基于小句复合体的中文机器阅读理解研究
2024-05-09王瑞琦罗智勇韩瑞昉李舒馨
王瑞琦,罗智勇,刘 祥,韩瑞昉,李舒馨
(北京语言大学 信息科学学院,北京 100083)
0 引言
机器阅读理解(Machine Reading and Comprehension, MRC)任务与人类阅读理解任务相似,是指计算机根据指定篇章文本回答相关问题的过程。近年来,随着深度学习技术,特别是词向量表示、预训练语言模型方法的发展,机器阅读理解模型的性能得到巨大提升,甚至在个别机器阅读理解数据集评测任务中逼近或超越了人类的水平[1]。但在涉及到远距离、深层次的语义关系时,现有的深度学习方法仍然没有取得实质性的突破。
在机器阅读理解任务中,这一现象主要体现在: 中文机器阅读理解任务的篇章文本(Context)长度较长,经常包含多个标点句;且问题(Question)对应的答案与回答此问题需要的线索要素在篇章文本中跨越多个标点句,这种情况给机器阅读理解任务的答案抽取带来较大困难,具体示例如图1所示。

图1 跨标点句问答样例
图1中,我们使用换行缩进形式直观地表示了篇章文本中话头-话体共享关系[2]: 此样例中篇章文本(Context)一共有8个标点句(用换行表示),其中,c2至c8等7个标点句均共享标点句c1中的话头“徐珂”(用缩进表示)。Question1中的线索要素包括: “1901年”(位于c8)、“徐珂”(位于c1,“加粗”显示),问题要素是“担任什么职务”(用“波浪线”标记),该问题对应的答案是“1901年在上海担任了《外交报》《东方杂志》的编辑”(位于c8,用“下划线”标记)。线索要素与问题答案之间在篇章文本中跨越8个标点句,属于远距离关联关系。在本例中,要想让模型准确地抽取出答案,必须在标点句c1中找到标点句c8缺失的话头“徐珂”,并将c8补充完整,再进行问答。
我们针对于这一跨标点句、远距离关联的现象,在CMRC2018阅读理解数据集[3]上进行了标注,结果如表1所示。其中,跨标点句问答问题占全部训练数据的67.89%;BERT的基线系统在跨标点句问答的问题上的精确匹配率(EM)为61.02%,相比于其他问题上的EM值72.02%,降低了11.00%,在一定程度上说明了跨标点句问答给答案的抽取带来了一定困难。

