基于汉字形音义多元知识和标签嵌入的文本语义匹配模型
2024-05-09赵云肖李欣杰苏雪峰施艳蕊乔雪妮胡志伟闫智超
赵云肖,李 茹,3,李欣杰,苏雪峰,4,施艳蕊,乔雪妮,胡志伟,闫智超
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 中译语通科技股份有限公司,北京 100043;3. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;4. 山西工程科技职业大学 现代物流学院,山西 晋中 030609)
0 引言
文本语义匹配(Text Semantic Matching,TSM)是自然语言处理的一项基础技术,广泛应用于机器阅读理解、信息检索、问答等任务中,它要求模型能够通过比较给定的两段文本确定它们之间的语义关系[1]。由于人类自然语言真实场景的语义表达灵活多变,研究两个文本间的语义关系一直以来都至关重要[2]。
近些年来,研究人员一直在推动文本语义匹配技术的发展,如ConvNet模型[3]、ABCNN模型[4]、DRCN模型[5],以及以BERT[6]为代表的预训练模型等,这些都极大地促进了文本语义匹配技术的进步[6-7]。但随着大数据时代互联网文本数据的发展,人们发现基于深度神经网络的模型虽然在一些匹配数据集上取得了与人类相仿甚至超越人类的效果,但在处理真实应用场景中的文本时仍面临着能力不足的缺陷(1)https://www.datafountain.cn/competitions/516/datasets。
分析相关前沿语义匹配数据集发现,在真实应用场景下导致模型无法精准预测匹配结果的干扰因素主要来自两个层面: ①来自文本语义层面; ②来自标签语义层面。其中,前者的干扰因素主要是因为现有模型常常忽略文本字形与拼音的信息表示;后者的干扰主要是因为现有模型在编码后直接经过分类层便得到预测结果,忽略了标签信息也隐含着分类的重要特征。表1给出了现阶段模型忽略文本语义层面与标签语义层面的典型案例。

