基于慢特征分析的分布式动态工业过程运行状态评价
2024-04-30钟林生常玉清王福利高世红
钟林生 常玉清 王福利,2 高世红
随着科技水平的快速发展,企业对生产过程的精细化管理提出了更高要求.如何在保证生产安全和产品质量的前提下进一步提高综合经济指标,成为企业在当今激烈竞争的市场环境中存活的关键.为实现上述目标,企业不仅要求生产过程处于正常的状态,还渴望追求过程运行在优状态[1].在企业投产初期,工程师会利用过程知识和优化技术,使得过程处于优运行状态.但是,由于外部扰动、过程参数的漂移和现场人员的不当操作等原因,过程会逐渐偏离最初设定的优运行区域[2].如果不能及时地检测出过程运行性能的退化,轻则降低企业的经济效益,重则演化为故障,威胁企业生产人员的安全.为了应对以上问题,过程运行状态评价和过程监测技术应运而生.运行状态评价是评估工业过程运行状态优劣等级的方法,其隶属于广义上的过程监测范畴,但在实现目标方面又有显著不同[3].具体而言,与传统过程监测技术仅将过程划分为正常与故障两种状态相比,运行状态评价方法进一步将正常运行的生产过程细分为多个性能等级(例如优和非优).运行状态评价可以看作是能够满足更高企业要求的扩展型过程监测方法.因此,研究及时、准确和全面的工业过程运行状态评价方法,对保障企业生产安全和提高企业综合经济指标,具有重要的理论价值和实际意义.
在过去的20 年中,运行状态评价获得了学术界和工业界的广泛关注.为了处理工业过程的多模态特性,Ye 等[4]采用高斯混合模型识别过程所处的模态,并开发了一种将优性评价指标划分为不同等级的分类方法.考虑到并非所有过程变量都会显著地影响过程的运行状态,Fan 等[5]首先采用皮尔逊相关系数选出与评价指标高度相关的变量,然后利用最小二乘支持向量机模型实现过程运行状态的划分.针对新过程训练数据不足问题,Zou 等[6]采用交叉域特征迁移算法,将旧过程的通用信息迁移到新过程中,从而提高新过程的评价模型的精度.为了同时评价过程稳定模态和过渡模态的运行状态,Liu 等[7]基于综合经济指标制定评价策略,对稳定模态通过高斯过程回归预测综合经济指标,对过渡模态采用历史数据库中相似过渡模态的综合经济指标的加权平均值作为当前过渡模态的评价指标.为了更好地处理过程数据中存在的不确定性信息,Wang 等[8]结合特征选择、即时学习和概率主成分回归,建立评价指标的预测模型,并通过概率模糊推理将多个评价指标转换为最终的评价结果.虽然文献[1-8]对过程运行状态评价进行了广泛探索并取得了巨大成就,但是上述研究成果普遍基于静态模型,忽略了过程的动态特性.当过程数据中包含动态信息时,直接将静态模型应用到动态数据是一种线性静态近似,并不能准确地揭示变量之间的关系[9].在广泛应用闭环控制的工业过程中,变量的时序相关性是普遍存在的[3].为挖掘过程数据的动态特性,学者们相继提出了典型变量分析、动态独立成分分析、动态主成分分析(Dynamic principal analysis,DPCA) 和动态慢特征分析(Dynamic slow feature analysis,DSFA)等方法[9-12].Sedghi等[13]采用动态主成分回归技术预测过渡模态的综合经济指标,改善了文献[7]的运行状态评价性能.Zou 等[14]将典型变量分析和慢特征分析(Slow feature analysis,SFA)进行分层组合,提取过程更深层次的特征,从而更加细致地刻画运行状态的等级.虽然上述方法[9-14]对一般的动态过程很有效,但是它们都是集中式模型,在应用于规模较大的工业过程时,很可能会因为忽略了过程的局部信息而降低模型评价非优状态的灵敏性.需要注意的是,上述基于分类[4-6]或回归技术[7-8,13]运行状态评价方法的应用前提是能获得足够多优状态和非优状态的训练数据.但在实际生产过程中,任意一个或多个变量发生不同程度的偏移都有可能导致过程处于非优状态.由于经济和技术条件限制,在企业投产初期,几乎不可能获得所有非优状态的完整数据集.针对非优状态模式多样但可获得的非优状态数据量相对较少的情况,用于表示优运行区域的闭合决策边界往往会比表示优与非优状态的分隔决策边界更具可靠性.以多元统计分析技术[15]和一类分类技术[16]为代表的数据描述方法为上述情况提供了很好的解决方案.
