基于BF-YOLOv5的红外及可见光图像融合的目标检测
2024-05-09谷继明刘力维
郝 博, 谷继明, 刘力维
(1.东北大学机械工程与自动化学院,沈阳 110000; 2.东北大学秦皇岛分校控制工程学院,河北 秦皇岛 066000)
0 引言
近年来,随着计算机视觉领域的发展,搭载着高效视觉系统的无人机功能越来越强大,无论在民用还是军用领域无人机都被广泛应用[1],尤其是具有 “低慢小”特征的小型无人机,使用方便灵活,成本相对低廉,可用于执行侦察监视、自杀式袭击等任务。目前无人机广泛搭载的多为可见光成像设备,也有部分搭载红外成像设备,红外图像探测距离远、穿透大气能力强,红外目标检测在军事预警、红外制导、民用安防等领域具有很高的研究和应用价值[2-3]。由于红外成像设备具有不易受光照变化影响的特点,无人机在夜间执行侦察任务往往需要红外成像设备。然而与可见光图像相比,红外图像仅有一个颜色通道,能够提取到的特征信息较少[4],并且红外图像往往有分辨率低、物体边缘模糊、含有噪声、对比度较低等问题,上述物理特性也给基于红外图像的小目标检测算法的设计与实现带来了更多的挑战[5]。因此,综合利用可见光图像和红外图像的优势,将红外和可见光进行融合的目标识别对提升侦察无人机的多种环境的目标识别性能具有重要意义。
深度学习的飞速发展为目标检测提供了新的动力,基于深度学习的目标检测算法根据不同的特征提取方式,主要分为单阶段和两阶段检测算法。2015年,Fast R-CNN[6]和Faster R-CNN[7]目标检测算法被提出,2017年,基于 Faster R-CNN 框架的Mask R-CNN[8]的目标检测算法被提出,上述检测算法均属于两阶段检测算法,算法在检测时首先生成候选区域,接下来对候选区域进行分类和定位,两阶段检测算法识别精度很高,但是由于计算量大,识别速度难以满足航拍图像目标识别较高的实时性要求。然而,单阶段目标检测算法可以在不生成候选区域的情况下完成端到端的目标检测,虽然较两阶段检测牺牲一些检测精度,但是提高了检测速度以满足检测的实时性,目前较为成熟的单阶段检测算法分别是 SSD[9]系列算法和YOLO[10]系列算法。
由于可见光相机图像只能在光线充足的情况下有着较高的识别精度,在夜晚和有雾的天气等能见度较低的情况下难以满足较高的识别精度[11],因此,已有研究者同时使用可见光相机和红外相机进行拍摄,融合可见光图像和红外图像,用融合的方法进行检测以提高检测模型的检测能力[12-14]。朱浩然等[15]提出一种基于对比度增强与多尺度边缘保持分解的图像融合方法,解决了在低照度环境下拍摄的可见光图像与红外图像直接融合导致融合结果清晰度不理想等问题;李永萍等[16]提出一种在变换域中通过VGGNet19网络的红外与可见光图像融合方法,该网络在提取源图像中的边缘及细节信息上有着更好的效果,有效抑制了红外与可见光图像融合中出现细节信息丢失及边缘模糊的问题;马梁等[17]提出了一种基于多尺度特征融合的遥感图像小目标检测方法,该方法提出了一种基于动态选择机制的轻量化特征提取模块和基于自适应特征加权融合的 FPN (Feature Pyramid Network) 模块,增加图像特征表达的准确性。融合红外和可见光的目标检测算法根据在融合阶段不同,分为前期融合和中期融合,前期融合是在检测模型特征提取之前将红外和可见光图像进行融合,然后将融合图像输入检测模型。前期融合能够提升的检测精度较低,同时,由于需要单独对红外和可见光图像增加融合阶段,导致检测速度较低,然而中期融合是在特征提取阶段分别对红外图像和可见光图像的特征进行提取,然后再进行融合检测,中期融合算法具有更高的精度和检测速度,能够满足实时检测的要求。
目前在目标检测网络中,YOLOv7网络的检测速度和精度都要高于已有的检测网络,但是其网络结构复杂,不利于进行融合改进,融合后会大大增加模型的计算量。因此,本文以YOLOv5为基本框架, 提出一种基于YOLOv5改进的红外特征和可见光特征交互与融合的目标检测算法, 算法采用双分支结构,通过两个Backbone分别读取可见光图像和红外图像,在每个Backbone中分别融合了CBAM注意力模块,通过学习的方式自动获取每个特征通道的重要程度,并且利用得到的重要程度来提升特征,并抑制对当前任务不重要的特征。在Neck部分融合了BiFormer注意力机制,用来提升对小目标的检测能力。
1 BF-YOLOv5算法设计
1.1 多模态检测算法
多模态检测算法类型如图1所示。
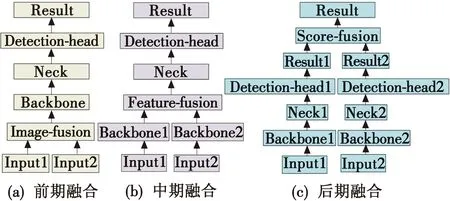
图1 多模态检测算法类型Fig.1 Types of multimodal detection algorithms
如图1所示,根据在检测网络融合的位置不同,多模态目标检测方法主要分为前期融合、中期融合(特征级融合)和后期融合3大类。前期融合如图1(a)所示,主要集中在输入部分的融合以及多源图像逐点叠加融合[18];图像融合方法的重点是获得质量非常好的融合图像作为检测的输入,但质量非常好的融合图像并不一定在检测任务中表现出优异的效果。大多数前期的融合方法与特定的下游检测任务不太相关。中期融合如图1(b)所示,CAO等[19]对不同阶段的融合进行了实验研究,发现中期融合是效果最好的方法,FANG等[20]提出一种跨模态的注意力特征融合算法,网络可以自然地同时执行模态内和模态间融合,并捕获可见光图像和红外图像的潜在相互作用,算法提高了多光谱目标检测的性能,并在遥感图像上取得了较好的效果。后期融合如图1(c)所示,CHEN等[21]提出一种概率集成技术,将来自多模态的检测融合在一起,并在FLIR数据集上进行了验证,也达到了较好的检测效果。多模态融合检测的重点是在不同模态之间图像特征融合,提升每个模态的图像的特征,减少对无关特征的关注,能够有效提升识别。
1.2 BF-YOLOv5算法
BF-YOLOv5算法结构如图2所示。
本文选择YOLOv5l作为基础网络来实现红外和可见光双分支图像输入的目标检测,对YOLOv5l的Backbone进行复制,用于处理红外图像输入,在每个Backbone中分别融合了CBAM,通过学习的方式自动获取每个特征通道的重要程度,并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征。在Neck部分融合了BiFormer注意力机制,用来提升对小目标的检测能力。
1.3 CBAM
CBAM如图3所示。
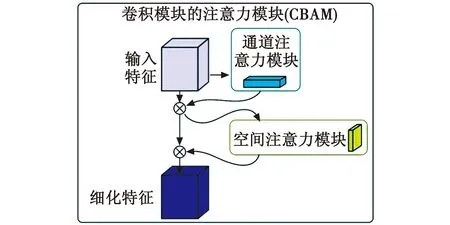
图3 CBAM
CBAM通过学习的方式自动获取每个特征通道的重要程度,并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征,其提取特征通道注意力的方式基本与SENet类似 ,在SENet的基础上增加了max_pool的特征提取方式,其余步骤是一样的。CBAM在提取特征空间时,先经过通道注意力模块,然后将经过通道重要性选择后的特征图送入特征空间注意力模块。与通道注意力模块类似,空间注意力是以通道为单位进行最大池化和平均池化,并将两者的结果进行 Concat之后再一个卷积降成1×w×h的特征图空间权重,再将该权重和输入特征进行点积,从而实现空间注意力机制,w和h分别代表特征图的宽和高。
1.4 BiFormer模块
BiFormer模块结构如图4所示。