表1 CMRC2018阅读理解数据集跨标点句问答统计情况
目前针对中文机器阅读理解任务的研究方法多为模型结构的更改或增加实体信息等外部知识,却很少关注数据中普遍存在的跨标点句问答问题。本文应用小句复合体理论降低中文机器阅读理解任务中跨标点句问答问题答案抽取的难度,提高模型的性能。小句复合体理论基于逻辑语义关系和成分共享关系研究汉语中跨标点句的句间关系,本文应用该理论对阅读理解数据的篇章文本进行分析,使用标点句间的话头-话体共享信息构建远距离标点句之间的联系。篇章文本中的标点句补全缺失的话头话体成分,转化为自足的话题结构后,问题的线索要素与答案要素将处于同一话头自足句或者同一小句复合体结构内部,便于答案的抽取。标点句之间的远距离成分共享关系可以保证标点句语义的完整性,为模型提供额外的语义信息,提高模型的语义表示能力,对于机器阅读理解等自然语言处理任务具有基础性的意义。
本文的主要贡献在于: 提出将小句复合体结构自动分析任务与机器阅读理解任务融合的策略,利用小句复合体中话头-话体远距离共享关系,为模型提供句级别的结构化语义信息,降低远距离答案抽取的难度;提出了基于小句复合体的机器阅读理解模型,并验证了小句复合体话头-话体共享关系在机器阅读理解任务中的作用效果;另外,本文在CMRC2018阅读理解数据集上的实验结果表明: 小句复合体结构自动分析任务对机器阅读理解任务中的远距离跨标点句问答问题有明显的效果,与基准模型相比,基于小句复合体的机器阅读理解模型的整体精确匹配率(EM)提升3.26%,其中跨标点句问答问题的EM提升3.49%。
本文组织结构如下: 第1节介绍相关研究;第2节介绍相关概念和基于小句复合体的机器阅读理解任务建模;第3节介绍基于小句复合体的机器阅读理解模型设计;第4节介绍实验结果及分析,第5节为总结与展望。
1 相关研究
机器阅读理解任务的起源可以追溯到20世纪70年代,但是由于数据集规模过小和传统的基于规则的方法的局限性,当时的机器阅读理解系统性能较差,不能满足实际应用的需要。1977年Lehnert等人提出基于脚本和计划的框架QUALM[4],专注于语用问题,以及故事的上下文背景对回答问题的影响。由于机器阅读理解任务的复杂性,很长一段时间该任务被搁置没有进展。直至20世纪90年代,Hirschman等人[5]提出一个包含60个故事的数据集,并提出Deep Read系统,使用基于规则的词袋模型进行浅层语言处理,加入词干提取、指代消解等帮助理解文本。Riloff等人2000年提出的QUARC系统[6],基于词汇和语义对应。这些基于规则的方法,准确率最高只有30%~40%。此阶段,由于缺少大型的数据集,任务发展缓慢。
机器学习兴起后,阅读理解被定义为有监督问题[7],将MRC任务看作一个三元组(篇章,问题,答案),训练一个统计学模型将篇章及问题映射到答案。MCTest[8]和ProcessBank[9]两个数据集的提出,促进了该任务的发展。Garcia等人[8]同时提出了滑动窗口法计算篇章与问题、答案之间的信息重叠度,还提出将答案转化为语句,然后做文本蕴含的方法。基于检索技术的阅读理解模型,通过关键词匹配在文章中搜索答案,存在局限性,匹配度高的结果有时并不是问题的答案。此阶段,机器学习模型对机器阅读理解任务带来的提升有限,原因在于模型使用语义角色标注系统等语言工具提取特征,这些工具多用单一领域的语料训练,难以泛化;而且数据集过小,不足以支撑模型的训练。
2015年以后,深度学习飞速发展,提出了很多大规模数据集(如CNN &Daily Mail[10]、SQuAD[11]等)和易于提取上下文语义信息的神经网络模型。模型的效率与质量大幅度提升,在一些数据集上甚至可以达到人类平均水平。Hermann等人[10]于2015年提出的基于Attention的LSTM模型“Attentive Reader”和“Impatient Reader”,成为了后来许多研究的基础,Attentive Reader将篇章和问题用双向RNN分别表示后,利用Attention机制在篇章中寻找问题相关的信息,最后根据相关程度给出答案的预测。在SQuAD数据集的基础上,产生了许多神经阅读理解模型,如基线模型Logistic Regression。2018年,Google提出的BERT模型也提供了阅读理解问答的模型架构,在SQuAD数据集上的F1值达到了93.16%。各种大规模数据集和预训练语言模型的提出推动该任务飞速发展。
目前,预训练语言模型存在上下文语义表示和学习不足的问题,解决方法多为添加额外的语言学知识。ELMo[12]、BERT[13]等语言模型只发掘了Character Embedding、Word Embedding等上下文敏感的特征,没有考虑结构化的语言学信息。Zhang等人[14]于2019年提出: Semantics-aware BERT模型,将 BERT与语义角色标注任务结合,用谓词-论元信息来提升阅读理解模型的语言表示能力,提高了问题的准确率。该融合模型在机器阅读理解任务上应用的有效性,表明显式的上下文语义信息可以与预训练语言模型的语言表示融合来提高机器阅读理解任务的性能。Zhang等人[15]提出: ERNIE,用知识图谱来增强语言表示,该模型在BERT的基础上,加入了实体、短语等语义知识。这两种方法均应用额外的语义信息增强模型的表示,提高了模型的性能,证明了结合必要外部知识对提升模型性能的有效性。但语义角色标注和实体信息并不能处理机器阅读理解任务中远距离跨标点句问答的问题。
现有基于CMRC2018等数据集的研究方法多为对于分词或者模型结构的更改。排行榜中取得较好成绩的模型MACBERT[16]和RoBERTa-wwm-ext-large[17]都是针对预训练策略的更改,没有考虑篇章文本中存在的远距离问答的问题。而小句复合体结构分析可以提供句间的语义信息,用话头话体的共享关系来增强标点句间的语义完整性和相关性,简化抽取答案的难度,从而提升模型效果,故本文采用小句复合体结构分析模型与机器阅读理解模型融合的方法解决跨标点句问答问题。
小句复合体研究任务已经历十几年,定义、分类及内部理论体系已经成熟,在此基础上话头识别工作有如下成果: 起初仅对小句复合体语料中的堆栈类型数据进行单个标点句的话头结构分析,蒋玉茹等人[18]于2012年使用穷举法研究,在上一个话头自足句中找出当前标点句的全部候选话头,再使用语义泛化和编辑距离两种手段选出合适的话头,识别正确率为73.36%。基于之前研究,蒋玉茹等人[19]又采用相同方法研究堆栈类型标点句序列的话头结构识别,将各标点句的全部候选话头存储于树结构中,选取概率最大的路径获得话头序列,最终正确率为64.99%。由于穷举法对系统执行效率和话题句识别的准确率存在限制,蒋玉茹[20]等人在2014年利用标点句在篇章中的位置和话头的语法特征等信息减少生成的候选话头的数量,从而提高模型的识别效率和效果。2018年,MAO等人[21]提出的基于 Attention-LSTM的神经网络模型在单个标点句的话头识别任务上的正确率达到81.74%。胡紫娟[22]2020年在前面研究的基础上,增加了对新支、汇流、后置类型数据的分析,并且添加了标点句尾缺失成分的识别,总的正确率达93.24%,为小句复合体理论在实际任务中的应用打下基础。
2 基于小句复合体的机器阅读理解任务建模
2.1 机器阅读理解任务
机器阅读理解任务主要分为完形填空、多项选择、跨度提取和自由回答四种类型,另外还有会话式回答、多段式阅读理解等。本文涉及到的类型为跨度提取型阅读理解,如图2所示。该任务要求在原文中抽取一个片段作为答案。

