改变,造成信息丢失,将卷积后的通道与后r-1)份通道直接进行拼接即可.PConv并不会影响模型检测性能,但可有效降低运算成本.
部分卷积计算量FLOPs和内存访问量Amount为:
FLOPs:H×W×k2×C2p
Amount:H×W×2CP+k2×C2p≈H×W×2CP(1)
其中特征图通道与卷积通道数比例CCp=r,所以部分卷积计算量和内存访问量仅为标准卷积的1r2,1r.
PConv可降低计算成本,但仍有不足之处,在卷积过程中只考虑到了对第一部分通道进行特征提取,而忽略了其他通道上的特征,不可避免存在信息丢失.因此,为充分提取高层语义信息,提出SECPM弥补上述不足之处,实现了多层次多通道的特征提取,其结构如图4所示.
1)建立跨窗口连接.由 Transformer Block4 产生的高层特征图先通过Spatial Shuffle,如图4所示完成窗口重组,可打破特征层空间约束,建立跨窗口连接,实现特征图空间信息流通.
2)上层分支输出Xout1.对输入特征Xin进行全局池化Global pooling,GP)获取其全局特征信息,再依次通过卷积、Sigmod激活函数后输出得到Xout1,上层分支输出将为后续特征提供全局融合指导.
Xout1=sigmodf7×7(2)
式(2)中:f7×7代表卷积核大小为7×7的标准卷积.
3)中层分支输出Xout2.
Xout2=CBL1×1Xin)(3)
式(3)中:CBL1×1為1×1标准卷积、批归一化、ReLU三部分.
4)下层分支输出Xout3.先在输入特征Xin在通道维度上划分4部分,然后利用卷积核为3×3的PWConv部分卷积结合逐点卷积)输出形状为16×16×256的特征层将作为下一层的输入,之后将对第2、3、4部分的通道分别利用卷积核大小为5×5、7×7、9×9 PWConv进行特征提取,而每一层输出都将作为下一层的输入,最后将不同层获取到的特征图在空间尺度上完成特征融合,输出Xout3.
Xi+1=PWConvi+1k×kXin),i=0
PWConvi+1k×kXi),i=1,2,3[JB)],k=3,5,7,9
Xout3=∑3j=1PWConvj+1k×kXj)+X1(4)
式(4)中:PWConvnk×k代表对第n部分先进行卷积核大小为k×k的部分卷积,再进行逐点卷积;
5)特征融合.为充分利用不同分支获得的高层语义特征,将中层分支与下层分支特征图进行融合,并利用上层分支得到的全局信息为特征融合提供信息指导,避免了常规多层次特征融合缺乏信息指导的设计缺陷.
Xout=Xout1Xout2Xout3)(5)
式(5)中:、分别代表特征融合相加、逐元素相乘.
SECPM实现了多层次多通道的特征提取,完成了不同分支的特征融合,能够挖掘更丰富的高层语义信息,增加了模型对不同尺度裂缝的分割能力,同时引入部分卷积缓解了因扩大感受野带来的效率衰减的问题,提高了运算性能.
2.3 通道注意力模块
输入图像经编码器处理后将产生四层不同尺度的特征图,为抑制不同尺度特征融和时产生的冗余信息,本文在低层特征与高层特征融合处构建了通道注意力模块,其结构如图5所示.
首先将从低层上采样2倍获得的特征与高层特征在通道维度上进行拼接.为降低网络参数,同时实现信息快速流通,将拼接后的特征图在宽维度上拆分为X1、X2,X1∈RC×H×W/2在通道维度上分别进行全局平均池化Average Pooling,AvgP)和全局最大池化Maximum Pooling,MaxP)获取两个不同维度的全局信息,然后将两者相加融合得到池化后的通道权重特征Cweight∈RC×1×1.为打破通道约束,实现不同通道间信息流通,将得到的权重特征Cweight Reshape形状为C4×4×1×1,然后依次通过Transpose(4×C4×1×1)、Flatten(C×1×1),Sigmoid激活函数后得到最终的通道权重特征Cweight,通过改变权重特征形状再恢复,实现了跨通道信息交流,同时并未增加模型参数量.将得到的通道权重特征Cweight与原输入特征X1逐元素相乘后再与X2拼接用以恢复输入原有尺度,最后利用卷积调整其通道数后输出.
