基于情绪计算的GIS 硕士面试成绩预测
2024-05-07付康钰杨妙玲
费 腾,付康钰,卞 萌,杨妙玲
(1. 武汉大学资源与环境科学学院,湖北 武汉 430079;2. 武汉大学遥感信息工程学院,湖北 武汉 430079)
近年来,我国普通高校中地理信息科学(geographic information science,GIS)相关专业人才培养的规模不断扩大,为适应地理信息行业发展需求,对GIS 人才培养方法进行创新具有重要意义。GIS 专业研究生选拔除了考查学生的专业基础知识,更重要的是考查学生是否具有科学研究的综合素质[1-2]。相对笔试而言,面试可以弥补笔试的不足,即在较短的时间内考查学生的语言组织能力,应变能力,表达能力等研究素质。传统面试需要多名经验丰富的考官在现场考核,人力资源与时间成本大。随着信息技术的发展,信息技术和学习管理系统在教学和评估中的兴起,为GIS人才面试的快速评估提供了一种选择[3]。
“价值-控制”理论认为学业成就情绪会影响学业行为与表现[4],国内外学者对情绪与学生成绩表现的相关性进行了研究,结果表明情绪是有效学习和解决问题的一个关键组成部分,对学生成绩和表现是重要的影响因素[5]。此外,面试中的情绪表达可能对面试评分存在重要影响。研究表明,对求职者面试表现的主观印象是决定面试官评价的一个重要因素[6],情绪的自我调节和表现会影响面试的结果,具有更高社交能力的个体善于传递情感和社交信息,从而在结构化面试中获得更好的评价[7]。因此在教学与面试中进行情绪的挖掘和成绩预测研究具有实践价值。
从目前的研究中发现机器学习算法在教学领域多用于学习成绩预测与考核任务的自动评分,但对于面试的评估研究较少。此外,在心理学、教育、医学等各个领域中,机器学习的方法已被证明能从教育数据中寻找规律以达到良好的预测效果[8]。因此,本文聚焦GIS 领域人才选拔方法的创新,基于GIS 专业硕士面试过程的视频数据,拟从受试者面部表情出发,训练并使用卷积神经网络实时识别人脸情绪,建立基于时间序列的情绪特征,进而采用4 种机器学习模型分析情绪特征与面试成绩的关系,并通过比较模型精度指标,选择最优模型,了解在多大程度上面试者的面部情绪信息可被用来预测面试成绩,旨在推动GIS 人才培养方法的改革创新。
1 实验流程和数据获取
1.1 研究对象
某双一流大学的某年的46 名大四学生参与了本研究,有效被试为44名,其中女生23名,男生11名。学生中最大年龄为23岁,最小年龄为20岁,平均年龄为21.5岁,他们分别来自地理科学类专业、土地资源管理专业。
1.2 实验流程
本实验为选拔性综合面试,考核内容为英语能力与专业知识掌握情况。每位面试者面试时长为10~15 min。获取每位面试者固定时长的视频数据,在该时间内面试者将完成2 项任务,分别是英语自我介绍、第一个GIS专业问题回答。
1.3 数据获取
为了避免不相关因素的干扰,面试视频数据采集经过严格控制,录制视频时在光线充足,明亮的环境,固定摄像头角度进行正面拍摄,为了有效捕捉受试者情绪变化,采集帧率设置为30 帧/s[9],采集时长为面试开始的前200 s,后续人脸识别将无法识别情绪或人脸的视频帧进行剔除。
