基于特征解耦的少样本遥感飞机图像增广算法
2024-05-11刘牧云卞春江陈红珍
刘牧云,卞春江,陈红珍
1.中国科学院国家空间科学中心复杂航天系统综合电子与信息技术重点实验室,北京 100190
2.中国科学院大学计算机科学与技术学院,北京 100049
近年来,遥感图像采集和深度学习技术快速发展,遥感图像智能解译算法取得了重大突破[1]。空中目标检测与识别是遥感技术在军事侦察领域的重要应用,随着天基遥感影像分辨率提升及军事侦察工作的需要,空中目标细粒度检测任务对分类精确度提出了更高标准要求。但性能优异的深度学习模型通常依赖准确标注的大规模数据集训练,样本收集、人力标注需要耗费大量资源和精力[2]。并且,飞机目标的高动态特性以及复杂多变的背景环境导致其缺乏长期数据收集的客观观测条件,大规模、高质量的遥感飞机目标图像数据集存在收集困难的问题[3]。因此,现有的遥感图像飞机细粒度图像数据集往往存在各子类样本数较少且分布不均衡情况。基于数据驱动的深度学习模型容易在样本数量丰富的类别上过拟合,而在样本数量缺乏的类别上欠拟合,这种现象称为长尾效应,是导致导致分类、检测等模型的性能难以提升的重要因素[4]。为数据匮乏的类别生成更多样本图像补充原有数据集是缓解模型过拟合,提升下游模型性能的直接途径。
数据增强是解决样本不足、不平衡的关键技术。传统的数据增强方法包括仿射变化、色彩变换、信息遮挡、多图融合等,这类方法生成的样本虽然能在数量上对原有数据集做补充,但存在泛化能力差、样本多样性不足的瓶颈问题[5]。小样本图像生成技术是图像数据增广的一种方式,其仅利用少量未知种类的图像数据生成大量真实且多样的同类别图像,在不实质性增加数据的条件下,通过深度生成模型提高原始数据的数量和质量,让有限的数据产生等价于更多数据的价值,从而为细粒度图像分类、目标检测等多种的下游任务提供数据支持。并且,相比于上述传统数据增强方法,小样本图像生成技术能够提供更加多样的图像,并且在特征层面生成更加丰富和合理的语义信息。当前基于深度生成模型的图像生成方法往往依赖大规模数据集训练,提出一种少样本条件下的数据增广方法是有必要的。
小样本图像生成技术能够借助深度生成模型(deep generation models,DGM)从现有数据集中学习和模拟真实的数据分布,并生成新的图像。当前主流的深度生成模型可分为3 类:变分自编码器[6](variational auto-encoders,VAE)、生成对抗网络[7](generative adversarial networks,GAN)和扩散模型[8](diffusion models,DM)。GAN 网络由生成网络和判别网络两部分组成,以对抗的方式,交替优化网络参数,直到二者达到纳什均衡,从而生成以假乱真的样本。但GAN 网络对数据分布是隐式建模,并且在模型训练过程中容易陷入模式坍塌。DM 的基本思想是在正向扩散过程中系统地扰动原始数据分布,在反向扩散过程中学习如何恢复数据分布。DM 虽然在图像生成质量上优于GAN 和VAE,但其仍存在采样效率低、最大似然估计效果差、训练所需资源多的问题。VAE 是小样本图像生成技术的主流生成模型之一,其包含一个编码器作为推断网络和一个解码器作为生成网络。它是基于变分推断思想的概率模型,能够对于数据分布进行显式建模,这大大提高了生成样本的可解释性。总的来说,相比于其他生成式模型,VAE有可解释性强、训练稳定、资源消耗小的优势。
并且,近年来,VAE及其变体在医学影像分析、人脸识别、故障检测等领域取得了优异的表现并具有重要的实际应用价值。但在遥感图像处理的应用领域,仍缺少相应的数据增广方法。一方面,传统的VAE 方法需要大规模数据作为支撑用于训练模型,无法解决少样本条件下的数据增广问题;另一方面,由于真实场景下的遥感飞机目标图像存在类间相似度高、类内差异性大的特性,针对全局特征拟合的小样本图像生成算法难以生成高质量和多样性的细粒度飞机图像。