针对现代工业过程规模大、流程长和工序多的特点[17],分布式模型得到了越来越多学者们的关注.分布式建模策略是经过过程分解、子模型建立和子模型结果融合而得到,因而更适用于规模较大的工业过程[18].Liu 等[19]提出一种基于全潜结构投影模型的分布式运行状态评价方法.为了应对工业过程大数据问题,Zhu 等[20]基于MapReduce 框架,设计一种分布式并行主成分分析方法.考虑到字典学习能够有效减少高维数据的计算和存储负担,Huang等[21]提出一种基于字典学习的分布式过程监测方法.然而,上述方法[18-21]均根据过程拓扑或机理知识实现过程的分解,有可能无法将过程变量划分为概念上有意义的重叠或不相交的子块[22].此外,当面对大规模和高复杂度的工业过程时,很难保证过程知识的完备性.为了解决这个问题,近年来涌现出一些数据驱动的过程分解方法[23],即根据过程变量的统计特性将其划分为多个子块.Ge 等[24]根据主成分的不同投影方向构造子块,将原始特征空间自动地划分为若干个子特征空间.为了处理过程的非线性,Jiang 等[25]利用互信息将相似性高的变量划分为同一子块,并对每一子块建立核主成分分析模型,从而有效地挖掘出过程数据中的非线性信息和局部信息.显然,以上过程分解方法[18-21,24-25]并未充分利用过程的动态信息.为了解决该问题,Tong等[22]基于皮尔逊相关系数,提出一种动态特征选择方法,但其子块个数等于过程变量数,这在一定程度上过度强调过程的局部信息,很可能会导致模型的误报率升高.Zhong 等[26]在文献[22]基础上,采用最小冗余最大相关性(Minimal redundancy maximal relevance,mRMR)实现过程的分解,但mRMR 本质上是一种非线性特征选择方法,并不能充分利用过程数据的动态信息.
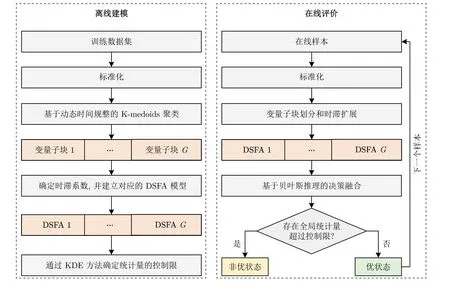
以上分析表明,充分利用动态信息的过程分解方法还需要进一步研究.此外,过程分解方法需要与相应的子模型的建模原理密切相关,才有可能显著地提高分布式评价模型的性能.以此为动机,本文提出一种分布式动态过程运行状态评价方法.首先,结合动态时间规整(Dynamic time warping,DTW)[27]和K-medoids 聚类算法[28],实现过程子块的划分;然后,针对每一变量子块建立相应的DSFA模型;最后,利用贝叶斯推理获得全局的综合评价指标,从而实现大规模工业过程的运行状态评价.为方便后续阐述,将本文方法命名为分布式动态慢特征分析(Distributed dynamic slow feature analysis,DDSFA).本文工作的主要贡献如下: 1)结合动态时间规整和K-medoids 聚类算法对过程进行分解,将波形相近的过程变量划分到相同的子块,提高了DSFA 算法对过程动/静态信息的表征能力;2)与传统动态模型为所有变量选择单一时滞系数不同的是,本文设计一种新颖的时滞系数确定方法,使得不同子块可以具有不同的时滞系数,增加了子模型的多样性.
