基于CA-GRU的污水处理厂出水总氮浓度预测研究
2024-05-07廖明潮
吴 婧,廖明潮
(武汉轻工大学数学与计算机学院,湖北 武汉 430000)
0 引言
随着人类经济社会的发展,水污染问题日益突出。城市化和工业化过程带来了大量的废水排放。这些废水中含有大量的有机物、营养物和有害物质。废水排入水体会导致地表水的恶化,对水生态系统以及人类的健康产生严重威胁。为了减轻水污染对生态环境的影响,各国政府和相关部门采取了一系列措施。措施之一就是建立污水处理厂,对污水进行处理后再排放。因此,对污水处理厂出水水质的监测和预测变得尤为重要。
总氮是水质指标中的重要参数之一,对污染物的追踪和评估具有重要作用。污水处理厂出水水质中的总氮预测[1-2]是以出水的实测数据为基础,利用数学模型预测出水水质中总氮的变化情况。近年来,随着人工智能技术的快速发展,深度学习在各领域的应用越来越广泛。许多经典的算法被用于污水处理厂出水水质的预测研究。其中,深度学习在时间序列预测中得到了广泛的应用。长短期记忆[3](long short-term memory,LSTM)神经网络模型是循环神经网络(recurrent neural network,RNN)预测模型的一种改进模型,具有强大的信息捕获以及存储能力,可以有效地捕捉长序列之间的语义关联,同时能够缓解梯度消失或梯度爆炸的问题。门控循环单元(gate recurrent unit,GRU)模型是LSTM模型的变体。与LSTM相比,GRU因少1个门而参数更少,更加便于训练,并且可以防止出现过拟合的情况、节省训练时间。
然而,这些模型仍存在一些问题,如对局部变化的捕捉不足等。相比之下,卷积神经网络(convolutional neural network,CNN)预测模型可以更充分地提取数据中的有效信息,降低由参数带来的预测误差,从而提高预测精度。
本文提出了基于卷积注意-门控循环单元(convolutional attention-gate current unit,CA-GRU)网络的混合模型,并以呼玛县某污水处理厂的实际监测数据为样本对模型进行训练与验证,从而提升预测准确度。验证结果证明了本文模型的有效性。该研究为污水处理厂出水水质的监测和预测提供了一种新的解决方案。
1 相关方法分析
1.1 GRU模型
GRU模型的结构如图1所示。
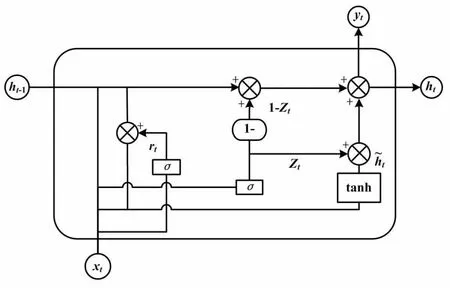
图1 GRU模型结构
GRU是1种常用于自然语言处理和序列数据处理的RNN模型。GRU能够有效捕捉长序列之间的语义关联,并且缓解梯度消失或爆炸现象。与LSTM相比,GRU的结构和计算更为简单。GRU的核心结构由更新门和重置门这2个部分组成。这2个门的作用是控制当前时刻输入和前一时刻输出之间的权重,从而保留前一时刻的输出特征。相比于LSTM,GRU参数更少、模型训练过程中迭代速度更快,因而更便于计算,可提高模型效率。
GRU的计算方式如下。
rt=σ(Wr[ht-1,xt])
(1)