因此,针对目前空中高价值目标数据匮乏的实际问题,为了增强生成样本多样性和模型可解释性,采用基于特征解耦的小样本图像生成技术生成特征丰富的遥感飞机图像样本。在模型编码阶段通过变分推断和平均池化的方式分别提取图像的类内可变特征和类间判别特征,在解码阶段多次随机采样重组特征以提高生成图像多样性。并且,利用上述方法的生成结果补充现有数据集,有效提升了后续目标精细化识别准确率。
在本文中,做出了如下贡献:
(1)为解决生成样本多样性不足的问题,提出了“图像由类内可变特征和类间判别特征组成”的假设,并根据此假设构建特征解耦模块。
(2)改进原始VAE 结构,提出了特征解耦变分自编码器(feature disentangle variational auto-encoders,FD-VAE),用于在少样本条件下生成具有特征多样性、语义信息丰富的遥感细粒度飞机样本图像。
(3)在两个细粒度飞机数据集上FAIR1M[9]和MAR20[10]验证FD-VAE 算法生成图像的性能。将生成的样本补充到原有的数据集中形成增广数据集,并输入到下游ResNet-18[11]分类网络中验证数据增广对提升下游模型分类精度的效果,形成闭环实验。实验结果证明了本文方法在飞机图像生成效果上的优势以及对于下游模型分类准确率提升的有效性。
1 相关工作
1.1 小样本图像生成
随着人工智能的快速发展,越来越多的人试图解决低样本情况下的机器学习问题。小样本学习(few-shot learning,FSL)和图像生成结合的方法被称作小样本图像生成技术(few-shot image generation,FSIG),用于在数据规模有限的情况下,生成高质量、多样性的图像,增强原有数据集。FSIG是利用可见类别数据训练生成模型,再通过少量未知种类的条件图像来控制生成模型生成特定图像。通过生成额外的图像对小样本类别进行增强可以有效缓解小样本学习中由于训练数据类别不平衡(long-tailed)导致的过拟合问题,并从根源上解决实际应用中某些类别样本数量不足的情况。
许多相关研究内容已经发表,研究人员通过修改网络框架、损失函数、迭代方法等方式来构建新的生成网络,从而提高图像生成器的性能。从当前小样本图像生成模型的工作原理出发将小样本图像生成方法分为优化法、类内转换法以及特征融合法。
优化法是指将元学习(meta-learning)算法与深度生成模型结合的小样本图像生成方法[12-14],其基本原理是在可见类别数据上用元学习算法框架训练生成式模型,在少样本数据集上进行参数微调后得到针对小样本类别图像的生成器。基于优化的方法能够成功生成图像,但生成图像往往不够清晰和真实,在图像生成质量上还有较大的提升空间。
基于特征融合的小样本图像生成[15-17]是指通过全局或局部特征匹配的方式将多张条件图像特征融合并形成新样本的方法。LoFGAN[17]提出的局部融合策略,解决了由于条件图像语义信息不对齐导致生成样本存在混叠伪影的不合理现象,但仍存在生成样本多样性不足的问题。由于特征匹配和融合理论的固有限制,目前的融合方法难以在生成图像形状、姿态等方面做出改变。并且,此类方法需要输入多张条件图像,并不适用于单样本图像生成。
类内转换法[18-20]的基本假定是同一类别不同样本之间的差异是能够泛化到其他的类别中的。用大量的可见类别样本中训练模型学习如何提取和转换的类内可变特征到非可见类别样本中,生成新样本。近年来,基于类内转换的方法实现了从小样本特征增强到图像生成的进步。AGE[20]试图在编码好的隐空间中学习有效的特征编辑方向,通过编辑特征向量生成多样性的图像,实现了在没有明确监督的情况下的特征解耦和图像编辑,但仍需要借助预训练到解码和图像到编码的逆转换模型。