1 预备知识
1.1 动态时间规整
动态时间规整是一种常用的度量2 个时间序列相似度方法,主要是形状相似度[27].通过对2 个时间序列进行拉伸或压缩,尽可能地消除序列在时间轴上的扭曲,从而找到序列间相似度最大的匹配路径.给定如下2 个时间序列:
式中,I和J为2 个时间序列的长度.需要注意的是,2 个时间序列的长度可以是不相等的,但2 个序列中元素的维度必须相同.为了便于理解,以下仅考虑一维时间序列.DTW 的目标是寻找一个规整路径F=[f1,f2,···,fK],使得序列a和b的累积距离最小,其中fk=(ik,jk) 表示序列a的第ik个元素与序列b的第jk个元素相匹配.通常采用欧氏距离的平方来度量2 个序列元素间的差异,即:
DTW 的优化目标函数可表示为:
为了尽可能保留序列在时间轴上的本质结构并确保能够找到最优匹配路径,在寻找规整路径过程中,还需满足以下约束条件:
1)单调连续性条件.单调连续性条件是为了保证所获得的规整路径没有跳过任何元素,也没有出现交叉情况:
2)边界条件.在规整路径F中,2 个序列的开始和结束元素必须相互匹配:
3)窗口调整条件.增加调整窗口长度条件,一是考虑到2 个时间序列在时间轴上的扭曲通常不会太大,二是为了缩短路径搜索的时间:
由式(4)~ (7)定义的优化问题可以采用动态规划算法获得最优解.d(a,b) 取值越小,代表序列a和b的相似度越大;反之亦然.
1.2 慢特征分析
慢特征分析是一种常用的降维技术,其前提假设是变化缓慢的特征比变化快速的特征更能代表数据核心信息[12].该观点已被证实与生物视觉特性一致[29].SFA 的优化目标是寻找一个映射函数使得转换后的特征的变化尽可能慢.假设存在一个m维的输入信号x(t)=[x1(t),x2(t),···,xm(t)]T,在线性情况下,慢特征s(t) 可表示为:
SFA 的优化目标函数定义如下:
式中,〈·〉t表示时间平均运算符,为慢特征sj对时间的一阶导数.需要注意的是,每个慢特征sj都被约束为零均值和单位方差,从而避免常数解.此外,不同慢特征之间的去相关,使得不同慢特征所携带的信息不同.
由式(9)的约束条件,可得:
由式(11)、式(12),可得:
与DPCA 类似,可以直接将上述SFA 算法应用于原始输入变量的时滞拓展矩阵,来获得其动态版本DSFA.时滞拓展矩阵进一步考虑了每个变量的l个滞后采样时刻,并按如下方式进行叠加[11]:
2 分布式运行状态评价方案
通过对DTW 和DSFA 方法的分析表明,DSFA算法的目标是从过程数据中提取出具有较小变化速度的潜变量,即潜变量波动尽可能平缓.显然,潜变量变化速度与其自身波形相关.反向思考,波形相近的过程变量很可能是由相同潜变量所驱动的.因而,如果将波形相近的过程变量划分到相同变量子块,则有望提高所提取潜变量的准确性.考虑到,DTW 算法尽可能消除了2 个序列间在时间轴上的扭曲,是度量2 个时间序列波形相似性的常用方法.因此,本节创新性地将DTW 和DSFA 进行组合,设计一种分布式运行状态评价方案,主要步骤包括基于DTW 和K-medoids 聚类算法的过程分解、基于DSFA 的运行评价子模型的建立和基于贝叶斯推理的子块评价结果融合.