表1 现有模型忽略重要信息的典型案例
如表1所示,样例1~样例6的案例表明现有模型仅从汉字字符的角度不能精准判别文本间的语义一致性。首先,如样例1案例表明,当汉字字符不能提供额外的分类特征时,拼音维度的特征信息(/jiu/yi/nian/shu/shen/me/?)可能会对模型的精准分类起到作用。其次,样例2~样例4的案例表明: ①现有模型对文本间关键词汇的区分仅从汉字字符的角度进行区分远不够; ②关键词汇的释义信息对模型的精准分类至关重要。此外,样例5~样例6的案例表明,在真实场景案例表达的语义一致但汉字字符语义不一致的情况下,真实标签(用1表示)隐含了案例一致的关键语义信息。标签所隐含的语义信息往往有助于模型的精准分类,而现有模型在匹配分类时尚未考虑标签信息对模型性能的影响。
现阶段,文本语义匹配任务面临的问题是文本层面和标签层面的语义信息利用不充分,导致模型的泛化性与鲁棒性得不到保证。因此,精准融合文本层面的汉字字形、拼音与释义信息以及标签层面的标签信息来提升模型的性能至关重要。
针对以上问题,本文从文本语义与标签语义两个层面提出一种基于汉字形音义的多元知识和标签嵌入的文本语义匹配模型。该模型的主要思想是: 首先获取文本层面汉字形音义的多元知识并进行融合表示,然后采用标签嵌入的方法将标签信息结合起来,进而再进行语义匹配关系的预测。在相关数据集上的实验表明,本文所提模型的性能得到了有效提升。
本文的主要贡献有以下几点:
(1) 从文本语义的层面,利用汉字形音义多元知识融合表示的方法,挖掘模型在编码时潜在的语义表示。
(2) 从标签语义的层面,利用标签嵌入的方法考虑标签信息对模型的影响来强化最终的预测结果。
(3) 提出一种基于汉字形音义的多元知识和标签嵌入的文本语义匹配模型,模型在LCQMC和BQ Corpus两个公开数据集以及CCF-BDCI-2021问题匹配评测数据集上的实验结果表明,本文所提出的方法有效提升了模型的性能。
1 相关工作
早期的文本匹配方法主要依赖于基于特征的方法,如句法特征的提取、转换和关系抽取[8-9]。基于特征的方法由于只能在非常具体的任务上进行操作,缺乏普适性,模型的性能受到了一定的限制。与此同时,由于缺乏大规模语料的限制,基于深度学习方法的模型性能得不到显著提升。直到2015年,Bowman等人发布了第一个大规模人工标注的数据集SNLI[10-11],深度学习的方法才开始在文本语义匹配的任务上崭露头角。深度学习在文本匹配任务上应用的初期,Huang等人为了优化文本语义信息的表示,构建了DSSM,将查询和文档映射到共同维度的语义空间进行隐含语义模型的学习[12]。Severyn等人通过卷积神经网络对DSSM进行了改进,并采用TextCNN来提取文本语义特征[3]。
随着深度学习的发展,人们开始关注嵌入表示学习,以表示学习为中心的语义表示方法主要有两种: ①基于句子编码的语义表示; ②基于跨句特征或句间注意力的联合特征表示。其中,针对基于句子编码的语义表示,Conneau等人提出一种通用的句向量的表达模型[13];Nie等人通过有监督学习使用这种通用的编码器模型将两个输入句子编码为两个向量,随后使用矢量组合上的分类器来标记两个句子之间的关系[14]。而后,Wang等人提出了一种双向的多角度匹配模型BiMPM,从多个角度利用自定义余弦匹配方程来比较两个向量的相似度[1]。此类方法可将句子编码到当前查询的句子表征中,并可迁移到其他自然语言处理的任务中。虽然此类方法对模型性能有一定的提升作用,但却忽略了两个句子之间的交互特征。
为了弥补句子编码表示的交互性不足的问题,人们开始引入联合特征的表示学习。Parikh等人摒弃传统上词在句子中的时序关系,更多地关注两句话的词之间的交互关系以使得两个句子间产生交互影响[15];Cheng等人通过设计特殊结构及引入词与词之间相关程度的注意力来改进LSTM输入的结构化问题[16]。Chen等人考虑局部推断和推断组合,基于链式LSTMs设计了序列推断模型ESMI,在LSTM的基础上引入了句子间的注意力机制,来实现局部的推断,进而实现全局的推断[17]。Yin等人考虑了句子之间的相互影响,在CNN的基础上构建了一种基于注意力的卷积神经网络(ABCNN),用于对句子对进行建模[4];Gong等人引入了交互式推理网络,通过从交互空间中分层提取语义特征来实现对句子对的高级理解,以此构建了DIIN[18];Kim等人构建了DRCN,在Attention机制的基础上借鉴了图像识别中的DenseNet的密集连接操作,更好地保留了原始特征信息来增强句子语义匹配的表示能力[5]。联合特征表示的方法考虑了两个句子间的交互影响,在一定程度上增强了两个句子间的语义相似性。
基于以上语义表示的方法虽然可有效地提升文本匹配模型的精度,但是却容易丢失查询各自词汇的上下文信息。同时,业界也缺乏大规模的知识表示。直到预训练范式的出现,基于大规模通用语料的模型正是借助了这种优势,有效地提升了模型的性能,一度刷新了文本匹配任务的榜单。其中,代表性的模型有BERT[6]、ERNIE[19]等。
基于大规模语料的预训练有助于文本匹配任务性能的提升,但是这一部分提升也仅仅是利用大规模语料的预训练缓解了通用领域的知识表示缺乏的问题;利用注意力机制[20]缓解了词汇上下文信息丢失的问题。然而在面向复杂场景(涉及真实场景引发的特定知识的语义匹配场景)的语义匹配问题,预训练模型便显得无能为力。
有研究证明,无论是否融入预训练技术引入外部知识均可有效地缓解此类问题。Liu等人将CN-DBpedia 构建的知识图谱作为外部知识库,为模型引入额外的实体特征进行文本匹配的任务增强[21]。Chen等人在不使用注意力机制与预训练技术的前提下,引入依存句法信息与WordNet的词法信息,有效增强文本的匹配性能[22];周等人在使用注意力机制与预训练技术的前提下,引入WordNet与HowNet的词汇信息与词语搭配模块,有效提升文本匹配的模型性能[23]。
虽然基于深度学习的方法在文本语义匹配的任务上的性能可达到先进的水平(State Of The Art)但尚且存在着两方面的弱势: ①从文本语义的层面,未考虑除汉字字符外的潜在语义信息对模型性能的影响; ②从标签语义的层面,未考虑标签隐含的语义信息对模型性能的影响。
2 文本语义匹配模型
本节将分别从任务定义、模型架构、模型的训练及优化等方面进行详细介绍。
2.1 任务定义
文本语义匹配,又称自然语言语义匹配(Natural Language Semantic Matching,NLSM),可形式化地描述为: 给定一个三元组(s1,s2,y)[1],s1和s2的定义如式(1)、式(2)所示。
其中,s1表示长度为m的句子,s2表示为长度为n的句子,y∈Y表示s1和s2之间的关系标签;Y表示0和1的标签集合;ci(i∈[1,m])表示查询s1中的第i个字符;cj(j∈[1,n])表示查询s2中的第j个字符。
文本语义匹配任务可以形式化地表示为基于训练集去估计条件概率f(y|s1,s2),并通过式(3)预测样例之间的关系。
y*=arg maxy∈Yf(y|s1,s2)
(3)
2.2 模型架构
本文模型架构图如图1所示。该模型主要包含文本输入层、信息编码层、信息整合层、标签嵌入层、标签预测层五个部分,各个部分主要功能如下所示:

图1 文本语义匹配模型架构图
(1) 文本输入层: 从汉字形音义三个角度分别获取输入文本的汉字信息、拼音信息、关键词汇的释义信息。
(2) 信息编码层: 对输入文本的汉字信息、拼音信息、关键差异词的释义信息的多元知识进行编码。
(3) 信息整合层: 进一步获取融合汉字形音义多元知识的联合表示。
(4) 标签嵌入层: 基于编码后的分类标签,将标签信息融合至汉字形音义的联合表示,进而生成监督标签。
(5) 标签预测层: 根据信息整合层的联合表示与标签嵌入层的信息表示,得到分类标签与监督标签,以对文本语义匹配关系进行判别。
2.3 文本输入层
为了从文本语义层面强化并利用除汉字字符外的潜在语义信息,本文分别从汉字的形、音、义三个维度进行了相关特征知识的准备。
首先,汉字“形”,即文字本身的形体,主要包含偏旁、部首、字形等。在“形”的层面,本文侧重于汉字字符层面的信息,主要包含两方面: ①基于汉字全字的文本信息,②基于汉字偏旁部首的文本信息。其中,针对汉字全字的文本信息采用SnowNLP(2)https://pypi.org/project/snownlp/0.11.1/进行简体与繁体的统一,针对偏旁部首采用cnradical(3)https://www.cnpython.com/pypi/cnradical进行获取。
其次,汉字“音”,即形体所要表示的读音与音节。从“音”的层面,本文考虑字音的特征增强,基于Pinyin API(4)https://pypi.org/project/pypinyin/获取拼音维度的信息。
最后,汉字“义”,即形体所能表达出来的意义。从“义”的层面,本文收集了百科词典与百科知识(5)https://dict.baidu.com/的最新释义从词级粒度强化文本的语义信息。
2.4 信息编码层
2.4.1 汉字形与汉字音的编码
字形、字音、释义是汉字的重要组成部分,这三个方面在语言理解层面包含有重要的语义信息,而传统模型在编码时通常仅对汉字全字进行编码,忽略了除去汉字以外潜在数据的重要信息。因此,传统上的模型只能够从汉字全字表征的角度去计算语义相似度,这样往往不能够获取到丰富的语义差异信息,从而导致模型对文本层面汉字、拼音以及释义交叉干扰的样本不敏感。
为了丰富文本的语义信息,在语义表示的层面也有相关的研究对此进行了探索。Sun等人[24]曾在BERT的基础上,融合中文字体与拼音来增强文本的潜在语义信息表示。本文在此基础上进一步扩展,从汉字的形、音、义三个维度进行丰富文本的语义信息及捕获句间词级粒度的语义差异信息。汉字形音义融合过程如图2所示,其中释义编码具体细节见图3。