图2 跨度提取型阅读理解样例
2.2 跨标点句问答
本文使用线索要素、问题要素、答案要素来描述阅读理解任务中远距离跨标点句问答的情况:
线索要素: 问题中明确给出的关键词,是寻找答案的限定条件。
问题要素: 问题的提问方式,如when、where、how,what,why、who等。
答案要素: 原文中的实体、短语、句子。阅读理解问题的答案,与问题要素相对应。
全部要素是否跨标点句:将问题中的问题要素替换成答案要素,并转化成陈述句,其中包含的线索要素与答案要素在原文中是否处于同一标点句。
跨标点问答分为两种类型: 第一种答案要素较短,为词、短语或者一个标点句,与线索要素距离较远而跨多个标点句(如图3中样例所示)。另一种答案要素很长,答案在篇章文本中跨标点句(如图11中样例所示)。

图3 跨标点句问答样例
图3中,Question1的线索要素为: “范廷颂”和“被任为主教”,问题要素是“什么时候”,答案要素是“1963年”。将问题中的问题要素替换为答案后,问句可以转化为陈述句“范廷颂是1963年被任为主教”,该陈述句在原文中对应的标点句序列是“范廷颂枢机,圣名保禄·若瑟,是越南罗马天主教枢机。1963年被任为主教;”,线索要素与答案要素跨越4个标点句。Question2的线索要素是“1990年”和“范廷颂”,问题要素是“担任什么职务”,答案要素是“1990年被擢升为天主教河内总教区宗座署理”,全部要素在原文中跨越5个标点句。两问题均属于远距离跨标点句问答问题。
2.3 小句复合体理论
标点句: 本文的标点句是指被逗号、分号、句号、问号、叹号所分隔出的词语序列。如图4中的样例共有13个标点句。