2.4 数据增强
为提高模型对于路面裂缝分割的泛化能力,而路面裂缝不受位置、形状等方面限制,并且截取裂缝局部任意一段都可单独作为分割目标.本文针对路面裂缝提出了一种随机替换(Random Substituting,RS)的数据增强方法,箭头方向代表选择区域替代方向,而所替代的区域并非直接替代,其效果如图6所示.
为保证新生成数据环境整体保持一致,而不引入其他差异较大的环境影响分割效果,因此仅在同一张图片上完成操作,其算法流程图如图7所示.
随机替换数据增强对分割目标存在一定限制,执行分割任务如果需要以一个整体作为分割目标,不能以局部单独作为分割目标存在,在训练时使用随机替换,产生的图像往往会失去其原有特征,容易对模型分割产生负面影响.
3 实验结果与分析
3.1 实验设置
实验环境为AMD Ryzen 7 5800H CPU,16 GB内存,GeForce GTX3060 GPU,Windows 10 操作系统,在 Pytorch 框架下完成实验.
本文为验证改进模型的有效性,在公开数据集Crack500[15]上进行了实验验证.Crack500数据集共3 368张图片,将数据集按照8∶2的比例划分训练集、验证集,为加速模型训练,加载预训练MiT-B1模型参数作为预训练权重.
3.2 评价指标
本文除采用神经网络常用的准确率Precision,P ),召回率Recall,R )、调和均值 F1作为指标外,还采用平均交并比(mean Intersection over Union,mIoU)作为评价指标,以M表示.
mIoU=1k+1∑ki=0pii∑kj=0pij+∑kj=0pji-pii(6)
式(6)中:k为有效类别数目,pij表示真实标签类别i预测为类别j的像素数,故pii、pij、pji分別表示正阳性像素点、假阳性像素点以及假阴性像素点.
3.3 网络性能对比
为客观评价本文所改进模型分割路面裂缝的性能,将本文改进模型与PSPNet、HRNet、Deeplabv3+以及SegFormer等方法进行多次对比实验,并取实验的平均值作为评价指标结果,其结果如表2所示.
通过表2可以看出,本文所改进的模型相较于近年优秀模型表现出更好的检测性能.与基准模型SegFormer相比,模型表现更加优秀,调和均值F1和mIoU指标上分别提升1.03%、1.32%,获得更好的检测性能;与其他优秀模型对比,本文模型在调和均值F1分别高于PSPNet、HRNet、Deeplabv3+等模型3.55%、4.18%、2.87%,在平均交并比mIoU分别高于PSPNet、HRNet、Deeplabv3+等模型4.07%、4.92%、3.69%.本文所改进的路面裂缝分割方法明显优于其他对比模型,这是因为路面裂缝Crack500数据集检测目标形状各异,大小不一,而本文所设计的SECPM能够兼顾不同尺度的特征融合,挖掘更丰富的高层语义信息,并提出了随机替换的数据增强方法,提升了模型分割的泛化性能.
本文模型与SegFormer、Deeplabv3+、PSPNet等模型进行了可视化对比,如图8所示.
由图8可知,在第一行图片当中,改进模型对于细长裂缝比其他模型能够较为完整的展现出裂缝全貌,仅漏掉少部分目标;在第二行图片当中,改进模型对于裂缝大小在逐渐发生变化,且在原图当中裂缝表现不明显的图片中,能够挖掘更多的图片细微特征,较为明显的展现出了裂缝的细节信息;在第三行图片当中,改进模型对于裂缝较大的目标在展现细节和裂缝完整程度等方面同样能够表现出更好检测效果.
3.4 消融实验
为了解所改进解码器FFN中各个模块对于提升模型性能大小,本文设计了相应的消融实验.本文共设计了5组不同的消融对比实验,如表3所示.P1为对SegFormer进行测试,解码器为原始的MLP;P2~P5则将解码器更换为本文所设计的特征融合网络FFN,并逐次增加CAM、SECPM、RS,通过比较模型的P、R、F1、M来分析各个模块对于模型性能的提升.