图2 汉字形音义融合示例图

图3 释义信息捕获示例图
本文在得到句子差异成分的语义信息的同时,将s1和s2的汉字文本与拼音文本作为输入,与采用BERT进行编码。具体地,汉字文本层面表示主要包含基于汉字全字的文本信息表示和基于汉字偏旁部首的文本信息表示。本文将汉字全字进行简体与繁体的统一后,采用BERT进行编码表示,得到全字的文本信息表示;同时将偏旁部首信息用BERT编码表示,并与全字表示进行融合,从而得到汉字层面的最终表示。由于拼音信息的表示不同于中文字符的编码,而与英文相似,因此本文采用BERT的英文编码进行拼音信息的表示。
式(4)与式(5)中{Uform,Upinyin}∈Rl×h中,l=3+m+n表示输入字符的长度,h为隐藏层维度。

2.4.2 释义编码
在自然语言处理领域中,难点并不是汉字信息与拼音信息的获取,而是如何精准获取文本间句子的主要差异成分并将其语义化。语义化句子间的主要差异成分,并不是简单、机械地获取文本间的字符差异即可,它还要求我们能够挖掘其深层的意思并进行语义表示。因此,本文首先通过词级粒度语义信息捕获操作获取句子间的主要差异成分,然后结合外部释义知识挖掘词级信息背后潜在的语义信息,以此来增强模型在文本层面的语义表示。
其中,词级粒度语义差异信息捕获算法如表2所示。给定一个三元组(s1,s2,y),其中,s1和s2分别表示长度为m和长度为n的句子。

表2 词级粒度语义信息捕获算法
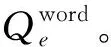

词义辨析任务一直以来是自然语言处理中的一大难题,针对本文任务,一词多义主要会带来由多义现象引发的释义信息不匹配的问题。具体来讲,释义信息不匹配的问题主要表现在由词语释义选取不恰当造成的当前语境下真实释义不匹配的问题,如“人家肚中有墨水”的“墨水”表示“文化与知识”,同时“墨水”还有“有颜色的液体、染料”的释义,模型无法精准获取语境所需词语的真实释义是一大难题。对于这类问题,本文并未针对性地处理一词多义现象,而是将一词多义的词语释义进行拼接。具体地,本文在释义拼接前,首先进行了释义预处理,并分别与原查询进行相似度计算排序,最终选取TOP3的释义,从而得到当前词语的最优释义信息。


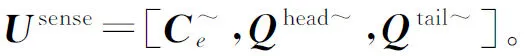
2.5 信息整合层
信息整合层主要是基于信息编码层编码得到的汉字形嵌入、汉字音嵌入、汉字义嵌入的多元知识进行融合,如图4所示。