相较于基于优化和基于融合的小样本生成方法,基于类内转换的方法在生成更加多样性的图像上具有显著优势。因为类内转换的方式能够学习到条件图像可移植的类内可变特征或可编辑属性,并借此生成更加多样化的同类别图像,这种方法有效地提升了模型的创造力。另一方面,在图像生成的真实性和清晰度上,基于类内转换的样本生成方法也达到了当前最为先进的水平。
随着小样本图像生成领域的研究逐渐深入,其应用场景也愈加丰富。如今,小样本图像生成技术广泛应用于医学影像分析[21]、故障检测[22]等领域,具有重要的实际应用价值。相对来说,小样本图像生成技术在遥感图像增广领域的相关研究比较匮乏。虽然一些遥感场景下基于深度生成模型的建筑物[23]、飞机[24]、船舶目标图像[25]数据增广方法被提出,但均没有考虑少样本条件下的图像生成问题。姜雨辰等人[26]提出改进StyleGAN2方法适用于少样本条件下的遥感图像数据增强,但此方法主要针对遥感图像中的大型建筑目标,生成样本缺乏局部细粒度信息。
在少样本条件下,提出一种遥感细粒度图像生成方法用于数据增广是有必要的。因此,针对当前小样本遥感图像生成的应用领域缺少解决细粒度图像增广方法的实际问题,本文提出了基于类内转换法的图像生成算法特征解耦变分自编码器FD-VAE 用于少样本条件下的光学遥感飞机细粒度目标图像增广,助力下游分类模型精度提升。FD-VAE 每次仅输入一张条件图像即可生成多样性的增广样本,实现完成1-shot 生成。并且,相较于当前基于类内转换法的模型结构,FD-VAE无需任何预训练和逆转换模型。
1.2 变分自编码器
2013年Kingma提出了基于变分推断思想的概率生成模型VAE,其整体结构如图1所示。在训练阶段VAE的编码器作为推断网络拟合数据分布,将输入样本映射为隐空间的概率分布,解码器作为生成网络用于重构图像。在生成阶段,网络使用采样器在潜在空间的概率分布中随机采样,再输入到已训练的解码器用于生成新的图像。VAE 的基本原理是利用逼近变量后验概率变分下界的方式拟合目标数据的最大似然概率分布,再利用重采样的方式生成多样化目标数据集。
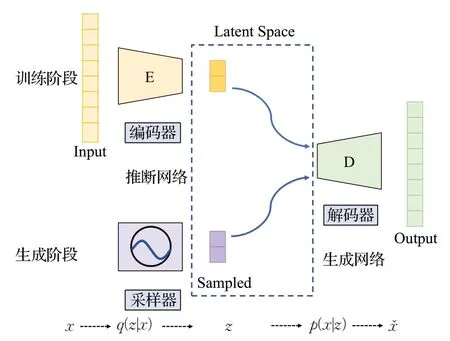
图1 变分自编码器结构图Fig.1 Basic structure diagram of VAE
假设每个真实样本Xk都存在一个专属分布p(Z|Xk),那么整体输入数据的概率分布p(x)可表示为:
由于分布q(z|x)计算较为复杂,对上式求对数似然,可得到:
根据詹森不等式,可推出:
VAE将数据概率分布p(x)的推断问题转化为近似分布q(z|x)的优化问题。式(3)称作分布logp(x)的变分下界(evidence lower bound,ELBO),其标准形式表示为:
如图2 所示,输入样本图像x,编码器通过优化分布q(z|x)使得变分下界L最大化,将输入数据映射到隐空间中,得到隐变量z的压缩表达:

图2 变分自编码器原理图Fig.2 Schematic diagram of VAE
为了避免采样噪声为0 导致生成模型的随机性减少,VAE假设p(z|x)服从正态分布,式(5)可表示为:
隐变量z可以在分布N(μ,σ)中采样得到,但此过程不可导。为解决此问题,VAE 使用重参数技巧,先在分布N(0,I)中采样ε,再经线性变换得到:
最终,在训练阶段,解码器将采样到的隐变量z重构为原图像。在生成阶段,解码器将隐空间中随机采样的点还原为图像,从而生成新样本。
