大数据场景下基于Java的国产数据交换中间件
2024-05-18时晓旭赖俊业谢江余烨黄逸飞
时晓旭 赖俊业 谢江 余烨 黄逸飞
摘要:随着大数据时代的到来,数据处理的需求不断增长,尤其是对传感器产生的海量数据的处理需求,以及数据生产和消费之间的速度不同步问题日益突出。同时数据安全问题日益受到关注,国产操作系统的应用也逐渐增多。因此在国产操作系统环境下,需要一款国产大数据中间件解决数据生产和消费之间速度差的问题。基于Java技术,采用发布-订阅模型作为设计模式,实现了消息的发送者和接收者可以独立地演化和扩展,解耦数据的发送和接收过程,有效平衡数据生产和消费之间速度差。
关键词:大数据;数据交换中间件;国产操作系统;传感器数据
中图分类号:TP311.1 文献标识码:A
文章编号:1009-3044(2024)08-0052-04
开放科学(资源服务)标识码(OSID)
0 引言
随着物联网的迅速发展和传感器数据的激增,数据生产和消费之间的速度不同步问题日益突出。传统的数据缓冲方式之一是将数据暂时存放在数据库。然而,由于不同的应用系统需要调用数据库中数据,可能导致存在数据泄露的风险,存在安全隐患[1]。同时,频繁的I/O操作也会导致数据库读写性能下降[2]。Kafka是目前业界常用的开源数据交换中间件,它由Apache软件基金开发,能够进行分布式流处理[3]。但其是由国外厂商开发,对于中国特有的应用场景可能存在一定的适配问题,并且可能会面临技术授权的问题,进而影响后续的软件升级和服务,同时也存在数据隐私和安全方面的风险。因此,本文基于Java技术,采用发布-订阅模式,开发适用于国产操作系统的数据交换中间件。
1 中间件设计采用的相关技术和数据格式
1.1 Java
Java是一个广泛应用于软件开发的编程语言。选择Java作为开发语言最主要的原因是其具有跨平台特性。Java的跨平台特性源于其独特的编译和执行方式。Java源代码首先被编译成字节码而不是机器码,然后在目標平台上由Java虚拟机(JVM) 解释执行字节码。这种机制使得Java程序能够在安装了Java虚拟机的任何平台上运行,而无须重新编译[4]。
1.2 发布-订阅模式
发布-订阅模式是一种常用的软件设计模式,用于实现组件之间的松耦合通信。在该模式中,通常存在两个主要角色:发布者和订阅者。发布者负责产生事件或消息,并将其发送到一个或多个订阅者。订阅者则注册自己对特定类型的事件或消息感兴趣,并在发布者发送相应事件或消息时进行相应的处理。发布-订阅模式的核心思想为解耦发布者和订阅者之间的关系,使它们能够独立地演化。发布者不需要知道订阅者的存在,也不需要关心具体的订阅者是谁。同理,订阅者也不需要知道发布者的存在,只需要注册自己感兴趣的事件或消息即可。这种解耦使得系统更加灵活和可扩展[5]。在发布-订阅模式中,发布者和订阅者之间通过一个称为消息队列或事件总线的中介来进行通信。发布者将事件或消息发送到消息队列或事件总线中,而订阅者则从中获取感兴趣的事件或消息进行处理。这种中介的存在使得发布者和订阅者之间的通信变得简单和高效。发布-订阅模式在许多领域都有广泛的应用,例如消息中间件、事件驱动系统、GUI开发等。它能够有效地解耦组件之间的依赖关系,提高系统的可维护性和可扩展性。同时,它还能够实现异步通信,提高系统的响应性和性能。
1.3 数据格式
该中间件主要面对的数据为传感器产生的检测数据。在传感器端的服务器中,会将数据进行预处理操作,将数据格式转化为JSON格式,每条数据将包含以下内容:时间戳(记录数据采集的时间点)、传感器类型、采样频率、数据值和数据单位。
2 系统架构设计
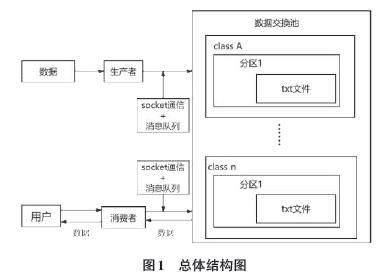
中间件总体结构如图1所示,主要由三大模块构成:生产者、消费者和数据交换池。生产者是向数据交换池发送数据的客户端应用程序,同时对外提供开发和调用接口,开发者可以调用其中包含的接口,向数据交换池发送数据或者设置数据交换池参数;消费者是一个从数据交换池中获取数据的客户端应用程序,同时对外提供开发和调用接口,开发者可以调用其中包含的接口,从数据交换池拉取数据;数据交换池部署于服务器中,主要作用为缓存数据和多线程处理数据读写任务,是中间件的核心模块。