图4 多元知识信息整合图
因此,最终可得到文本间汉字的形音义的综合语义表示U=[Uform;Upinyin;Usense]。
2.6 标签嵌入层
考虑到文本层面与标签层面的因素会交叉干扰样本的预测,导致模型的预测结果不乐观。因此,为了解决这个问题,使得标签信息可以与文本信息进行交互,本文将编码后的分类信息融合至汉字形音义的联合表示中。
为了让模型可以学习到文本层面与标签层面之间的关联,本文在标签嵌入层设计了如表3所示的两种标签类型: ①真实标签(TL),表示原始样本样例s1与s2之间的语义是否匹配; ②监督标签(SL),表示样例s1与s2之间的语义关系与真实标签(TL)表达的语义关系是否一致。

表3 标签嵌入层数据构造示例表
具体地,如表3所示,本文设定原始数据集中的数据样本为正例,然后针对正例构造了对应的负例。如No.1案例中的正例为原始数据集中的数据,正例s1与s2间的语义关系为不匹配(用0表示),真实标签为不匹配(用0表示),真实标签与样例句间语义均表示不匹配,因此监督标签为一致(用1表示)。与此同时,本文针对正例构造了负例。如表3的No.1案例中,负例为针对No.1正例构造的负例数据,构造的负例s1与s2间的语义关系为不匹配(用0表示),构造该负例的真实标签为匹配(用1表示),真实标签与样例句间语义不一致,因此构造负例的监督标签为不一致(用0表示)。
一方面,本文将原始真实标签作为模型Pipeline正常预测的类别标签yc;另一方面,将其作为嵌入标签信息与汉字形音义的语义表示进行整合,以用来生成监督标签ys。标签嵌入层的目的主要是将编码后的分类标签yc融合至汉字形音义的语义表示U。
本文在对标签集Y={ypos,yneg}进行编码时采用BERT进行编码,同时保证编码后的向量逆向平行。即,
基于得到的类别标签嵌入表示C与汉字形音义的语义表示U进行融合操作,如式(17)、式(18)所示。
其中,Sp表示汉字形音义与标签嵌入的联合表示,⊗代表张量的哈达玛乘积(Hadamard Product)。
2.7 标签预测层
标签预测层主要是根据信息整合层的联合表示与标签嵌入层的信息表示,得到分类匹配标签与监督标签,然后对文本语义匹配关系进行判别。
将基于信息整合层得到的汉字形音义的语义表示U输入到全连接层,得到隐藏特征之间的关联表示Up,然后经过线性分类器进行分类以得到分类匹配标签,如式(19)~式(21)所示。