VAE 以其优雅的推断理论和稳定的训练过程在图像生成领域大放光彩,并迅速涌现出一系列基于VAE的改进模型。VAE 系列改进方法根据其工作原理大致可分为3 类,增加条件约束提升模型的用户控制能力、通过分解隐变量提高生成图像清晰度、将VAE 与GAN等其他深度生成模型结合,增强模型生成性能和生成图像多样性。
(1)增加条件约束
VAE能够实现用给定的随机噪声生成图像,但其生成结果是不可控的。为了生成指定类别的图像,如图3所示,条件变分自编码器(conditional variational autoencoder,CVAE)[27],在输入阶段同时输入图像x和其对应的类别标签y,用于约束生成图像的类别。编码器从估计样本图像在潜在空间的概率分布p(x)扩展为估计隐变量的条件概率分布p(x|y),解码器在标签的监督下重构图像,从而生成指定标签类别的样本。

图3 条件变分自编码器原理图Fig.3 Schematic diagram of CVAE
动态变分自编码器(dynamical variational autoencoder,DVAE)[28]输入数据改进为序列数据x1:T,按照时间序列分解输入序列和隐变量序列如式(8)所示:
其中,x、z、u分别为模型的输入序列、隐变量和控制变量,变量之间遵循时间链式法则。
DVAE 考虑了数据向量的序列以及对应的隐变量的序列在时间维度上的关联性,常用于音频或视频生成,但对于输入数据规模和质量要求较高。以上两种相关方法都是为输入变量增加关联约束,从而促使模型生成特定类别或时间的样本。
(2)分解隐变量
Nouveau VAE[29](NVAE)引入多尺度设计,分层次设置了多组隐变量,再利用自回归的高斯模型拟合复杂的连续型分布,其模型框架如图4所示。
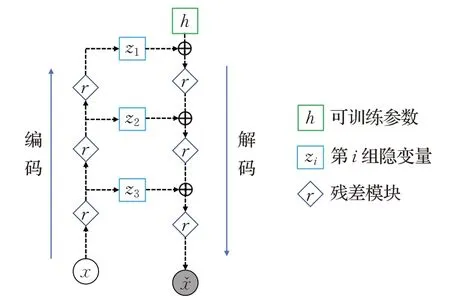
图4 NVAE框架图Fig.4 Framework diagram of NVAE
具体来说,NVAE通过设计多尺度的编码器将原有的隐变量z分解为L组隐空间中的向量,即:
并为分解后的每个隐变量z1,z2,…,zL建立高斯分布,将整体模型建立为自回归高斯模型,后验概率分布可表示为:
最终,解码器自上而下地利用多组隐变量实现样本图像的还原。
不同于NVAE构建多尺度隐变量,量子化自编码器[30](vector quantized variational autoencoder,VQ-VAE)为解决连续隐变量逼近精度有限的问题,将图像编码为离散的隐变量,再通过自回归模型拟合离散分布。这类分离隐变量的改进方法有效提高了生成图像的清晰度,但其训练代价也显著增大。
(3)与其他深度生成模型结合
自省变分自编码器[31](introspective variational autoencoder,IntroVAE)借助GAN网络对抗训练的思想构建自省变分自编码器,将生成图像循环输入到编码器中。如图5所示,编码器不仅作为需要获得输入图像的概率分布,它还充当一个“判别网络”,将真实输入图像与解码器生成的图像区分开。相对地,解码器希望尽可能真实地重建图像来欺骗编码器。最终,IntroVAE通过编码器、解码器交替对抗训练的方式进一步提升了模型的图像生成质量。Soft IntroVAE[32]进一步解决了IntroVAE中需要人为设定硬边界阈值的限制,并且训练过程更加稳健。这类与其他深度生成模型结合的改进方法虽然有效提高了模型的生成性能,同时也存在训练不稳定的问题。
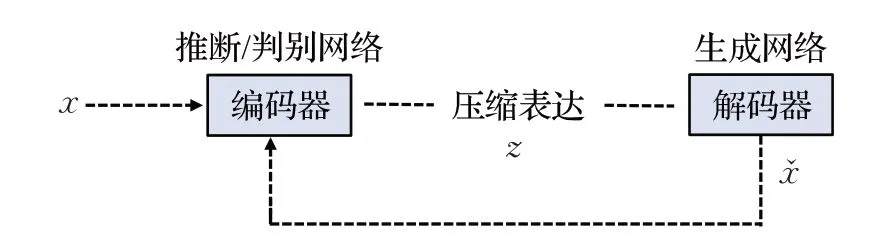
图5 Intro-VAE原理图Fig.5 Schematic diagram of IntroVAE