2.1 生产者模块
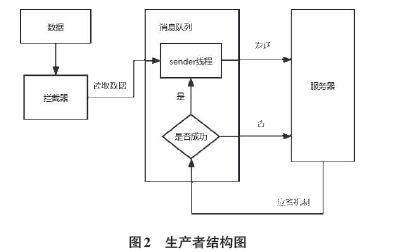
生产者模块结构如图2所示。生产者是为开发者提供的接口集合,开发者通过调用生产者提供的接口,将数据发布到数据交换池相应的Class中,通过配置消息分区方式和选择合适的消息序列化器实现可靠性设置,包括确认机制和重试策略。首先是开发者通过生产者创建Class,用户向数据交换池发送带有参数的请求,参数包括Class的名称以及分区数量等,以便在数据交换池开辟空间和设定数据管理的模式,同时向Class目录表添加新的Class记录;数据分区Class创建完成后,开发者通过调用生产者程序向指定的Class里写入数据。当数据开始流入时,首先要经过拦截器处理,拦截器的作用为:第一对数据的大小进行限制,若超过规定大小就要进行数据切分操作,第二对流入的每一条数据消息数据附加上事件时间戳(event time) 和UUID,形成每条数据的标识id,后期将以标识id作为数据的唯一标识对数据进行相关处理。
生产者与服务器的通信是基于Java的Socket通信和消息队列来实现的。当数据流出拦截器,会由sender线程发送到服务器,当服务器通过应答机制确认收到数据后会反馈给sender然后继续数据传输,若服务器没有收到数据服务器也会反馈给sender,sender就会重新发送数据,这里sender中设置最大重试次数和最大重试延迟时间。
应答机制具体内容:该应答机制支持三种模式,1) 当参数为0:生产者将不会等待任何确认信号,直接将消息发送到数据交换池并认为发送成功。这种方式是最快的,但是也最不可靠,因为如果消息未处理成功,则无法得知。2) 当参数为1:生产者会等待来自数据交换池中分区的确认信号。当分区成功写入消息后,生产者会收到确认信号。这种方式比参数0更可靠,但仍可能出现数据丢失的情况。3) 当参数为all或者ac当参数为-1:生产者会等待所有的副本都完成了消息的写入才会收到确认信号。这种方式是最可靠的,但同时也会影响性能,因为需要等待所有副本的确认。
2.2 消费者模块
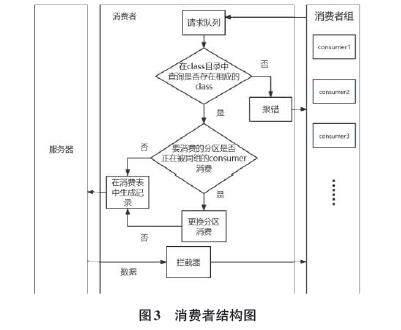
消费者结构如图3所示。消费者是为开发者提供的接口集合,开发者通过调用消费者提供的接口,订阅服务器中的Class,并从指定的Class中读取消息,可以配置消息消费的起始偏移量、消费组等参数。开发者调用消费者接口向数据交换池发送消费数据请求,请求的参数包括要消费的Class名称等。消费请求经过Socket通信进入请求队列中等待服务器响应。
数据交换池响应后,首先到Class目录表中查询是否存在对应的Class,若不存在则报错,若存在,继续查询消费表中要消费的Class的分区是否正在被同一消费者组中的consumer消费。若该分区正在被消费,则需要在Class下选择其他未被占用的分区进行消费,同时在消费表中生成一条记录,记录包括本次消费的Class和分区的名称,以及读取的最后一条数据的内容及时间等。数据读出后经过拦截器(这里的拦截器的主要作用为去除数据上的标识id) ,然后传递到开发者手中。
2.3 数据交换池模块
数据交换池结构图如图4所示。数据交换池部署于中央服务器,数据交换池内部的数据分类和分区设置是由开发者调用生产者相关接口进行设置的。开发者通过生产者上传的数据按照一定的规则存放在指定空间中,并按照开发者的设置定期清理数据。当开发者通过消费者提出消费数据的请求时,数据交换池会按照请求准备好相关数据。
数据交换池采用的存储策略为时间窗口策略。当任意一条数据进入服务器时,其自身携带的标识id已经带有自身的时间戳(event time),是每条数据的储存标识。用户可以通过指定时间段,也可以使用中间件默认的时间段,将同一时间段内接收到的数据写入同一个文件中。