图4 例2用换行缩进表示话头话体共享关系
话头、话体:在微观话题角度,话语的出发点叫做话头(Naming),话体(Telling)是对话头的说明。
话头结构:话头话体间关系构造的多个标点句之间的结构称为话头结构。换行缩进标注体系是使用空格表明话头结构的方式。
小句复合体:是话头共享关系和逻辑关系都不可分割的最小标点句序列。主要有堆栈、汇流、新支、后置四种类型。本文将阅读理解的篇章文本看作一个整体,分析各标点句之间的话头话体共享关系。
将图3中的标点句使用小句复合体理论进行分析,并用换行缩进格式表示其话头结构,如图4所示,标点句c1至c8的8个标点句处于同一小句复合体结构,c9至c11的3个标点句处于另一小句复合体结构,这种关系的划分基于话头-话体共享关系与逻辑语义关系(本课题不研究逻辑语义关系)。该样例中,标点句c1成分完整,但被后面的标点句共享话头,因此c1至c8处于一个小句复合体中。其中,c2至c6和c8共享c1中的话头“范廷颂”,c7共享的话头来自标点句c1和c6,为“范廷颂1994年”。c9不共享其他标点句中的话头,且自身不缺少成分,但被c10、c11共享话头“范廷颂”,故c9至c11这3个标点句被划分在一个小句复合体结构中。
2.4 基于小句复合体的机器阅读理解研究
使用小句复合体结构自动分析工具将待处理的篇章文本转换为换行缩进模式,并补全为话头自足句,使线索要素和答案要素处于同一标点句或同一小句复合体结构中。根据线索要素与问题要素在篇章文本中的位置来抽取答案,答案要素短的样例在一个话头自足句中提取即可;答案要素跨越多个标点句的样例在一个小句复合体结构内抽取答案,同一小句复合体内的标点句由于共享话头或话体被组织到一起,更容易把跨标点句的答案要素提取完全。
将图4中以换行缩进模式表示的部分标点句补全缺失成分,转化为话头自足句(即NT小句),如图5所示。从图中可以看出,标点句c4“范廷颂1963年被任为主教”包含了Question1的全部线索要素与答案要素,c5“范廷颂1990年被擢升为天主教河内总教区宗座署理”包含了Question2的全部线索要素与答案要素。直接在一个标点句完成问答,化简了答案抽取的难度。

图5 话题自足句
2.5 机器阅读理解任务的机器学习问题描述
本文使用的CMRC2018阅读理解数据集的类型是片段提取,该类型任务可定义为: 将机器阅读理解任务看做一个三元组
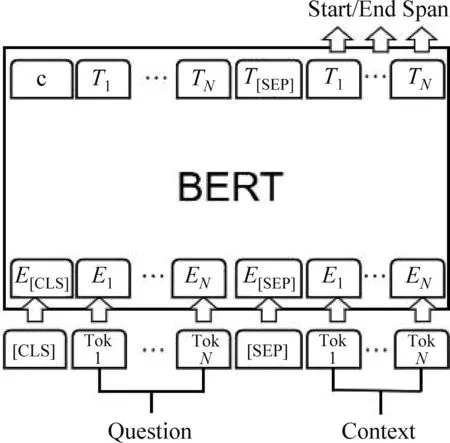
图6 机器阅读理解模型
2.6 小句复合体结构自动分析任务的机器学习问题描述
小句复合体结构自动分析任务可以定义为: 已知小句复合体C1,…,Cn,求对应的话头自足句Z1,…,Zn的过程。在每个标点句首尾插入[MASK],并在[MASK]处预测话头的位置(start,end),即预测共享的成分,补全共享的成分,便能得到相应的话头自足句。不添加[MASK]则使用T1、Tn位置的向量预测。图7为基于BERT的小句复合体结构自动分析模型图。

图7 小句复合体结构自动分析模型
3 基于小句复合体的机器阅读理解模型
3.1 融合模型一: BERTNTC
BERTNTC模型将小句复合体结构自动分析任务作为预训练任务,先在中文小句复合体数据集上进行预训练,之后在机器阅读理解数据集上对模型进行微调。此方法用于初步验证小句复合体结构自动分析任务对于机器阅读理解任务是否有作用。模型的结果于第5节实验结果部分展示并分析。
3.2 融合模型二: BERT_NTC/MRC
BERT_NTC/MRC模型如图8所示,为机器阅读理解任务与小句复合体结构自动分析任务融合的第二种方法。本模型中采用多任务学习的方式同时训练小句复合体结构分析任务与机器阅读理解任务,两任务共享一个BERT模型的参数。训练时, 对于一个批次的数据,如果是机器阅读理解类型的数据,经过BERT预训练语言模型编码, 获取上下文语义信息及话头-话体共享信息后,进入MRC的输出层,进行答案片段Start/End Span的预测;如果是小句复合体结构分析类型的数据, 获得上下文表示后进入NTC的输出层,通过MASK位置或者标点句的首位位置的向量预测缺失的话头话体的位置Start/End。

图8 BERT_NTC/MRC模型
3.3 融合模型三: BERT_NTC_add_MRC
图9中,BERT_NTC_add_MRC模型为机器阅读理解任务与小句复合体结构自动分析任务融合的第三种方法。该模型可以分为2个模块,分别使用独立的预训练语言模型。左侧模型BERTntc进行话头-话体结构信息抽取,右侧BERTmrc抽取上下文及问题信息。训练时,BERTntc模型训练好后,保存参数,使该模型拥有表达话头-话体信息的能力,再训练BERTmrc模型。

