Scrapy框架辅助下的Python爬虫系统研究
2024-05-19吕新超
吕新超
摘要:为了解决传统网络爬虫在大型网站上提取信息效率不高的问题,研究引入了Scrapy框架作為Python网络爬虫的提取方法。以某图书网站为案例,文章深入分析了该网站的页面结构,编写了高效的爬虫文件源码,用于提取目标网站的关键信息,包括图书名称、价格、定价、作者和销量排名等。研究结果表明,通过对主流网站的信息提取实验,在实际应用中展示了该方法取得了良好的效果,可以成功提出需要的信息,并根据提取出的图书价格和销量排名信息可以分析出价格与销量之间的关系,实现了对大型网站的信息提取任务。研究为爬虫技术在数据采集和分析领域的应用提供了有力的支持,为信息爬取与处理提供了新的解决方案。
关键词:网络爬虫;Scrapy框架;Python语言;数据采集
中图分类号:TP393.09 文献标识码:A
文章编号:1009-3044(2024)07-0049-04
开放科学(资源服务)标识码(OSID)
0 引言
近年来,大数据信息技术的发展使全球范围内的网站数量呈现指数性的增长,每个网站都蕴含着丰富的信息资源,这些信息资源具有巨大的潜力,可用于揭示某一行业的规律、预测未来趋势,并满足网络终端用户的个性化需求[1]。然而,从海量数据中提取有效信息并实现个性化信息传递,并非一项简单的任务。为了应对这一挑战,研究人员和企业界正在积极探索各种技术和方法。其中,Python爬虫系统融合了Web抓取和数据挖掘技术,成为一个强大的工具[2]。
赵蔷[3]发现,利用Python爬虫可以在短时间内成功抓取大量有用的旅游数据,包括地区、购物、评价等信息,说明Python爬虫系统对于高效数据的抓取非常有效,可以帮助旅游者和旅行规划者更快地获取和理解旅游相关信息。Rismawan[4]发现,利用Python编程语言的数据爬取技术创建的新闻高效网站可以系统地显示来自各种来源的新闻在线网站,有效地从在线新闻中获取信息。马腾[5]发现,通过使用Python网络爬虫技术可以从房地产网站上抓取二手房信息,这表明数据爬取获取技术在获取大规模房地产市场数据方面非常有效,能够深入了解大城市的二手房市场情况,为政府和购房者提供有价值的市场意见和信息。
Scrapy框架作为高度可定制的Web抓取框架,能够采集、处理和分析Web上的数据信息。针对传统网络爬虫在大型网站上信息提取效率不高的问题,本研究采用了Scrapy框架作为Python网络爬虫的核心工具。以某图书网站为例,本研究深入分析了该网站的页面结构,并编写了高效的爬虫文件源码,用于提取目标网站的关键信息,包括图书名称、价格、定价、作者和销量排名等。研究的创新性表现在引入Scrapy框架作为Python网络爬虫的核心工具,从而提高了数据采集、处理和分析的效率和灵活性,共同推动了网络爬虫技术在数据采集和分析领域的发展,为更高效和可靠的信息提供了新的解决方案。
1 网络爬虫相关理论
1.1 网络爬虫定义
网络爬虫,也被称为网络爬取器、网络机器人或网络蜘蛛,是一种自动化程序或脚本,用于自动地浏览互联网上的网页并从中收集信息[6]。网络爬虫的主要目的是收集互联网上的数据,这些数据可以用于各种用途,包括搜索引擎索引、数据挖掘、信息检索、价格比较、网站更新监测等[7]。
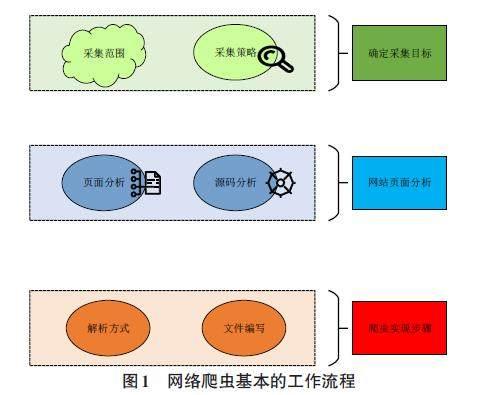
网络爬虫根据其功能、用途和行为特征有多种分类。通用网络爬虫广泛抓取互联网信息,如搜索引擎爬虫;聚焦网络爬虫专注于特定主题或领域,如新闻聚合网站;增量式网络爬虫定期更新已抓取数据的索引;深层网络爬虫访问难以到达的深层网页;垂直网络爬虫针对特定垂直市场;协作网络爬虫则是多个爬虫合作工作;爬虫机器人具有自主学习能力,选择爬虫类型需根据具体需求[8]。网络爬虫基本的工作流程如图1所示。
1.2 Python网络爬虫
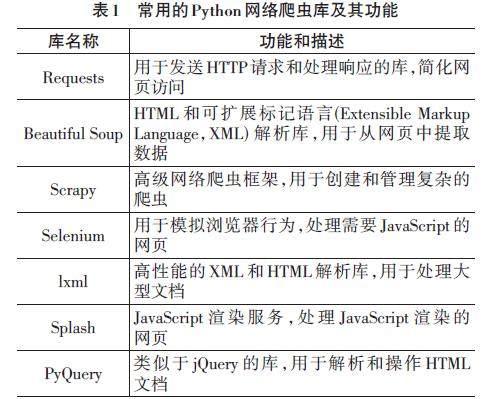
