面向AI安全的深度伪造视频检测技术
2024-05-20李杏清王志兵杨润丰张金旺詹宝容
李杏清,王志兵,杨润丰,张金旺,詹宝容
(1. 东莞职业技术学院建筑学院,东莞 523808;2. 东莞职业技术学院电子信息学院,东莞 523808;3. 广东创新科技职业学院信息工程学院,东莞 523960)
0 引言
近年来,人工智能技术发展迅猛,智能机器人在很多细分领域超越了普通人,甚至是该领域的专家,例如说无人驾驶、阿尔法狗等。但是,随着人工智能的深入应用,一些负面的影响也逐步呈现出来,深度伪造(Deepfake)就是其中的一种,深度伪造由于应用了深度学习的框架和方法,在人脸图像合成或者视频生成方面都取得了很大的进步,很多时候可以做到以假乱真[1]。
2015 年,生成对抗网络的出现,在视频生成中取得了突破性的进展,使得深度伪造技术更加的成熟,人们可以轻易编辑功能强大且轻便的图像,甚至可以制作合成图像和伪造视频。合成图像编辑和视频生成一方面给人类带来了极大的便利,另一方面又给社会带来了潜在的威胁,以前的照片和视频是交通场景和法庭上非常有力的证据,但是现在却不得不去检测这些图像和视频的真伪,是否有人为编辑和软件生成的痕迹。因为合成后的图像和视频非常容易误导我们对事情的分析和判定,甚至歪曲犯罪事实[2]。因此,找到有效检测深度伪造视频的方法非常重要。
本文采用改进的基于双流分析的网络模型来检测深度伪造视频,该模型可以有效捕获深度伪造视频时域特征和空间域特征不一致的特性,解决了泛化性差的问题,在准确率和曲线面积等性能上优于各基线模型方法。
此外,我们在训练网络权重的时候考虑到输入图像中的遮挡信息,并鼓励网络关注未被遮挡的面部区域。该方法在两个公开数据集上进行了评估,并与几种基线方法进行了比较。实验结果表明,该方法在遮挡下的精度和鲁棒性都优于基线方法。
1 视频伪造检测技术
1.1 传统的视频伪造检测方法
传统的视频伪造检测技术主要依赖于视频编辑痕迹检测、复制移动检测、嵌入式水印技术和音频分析等方法[3]:
视频编辑痕迹检测旨在检测视频中的编辑痕迹,如剪切、粘贴、叠加等。常见的技术包括帧差分析、帧间距离度量和关键帧提取,以查找不一致或异常的帧。复制移动检测用于检测视频中物体的复制和移动。它通过分析视频中的物体运动模式来查找不正常的复制或移动。嵌入式水印技术经常用于一些制造和分发视频的机构,在视频中嵌入特定信息,以验证视频的真实性。这种水印可以是可见的或不可见的。由于音频数据也可以用于视频伪造检测,所以通过分析视频中的音频轨道,可以检测是否存在不合理的剪辑或添加。
随着技术的不断发展,视频伪造技术也在不断进步,因此传统的检测方法可能需要不断更新和改进,以适应新的伪造技术。新兴技术如深度学习和人工智能也正在被应用于视频伪造检测领域,以提高检测的准确性和效率。
1.2 基于深度学习的视频伪造检测技术
近年来,基于深度学习的视频伪造检测技术逐渐成为研究热点,越来越多的学者从事相关的研究和改进,有基于单帧的图像特征的视频检测,有基于不同帧之间的时间特征的视频检测等。