图9 BERT_NTC_add_MRC模型
3.4 融合模型三的各层设计
BERT_NTC_add_MRC模型分为三层: 编码层、信息交互层和答案预测层。
编码层:该层的功能是将阅读理解任务的输入Input=[CLS]+Context+[SEP]+Question+[SEP]转换成计算机可以理解的向量Emrc,Emrc向量由词向量(Token Embedding)、位置向量(Position Embedding)、句向量(Segment Embedding)拼接得到。
信息交互层:在此层Emrc通过两个BERT预训练语言模型获得包含上下文信息、问题信息和话头-话体共享信息的词向量表示。
BERTntc模型的输入格式为:Entc=E[CLS]+EContext+E[SEP]。
BERTmrc模型的输入格式为:Emrc=E[CLS]+EContext+E[SEP]+EQuestion+E[SEP]。
经过BERT编码后,分别取两模型最后一层隐藏层的输出Tntc与Tmrc,将二者相加T=Tmrc+Tntc,把T接全连接层得到:ON×2=FC(TN×D)。其中,D为隐藏层大小768,经全连接层FC将维度转换为2,获得每个字作为Start和End的Logit值。
答案预测层:本层对Start/End Logits对进行相加计算,经softmax选择概率最高的一组,得到最后的答案。
基于小句复合体的阅读理解模型答案预测总计算如式(1)所示。
Start/End Logit=Softmax(FC(BERTntc(Entc)+
BERTmrc(Emrc)))
(1)
4 实验
4.1 数据集
小句复合体语料:北京语言大学中文小句复合体标注语料(简称小句复合体语料),包括百科全书、政府工作报告、新闻、小说4个领域,其中共有小句复合体9 256个、标点句37 635个。该语料主要用于训练小句复合体结构自动分析模型(NTC模型)。
机器阅读理解语料:CMRC2018阅读理解数据集用以训练机器阅读理解模型。该数据集的篇章文本来自于维基百科,问题由人工撰写,属于片段抽取式阅读理解任务。其中,训练集有篇章2 403篇、问题10 142个。验证集有篇章848篇、问题3 219个。在对CMRC2018阅读理解数据集的研究中发现了存在大量不严谨的地方,如答案长度提取不一致、问题答案不对应、答案位置错误等。经过核对,数据集中约有20%的样例存在此问题,现已全部修改。本文主要使用的是经过纠正后的数据集。
4.2 评估指标
本文采用的评估指标有F1、EM、AVERAGE。对于每个训练样例,预测的文本为prediction,长度为prediction_len,答案文本为answer,长度为answer_len,它们之间最长重合部分为lcs,lcs_len为重合文本的长度。
精确率(Precision)为正确预测为阅读理解答案的部分占全部预测比例。定义为: Precision=lcs_len/prediction_len。
召回率(Recall)为正确预测为阅读理解答案的部分占全部真实答案比例。定义为: Recall= lcs_len/answer_len。
模糊匹配率(F1)为精确率和召回率的调和平均数,两个值都很高时才高,可以综合体现预测的水平。定义为:F1=(2×Precision×Recall)/(Precision+Recall)。
精确匹配率(EM)是完全匹配的体现,当 prediction=answer时记为1,不等时记为0。
对于全部训练样例,Count为训练样例的个数,整体的F1=Σ(F1)/Count,整体的EM=Σ(EM)/Count。
AVERAGE=(F1+EM)/2,为EM与F1的平均值。
4.3 基线模型水平
如表2所示为BERT基线模型在CMRC2018阅读理解数据集上的结果,EM为64.55%,更改数据集中不严谨的情况后的EM提升至69.46%。
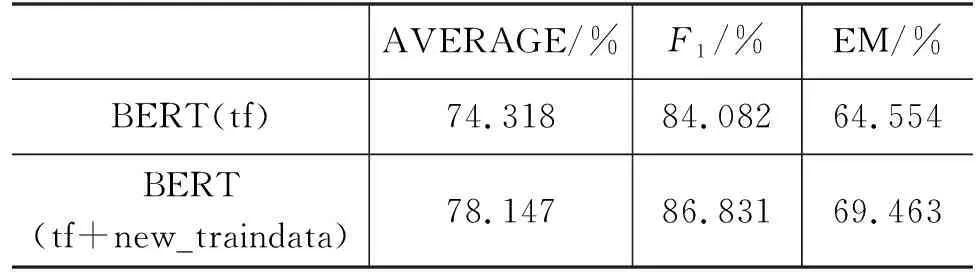
表2 CMRC2018上机器阅读理解任务基线模型结果
如表3所示,在小句复合体数据集中,小句复合体结构分析模型对与所有类型话头总Accuracy为93.24%,F1为94.69%。