式中:rt为重置门的输出;xt为输入序列的第t个元素;ht-1为GRU模型在第(t-1)个时间步的输出;σ为Sigmoid函数;Wr为待学习的权重矩阵。
zt=σ(Wz[ht-1,xt])
(2)
式中:zt为更新门的输出;Wz为待学习的权重矩阵。
(3)
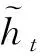
(4)
式中:ht为GRU模型在第t个时间步的输出。
1.2 CNN模型
CNN是1种在图像识别、自然语言处理等领域广泛应用的深度学习模型。CNN由多层神经网络组成,包括输入层、卷积层、激活函数层、池化层和全连接层,用于进行多层次的特征提取、筛选、网络表达和分类。在CNN中,卷积层和池化层是关键组成部分。卷积层通过卷积运算对输入数据进行局部特征提取,并利用卷积核与输入数据进行逐点相乘和求和,从而从输入数据中提取出图像的局部特征(如边缘、纹理等)。池化层则用于对提取的特征进行筛选和压缩,以减少参数数量、降低计算复杂度,同时保留关键特征。激活函数层在CNN中起到增强网络表达能力的作用。它通过引入非线性,使网络能够学习更复杂的特征表示,从而提高模型的表达能力和拟合能力。常用的激活函数有修正线性单元(rectified linear unit,ReLU)、Sigmoid和Tanh等。全连接层作为分类器,负责将经过特征提取和网络表达的特征映射到类别概率空间,从而进行最终的分类决策。CNN模型的核心就是卷积运算。卷积运算是1种在不同函数之间加权平均的方法,用于提取输入信号中的某些特征。
1.3 CA-GRU混合模型
CA-GRU混合模型以GRU模型为基础,将CNN添加注意力机制,从时间和空间维度上充分提取数据特征。由于采用数据集的参数较多,更需要注意各参数特征的相关性。因此,CA-GRU模型比其他传统的模型获取到的特征信息更加精确。这使得CA-GRU混合模型的预测结果更精确。
CA-GRU混合模型整体框架如图2所示。
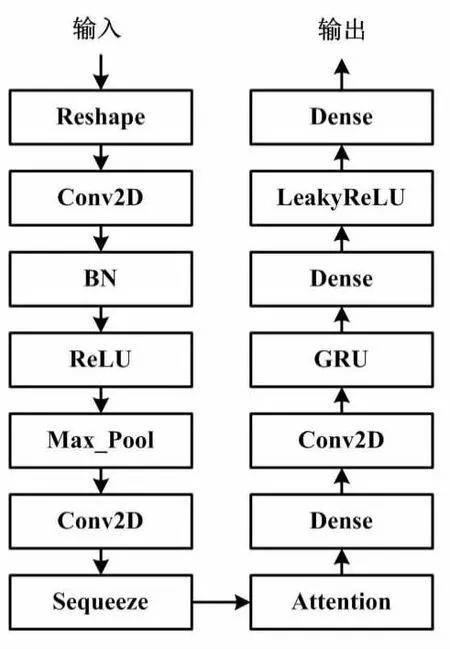
图2 CA-GRU混合模型整体框架
卷积操作是1种重要的提取目标特征的方法。注意力机制[4-5]可以对特征进行校正,保留有价值的特征,并关注抓取的特征信息。滑动窗口[6]是1种在时间序列分析中常用的技术。该技术以指定的步长在时间序列上滑动固定长度的窗口,从而计算窗口内数据的统计指标。这种方法类似于在时间序列上移动1个固定长度的窗口,并在每个滑动位置上进行数据采样。这样可以对时间序列数据进行更加全面和精确的分析,从而获得更具解释性和预测性的结果,以达到提高数据准确性的目的。批归一化(batch normalization,BN)层可以加速网络收敛速度,防止梯度爆炸、梯度消失和过拟合。ReLU在输入为负值时会输出0,导致梯度无法传递,从而使得神经元无法更新权重。Leaky ReLU是在ReLU的基础上引入了1个小的斜率,以解决ReLU在输入负值时可能出现的“死亡神经元”问题。
2 CA-GRU模型构建