基于汉字形音义与标签嵌入的联合表示Sp,进行分类以得到监督标签,如式(22)、式(23)所示。
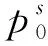
根据分类匹配标签与监督标签所对应的概率,来对给定的文本进行语义匹配关系的判别。
y*= arg maxyu∈YuPu⊙arg maxys∈YsPs
(24)
其中,y*表示s1和s2之间最终预测的语义一致性标签;Yu表示初步分类匹配的语义一致性标签,且Yu∈{0,1};Ys表示分类匹配标签的监督信号;⊙表示同或运算。
2.8 模型的训练及优化
本文实验的环境为32GB显存的Tesla V100。模型采用Adam优化器[25]对模型进行优化,并使用mini-batch进行梯度下降,初始学习率设置为2e-5,权重衰减为0.05。训练阶段Batch size设置为48,评估阶段Batch size设置为64,Epoch设置为3,预训练模型输入的最大序列长度为256。与此同时,采用交叉熵与交叉熵的变体Focal损失[26]构造损失函数。
本文采用交叉熵损失函数Lce作为基础损失,如式(25)、式(26)所示。
为了解决正负样本数量与样本难度不均衡的问题,本文引入了Focal损失来平衡样本数据。Focal损失公式如式(27)所示。
Lfl=-α(1-P(y))γlog(P(y))
(27)
其中,α为正负样本比例权重平衡因子,初始值设置为1.0;γ为样本难度权重平衡因子,初始值设置为2.0。
本文的损失函数主要由分类损失函数LC与信号监督损失函数LS两部分组成,如式(28)~式(30)所示。
其中,Lce表示交叉熵损失;Lfl表示Focal损失;η表示Focal损失的调节参数,初始值设置为0.1。
3 实验
为了验证模型的有效性,本文在多个数据集上进行了实验。本节首先简要介绍本文实验的数据集,然后给出实验所使用的评价指标,给出本文的主要实验结果、消融实验结果以及泛化能力实验结果来验证实验方法的有效性,最后结合实验结果给出相应的分析。
3.1 数据集
3.1.1 数据集介绍
本文针对来自文本层面与标签层面的预测干扰展开研究,因此选取了与Sun等人[24]匹配任务一致的公开数据集LCQMC[27]、BQ[28]以及CCF-BDCI-2021问题匹配任务(6)https://www.datafountain.cn/competitions/516/datasets的数据集进行实验。
(1)LCQMC数据集哈工大公开发布的语义匹配数据集。该数据集来自各个领域搜索引擎的实际搜索场景;该数据集复杂多样,数据的文本层面具有交叉性干扰和多样性匹配的特点,其中,交叉性干扰存在对文本层面的拼音、释义和标签信息交叉干扰的考察,多样性匹配包含对意图、浓缩、短语、同义及重排等多种类型的考察。
(2)BQ数据集哈工大公开发布的语义匹配数据集。该数据集来源于银行真实场景下的客户信贷服务日志,数据集内存在字形、拼音及标签信息多种特征交叉干扰预测的现象。
(3)CCF-BDCI-2021评测数据集中国计算机学会与百度联合推出的评测数据集,由多个数据集构成,覆盖了许多真实场景中的问题,标签信息更侧重于真实场景下语义的表达。数据集中存在大量的文本层面与标签层面的干扰问题。
3.1.2 数据集划分
LCQMC与BQ两个数据集分别包含260 068个口语化文本样例与120 000个信贷问题样例。CCF-BDCI-2021问题匹配评测主办方公开的数据,共计534 742个文本样例。三个数据集具体的数据划分如表4所示。

表4 数据集划分比例
3.2 评价指标
本文实验的评价指标采用准确率(Accuracy,Acc)来衡量模型整体性能,如式(31)所示。
(31)
其中,TP表示被模型判别为正例的正例样本数,TN表示被模型判别为负例的负例样本数;FP表示被模型判别为正例的负例样本数;FN表示被模型判别为负例的正例样本数。
3.3 实验方法对比
为了验证本文提出方法的性能,在语义匹配数据集上将本文的方法与以下七种方法进行了对比。这些模型具体如下:
CONVNET[3]: 传统上主流的文本语义匹配模型,是单语义模型的一种改进。
ABCNN[4]: 传统上主流的文本语义匹配模型,在CNN的基础上构建了一种基于注意力的卷积神经网络。
BERT[6]: 谷歌公开的预训练模型。
BERT-WWM[29]: 哈工大基于中文BERT进行全词掩码的中文预训练模型。
ERNIE[19]: 百度公开的预训练模型。
ERNIE-Gram[30]: 百度公开的预训练模型,在ERNIE的基础上进行改进,引入了n-gram掩码机制。
ChineseBERT[24]: 香侬科技公开的预训练模型,在BERT的基础上从文本层面将汉字字体与字音的表示整合到语言模型的预训练中进行了改进。
3.4 实验结果
本文将ERNIE作为预训练模型进行实验,与3.3节设计的七种方法进行对比实验,具体的实验结果如表5所示。