2.1 基于DTW 和K-medoids 聚类算法的过程分解
传统的静态过程分解算法通常假定训练集中样本是独立同分布的.然而,工业过程的动态特性会导致过程变量存在时序相关性(即自相关和互相关)[30].现有过程分解算法较少考虑过程的动态特性,因此还需要进一步研究利用过程数据动态信息的过程分解算法.给定一个标准化的过程运行在优状态的训练集X=[x1,x2,···,xm]T∈Rm×n,其中xi∈R1×n.m和n分别代表变量数和样本数,则过程变量间的DTW 距离矩阵D ∈Rm×m可构造为:
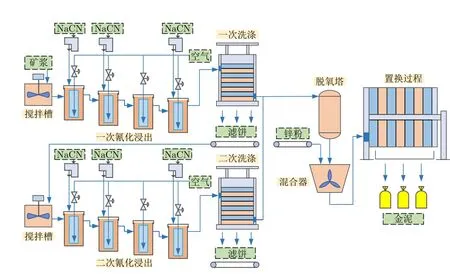
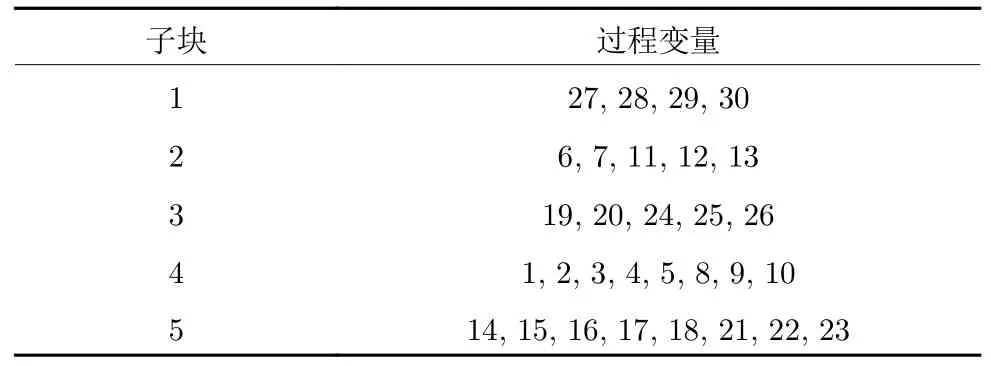
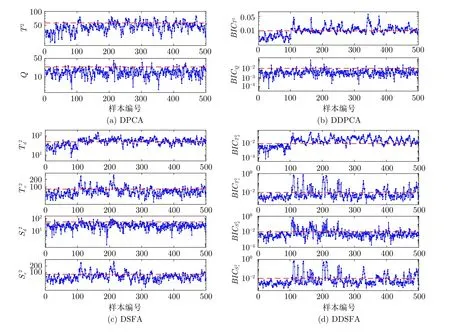
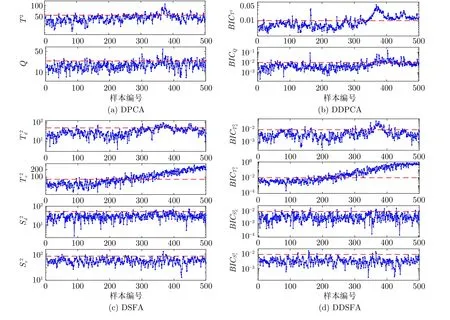
式中,Dij=d(xi,xj),表示变量xi和xj的DTW距离.考虑到,K-medoids 选取的质心是真实存在的过程变量,能有效避免虚拟质心对簇内过程变量间波形相似度的影响.基于距离矩阵D,本文采用K-medoids 聚类算法,将过程变量划分为G(G 1)从过程变量x1,x2,···,xm中随机选出G个变量作为簇的中心O1,O2,···,OG. 2)重复下面过程直到算法收敛. a) 确定变量的所属簇C={C1,C2,···,CG}.通过式(17),将每个变量分配到与簇中心的DTW距离最小的簇: b)更新簇的中心.确定所有变量所属的簇后,通过式(18)重新选择每个簇的中心.其中 card(·) 是计算集合元素个数的运算符: 第2.1 节已将过程变量划分为G个子块X=[X1,X2,···,XG]T,针对每个子块Xg ∈Rmg×n,建立其对应的DSFA 模型.动态建模方法的关键步骤是时滞系数l的确定.大部分现有的动态建模方法都为所有变量选择了相同的时滞系数.然而,这种做法一方面,人为增大了建模数据的维度[31],从而导致模型的计算复杂度增大;另一方面,规模较大的工业过程通常包含多个子工序,每个子工序都具有不同的运行机制和控制策略,因此,过程变量一般不太可能都具有相同的时滞结构[32].综合以上考虑,本文提出一种针对每个子块变量特性时滞系数lg的确定方法.由第2.1 节可知,DTW 的目标是寻找使得序列间相似度最大的匹配路径.因而,在获得变量间的DTW 距离时,还同时获得了变量间的最佳匹配路径.具体地,假设同一子块内变量xi和xj的 最佳匹配路径为Fij=[f1,f2,···,fK],其中fk=(ik,jk) 表示变量xi ∈Xg的第ik个元素与变量xj ∈Xg的第jk个元素相匹配.在实际工业过程中,过程数据通常是由等间隔采样获得.此外,训练集中不同变量的样本数相同.综合以上分析,变量xi和xj是等长的时间序列.因而,其时滞系数可以粗略估计为 |ik-jk|.但由于过程噪声的影响,而且在实际过程中,高度相似的变量相对较少.因而,仅依靠最佳匹配路径Fij中的一个元素确定2 个变量的时滞系数是不可靠的.鉴于此,本文提出一种更具一般性的时滞系数确定方法: 式中,m ode{·} 表示取众数运算符,|∆Fij|={|ikjk||(ik,jk)∈Fij},δ是一个非负整数.增加δ项,一方面,是为了更全面地提取过程数据蕴含的动/静态信息;另一方面,是为了便于在实际应用中对式(19)进行细调. 通过式(19)确定每一子块的时滞系数lg后,依据式(15)获得对应子块Xg ∈Rmg×n的时滞拓展矩阵Xg(lg)∈Rθ×N,其中,θ=mg(lg+1).