从整体来看,相较于SegFormer模型,本文所改进的各个模块对模型性能都有所提升.SegFormer的解码器从MLP替换为FFN,将不同尺度的特征进行了特征融合,使得不同尺度的特征产生了联系,模型的准确率和平均交并比有了显著提升.而在不同尺度特征融合时将CAM嵌入其中,能够有效过滤掉在特征融合时所产生的冗余信息, F1、mIoU均有提升.将SECPM接入模型,从不同尺度来提取特征图所存在的细节特征,并进行特征融合加强,从表3中实际数据可以看出,所设计的SECPM能够更好的挖掘图像特征,准确率略微下降,但其他指标提升明显.最后,在训练时使用了RS数据增强方法,能够挖掘更多细节信息,使得模型对于分割裂缝具有更好的泛化性能, F1和mIoU分别提升0.65%、0.28%,表现出更好的分割效果.
3.5 注意力模块对比实验
为验证提出的CAM对于模型性能提升有效,与CA[16]、GAM[17]以及CBAM[18]进行了横向对比实验.从表4所示的注意力模块横向对比实验当中可以看出,在不添加注意力模块时F1与mIoU仅为89.13%和81.39%,而在特征融合时添加不同注意力机制产生了各不相同的结果,融合GAM、CBAM后,模型性能不升反降,主要由于高低层特征是基于通道维度上的融合,空间融合后使得模型结构冗余,性能衰退,而在添加自行设计的CAM之后,模型性能提升最明显,F1与mIoU分别提升0.14%和0.36%.结果表明本文所提出的CAM可以有效实现高低层的特征融合,提高模型对裂缝的分割性能.
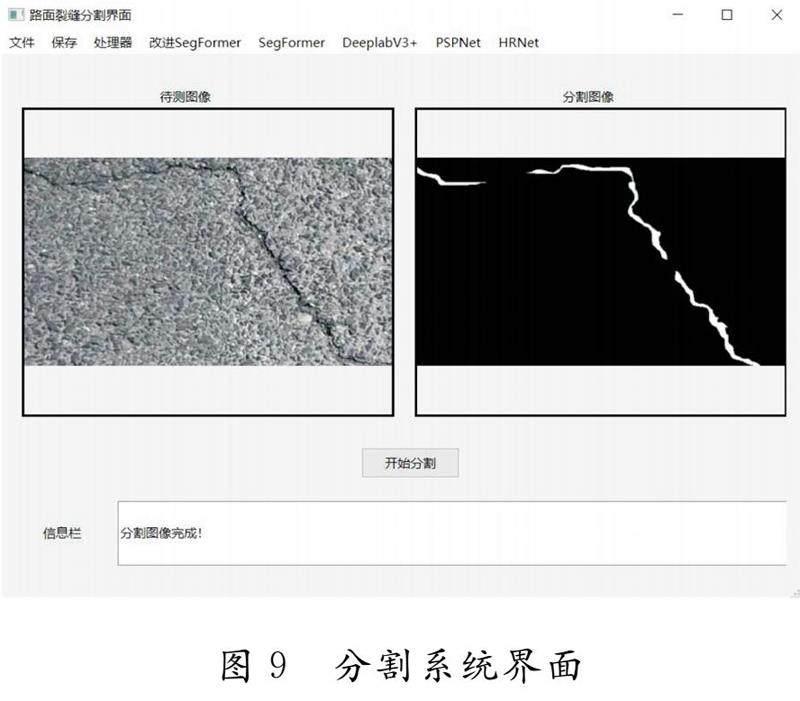
3.6 系统界面
基于改进模型具有较好的裂缝分割能力,使用QT6为其设计了一套分割程序界面.该系统界面支持正常的文件导入、保存以及退出功能,同时支持对一张图片使用不同网络模型完成分割.例如基于SegFormer、Deeplabv3+、PSPNet等模型的分割.该界面如图9所示.
图9 分割系统界面
4 结论
针对现有网络执行路面裂缝分割任务时,特征利用不充分、高层语义信息提取不足的问题,提出了一种改进SegFormer网络的路面裂缝分割算法,提出了一种提高裂缝分割模型泛化性能的数据增强方法;在网络结构上,设计了一种特征融合网络FFN作为分割网络的解码器,加强了特征层之间的联系,并对设计的CAM进行了横向对比试验;构造了空间高效卷积池化模块用于挖掘更深层次的高层特征信息,弥补高层语义信息不足的问题.在Crack500数据集上验证,改进模型相较于原模型在F1和mIoU指标上分别提升1.03%和1.32%,同时也优于其他主流分割模型,能够更好地适用在路面裂缝分割任务当中.