表5 不同方法的实验结果 (单位: %)
从表5中的数据可以看出:
(1) 本文提出的模型在验证集与测试集上表现均优于其他七种模型,说明本文融合汉字形音义与标签嵌入的方法针对文本层面与标签层面上语义交叉干扰的语义判别是有效的。
(2) 本文的模型不仅优于ERNIE,而且优于ChineseBERT模型,是因为一方面相比于ERNIE,本文的模型将文本语义层面的汉字字形、拼音与释义信息整合到模型中,增强了除汉字字符信息外的文本语义表示;另一方面,相比于ChineseBERT,本文的模型还从标签语义的层面融入了标签信息到模型中,捕获了标签层面隐含的文本语义信息。
综上,这充分说明了从文本层面与标签层面融合汉字形音义多元知识的表示与标签信息的表示有助于提升模型的性能。
3.5 消融实验
为了验证不同模块的有效性,本文分别对信息整合层(Information Integration Layer,IIL)、标签嵌入层(Label Embedding Layer,LEL)进行消融去掉,来观测模型性能的变化,具体结果如表6所示。
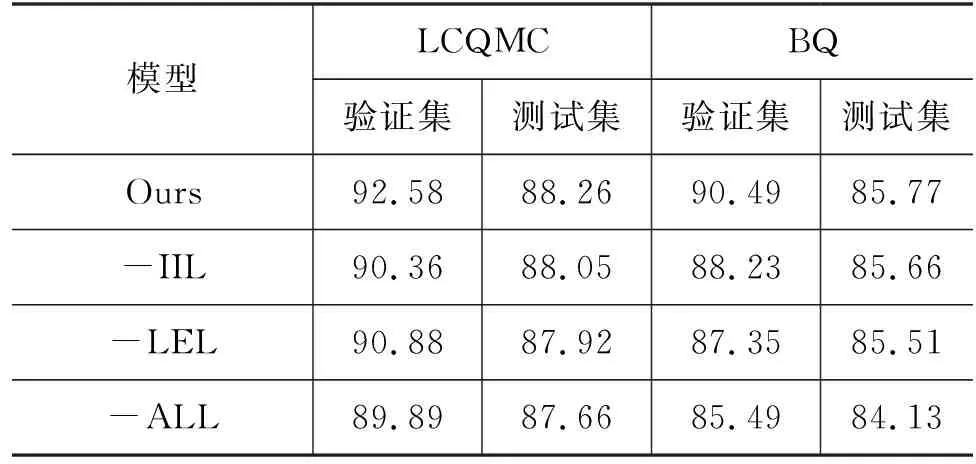
表6 消融实验的结果 (单位: %)
表6中的数据可以看出:
(1) 信息整合层(IIL)与标签嵌入层(LEL)均会影响模型的性能。其中,消融去掉标签嵌入层(LEL)后,模型的性能下降较大,说明标签嵌入层(LEL)贡献较大。这表明在现阶段模型缺失的语义信息中,标签信息所占的比例更大。
(2) 相比于模型-ALL,模型-LEL的性能也取得了一定的提升,这说明信息整合层(IIL)的融合汉字形音义多元知识的表示有助于增强文本原先的语义表示,进而提升模型匹配判别的性能。
3.6 模型泛化能力实验
为了验证本文方法的泛化性与鲁棒性,本文选取了CCF-BDCI-2021来自真实应用场景问题匹配的评测数据集进行实验。由于CCF-BDCI-2021问题匹配评测任务主办方未公开测试集,本文只能在训练集与验证集上进行测试。本文将原始验证集按照1:1的比例进行随机等比例切分,形成新的验证集与测试集,数据划分比例如表4所示。
与此同时,本文选取了传统模型与现阶段主流的预训练模型进行对比实验,实验结果如表7所示。

表7 模型泛化能力实验结果 (单位: %)
由表7的实验结果可以看出:
相比于传统模型与现阶段主流的预训练语言模型,本文的模型融合汉字形音义的文本语义表示与标签嵌入的标签语义表示得到了明显的性能提升,这充分说明了本文提出的模型有较好的泛化能力。
3.7 案例分析
为了验证本文方法在不同数据类型上的性能,本文进一步对模型的预测数据进行了分析。
3.7.1 案例对比分析
经过对比分析,我们发现,本文的模型在文本层面的拼音及释义产生的问题上表现较好,具体细节如图5所示。