利用SFA算法提取Xg(lg) 的慢特征,并根据特征的变化速度将慢特征划分为以下2 个部分: 式中,sg,d ∈Rr×N是变化较慢的特征,包含了系统的核心信息;sg,e ∈R(θ-r)×N是变化较快的特征.通过式(22)的分位数方法确定r值[12]: 式中,Qq{〈〉t} 表示集合 {〈〉t} 的q分位数.简言之,主导子空间sg,d移除了比所有原变量变化速度q分位数大的特征. 为指示主导子空间和剩余子空间中过程稳态分布p(x) 的变化,构造以下2 个统计量: 相应地,系统对过程暂态分布p() 的变化可通过以下2 个统计量指示: 给定一个标准化的在线样本xnew ∈Rm×1,根据本文的过程分解算法,可以将其划分为G个子块.每个子块对应的时滞拓展向量可表示为xnew,g(lg)∈Rmg(lg+1)×1.需要注意的是,为方便后续描述,本文采用xnew,g表示其自身的时滞拓展向量.相应地,xnew,g所对应的4 个统计量可通过下式计算: 本文采用贝叶斯推理策略[34]融合子块的局部评价结果,获得全局综合评价指标.因此,即使新的非优运行状态所影响的过程变量分布在不同的子块,也能获得相对较好的评价性能.具体地,依据统计量,在线样本子块xnew,g处于非优状态的后验概率可通过式(31)计算: 式中,os和nos分别表示优运行状态和非优运行状态.(os)和(nos)是过程处于优运行状态和非优运行状态的先验概率,可分别赋值为1-α和α.一般地,α取值为0.01 或0.05[34]. 根据贝叶斯推理融合每个子块的评价结果,全局统计量可计算为: 综上所述,本文基于DDSFA 的运行状态评价流程图如图1 所示. 图1 基于DDSFA 的运行状态评价流程图Fig.1 Flow diagram of DDSFA-based operating performance assessment 本节通过将本文的基于DDSFA 的运行状态评价方法应用于数值仿真算例和金湿法冶金过程,以验证其在工业过程运行状态评价领域的有效性.为验证分布式模型感知过程微小变化的灵敏性,将DDSFA 与集中式模型DPCA[11]和DSFA[12]进行比较.此外,为体现DDSFA 的优越性,将其与分布式模型DDPCA (Dynamic decentralized principal component analysis)[22]进行对比. 本文数值仿真算例是在文献[9] 和文献[22]基础上修改得到的.数值仿真算例中包含2 个独立的子过程.需要注意的是,虽然在实际工业过程中,较少存在像数值仿真算例这样能理想划分的系统,但该算例能直观地验证本文方法的有效性. 式中 式中,zi、ui和yi分别表示系统的状态变量、输入变量和输出变量;Ai、Bi、Ci和Di表示参数矩阵;wi和ei均为零均值单位方差的随机变量;ei的系数矩阵是为了保证yi的信噪比为1%.选择x(t)=[y1(t),···,y4(t),u1(t),···,u4(t)]T作为过程的运行状态评价变量.通过上述系统生成500 个样本作为优运行状态的训练集,同时,在过程中引入不同的扰动,使过程偏离优运行区域生成以下2 组包含500 个样本的测试数据. 案例1.从第101 个样本到第500 个样本,在w1引入幅值为2 的阶跃扰动,模拟系统的潜变量发生偏移导致的非优运行状态. 案例2.从第101 个样本到第500 个样本,将C1中的-0.393 改为-0.193,模拟过程变量的动态相关关系发生变化导致的非优运行状态. 需要注意的是,上述优运行状态和非优运行状态是人为预定义的,并不具备实际的物理意义. 