在数据交换池内部采用以下存储模式:当开发者通过调用生产者相应接口,向数据交换池发送创建Class命令时,数据交换池会创建Class文件夹(Class名称由用户指定),在Class文件夾下又会建立几个分区文件夹(数量由用户决定),分区文件夹中存放着写有数据的文本文件。每个数据文本文件的名称以文件中所有数据里最小event time命名,分区文件夹名称以分区文件夹中最小数据文本文件名称命名。
数据交换池采取多种措施保障其安全、稳定和可靠:1) 备份机制。为保障数据可靠性,为每个Class创建相同结构的备份文件。2) 日志文件机制。数据交换池内部存在两张表,分别是Class目录表和消费表,由数据交换池内部的listener负责管理。Class目录表记录生产者所有的操作,以及服务器上所有Class的名称、其创建的时间、最新一条数据的标识id和哪些分区文件夹正在写入,目的是快速地查询所需的Class和内部数据的更新情况,同时保证分区文件夹的负载均衡。消费表记录消费者所有的操作,以及正在被消费的分区文件夹、正在消费的消费者信息、每个消费者每次消费的Class名称和最后一条消费数据等消费信息,此表的目的是保证在任何时间点只有一个消费者可以处理特定的分区。3) 内存缓冲读写机制。当生产者对数据文本文件进行写操作时,为每个生产者在内存中开辟一个长度可变的缓存空间。先将输入的数据写入缓存中,等待写入操作完毕后再从内存空间写入数据文本文件,并回收内存空间。这样既能够保证多并发操作,又不会降低写入速度。4) 消费者组机制。若多个消费者消费同一个Class的数据,则将这些消费者划为同一个消费者组并分配group id,确保每个分区只被消费者组中的一个消费者消费。在任何时间点只有一个消费者可以读取特定的分区文件夹,并且如果该消费者失败或离线,则另一个消费者可以立即接管。5) 定期删除机制。数据交换池会保存一定时间内的数据,并对过期数据进行定期删除,保存数据的时间可由开发者调用生产者相应接口设置。6) 监听者机制。在交换池内部设有一个监听程序(listener) ,主要负责监控并记录生产者和消费者的所有操作,以及对Class目录和消费表的管理。
2.4 系统测试
服务器测试环境为麒麟银河V10操作系统,系统界面如图5所示。测试环境通过VMware Workstation Pro软件搭建,配置了2个处理器,每个处理器拥有4个内核,分配了8GB内存和50GB的硬盘。在此环境中部署中间件的交换池模块,并创建用于测试的Class分区。
使用Java编写一个随机数据生成程序,通过调用生产者提供的相关接口向数据交换池中写入数据。数据生成程序的可设定参数包括每秒生成数据条数,数据格式为JSON,每条数据包含时间戳(记录数据采集时间)、传感器类型、采样率、数据值和数据单位。测试结果如表1所示。
使用Java编写程序,模拟实际情况中通过调用消费者提供的相关接口,从数据交换池中读取数据。测试结果表2所示。
3 结束语
本文主要围绕数据中间件的设计和功能实现展开论述,包括所采用的相关技术、理论概念,以及中间件的系统架构设计和最终测试。该中间件具备适配国产操作系统的能力,能够满足本土化需求,为国内相关企业在选择同类型中间件时提供更多选择。未来,该中间件的消费者模块可扩展链接不同数据库的接口,使开发人员能够更便捷地将数据直接存储到数据库中。
参考文献:
[1] 郭琼.计算机数据库的信息安全管理策略分析[J].电子技术,2023,52(10):326-327.
[2] 张志强,王伟钧,周利军,等.数据库读写策略在文本挖掘中的优化研究[J].成都大学学报(自然科学版),2015,34(3):262-265,274.
[3] 余建忠,谭任深.基于Kafka的海上风电场数据传输系统设计与实现[J].科技创新与应用,2023,13(31):26-31.
[4] 董正言.Java跨平台特性的实现原理[J].科技资讯,2014,12(18):20-21.
[5] 吴雯君.基于模式挖掘的发布/订阅分布式系统异常检测技术研究[D].南京:东南大学,2021.
【通联编辑:谢媛媛】