图4 BiFormer模块Fig.4 BiFormer module
使用两级路由注意力作为基本构建块,模块先使用3×3卷积隐式编码相对位置信息,通过LN(Layer Norm)进行归一化操作,经过BRA(Bi-Level Routing Attention)模块将特征图划分为S×S个非重叠区域,在粗糙区域级别过滤掉大部分不相关的键值对,以便只保留一小部分路由区域,过滤掉了冗余信息,最后,经过 MLP(Multi-Layer Perceptron)选取最合适的权值和偏置,实现特征转换、信息重组、特征提取。
2 实验分析与讨论
2.1 实验数据集
FLIR数据集包含大约10 000幅已经标注的红外图像和对应的可见光图像,其中包含person、car、bicycle和dog这4个类别,由于本文使用的双流网络的输入红外和可见光图像需要严格对齐,因此使用的数据集版本是FLIR-align,数据集中包含了5142对严格对齐的图像,其中,4407对图片用于训练,735对图片用于测试。
LLVIP数据集包含了30 976幅图像,该数据集只有一个类别person,并且对数据集测试表明,此数据集在识别精度方面非常高,然而,为了验证本文改进模型的泛化性能,仍然使用LLVIP数据集进行实验验证,以证明在输入图像质量不相同的情况下,本文改进的模型依然能够对识别精度有所提升。
2.2 实验平台及网络训练参数设置
本文实验环境为 64 位 Windows10 操作系统下搭建的 Python3.9+Pytorch1.12.1+CUDA11.6 深度学习框架。实验所用计算机 CPU为Intel®CoreTMi7-12700H,GPU为NVIDIA GeForce RTX3060,内存为 32 GiB。网络训练的初始学习率设置为 0.01,最小学习率为 0.000 1,预训练权重使用YOLOv5,输入图片尺寸为640×640(单位:像素),批量大小(Batch size)为 8,训练轮次(Epoch)为 300。
2.3 实验结果与分析
2.3.1 主流融合算法性能比较
为了对本文改进的模型在红外和可见光图像上的检测性能进行总体评估,用FLIR数据集和LLVIP数据集进行实验验证,在FLIR数据集上的实验结果如表1所示。