首先,将训练数据进行标准化处理;然后,结合DTW和K-medoids 聚类算法将数值仿真算例划分为X1=[x1,x2,x5,x6]T和X2=[x3,x4,x7,x8]T两个子块.不失一般性,式(7)的h取值为5.可以看出,子块划分的结果与实际过程的情况完全一致.针对每个子块,通过式(19)确定其时滞系数,其中δ=1,则l1=2、l2=2.根据时滞系数将子块训练集进行时滞拓展,并构建对应的DSFA 模型.主导空间所保留的慢特征个数由式(22)确定.需要注意的是,在式(22)中,q=0.3.为保证对比的公平性,DPCA、DDPCA 和DSFA 都采用相同的时滞系数l=2.显著水平α=0.01.主成分个数根据累积方差百分比(Cumulative percentage variance,CPV)确定[35],即 C PV>0.9.由于DDPCA 包含的变量子块数等于过程变量数,且每个子块是由不同时滞系数的过程变量构成,因此本文不作展示. 4种算法在数值仿真算例中的漏报率如表1 所示.可以看出,DPCA 和DDPCA 能有效指示过程变量的均值和方差发生的明显变化,然而,几乎无法感知过程变量间动态相关关系的变化.其主要原因是DPCA 采用时滞扩展矩阵的方式,将动态信息引入到原先的静态模型中,从而实现对过程动态信息和静态信息的提取.但DPCA 的目标函数依然主要关注过程的静态特性,所提取的潜变量容易被静态信息所主导,无法保证提取出准确的动态表征.因此,DPCA 和DDPCA 感知过程动态信息变化的灵敏度相对较低.DSFA 和DDSFA 对案例2 中的非优运行状态的评价性能明显高于DPCA 和DDPCA,其主要原因是,在建模过程中DSFA 通过T2统计量和S2统计量分别对过程变量的稳态分布p(x) 和暂态分布p(x˙) 进行单独描述[12],从而有效地避免了过程动态信息的变化被静态信息所掩盖.因此,DSFA 比DPCA 和DDPCA 能更细致地描述过程数据的动态特性.需要注意的是,案例1 比案例2 所引起的变量幅值变化量大,得益于分布式建模方法更加注重过程局部信息的变化和DSFA的优良性能,DDSFA 依然获得了令人满意的评价结果.与DSFA 相比,DDSFA 获得了明显性能提升. 表1 不同算法在数值仿真算例中的漏报率(%)Table 1 Missed alarm rates of different methods in the numerical example (%) 数值仿真算例中案例1 的运行状态评价结果如图2 所示.从第101 个样本到第500 个样本,在w1中引入幅值为2 的阶跃扰动,将导致过程变量x1、x2、x5、x6的均值和方差都发生明显的变化.由于案例1 所影响的变量相对较多且变化幅值也相对较大,因而,集中式模型DPCA 和DSFA 也获得了较好的评价结果,如图2(a)和图2(c)所示.由于分布式建模方法更加注重过程局部信息的变化,与集中式模型相比,分布式模型DDPCA 和DDSFA获得了显著的性能提升,如图2(b)和图2(d)所示. 图2 数值仿真算例中,案例1 的运行状态评价结果Fig.2 The operating performance assessment result of case 1 in the numerical example 数值仿真算例中,案例2 的运行状态评价结果如图3 所示.从第101 个样本到第500 个样本,将过程参数-0.393 改为-0.193,改变了过程变量x1、x2、x5和x6的动态相关关系.