未来研究工作为:(1)将提出的数据增强方法进一步改进,并将其推广到其他分割任务,提高应用性;(2)将裂缝分割算法移植到机器人设备当中,通过分析像素区域大小,实现机器人对路面裂缝受损程度的自动化评估.
参考文献
[1] Cao W M,Liu Q F,He Q.Review of pavement defect detection methods.IEEE Access,2020,8:14 531-14 544.
[2] 王改华,翟乾宇,曹清程,等.基于MoblieNet v2的图像语义分割网络.陕西科技大学学报,2022,401):174-181.
[3] Cha Y J,Choi W,Büyükztürk O.Deep learning-based crack damage detection using convolutional neural networks.Computer-Aided Civil and Infrastructure Engineering,2017,325):361-378.
[4] umar P,Batchu S,Swamy S N,et al.Real-time concrete damage detection using deep learning for high rise structures .IEEE Access,2021,9:112 312-112 331.
[5] Han C J,Ma T,Huyan J,et al.CrackW-net:A novel pavement crack image segmentation convolutional neural network .IEEE Transactions on Intelligent Transportation Systems,2022,2311):22 135-22 144.
[6] 张伟光,钟靖涛,呼延菊,等.基于VGG16-UNet语义分割模型的路面龟裂形态提取与量化.交通运输工程学报,2023,232):166-182.
[7] Long J,Shelhamer E,Darrell T,et al.Fully convolutional networks for semantic segmentation[C]//2015 IEEE conference on Computer Vision and Pattern Recognition CVPR).Boston,New York:IEEE Press,2015:3 431-3 440.
[8] Hou Y,Liu ,hang T,et al.C-UNet:Complement UNet for remote sensing road extraction.Sensors,2021,216):2 153.
[9] Chen L C,Papandreou G,okkinos I,et al.DeepLab:semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs.IEEE Transactions on Pattern Analysis and Machine Intelligence,2018,404):834-848.
[10] Yu L J,eng X,Liu A,et al.A lightweight complex-valued DeepLabv3+for semantic segmentation of PolSAR image .IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2022,15:930-943.
[11] heng S,Lu J,hao H,et al.Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern RecognitionCVPR).New York:IEEE Press,2021:6 881-6 890.
[12] 翟軍治,孙朝云,裴莉莉,等.多尺度特征增强的路面裂缝检测方法.交通运输工程学报,2023,231):291-308.
[13] Xie E,Wang W,Yu ,et al.SegFormer:Simple and efficient design for semantic segmentation with transformers.Advances in Neural Information Processing Systems,2021,34:12 077-12 090.
[14] Chen J,ao S,He H,et al.Run,Don&apso;t walk:Chasing higher FLOPS for faster neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition CVPR).Vancouver,Canada:IEEE,2023:12 021-12 031.
[15] Yang F,hang L,Yu S J,et al.Feature pyramid and hierarchical boosting network for pavement crack detection.IEEE Transactions on Intelligent Transportation Systems,2020,214):1 525-1 535.
[16] Hou Q,hou D,Feng J.Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition CVPR).Online:IEEE,2021:13 713-13 722.
[17] Liu S,Wang Y,Yu Q,et al.CEAM-YOLOv7:Improved YOLOv7 based on channel expansion and attention mech anism for driver distraction behavior detection.IEEE Access,2022,10:129 116-129 124.
[18] Woo S,Park J,Lee J Y,et al.CBAM:Convolutional block attention module[C] //Proceedings of the European Conference on Computer Vision ECCV).Munich,Germany:Springer,2018:3-19.
【责任编辑:陈 佳】
基金项目:国家自然科学基金项目51775072)
作者简介:唐 源1998—),男,四川广安人,在读硕士研究生,研究方向:图像处理
通讯作者:董绍江1982—),男,山东烟台人,教授,博士生导师,研究方向:机电一体化技术,dongshaojiang100@163.com