表1 不同算法在FLIR数据集的识别精度对比
由表1可知:使用YOLOv5算法单独对可见光图像进行训练的检测精度最低,使用红外图像进行训练的精度略高于可见光图像,使用3种前期融合的算法(Dense-Fusion、PIAFusion、SeAFusion)的检测精度均高于单独使用单一模态的图像,但是精度提升效果并不明显,使用YOLOv5双输入(Two-Stream)算法的检测精度最高,相比单独红外图像检测的mAP@0.5提升了5.3个百分点,因此证明了中期融合算法相比前期融合算法的检测效果更好。
为了验证融合算法的泛化性,在LLVIP数据集上进行了相同的实验,实验结果如表2所示。

表2 不同算法在LLVIP数据集的识别精度对比
由表2可知,3种前期融合算法的检测精度远高于单独的任一模态的检测,双输入的中期融合算法与前期融合算法的检测精度基本持平,出现这种情况的原因可能是LLVIP数据集的类别少,并且mAP已经达到97%以上,很难继续提升,但是实验结果也能证明融合算法相比单一模态检测有更高的精度。
2.3.2 消融实验结果与分析
为验证本文提出的各种改进措施对检测性能的提升作用,在FLIR数据集上进行了一系列消融实验,实验结果如表3所示。
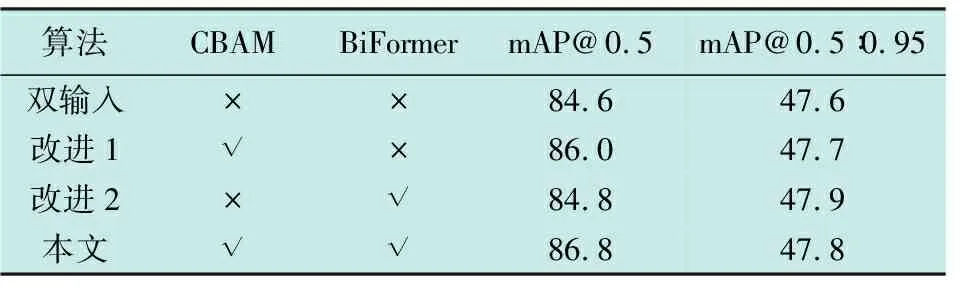
表3 消融实验结果
由表3可知:改进1融合CBAM注意力机制,相比原模型的mAP@0.5提升了1.4个百分点;改进2添加了BiFormer模块,提升算法对小目标的检测能力,由于数据集的小目标较少,所以mAP@0.5仅提升了0.2个百分点;本文算法是结合改进1和改进2,同时对Backbone及Neck部分进行改进。实验结果表明,本文算法相对原有算法mAP@0.5提升了2.2 个百分点;说明了本文算法对红外及可见光融合的检测有显著的提升效果。
2.3.3 训练结果与分析
图5所示为不同算法在FLIR数据集上训练过程mAP变化情况。

图5 不同算法在FLIR数据集mAP对比Fig.5 Comparison of mAP of different algorithms on FLIR dataset
由图5能够明显看出,融合检测效果明显优于单独的红外图像检测和单独的可见光图像检测,3种前期融合的算法的检测精度基本持平,中期融合的算法检测精度明显高于前期融合算法,然而本文改进的BF-YOLOv5算法达到了更高的精度,证明改进的算法对红外及可见光图像融合的检测具有很好的检测效果。
2.3.4 检测实验结果与分析
图6是不同算法在LLVIP数据集上检测效果对比。由图6能够直观看出,在弱光照情况下,可见光图像检测框的置信度最低,红外图像检测框的置信度略高于可见光图像检测,2种前期融合算法检测的效果相比于单独红外或可见光图像的检测已经有了很大提升,然而本文的BF-YOLOv5算法在实验过程中的检测效果是最优的,实验证明,BF-YOLOv5算法在红外及可见光图像融合的检测中相比其他算法有着更好的检测性能。

图6 不同算法在LLVIP数据集上检测效果Fig.6 Detection performance of different algorithms on LLVIP dataset
3 结束语
本文提出以YOLOv5算法为基础的BF-YOLOv5网络模型,在红外及可见光FLIR数据集和LLVIP数据集上的检测精度均高于3种前期融合算法,在FLIR数据集上平均精度均值(mAP)高达86.6%,相比原有双分支算法提升了2.2个百分点,并且本文提出的BF-YOLOv5算法不需要提前对图像进行融合,检测速度和精度都优于前期融合算法,具有较好的实时性,在2个数据集的优秀表现也证明模型具有很好的泛化性能。