由图3(a)、图3(b)可以看出,DPCA 和DDPCA 并未取得令人满意的评价结果.然而,由图3(c)、图3(d)可以看出,DSFA和DDSFA 评价模型中T2统计量和S2统计量均显著地超出了控制限.得益于本文的过程分解方法将波形相近的过程变量划分到相同的子块,提高了DDSFA 算法对过程动/静态信息的表征能力.因而,DDSFA 获得了最高的评价性能. 图3 数值仿真算例中,案例2 的运行状态评价结果Fig.3 The operating performance assessment result of case 2 in the numerical example 金湿法冶金技术是从低品位矿石中提取黄金的有效方法.从生产安全角度出发,开发的算法必须经过严格测试才能应用于实际的生产过程.虚拟仿真技术是一种有效降低算法前期测试成本和安全风险的措施.基于以上考虑,本文课题组根据金湿法冶金过程的运行机理,设计并开发了金湿法冶金过程半实物仿真平台.该平台为金湿法冶金过程的监测、运行状态评价和优化等系统的开发与验证提供软硬件基础[36-37].一个典型的金湿法冶金过程包括一次氰化浸出、一次洗涤、二次氰化浸出、二次洗涤和置换5 个核心工序,金湿法冶金过程工艺流程如图4 所示.浸出过程包含4 个自然溢流的浸出槽.向浸出槽中添加 NaCN,并充入空气,使矿浆中的固态金溶解为 [Au(CN)2]-,此过程称为一次氰化浸出.通过全自动立式压滤机,实现贵液和矿浆的分离.为了使附着在滤饼中的[Au(CN)2]-尽可能少,需要使用贫液反复冲洗滤饼,此过程称为一次洗涤.二次氰化浸出、二次洗涤与一次氰化浸出、一次洗涤类似,其作用是尽可能多地提取矿石中含有的黄金.分离出的贵液经过脱氧塔处理后,流入框板式压滤机,并通过加入锌粉置换出固态金.金湿法冶金过程的变量如表2 所示. 表2 金湿法冶金过程的变量Table 2 The variables of gold hydrometallurgy process 图4 金湿法冶金过程工艺流程图Fig.4 The flow chart of gold hydrometallurgy process 基于金湿法冶金半实物仿真平台产生500 个优运行状态的样本组成训练集.具体地,金湿法冶金过程单位时间内的综合经济指标位于[5 500,6 000](元/小时).同时,在过程中引入不同的扰动,使过程偏离优运行区域生成2 组包含500 个样本的测试数据. 案例3.从第101 个样本到第500 个样本,将矿浆浓度由0.25 改为0.26. 案例4.从第101 个样本到第500 个样本,将锌粉添加速度由0.31 线性地增加为0.33. 通过基于DTW 距离的K-medoids 聚类算法将金湿法冶金过程划分为5 个子块,金湿法冶金过程变量的子块划分结果如表3 所示,其中式(7)的h取值为5. 表3 金湿法冶金过程变量的子块划分结果Table 3 Sub-block division result of process variables of gold hydrometallurgy 通过式(19) 确定子块的时滞系数,其中δ=1,则l1=l4=l5=2,l2=l3=1.显然,本文的时滞系数确定方法根据变量子块的特性选择了不同的时滞系数,不仅降低了建模数据的维度,还增加了子模型的多样性.根据时滞系数将子块训练集进行时滞拓展,并构建对应的DSFA 模型.主导子空间所保留的慢特征个数由式(22)确定,其中q=0.3.为了保证对比的公平性,DPCA、DDPCA 和DSFA都采用相同的时滞系数l=2.显著水平α=0.01.