Masi 等[4]提出一种隔离视频深度造假的双分支循环网络,该方法基于稠密连接层的双分支表示提取器,使用多尺度拉普拉斯高斯算子学习组合来自色域和自由频率域的信息,高斯运算符抑制低级特性映射中出现的图像内容,充当带通滤波器来放大伪影。该方法还使用了一种新颖的损失函数,促进了自然的面孔表征的紧密性,并推开被操纵的面孔,以获得更好、更宽的分离边界,这与使用二元交叉熵来检测面部操纵的方法不同。
Qian 等[5]把频率引入人脸伪造检测中,提出了一种新的人脸伪造频率网络(F3-Net),利用两种不同但互补的频率感知线索,频率感知分解图像分量和局部频率统计,深度挖掘伪造模式,并通过双流协作学习框架,应用DCT 作为频域变换。通过综合实验研究,证明了所提出的F3-Net 模型在所有压缩质量上明显优于当时其他检测方法,特别是在具有挑战性的face Forensics++数据集中取得了良好的实验效果。
Zhao等[6]将深度伪造检测描述为一个细粒度的分类问题,并提出了一种新的多注意力深度伪造检测网络。该网络由三个模块组成:多空间注意力模块、纹理特征增强模块和特征融合模块,多空间注意力使网络关注不同的局部部分;纹理特征增强块放大浅层特征中的细微伪影;特征融合模块对低层次的纹理特征和高层次的语义特征进行聚合。此外,为了解决该网络的学习困难,作者进一步引入了一种新的区域独立性损失和一种注意力引导的数据增强策略。通过在不同数据集上的大量实验,证明了该方法优于普通的二元分类器,并实现了较好的性能。
2 改进的基于双流分析的检测技术
2.1 数据预处理模块
对于深度伪造视频,针对拍摄场景的不同、拍摄角度的差异和遮挡程度的不同,最后得出的识别效果差别很大,因此,在检测之前,我们需要对数据集中的数据进行预处理。首先需要定位人脸位置,通过算法来检测人脸并使用边界框来定位人脸位置,如果是视频中变化的人脸,我们会把视频中的图像分成几个小的帧结构,每个帧结构识别出一个人脸图像,通过识别框来定位人脸位置,将每帧的识别框转换为视频。实验中我们将视频分为128帧,每帧的人脸视频裁剪为128*128大小,检测模型总体框图如图1所示。
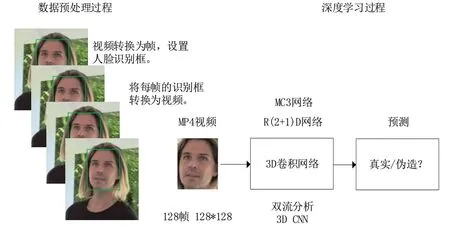
图1 检测模型总体框图
2.2 基于MC3和R(2+1)D的Deeper网络
R(2+1)D 包含空间卷积和时间卷积两个模块,这两个模块是相互独立的,一个是2D 的空间卷积,一个是1D 的时间卷积,如果分解后的网络和3D 网络采用相同的参数量,分解后的R(2+1)D更容易优化。
MC3 网络和R(2+1)D 不同,MC3 网络先是针对图像高级特征进行了2D 卷积处理,然后针对图像低级特征,在浅层进行3D 卷积运算,同时具备了2D 卷积和3D 卷积的优势,训练图像的分辨率采用128*128,损失函数采用交叉熵损失函数。
我们结合R(2+1)D 网络和MC3 网络的优缺点,设计了自己的Deeper 网络,该网络全部使用3D 卷积,加快了训练速度,提高了网络的性能。我们使用两个小的3*3 的卷积核代替大的7*7 卷积核,训练图像的分辨率采用128*128,激活函数选用ReLU 函数,这样既可以获得MC3网络3D 卷积的优势,又可以通过小卷积核代替大卷积核减小训练参数数量和计算机内存损耗。R(2+1)D 网络、MC3 网络和Deeper 网络如图2所示。

图2 R(2+1)D网络、MC3网络和Deeper网络