提出的方法FD-VAE与以上三类改进思路不同,上述相关方法仅针对图像层面的样本进行还原和重构,主要关注隐层编码在图像色彩和结构上的还原能力,其构建的隐空间往往存在不均匀和无规律的情况,这一定程度上限制了生成样本的可解释性和多样性。针对以上问题,为在平滑、连续的潜在空间中随机采样或插值得到有意义和可解释的样本,并且进一步增强模型生成结果的多样性和语义信息合理性,本文提出的解耦变分自编码器FD-VAE 一方面使用特征解耦模块促使模型在解码阶段进行特征层面的学习,试图让模型“理解”样本的语义信息,从而生成更加有意义的样本图像。另一方面,在模型解码阶段引入特征调节因子α,控制判别特征和可变特征的重组关系,从而提高模型生成样本的多样性。
2 改进的解耦变分自编码器
2.1 基本原理和网络结构
由于遥感飞机目标图像类间相似度高、类内差异性大的特性,提出的图像由类内可变特征和类间判别特征组成的基本假设。类内可变特征包括光照、阴影、飞机涂装、飞机停放角度、背景条件等环境因素,这些特征在所有类别中共享,即在真实环境下,不同型号的飞机样本可能存在相似的停放角度、背景条件、光照条件等环境特征。在数据模拟阶段,使用共同分布p(zv)为类内可变特征建模。类间判别特征指飞机的型号特征,如引擎数量、气动结构等。相同类别的飞机样本具有同样的类间判别特征,因此,对每个类别的样本图像特征求均值即可得到各个类别飞机的类间判别特征。在图像生成阶段,通过多次随机采样的方式增强生成样本环境特征多样性,从而更改同类别样本的类内可变特征,达到生成大量类别相同而环境特征多样的样本图像的目的。
基于上述假设提出了特征解耦变分自编码器FDVAE,其原理图如图6所示。不同于VAE及其衍生模型使用变分推理的方式拟合整体图像特征概率分布,而是仅拟合图像的类内可变特征分布,即阴影、飞机涂装、飞机停放角度、背景条件、光照条件等客观环境因素,并结合平均池化模块提取图像的类间判别特征,从而分离类间判别特征和类内可变特征(客观环境特征),并通过多次随机采样和特征重组的方式达到提升生成样本多样性的目的。
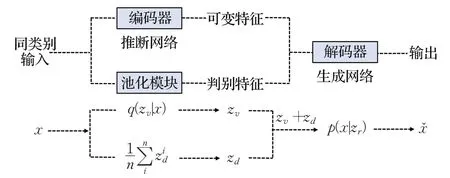
图6 FD-VAE原理图Fig.6 Schematic diagram of FD-VAE
FD-VAE 的整体网络结构如图7 所示,包含一个特征提取器、一个编码器用于拟合类内可变特征zv、一个池化模块用于提取类间判别特征zd,一个解码器和一个特征重构器用于重构和生成图像。特征提取器选用基于卷积层的残差网络,它包含两个残差模块。图像重构器相比于特征提取器增加了一个全连接层用于分类重构图像,确保生成图像的判别特征保持不变。
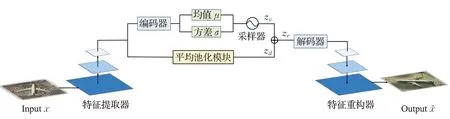
图7 FD-VAE网络结构图Fig.7 Framework of FD-VAE
2.2 特征解耦模块
特征解耦模块由编码器和池化模块组成。基于输入图像xi的特征是由类内变量特征和类间判别特征组成的假设,图像特征可以表示为:
其中,输入图像xi对应特征图X(i)的类间判别特征zd由多个同类别图像特征图的平均池化得到。
其中,n为批量数(batch size,BS)。
真实的后验分布p(z|x)难以计算,可用分布q(z|x)近似推断p(z|x),并用KL散度约束二者间的距离:
进一步假设近似后验分布p(z|x)是各项独立的正态分布,表示为:
其中,μ(i)、σ(i)由编码器拟合数据分布得到,根据公式(10)和重参数技巧,zv可以表示为:
最大化p(x)的变分下界使得真实后验分布与近似分布之间的差距最小,可表示为:
其中,p(X|z(i))由解码器提供。
每个输入条件图像唯一确定一个类内判别特征zd:
lbp(x)的变分下界可写为:
编码器通过优化式(19)变分下界和多次采样获得样本的可变特征。
图像生成阶段,为了生成更多样的样本,在生成阶段FD-VAE引入了特征调节因子α,用于控制重构特征中类间鉴别特征zd和类内变量特征zv的比例。特征向量zd、zv均归一化后:
2.3 损失函数
损失函数由重构损失、KL损失和分类损失组成。
分类损失用于确保池化模块所提取到类间判别特征zd的准确性:
其中,y(i)表示输入特征图X(i)的类别标签。
重构损失和KL 损失用于监督编码器学习数据分布,由于p(X|zr)被建模为近似高斯分布,lbp(X|zv)等价于x和p(X|zr)均值的平方误差重构损失,lbp(x)的变分下界可写为:
式(23)的前半部对应重构损失,后半部对应于KL损失。βrec和βkl是重构损失和KL 损失对应的超参数权重。
为了与编码器变分下界的重构约束保持一致,采用加权图像级MSE重构损失来约束解码器生成的图像Xr:
编码器的目标函数包括分类损失和变分损失,变分损失由KL损失和重构损失组成。
解码器的目标函数包括分类损失和重构损失:
其中,βcls、βrec、βkl分别对应分类损失、重构损失和KL损失的超参数权重。
FD-VAE 网络根据上述三类目标函数进行端到端优化。
3 实验结果与分析
3.1 数据集
本文选取两个细粒度的遥感图像数据集FAIR1MAircrafts[9]MAR20[10]作为模型效果评估的数据集。这两个数据集的飞机类别不重叠。
(1)FAIR1M-AIRCRAFTS:在FAIR1M 数据集中截取了9 种不同类型的民用飞机图像,共19 299 个示例。其中7 个类别被设置为可见类别,用于训练,另外两个被指定不可见类别,用于测试。
(2)MAR20:MAR20 包括20 种军用飞机,共有22 341 个示例。其中,16 个类别用于训练,其余4 个类别的样本用于评估。
3.2 实验部署
本文的网络采用端到端的形式进行训练,输入图像大小为64×64,批量数为32,共迭代300次。在超参数设置方面,对于FAIR1M-Aircraft 数据集,超参数设置为βcls=1,βrec=2,βkl=4,z_dim=512 ,其中z_dim表示隐特征空间的维度。对于MAR20 数据集,潜在编码维度是512,其他参数设置为βcls=1,βrec=4,βkl=8。在测试阶段,遵循标准的小样本图像生成评估方案。根据1-shot和3-shot的实验设置,每次使用1或3张未见类别样本图像输入到生成器。
3.3 生成图像质量分析
将本文提出的FD-VAE方法分别与原始VAE方法、引入对抗训练的VAE 方法IntroVAE、基于特征融合的样本生成方法LoFGAN 以及基于类内转换的样本生成方法AGE对比生成图像质量。
采取了一系列试验验证FD-VAE 在图像生成方面的性能,包括生成图像的定性和定量分析实验用于评估生成图像质量,特征解耦消融实验用于验证本方法的特征可分性以及隐空间的线性插值实验用于验证本方案生成图像的多样性和真实性。
3.3.1 生成图像质量定性评价
将FD-VAE(1-Shot,每次生成仅使用1个输入样本)与LoFGAN(3-Shot,每次生成使用3 个输入样本)、AGE(1-Shot)方法在FAIR1M数据集上的生成图像进行定性比较。
如图8 所示,前两列是输入真实样本,其余各列分别是AGE、LoFGAN 和提出的FD-VAE 算法生成结果。第1 至5 行分别展示了输入样本在一般情况下、存在多目标实例或实例不完整、存在涂装、存在尾影、高曝光或阴影条件下各方法的图像生成结果。AGE方法生成的图像清晰度较高但生成的飞机主体存在局部扭曲的现象,并且当输入样本实例不完整、存在局部涂装时,AGE难以重建图像。LoFGAN 方法虽然能够完成各种情况下的图像重建,但存在重构机身不完整、局部模糊的现象。相比之下,FD-VAE在生成图像清晰度和真实性方面优于其他方法,而且具有很好的鲁棒性。