本文对原始数据作预处理后,按时间滑动窗口构建连续特征图,并以此作为CNN的输入。通过调整数据维度,由CNN完成初步的特征提取。特征提取完成后通过降维,经过注意力层和GRU层得到预测结果。初步特征的提取通过2层二维的CNN完成:第一层卷积层的卷积核设为(3,3)、步长设为1、滤波器设为8;第二层卷积层进行调整通道数,通过压缩操作将最后1个维度挤压掉。在CNN完成初步的特征提取后,本文将提取到的特征传入注意力机制与GRU组成的网络中,以完成预测。
基于CA-GRU模型的算法步骤如下。
①对数据进行预处理,包括填充缺失数据和数据标准化。对缺失数据可采取邻近均值法实现填充。
②将数据集的75%划分为训练集、10%划分为验证集、15%划分为测试集,从而使用更多的数据来进行模型训练,以获得模型的最优参数。根据时间序列滑动窗构造训练集、验证集和测试集。
③构建基于CA-GRU混合模型的污水处理厂出水总氮预测模型。
④用训练集训练CA-GRU后,通过验证集调整模型的超参数,并根据训练损失变化曲线和验证损失变化的趋势不断地修改模型,从而得到更好的预测模型。
⑤在得到的最优模型中输入测试集,以得到预测结果,并绘制真实值与预测值曲线。
3 试验分析
3.1 数据集介绍
试验中的污水处理厂水质数据来源于黑龙江省大兴安岭地区呼玛县某污水处理厂2021年的监测数据。总氮[7]指污水中4种含氮化合物(即有机氮、氨氮、亚硝酸盐氮、硝酸盐氮)的总量,是重要的水质检测指标之一。数据集共有2 206组数据。监测时间从2021年10月1日至2021年12月31日。试验每隔1 h记录1次。其中:数据输入特征为排水流量、化学需氧量进口浓度、化学需氧量排口浓度、生化需氧量进口浓度、生化需氧量排口浓度、总氮进口浓度、氨氮进口浓度、氨氮排口浓度、总磷进口浓度、总磷排口浓度;输出特征为总氮排口浓度。各特征数据具有一定的周期性。
3.2 模型评价标准
为了更准确地评价模型预测能力,本文采用均方根误差(root mean square error,RMSE)和平均绝对百分比误差(mean absolute percentage error,MAPE)对预测结果进行评估。RMSE用于衡量观测值与真实值之间的偏差。模型的RMSE值越低,其预测结果越稳定。MAPE表示模型的准确性。模型的MAPE值越小,则精准度越高。
(5)
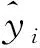
(6)
式中:MMAPE为MAPE值。
3.3 模型参数
试验中:模型训练时学习率设为0.002;损失函数使用平均绝对误差(mean absolute error,MAE),以计算标签值和预测值之间的绝对差异的平均值;优化器选用Adam;批量大小设为16;迭代次数设为100;时间滑动窗口为120。随机失活是1种常用的正则化技术,可以随机地将神经元的输出设置为0,使得被屏蔽的神经元不会对网络的输出产生影响。这种方法可以减少过拟合现象的发生,从而提高模型的泛化能力。在前向传播时,被屏蔽的神经元不参与运算;在反向传播时,被屏蔽的神经元梯度也被设置为0,从而避免了梯度爆炸的问题。为了防止过拟合,试验设置了提前停止。当模型连续10次训练损失值不下降时,模型停止训练。