图5 汉字形音义角度案例分析对比图
其中,query1和query2分别表示待匹配的两个文本;label表示真实匹配标签;左半部分的pred_label与y_probs分别表示ERNIE最终预测结果与对应的概率;右半部分的final_pred_label表示本文模型最终预测结果;pred_class_label和pred_superviser_label分别表示中间过程分类标签的预测结果及生成的监督标签结果。
如E1所示,大规模预训练模型ERNIE从汉字字符的角度可区分开来E1中的“螨虫”和“满虫”的差异,并认为二者的语义不一致。然而E1真实语境下的标签为一致,ERNIE基于汉字字符并未学习到二者的一致性。然而本文的方法,融合字形、拼音与释义的信息后,可从拼音的角度强化其语义信息,最终预测正确。如E2所示,针对单义现象,在不经过释义信息融合的情况下,ERNIE并不能得到正确的预测结果,而本文经过融合释义信息对文本语义增强,模型可对“猕猴桃”与“奇异果”的案例预测正确。如E3所示,针对多义现象,本文将一词多义的词语释义进行拼接,最大程度地为模型释义维度提供了最优释义信息,使得由缺失释义信息导致错误的样本“卖”与“买”的案例可预测正确。
与此同时,我们发现,本文的模型融合标签嵌入的表示在一定程度上可弥补预训练模型的部分缺陷。例如,预训练模型会倾向于将字符重叠度较高的文本视为语义一致。如图6所示,ERNIE会认为“这个季节吃什么水果好”与“各个季节吃什么水果好”的语义一致。同样,本文的模型基于汉字形音义信息也未捕获到二者的区别,但本文模型融合标签特征信息后,对分类匹配标签进行监督再判别,最终预测正确。

图6 标签嵌入角度案例分析对比图
3.7.2 错误案例分析
通过对本文模型预测的数据进行分析,我们筛选出了模型预测错误的案例,如图7所示。

图7 错误案例示例图
经过分析,我们发现:
首先,本文的模型覆盖的释义尚且不全面。如图7中E5所示,模型并未精准识别“一米五以上小孩”是“未成年小孩”。因此该样本预测错误,且预训练模型ERNIE也未正确预测。
其次,本文的模型对涉及到的句法结构变换语义的样本数据并不敏感。如图7中E6和E7所示,“过期的茶叶”与“茶叶快过期”、“为什么……公交卡……”与“公交卡为啥……”,标签嵌入方法并未对此类样本语义的计算产生积极的影响。
再次,本文的模型尚且无法区分程度等修饰语的语义成分。如图7中E8和E9所示,“最好看”与“好看”、“挺难受”与“很难过”的程度修饰语义未能被捕捉,导致模型预测错误。
最后,本文的模型并未彻底解决由一词多义导致的真实释义选取不准确的问题,目标仅是最大程度地覆盖模型所需的释义。
4 结论
本文围绕文本语义匹配任务中文本层面和标签层面的语义问题进行研究,提出一种基于汉字形音义与标签嵌入的文本语义匹配模型。
该模型采用知识融合与标签嵌入的方法引入文本层面与标签层面隐含语义知识,提升了文本语义匹配的性能。该模型从文本语义层面进行了汉字字形、拼音及释义的多元知识整合,解决了文本层面涉及形、音、义多维度的语义交叉干扰的问题;从标签语义层面进行了标签信息的嵌入表示,并进一步引入标签监督信息,丰富了文本潜在的语义信息。经过实验对比,验证了本文模型的有效性。进一步对案例分析发现,在提升模型性能的同时,本文的方法在释义覆盖、句法结构、程度修饰以及一词多义的释义信息等细节问题上尚且存在一定的缺陷,后续的研究中将从句法结构、语法信息等角度围绕这些问题展开研究。