图8 LoFGAN、AGE和FD-VAE方法生成图像质量比较Fig.8 Comparison between images generated by LoFGAN,AGE and FD-VAE
3.3.2 生成图像质量定量评价
选取FID[33]和LPIPS[34]两个定量指标评估图像的生成质量。
FID(fréchet inception distance)指标用于计算真实样本、生成样本在特征空间之间的距离,表示生成图像分布和真实图像分布的距离,较低的FID意味着较高图片的质量,其表达式如下:
其参数是将图像真实分布Pr和生成图像分布Pg建模为多维高斯分布(μr,Σr),(μg,Σg),其中μ、Σ分别表示均值向量和协方差矩阵,tr 表示矩阵的迹(矩阵对角元素之和)。
学习感知图像块相似度(learned perceptual image patch similarity,LPIPS),用于度量两张图像在数据分布上的差别。对于生成样本集来说,较高的LPIPS代表图像具有较好的多样性和真实性,其计算表达式为:
其中,d为x与x0之间的距离,l为特征提取堆的层数,Hl、Wl分别为通道的行和列数。
在评估阶段,FD-VAE 对于每个不可见类别的测试样本生成1 024张图像用于计算FID和LPIPS。
表1、表2 分别展示了本文的方法和其他几种先进的小样本图像生成方法在FAIR1M-Aircrafts 和MAR20数据集上的测试结果。所提出的FD-VAE 方法与其他方法相比在FID 和LPIPS 评价指标上取得了显著改进。与原始VAE生成方法相比,本文的方法在FAIR1M数据集上的测试结果FID下降了20.07%,LPIPS上升了13.21%。在MAR20 数据集上的测试结果FID 下降了21.83%,LPIPS上升了21.36%。这表明FD-VAE生成的图像具有更好的特征多样性和图像真实性,本文方法的核心优势在于从编码器拟合的数据分布N(μ(i),σ(i))中多次采样类内可变特征zv并保持与原始图像相似的判别特征zd。前者提高了生成图像的多样性,后者保证了生成图像的真实性。这使得本文方法的生成结果与其他方法相比,在真实性和多样性的评价指标上表现出极大的优势。
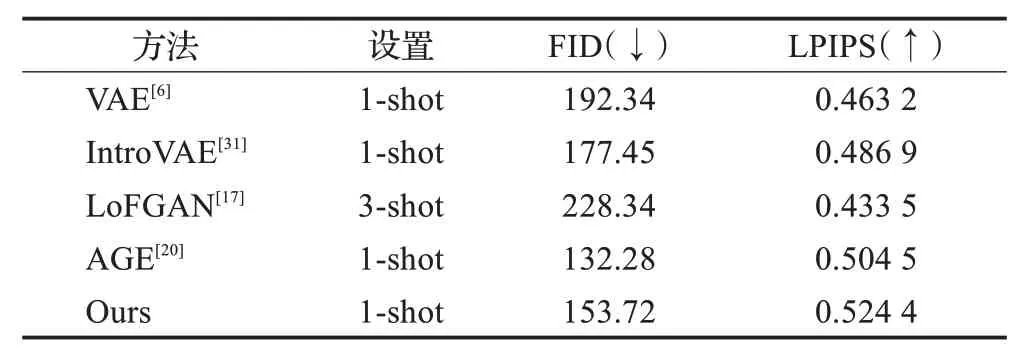
表1 FAIR1M-Aircrafts数据集上的定量评价结果Table 1 Quantitative comparison on FAIR1M-Aircrafts
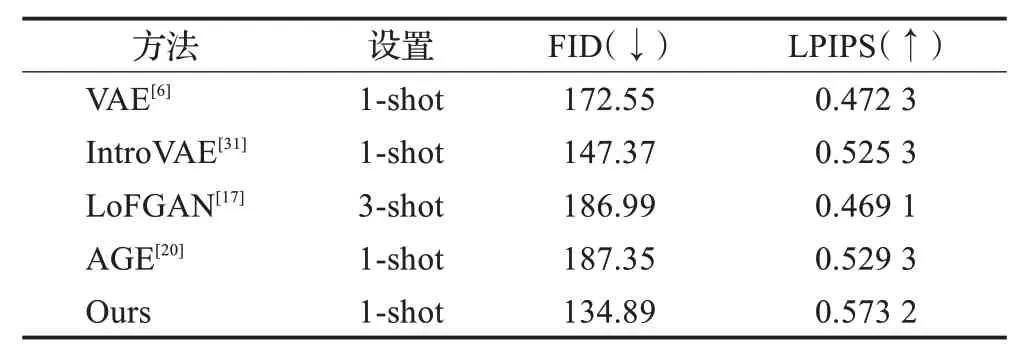
表2 MAR20数据集上的定量评价结果Table 2 Quantitative comparison on MAR20
3.3.3 特征解耦消融实验
在图像生成阶段,特征调节因子α决定了生成图像判别特征和类内可变特征的比例。如图9 所示最左侧一列是输入的真实图像,其余各列是不同α取值对应生成图像。如式(21)所示,特征调节因子α仅决定重构图像判别特征和类内可变特征的比例,与输入样本的类别无关。当α=0 时,生成的图像仅由类间判别特征重建。可视化结果表明,此时重建图像主体突出,而背景趋于模糊,色调趋于均匀,这表明判别特征zd被成功提取,证明了特征解耦模块设计方案的合理性。当α值逐渐升高,可变特征zv在重构特征z中所占的比例增大,生成的图像与原始图像的差异越大,这种可视化结果表明额外添加的类内可变特征zv在不影响图像真实性的前提下,改变了图像生成结果,增强生成模型结果的多样性。