为了评估面试表现,聘请5 名行业专家、研究生导师根据英语能力、专业知识回答、心理素质3 项指标以百分制的方式对学生进行打分,评分表如表1所示,每个学生的最终得分为5 位专家评分的均值,英语能力、专业知识、心理素质分别占总分的30%、50%和20%。

表1 专家评分表
2 研究方法
2.1 mini_Xception面部情绪识别
mini_Xception架构是一个全卷积神经网络,它由3 个普通卷积层和4 个残差模块以及3 个池化层组成,如图1 所示,作为全卷积神经网络的主流框架,与其他模型相比,有更好的性能[10]。该架构使用Dlib 库进行人脸检测,其预训练模型在FER-2013 数据集上测试情感分类任务获得了的65.9%的准确率。本研究对Fer-2013 数据集进行一系列的扩充,将图像进行旋转、变形、归一化等图像增强操作,然后利用扩充后的数据集进行训练并保存为HDF5 文件,最终其精度达到70.00%。除了“中立”情绪外,6 种情绪可从面部表情中识别并量化:“开心”、“悲伤”、“厌恶”、“惊讶”、“恐惧”和“生气”。本研究使用训练后的mini_Xception 模型对视频中面试者的情绪进行提取,使用Harr分类器[11]获取人脸区域坐标从而提取人脸图片,进行人脸面部特征的识别和人脸表情的分类,得到每一张人脸对应的每一种表情的概率值预测的集合,并将分类结果记录在数据库中。
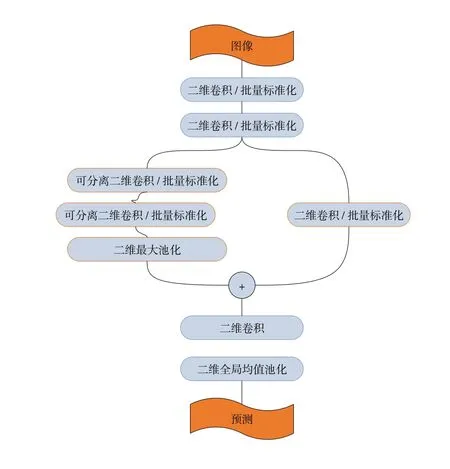
图1 mini_Xception架构
2.2 生成潜在有效的情绪特征组合
通过机器学习模型提取的情绪参数为时域上的数据集,该数据集为44×200×9 的矩阵。其中,44 为面试者人数,200 为采样数(1 Hz×200 s);9 列数据中除了第1 列和第2 列为样本ID 和采集时间,其他7 列为不同情绪的预测概率值。Tsfresh是基于Python的开源时序数据特征提取工具包,内置了众多统计学的特征计算函数,例如计算均值、标准差等常规统计量,与传统特征提取方法比,其提取效率高和范围广,能自动计算出大量的时间序列特征[12],部分特征如表2所示。情绪特征工程的流程如图2 所示,最终对情绪时序数据提取了5509×44维时序特征。
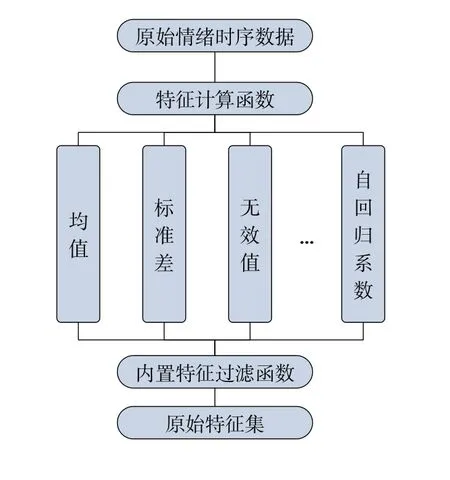
图2 Tsfresh特征提取流程

表2 Tsfresh特征工程包含的部分特征
2.3 特征选择
本研究对提取的众多时序特征进行初步筛选,先剔除对面试分数预测无关的特征,包括单一取值的特征、低相关性的特征。研究设置了情绪特征与面试综合分数的相关性阈值,对其绝对值大于0.45,并且通过P<0.05 显著性检验的情绪特征进行保留。为了避免多重共线性造成模型失真,在进行模型回归前对特征进行多重共线性检验,筛选合适的特征,保证回归模型的可靠性。通过计算方差膨胀因子(variance inflation factor,VIF)进行共线性检验[13],VIF评估当预测因子相关时,回归系数的方差会增加多少,该值越大意味着共线性越强,回归系数难以估计准确。本研究对VIF大于10的特征进行剔除,确定特征数据集,最终得到满足要求的12个情绪特征,进行模型回归。
2.4 回归模型构建与分析