2.3 改进的基于双流分析的网络模型
本文在3D CNN 的基础上,利用自己训练出的Deeper 网络,设计出改进的双流分析网络模型,该模型采用两个通道同时处理RGB 数据和光流数据,一个通道进行RGB 数据处理,一个通道进行光流数据处理,通过Deeper 网络后进行叠加,最后得出分类的判定,是真实的还是伪造的。在实验中,Deeper 网络输入的数据为128 帧,每帧图像分辨率为128*128,激活函数选用ReLU 函数,最后一层使用softmax 函数来输出分类结果,在缩减训练参数的同时提高了运算速度,并且解决了泛化性不足的问题,改进的双流分析结构图如图3所示,改进的基于双流分析的网络模型如图4所示。

图3 改进的双流分析结构图
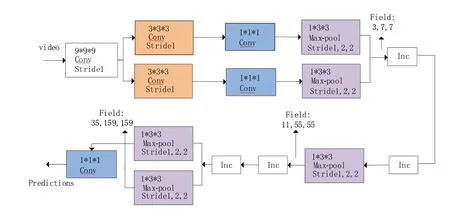
图4 改进的基于双流分析的网络模型
3 实验
本节描述了所进行的实验,以评估本文提出的网络模型在深度伪造视频检测中的性能。
3.1 数据集
随着Deepfake 伪造技术的发展,更大规模和更高质量的数据集不断被发布,我们使用Deepfake 数据集中Face Forensics++[7]来训练以及评估检测模型的性能。该数据集包含1000 real,4000 fake,一共四种伪造方法,包含三种分辨率,整体质量偏低,有明显伪像。
3.2 实验结果
实验的主要评估指标有准确率(ACC)、ROC曲线面积(AUC),HQ和LQ分别代表低压缩率和高压缩率。
其中:TP和FP表示正确检测到的像素数量和错误检测到的像素数量,FN为错误遗漏像素的数量。FPR为负正类率,即ROC曲线的横坐标,TPR为真正类率,即ROC曲线的纵坐标。
实验中,我们分别在FF++HQ和FF++LQ测试数据集中进行了测试和验证。在FF+ +HQ数据集中,验证得到的ACC和AUC都高于基线方法,其中,ACC的效果比较明显。在FF++LQ数据集中,得到的ACC和AUC都取得了较好的效果。实验结果见表1。
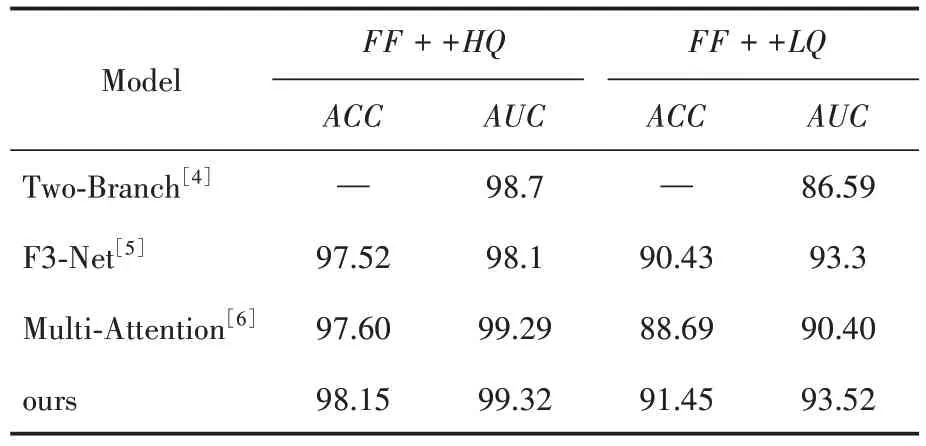
表1 FF + +HQ和FF + +LQ数据集中测试的结果(%)
3.3 结果分析
实验结果表明,Deeper 网络和卷积核的大小对网络性能的影响最为显著。去掉这些组件会显著降低网络模型的测检率和鲁棒性。同时,我们发现引入不同的损失函数和训练数据集也会对网络性能产生一定的影响。通过实验,我们可以更好地了解网络模型中不同组件的贡献,并进一步优化网络结构和训练策略,以提高网络性能。
4 结语
本文主要研究基于AI 安全的深度视频伪造检测技术,针对实际应用伪造类型多样化,而检测过程中只检测单一伪造数据类型等问题,提出了一种新的数据预处理方法,解决了视频中运动图像容易连续重叠的问题。针对人脸模糊伪造、侧面人脸伪造和遮挡人脸伪造问题,利用小卷积核代替大卷积核的方法训练出自己的Deeper网络;针对帧插入、帧复制、帧修改、帧内篡改四种常见的深度视频伪造,尤其是在测试领域差距较大的情况下,容易产生泛化性不足的问题,设计了一种基于双流分析的深度伪造视频检测模型,在Face Forensics++数据集的实验结果表明,该模型在ACC和AUC都取得了较好的效果。