表3 小句复合体语料库上小句复合体自动分析结果
4.4 实验设置
实验中涉及的模型均使用pytorch搭建,BERT、RoBERTa、RoBERTa_wwm_ext三个预训练语言模型均为base版本,12层的Transformer。Batch size设置为8,Epoch为2,学习率(learning_rate)为3e-5。
4.5 实验结果
在修改后的CMEC2018阅读理解数据集上,对两种基于小句复合体的机器阅读理解模型的效果进行验证,结果如表4所示,其中,第一行结果为BERT基线系统的结果,F1为86.83%,EM为69.46%。

表4 基于小句复合体的机器阅读理解模型验证集上的结果
BERTNTC模型:将小句复合体结构自动分析任务作为预训练任务,在修改后CMRC2018阅读理解数据集上的结果与基准模型相比F1值提升1.11%,EM值提升1.49%。该结果初步证明小句复合体结构自动分析可以为机器阅读理解任务带来一定帮助。
多任务学习模型BERT_NTC/MRC:与基线模型相比,F1提升1.46%,EM提升2.21%。虽然小句复合体结构分析任务与机器阅读理解任务具有一定的相似性,但毕竟属于两个不同的任务。其中,MRC是根据篇章和问题在原文中找到相应的答案片段,而NTC结构分析要对每个缺失成分的标点句在原文中找到相应的话头话体成分。从结果上看,在这样的模型融合方式中,小句复合体结构自动分析任务虽然给机器阅读理解任务带来了一定的性能提升,但提升的效果并不显著。
BERT_NTC_add_MRC模型:将CMRC2018阅读理解数据集篇章文本部分的输入经过两个模型的最后一层隐藏层的表示相加,再进行答案片段的预测。这个过程使篇章文本的表示即包含词级别的信息和篇章上下文的语义信息,也包含基于话头话体共享关系的结构化语义信息。此模型的EM达到72.72%,与基线模型相比提高了3.26%。本文提出的三种小句复合体结构自动分析任务与机器阅读理解任务融合的方法,均可以给机器阅读理解任务带来性能提升。
更换预训练语言模型为RoBERTa后,EM为72.57%,添加小句复合体信息使EM提升1.24%。将语言模型换为RoBERTa_wwm_ext,融合模型三在CMRC2018阅读理解数据集上的EM达到74.96%,提高1.17%。实验结果表明,在不同的预训练语言模型上,小句复合体结构自动分析信息的融入,均能够给模型带来一定的性能提升,证明了小句复合体理论在实际任务中的应用价值。
4.6 小句复合体结构分析对远距离跨标点句问答的解决情况分析
为验证小句复合体结构自动分析任务对机器阅读理解任务中远距离跨标点句问答问题的影响,在全部的数据集中标注出线索要素与答案要素在原文中是否为跨标点句,为此定义了一个新的标签“tag”。其中,tag为0的样例为较为简单的阅读理解问题;tag为1的样例为跨标点句问答且能应用小句复合体结构信息化简答案抽取难度的问题;tag为2的样例中也存在跨标点句问答问题,但是由于其他因素影响不能使用话头-话体共享信息化简任务难度,具体标注样例如图10所示。