偏最小二乘回归(partial least square regression,PLSR)以及支持向量回归(support vector regression,SVR)是传统典型的统计方法和机器学习模型。随机森林回归模型(random forest regression,RFR)、梯度提升回归树(gradient boosting regression tree,GBRT)作为经典的集成模型,对于小样本的回归具有较强的泛化能力。为了比较不同机器学习模型在情绪评分上应用的效果,本文采用PLSR、SVR、RFR、GBRT 进行回归模型的构建与预测分析。
2.4.1 模型评价指标
本文采用均方根误差(root mean square error,RMSE)、决定系数R2来衡量模型的预测精度。均方根误差取值越小,模型的拟合性能越好。决定系数R2越接近1,因变量的方差可以被独立变量所解释的部分越多,模型的效果越好。决定系数和均方根误差的公式如式(1)、(2)所示:
式中,yi为真实预测值;ypi为模型预测值;ym为真实预测值的平均值。
在调整模型的参数时,常用的方法是交叉验证(cross validation,CV)。为了解决数据集数据量不够大的问题,本文采用留一交叉验证(least one out cross validation,loocv)计算模型的评价指标的平均结果,更好地反映模型的预测精度。
2.4.2 排列重要性
排列重要性(permutation importance,PI)是与模型无关的衡量特征重要性的有效方法[14],能够研究不同特征对模型预测结果的影响,排列重要度越高说明特征对模型预测的准确度影响越大。排列重要性的原理是改变数据集中某一个特征数据的排列顺序,其他特征保持不变,对比变化前后模型预测精度的变化大小,就认定为该特征的排列重要度。本文计算模型的PI值,绘制影响因素的排列重要性图,分析影响表现的情绪特征。
3 实验结果
在AMDRyzen74800 HCPU、RTX2060 GPU 上,基于Python3.7完成人脸情绪识别与模型构建,主要采用的算法包为Keras 2.3.1、 TensorFlow 2.2.0、 TSfresh0.18.0和Scikit-learn 0.24.2。
对44 名被试进行了面试专家评分和人脸情绪识别,评分分数分布在[75,92] ,平均分为86.3 分,方差为4.11,前200 s 内统计的情绪结果如图3 所示,其中虚线为平均值,空心圆为离群值。由图可知,面试过程中的中性情绪为学生表现的主体情绪,高兴和中性情绪表现占比超过50%。通过计算面试过程的平均情绪,其结果显示情绪为中性的占比为43.94%,其次是高兴情绪19.94%,悲伤、恐惧和愤怒情绪的占比分别为10.34%、10.43%、10.6%。本研究将惊讶和高兴定义为积极情绪,愤怒、厌恶、悲伤、恐惧定义为消极情绪。通过计算面试成绩与7 种情绪平均值的Pearson 相关系数,发现中性情绪、积极情绪和面试成绩呈现正相关,并且是显著的(P<0.01) ,愤怒、悲伤、恐惧与面试成绩呈现负相关,且也是显著的(P<0.01)。
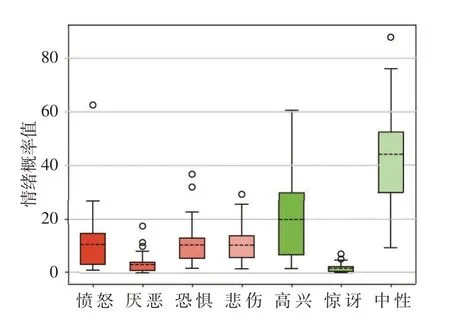