为了验证本文提出的基于CA-GRU网络的混合模型的实际效果,试验对CA-GRU混合模型与GRU模型[8]、CNN-GRU[9-10]模型以及Attention-GRU[11-12]模型进行对比。试验中,所设置的迭代次数、优化器、批量大小都一致。其中:GRU模型的神经元数量设为8、随机失活概率设为0.5;CNN-GRU模型的滤波器设为8、卷积核尺寸设为(3,3)、神经元数量设为16、随机失活概率设为0.2;Attention-GRU模型的神经元数量设为8、随机失活概率设为0.5;CA-GRU混合模型的滤波器设为8、卷积核尺寸设为(3,3)、神经元数量设为32、随机失活概率设为0.5。
3.4 结果分析
试验采用Windows10操作系统,并使用Python语言进行编码。Python的版本为3.8.5。编程工具为PyCharm。其中,各模型均使用Keras实现。
根据各模型训练时的损失数据,训练损失变化曲线如图3所示。
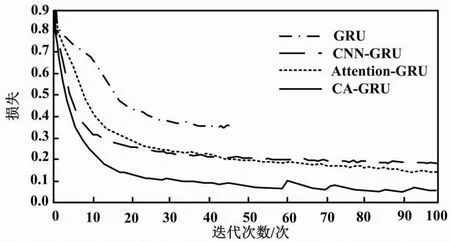
图3 训练损失变化曲线
由图3可知,在同样的学习率、优化器条件下,GRU模型在训练到第48次时停止训练。根据对比结果可知,CA-GRU混合模型的训练损失相较其他模型更小。
根据确定的模型,将输入数据换成测试集,以得到预测结果。
各模型测试集预测值与实际值对比如图4所示。
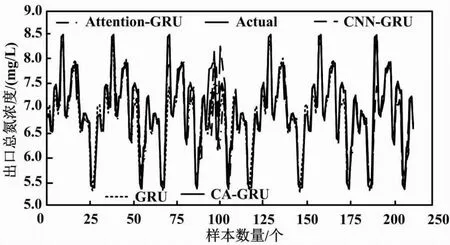
图4 各模型测试集预测值与实际值对比
由图4可知,与GRU、CNN-GRU、Attention-GRU模型相比,本文采用的基于CA-GRU网络的混合模型的水质预测结果更接近目标值,并且预测值与实际值的偏差较小。CA-GRU混合模型对污水处理厂出水总氮浓度的预测表现出较好的性能。此外,结合图3中CA-GRU混合模型训练损失明显低于其他模型的结果,试验证明了CA-GRU模型具备更优秀的学习与预测能力。
同时,本文使用RMSE和MAPE对模型预测结果进行评估。
各模型预测性能如表1所示。
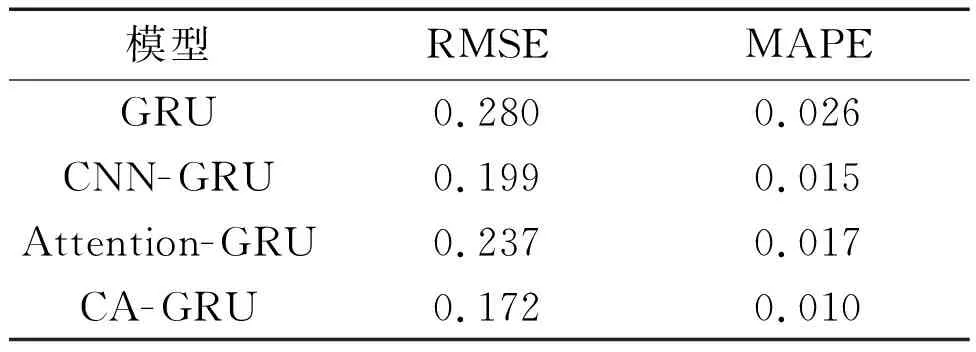
表1 各模型预测性能
由表1可知,CA-GRU混合模型的RMSE、MAPE比GRU模型低0.108、0.016,比CNN-GRU模型低0.027、0.005,比Attention-GRU模型低0.065、0.007。试验结果表明,CA-GRU混合模型在污水处理厂出水总氮浓度预测方面优于传统的GRU模型、CNN-GRU模型与Attention-GRU模型。
4 结论
本文提出了1种基于CA-GRU网络的污水处理厂出水总氮浓度预测混合模型。该模型首先对原始数据进行维度调整,然后结合CNN模型和注意力机制进行特征信息提取,最后通过GRU网络实现对出水总氮浓度的预测。试验结果表明,CA-GRU混合模型能够更加关注数据中的关键信息、消除冗余信息,对总氮浓度预测效果较好。与传统GRU模型、CNN-GRU模型以及Attention-GRU模型相比,CA-GRU混合模型对于污水处理厂出水总氮浓度预测的准确率更高,因而实用价值更高。