Python网络爬虫是一种基于Python编程语言的自动化程序,用于在互联网上浏览并抓取网页内容[9]。其主要功能包括发送超文本传输协议(Hyper Text Transfer Protocol,HTTP) 请求获取网页、解析超文本标记语言(HyperText Markup Language,HTML) 文档以提取所需信息以及存储或分析抓取到的数据。网络爬虫通常用于各种用途,包括数据采集、搜索引擎索引、信息检索、数据挖掘等,但在使用时需要遵守法律和道德规范,以确保合法和道德的数据采集行为[10],常用的Python网络爬虫库及其功能如表1所示。
1.3 Scrapy框架
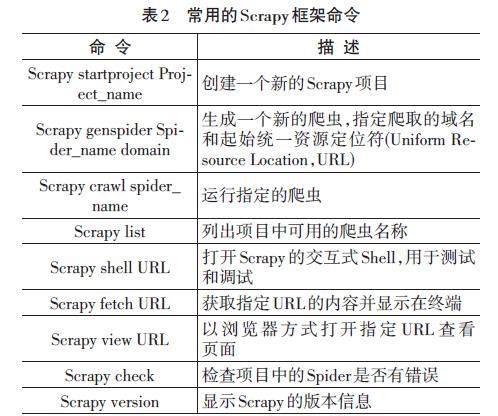
Scrapy是一个领先的Python网络爬虫框架,专注于高效且可扩展的大规模数据采集任务。其优势在于提供了一套全面的工具,包括HTTP请求管理、数据解析、链接追踪、异步处理等,以支持系统化的信息抓取工作。Scrapy允许开发者根据项目需求定制爬虫规则,并提供多种数据存储选项,使其广泛应用于搜索引擎索引、数据挖掘、新闻聚合等多个领域。这一框架拥有坚实的社区支持和详尽的文档,是研究和实践网络爬取任务的首选工具之一[11]。常用的Scrapy框架命令如表2所示。
Scrapy框架结构如图2所示,主要组件包括引擎(Engine)、调度器(Scheduler)、下载器(Downloader)、中间件(Middleware)、爬虫(Spiders)、项目管道(Pipelines)、下载中间件(Downloader Middleware)、扩展(Extensions),这些组件共同协作,构成了Scrapy框架的核心结构,使其成为一个强大且高度可配置的网络爬虫工具[12]。
引擎是Scrapy的核心组件,负责协调整个爬虫流程,包括处理请求、分发响应、触发爬虫中间件和管道等。调度器负责管理爬取请求的队列,并确保它们以合适的方式被发送到引擎进行处理。下载器负责从互联网下载网页内容,并将响应返回给引擎,处理HTTP请求、处理Cookies和处理重定向等。中间件是可自定义的组件,用于在请求发送和响应接收的过程中进行处理。爬虫是用户定义的规则,用于指定如何抓取和解析网页。每个爬虫通常定义了起始URL、如何跟踪链接以及如何解析网页内容。项目管道是数据处理和存储的组件,用于将爬取到的数据进行后续处理,如存储到数据库、写入文件或进行其他自定义操作。下载中间件是特定于下载器的中间件,用于在HTTP请求和响应的发送和接收中进行处理。扩展允许开发者自定义和扩展Scrapy的功能,可以编写扩展来添加新特性或修改现有功能的行为[13]。
Scrapy框架的数据流向[14]:首先,Scrapy引擎向Spider请求第一个要抓取的URL,然后Spider提供URL给引擎。接着,Scrapy引擎接收到URL并将其传递给调度器进行排队和排序,随后调度器将URL处理成请求(request)并将这些请求返回给Scrapy引擎。Scrapy引擎接收到这些请求后,使用下载器中间件将它们发送给下载器进行页面下载。下载器下载完成后,将页面内容封装在响应(response)中,并将响应返回给Scrapy引擎。Scrapy引擎接着使用Spider中间件将响应传递给Spider进行处理,Spider提取网站数据并返回结构化的item给Scrapy引擎,如果有跟进的请求(request)也会返回给引擎。Scrapy引擎接收到item后,将其交给项目管道(Item Pipeline)进行进一步处理,同时如果有新的请求生成,它会再次经过调度器,循环直到调度器没有更多请求。整个流程允许Scrapy框架高效地协调和处理网络爬取任务,包括数据抓取和处理。
1.4 Xpath查询语言
可扩展标记语言路径语言(XML Path Language,XPath)是一种用于在XML文档中定位和提取数据的查询语言。XPath的主要原理是根据路径表达式在XML文檔的节点树中进行导航和筛选,以便精确定位所需的节点。它是XML文档处理的重要工具,用于XML数据的查询、转换和提取,常用于Web爬虫、XML文档处理、XPath查询引擎等各种应用领域[15]。XPath路径表达式如表3所示。