图10 tag标注样例
tag=0: 问题与答案的全部要素对应回原文处于同一标点句。
tag=1: 全部要素不处于同一标点句,但是处于同一小句复合体内。
tag=2: 除上述两种情况之外的情况,包括指代消解、推理等问题。
图10中,Question1的线索要素是“观察家报”“报纸”,问题要素为“哪国”,答案要素为“英国”,全部要素对应回原文处于同一标点句,故tag标签为0。Question2的线索要素为“观察家报”“发行”,“什么时候”答案要素为“每周周日发行”,将问题转换为陈述句为: 观察家报每周周日发行,对应回原文跨越2个标点句,且中间分隔符号为句号,但是按照小句复合体理论,由于这两个标点句共享话头“观察家报(The Observer)”,因此处于同一小句复合体内部,tag为1。Question3的线索要素为“观察家报”“公开宣言了无党派倾向的编辑方针”,问题要素为“哪一年”,答案要素为“1942年”,虽然跨标点句,但“该报”指代线索要素“观察家报”为指代消解的问题,小句复合体结构分析难以解决这种情况,故tag标签为2。
对CMRC2018阅读理解数据集的验证集中tag标签的情况进行统计。结果如表5所示。数据集修改前后,验证集上tag=1的数据的EM都小于tag=0的EM值,tag=2的问题由于需要复杂推理等较难回答,EM值最低,拉低了整体水平。符合之前的认知,跨标点句的远距离问答会给机器阅读理解任务的答案抽取带来困难。Bert基础上的融合模型三经过训练后,tag=0样例的完全匹配率提升2.08%,tag=1的EM提升3.49%,tag=2的EM提升4.06%。小句复合体结构分析不仅对跨标点句问答有提升,对其他类型也有帮助。

表5 CMRC阅读理解数据集验证集上tag标签EM统计情况
用实例具体分析基于小句复合体的机器阅读理解模型对跨标点句问答问题的解决情况,图11为tag标签为1的样例,对模型增加小句复合体结构信息前后的答案预测结果进行分析。该样例中,前两个标点句单层汇流的关系,第三和第四个标点句共享第二个标点句中的话头“于乐”,故四个标点句处于同一话头结构内。不添加小句复合体结构信息时,预测答案较短,导致错误;加入话头话体共享信息后,线索要素与答案要素虽然未处于同一标点句内,但是处于同一小句复合体结构内,模型预测出了完整答案,证明了小句复合体结构分析对于解决机器阅读理解任务中跨标点句问答的有效性。

图11 加入小句复合体信息后的答案预测
4.7 错误样例分析
CMRC2018阅读理解数据集的验证集问题数为3 219,全部错误样例数量为878。对全部的错误样例进行分类,其中,F=0: 按照正常逻辑,可以算作正常答案,共计438个;F=1: 答案过长,预测缺失,共计77;F=2: 答案很短,预测过长,共计227;F=3: 由于复杂推理等原因,完全预测错误,共计130。
在如图12所示的错误样例中,对于Question1,模型预测的答案多了人物的定语,被判定预测错误。然而,很多标准答案中也包含加定语的答案,所以此类型的错误样例可以算作正确。Question2的结果表明小句复合体结构分析对跨标点句问答有帮助,虽然该样例没有预测出全部的答案,但是与不加小句复合体信息时相比预测的长度更长了。当然,也存在部分样例由于添加了话头话体共享关系信息,预测了多余的答案。

图12 错误样例分析
如Question3所示,对于包含多个时间的情况,经常预测错误,但是这类问题不是小句复合体结构分析可以解决的。
Question4涉及指代消解,而且需要推理属于中国的地区,是小句复合体结构分析解决不了的问题。
总体而言,小句复合体结构分析提供的结构化语义信息可以解决部分跨标点句问答问题,给机器阅读理解任务带来帮助。
5 总结与展望
在中文机器阅读理解任务中,增加外部知识成为提高模型表现的一种热门方向。小句复合体理论的话头-话体共享关系保证了标点句的语义连贯性,加强了远距离标点句之间的联系,缺失成分的补充同时降低了答案抽取的难度。更换不同的基础模型后,模型效果均有不同程度的提升,也体现了小句复合体结构分析任务与机器阅读理解任务融合的有效性。
目前,在小句复合体结构自动分析任务中,实际需要预测的节点的准确率还有提升空间,虽然该任务上F1有94.6%,但预测的位置大多不缺少成分,预测的结果表现高于实际的预测水平,这对于模型融合的效果产生了影响。另外,本文中实验没有采取先对阅读理解数据进行话头-话体结构分析,补全缺失成分后,再作为机器阅读理解任务的输入,微调模型的方法,主要是由于机器识别话头-话体的水平有限,且没有对机器阅读理解数据集进行小句复合体结构的人工标注。因此,提高小句复合体结构自动分析任务的准确率,对机器阅读理解数据集进行小句复合体话头-话体结构标注,探索小句复合体理论在其他自然语言处理任务中的应用是下一步的研究工作。