主成分个数通过 C PV>0.9 确定. 4种算法在金湿法冶金过程中的漏报率如表4所示.可以看出,本文算法获得了最高的评价性能.与DPCA 相比,DDPCA 获得了较大性能提升.然而DDPCA 的变量子块数等于过程变量数,当过程变量数较大时,会导致模型中的冗余信息较大,从而降低了模型性能.得益于分布式建模方法更加注重过程局部信息的变化和本文的过程分解方法提高了DDSFA 对过程动/静态信息的表征能力,因而与DSFA 相比,DDSFA 性能获得了明显提升. 表4 不同算法在金湿法冶金过程中的漏报率(%)Table 4 Missed alarm rates of different methods in gold hydrometallurgy process (%) 金湿法冶金过程中,案例3 的运行状态评价结果如图5 所示.矿浆浓度的增加短期内会导致浸出槽中 CN-浓度下降.在 CN-浓度闭环控制器的作用下,会加大 NaCN 的添加流量.上述调节过程会导致溶液中 [Au(CN)2]-浓度升高,从而继续影响后续工序.综上所述,矿浆浓度变化会导致金湿法冶金过程较多的变量发生变化.因而,案例3 属于全局非优运行状态.由于矿浆浓度的变化量相对较小,集中式模型DPCA 并未取得令人满意的评价结果,如图5(a)所示.DDSFA 采用分布式建模框架,能灵敏地察觉到每一子块的数据变化,并通过贝叶斯推理算法融合每个子块的评价结果,因此获得了最高评价性能,如图5(d)所示. 图5 金湿法冶金过程中,案例3 的运行状态评价结果Fig.5 The operating performance assessment result of case 3 in gold hydrometallurgy process 金湿法冶金过程中案例4 的运行状态评价结果如图6 所示.由金湿法冶金过程工艺流程图可知,锌粉添加速度的变化只会影响置换过程.换言之,案例4 属于局部非优运行状态.由于锌粉添加速度是线性增加的,可以清楚地看到统计量的变化趋势.由图6(d) 可以看出,从第270 个样本开始,DDSFA 的统计量显著地超出了控制限,而DSFA的统计量从第330 个样本才开始显著地超出控制限.综上所述,本文DDSFA 算法对金湿法冶金过程的局部非优运行状态具有更强的感知能力. 图6 金湿法冶金过程中,案例4 的运行状态评价结果Fig.6 The operating performance assessment result of case 4 in gold hydrometallurgy process 为充分挖掘大规模工业过程的动态信息和局部信息,本文提出一种基于慢特征分析的分布式动态工业过程运行状态评价方法.首先,结合DTW 和K-medoids 聚类算法实现过程变量子块的划分,一是减少了对过程机理知识的依赖,二是充分利用了过程数据的动/静态信息;然后,在建立子模型阶段,与传统动态建模方法对所有过程变量选择单一的时滞系数不同的是,本文设计一种新颖的时滞系数确定方法,在降低模型的计算复杂度的同时,增加了子模型的多样性;最后,利用贝叶斯推理融合子块的评价结果,简化了触发非优运行状态报警的最终决策.将本文方法应用于数值仿真案例和金湿法冶金过程,仿真对比结果表明,该方法具有一定的优越性.然而,本文方法主要面向线性动态工业过程,如何将其扩展到非线性动态过程或非平稳过程,值得进一步研究.2.2 基于DSFA 的运行状态评价子模型的建立
2.3 基于贝叶斯推理的子块评价结果融合
3 仿真验证
3.1 数值仿真算例



3.2 金湿法冶金过程


4 结束语