1.5 网页爬虫设计
为了搭建网页爬虫的环境,首先需要下载安装Python 3.5,确保在安装过程中选择将Python 3.5添加到系统的环境变量(Path Environment Variable,PATH)中,以方便后续使用。接着,安装JetBrains PyCharm Community Edition 2018.1.4 x64,这是一个Python编程的集成开发环境,用于编写和管理爬虫代码。此外,还需要安装phpStudy,它包含了Apache或Nginx等Web服务器、MySQL数据库以及超文本预处理器(Hypertext Preprocessor,PHP) 环境,对于爬虫的开发和测试非常有用。最后,通过使用pip工具安装Scrapy框架,这是一个用于爬虫开发的Python框架,它提供了强大的工具和库来简化数据爬取任务。安装完成后,通过运行“scrapy version”命令来验证Scrapy是否正确安装。搭建环境后可以开始使用Scrapy进行数据爬取,以获取所需的数据。基于Scrapy框架下的Python爬虫系统流程如图3所示。
研究以某图书网站为例,基于Scrapy框架辅助下的Python爬虫进行了信息提取,主要信息包括图书名称、价格、定价、作者、销量排名等。基于Scrapy框架下的Python爬虫系统信息提取流程如图4所示。
2 基于Scrapy框架下的Python爬虫系统信息提取示例分析
2.1 应用示例分析
基于Scrapy框架下的Python爬虫系统信息提取应用示例如图5所示。
如图5所示,基于Scrapy框架下的Python爬虫系统应用示例显示了从某图书网站上获取有关图书的关键信息,主要包括书名、作者、价格、描述、折扣、出版时间、定价、出版社和销量排名等。这个系统成功提供了一个高效的数据采集工具,可以让用户能够方便地获取和比较各种图书信息,无须手动浏览网页,从而节省时间和精力。这对于图书爱好者、图书销售商和评测网站等各种应用场景都具有实际的价值,同时也为数据分析和决策提供了有力支持。
2.2 图书价格与销量排名描述型分析
图书价格与销量排名描述型分析结果如图6所示。
如图6所示,销量排名与价格之间存在明显的负相关关系。具体而言,销量排名靠前的产品通常表现出较低的价格水平,而销量排名靠后的产品则倾向于具有排名靠前的价格。排名前五的产品平均价格为23.28元,而排名后五的产品平均价格为11.82元,这强烈暗示了价格对产品销量排名的影响,反映了市场的竞争特点,消费者更倾向于购买价格相对较低的产品。该信息的分析结果为市场策略制定者提供了强有力的指导,强调了在竞争激烈的市场中,降低产品价格可能是提高销售排名的方法有效。
3 结束语
研究基于Scrapy框架下的Python爬虫系统,成功构建了一个高效的信息提取工具,以某图书网站为例,实现了对图书价格和销量排名等关键信息的自动化采集和存储。研究结果表明,基于Scrapy框架下的Python爬虫系统在获取、提取和分析数据方面表现出了强大的能力。通过分析图书价格与销量排名的关系,发现了一些有趣的趋势。在价格方面,本研究观察到图书的价格分布比较广泛,从低价到高价不等,但总体来看图书都集中在较低的价格区间,这可能反映了市场对于价格敏感度的体现。研究证实了基于Scrapy框架下的Python爬虫系统在信息采集和分析中的重要性和价值。通过自动化的方式获取相关图书的信息,能够更好地理解市场趋势、用户偏好,并为相关领域的决策提供数据支持。该方法不仅提高了数据的准确性和效率,还为驱动决策提供了充足的数据工具,具有广泛的应用前景。研究虽成功应用Scrapy框架下的Python爬虫系统进行数据提取与分析,但未来需要进一步探索数据的深层挖掘和多维分析,以更全面地理解信息关联性。
参考文献:
[1] 唐文军,隆承志.基于Python的聚焦网络爬虫的设计与实现[J].计算机与数字工程,2023,51(4):845-849.