图9 不同特征调节因子α 对应的重构图像Fig.9 Images generated with different regulatory factor α
3.3.4 线性插值实验
对于VAE 系列生成模型来说,编码器所映射隐空间的规则性和连续性决定了生成图像的质量。设计并完成了隐空间的线性插值实验。
在潜在空间中两个真实图像的特征向量之间进行线性插值,将插值特征向量输入到解码器中获得生成图像,以证明编码空间的连续性。如图10所示,第一列和最后一列是真实图像,其余5列是生成的插值图像。按行从左至右观察,可见生成图像的背景、纹理、光强、飞机类型和旋转角度按照最左侧输入图像向最右侧输入图像逐渐改变,这种平滑的变化过程表明本文的编码空间是一个流畅的、连续的流形空间。语义丰富且合理的插值结果表明,本文的模型准确地“捕获”了潜在空间中图像的语义特征,而不仅仅是“记住”它们。

图10 隐空间两个真实图像间的平滑插值图像Fig.10 Smooth interpolation between two real images in latent space
3.4 下游分类模型提升效果
为了验证提出的小样本图像生成方法FD-VAE 对下游分类模型精度提升的增益效果,设计了一系列定量和定性实验。
选用ResNet-18 作为下游分类模型,在FAIR1MAircrafts 数据集上测试。FAIR1M-Aircrafts 数据集包含9类民用飞机样本,其中ARJ21型号的飞机样本数量最少,为197 张,A220 型号的飞机样本数量最多,为6 173张。整体数据集样本数量不均衡较为明显,9类样本数量的平均数为2 400张,存在6类样本数量低于平均数。
未做任何处理的FAIR1M-Aircrafts 数据集,称为原始数据集A0。将A0 中样本数量高于平均数的类别样本随机抽取2 400 张,样本数量低于平均数的类别样本分别利用FD-VAE 或传统方法增广为2 400 张,补充至原有数据集。传统方法增广选用50%随机旋转、25%色彩变换、25%随机缩放的增广方案。最终形成FD-VAE增广的数据集A1,传统方法增广的对照数据集A2。各数据集样本数量如表3所示,数据集A0、A1、A2均按照60%、20%、20%划分为各自的训练集、测试集和验证集。

表3 三种测试数据集的样本数量Table 3 Number of samples of three datasets
使用划分好的未增广数据集A0、增广数据集A1、对照数据集A2 分别训练ResNet18 网络,分类准确率如表4所示。
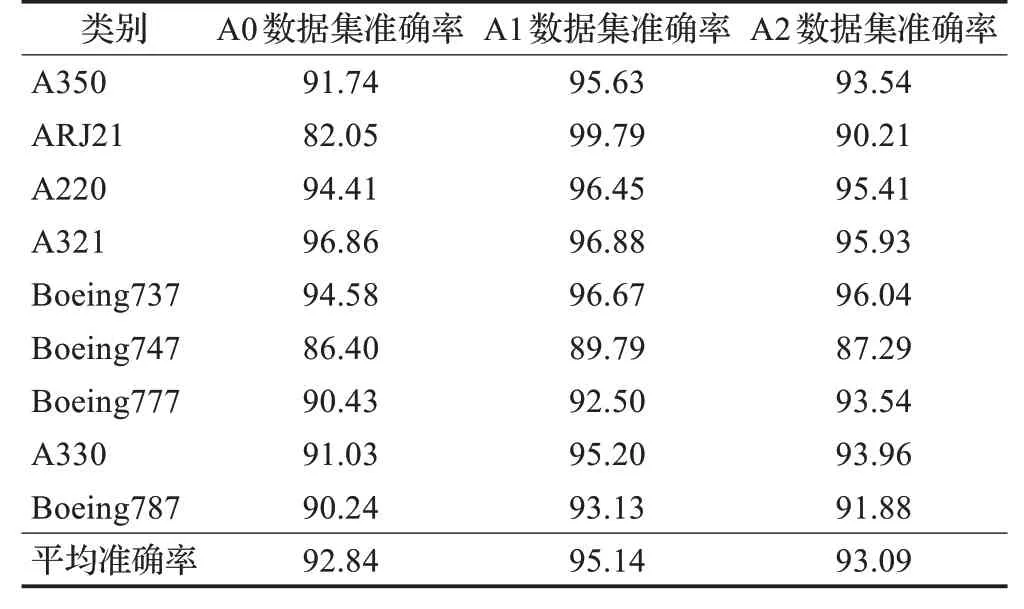
表4 三种数据集的ResNet-18网络分类准确率Table 4 Classification accuracy of ResNet-18 network on three datasets 单位:%
使用FD-VAE增广后的数据集A1分类准确率相比原始数据集A0提升了2.3个百分点,相比传统方法增广的对照数据集A2 提升了2.05 个百分点,并在ARJ21 类别的飞机样本上分类准确率达到99.79%。实验结果验证了提出的图像增广算法FD-VAE 在提升下游模型分类精度方面的有效性。
4 结论
本文提出了一种用于少样本条件下遥感飞机图像生成的算法FD-VAE,在两个公开数据集上定性和定量的测试其图像生成能力,实验结果表明生成网络在小样本图像生成领域十分具有竞争力,生成图像具有多样性和可解释性,FD-VAE的定量评价结果超过了目前较为先进的1-Shot和3-Shot模型。并且,使用提出的图像生成方法增广后的数据集有助于提升下游模型分类精度。