图3 7种情绪箱型图
经过特征选择确定了12个情绪特征,每个特征由不同的特征计算器函数得来。此外,在进行回归模型构建之前对12个特征计算方差膨胀因子,进行多重共线性检验,结果如下表3 所示,所有特征对应的方差膨胀因子的值在[1.00,2.00] 之间,均小于5,这表明特征选择出来的12个特征数据不存在严重多重共线性问题,如果只存在相对较为轻微的多重共线性,可保留作为模型构建的特征集。
采用支持向量回归、偏最小二乘回归、随机森林回归、梯度提升回归树以特征集作为输入,面试分数作为输出,构建回归模型。基于模型精度评价指标,对4 种回归模型进行留一验证,表4 列出了采用留一验证后的模型精度评价指标的平均值,图4是PLSR 模型拟合效果图。由验证结果可知,RFR 模型和GBRT 模型的表现相似,其拟合能力较弱,RMSE 和R2的值非常接近,SVR 模型的拟合能力和模型效果均优于RFR 模型和GBRT 模型。整体来看,PLSR 模型的拟合能力、稳定性和精度表现最好,其R2值为0.486,RMSE 值为0.172,均高于前3 个模型的预测精度。
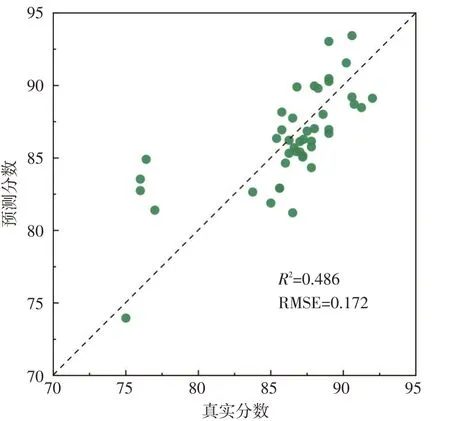
图4 PLSR模型预测效果
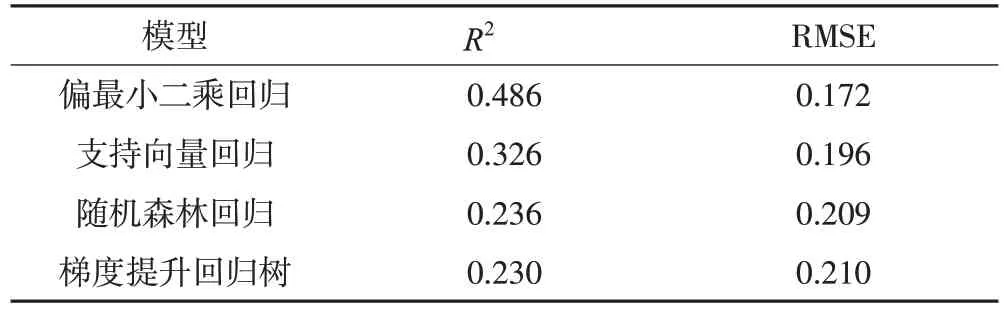
表4 模型评价指标
通过模型的训练与预测,本研究选择拟合效果更好的偏最小二乘回归模型,计算不同特征的PI并绘制影响特征的排列重要性图,如图4 所示。排列重要性可以增加对模型的解释性,特征的重要性值越大,对模型的预测结果影响越大。从图中可以看出,愤怒情绪相关特征的排列重要性最高为0.123,意味着将该特征列进行随机打乱,会使模型的预测精度下降12.3%,影响相对较大。图4中权重的正值意味着该特征对预测结果有贡献,负值则表明该特征对预测结果贡献度不大,重要性接近于0。在重要性值排名前8位的情绪特征中,比例最高的是与负面情绪相关的特征(愤怒、悲伤、恐惧、厌恶)占62.5%,其次是中性情绪相关特征占25%,最后是积极情绪相关特征(高兴)占百分之12.5%。
4 结语
根据上述分析,我们的研究发现通过分析面试视频前200 s 的表情数据,可以预测出面试成绩,可解释占比为48.6%。研究比较了PLSR、SVR、RFR 和GBRT 4种模型在成绩预测中的应用,其中PLSR模型的预测精度与稳定性高于其他模型。
特征重要性排序结果表明,占比更高的消极情绪和中性情绪对面试成绩预测准确性的影响更大。结合情绪与面试成绩的相关系数,消极情绪与面试成绩呈显著负相关,可能是因为学生在面对专家提出的问题,出现无法解答的情况下,容易呈现负面情绪的表情如焦虑,愤怒;而中性情绪与成绩呈现正相关,这体现了稳定的情绪表达更容易得到专家的肯定。
本研究对GIS 研究生面试过程中的情绪与面试成绩的关系进行了探索,研究表明受试者面部表情时间序列数据可以作为面试成绩表现的重要预测变量,特征挖掘进一步提高模型预测精度,采用深度学习分析情绪可以作为面试官打分的辅助依据。然而本文仅基于GIS 专业硕士面试数据,结果未必具有跨专业的普适性,因此在后续的研究中,我们将扩大专业范围,测试本研究的普适性以及情绪识别模型精度的优化。