[2] WAN B.Exploring the effectiveness of web crawlers in detecting security vulnerabilities in computer software applications[J].IJIIS:International Journal of Informatics and Information Systems,2023,6(2):56-65.
[3] 赵蔷.基于Python爬虫的旅游网站数据分析与可视化[J].电子设计工程,2022,30(16):152-155.
[4] RISMAWAN S A.Implementasi Website Berita Online Menggunakan Metode Crawling Data dengan Bahasa Pemrograman Python[J].Jurnal Teknik Informatika dan Sistem Informasi,2023,10(3): 167-178.
[5] 马腾,余粟.基于Python爬虫的二手房信息数据可视化分析[J].软件,2023,44(7):29-31.
[6] LUO K.A Study and Implementation of an Optimized University Library Book Recommendation System Based on Artificial Intelligence and Python Crawler Scraping Technology[J].Journal of Artificial Intelligence Practice,2023,6(2): 9-17.
[7] 刘萍.基于Python爬虫技术的网页数据抓取方法[J].信息与电脑(理论版),2022,34(14):169-171.
[8] KHAN N,HAROON M.A Personalized Tour Recommender in Python using Decision Tree[J]. International Journal of Engineering and Management Research, 2023, 13(3): 168-174.
[9] 孙握瑜.基于Python的新浪微博爬虫程序设计与实现[J].科技资讯,2022,20(12):34-37. (下转第56页)
(上接第52页)
[10] WU L,CHEN J S,ZHOU J.Teaching case design of python data analysis course for non-computer majors[J].Journal of Education and Educational Research,2023,3(1):97-99.
[11] 时春波,李卫东,秦丹阳,等.Python环境下利用Selenium与JavaScript逆向技术爬虫研究[J].河南科技,2022,41(10):20-23.
[12] LI C Y.Study based on SNOWNLP model mining of stock bar investors emotions on stock prices[J].Modern Economy,2023,14(6):778-795.
[13] 李通,姚新強.Scrapy框架下区域人口数据爬虫的设计与实现[J].软件导刊,2021,20(11):152-157.
[14] ZHANG X Y,QUAH C H,NAZRI BIN MOHD NOR M.Deep neural network-based analysis of the impact of ambidextrous innovation and social networks on firm performance[J].Scientific Reports,2023,13(1):10301.
[15] 黎妍,肖卓宇.引入Scrapy框架的Python网络爬虫应用研究[J].福建电脑,2021,37(10):58-60.
【通联编辑:代影】