基于输出不一致测度的水文预报缺失数据流关联修复方法
2024-04-29苑艺琳
苑艺琳
(河北省石家庄水文勘测研究中心,河北 石家庄 050000)
水文预报需要对水域的实时状况进行全面、具体、长期的持续监测,因此水文数据是水文工作中非常重要的因素,然而由于数据量过大、网络事故、人为因素、硬件设施缺陷等问题,水文数据缺失错漏问题频发。水文预报数据关乎整个系统的安全与稳定,因此对水文预报缺失数据进行补足修复是当前研究的重点。然后,无论是采用经典Nyquist奈奎斯特采样或是压缩感知的采样方式,时常会因为传感器、传输设备、转换设备等故障造成部分采集谐波信号丢失的问题,或是在通信通道,如电力线载波,传播过程中由于信道的干扰导致数据丢失的现象。文献[1]基于DEM算法建立分布式水文模型,根据空间分布进行驱动水文数据修正,但该方法对误差控制精准度不高。文献[2]采用生成对抗网络和记忆网络相结合的方式结合构建耦合模型,生成与缺失数据分布相一致的数据特征实现填充,但该方法的填充效果受水文监测数据周期限制较大。
本文针对传统方法的不足,提出了一种基于输出不一致测度的水文预报缺失数据流关联修复方法,通过输出不一致测度提取特征矩阵,选用FSOM模糊聚类算法进行分层聚类,优化聚类收敛度,再映射回原始数据中完成缺失数据填补修复,并通过实例分析验证该方法的修复效果。
1 水文预报缺失数据多维映射
对水文预报缺失数据进行分析填补,首先需要监测采集各项水文特征数据,采集到的原始的数据信息为单一维度信号,通过分类整理将相关联的单一维度信号映射到多维灰度图中[3-4]。映射模式如图1所示。

图1 映射模式
多维映射从单一维度信息中进行单一采样,采样相邻数据设为6~10个,从数据之间的相关关系出发选择多维映射策略,既要保留原始单一维度信号的特征属性,又要在聚类解析过程中能够根据数据特征和相关关系实现缺失数据修复聚类。根据水文预报数据分布规律,探索多维映射横向和纵向的相关性规律。数据截断如图2所示。

图2 数据截断
对水文预报缺失数据进行捕获,将水文预报数据进行整合,分析捕获缺失数据位置,构建训练模型,对原始数据进行训练,提取数据特征[5-6]。通过判别器鉴别数据特征分布是否与原始数据分布相一致,如果结果总体一致则可以进行缺失数据填补工作。
训练模型主要包括生成板块和判别板块,将水文预报原始数据集输入到生成板块中进行映射,映射得到的多维灰度图如图3所示。
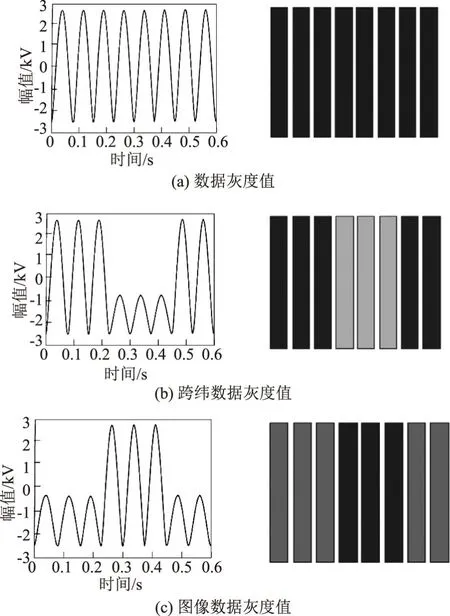
图3 多维灰度图

(1)
通过训练模型对水文数据的复位数值R和趋向数值Z进行计算,引入多元序列的缺失变量θ,对水文预报缺失数据的隐藏单元进行控制:
R(x)=δ(Wrxn+Vrxn-1+θ)Z(x)=δ(Wzxn+Vzxn-1+θ)
(2)
式中,δ—生成板块引入的各单元之间的权重;W、V—模型各部分的复位参数和学习参数。通过数据映射得到灰度检测结果,能够分析缺失数据分布状态,通过对缺失数据的隐藏单元进行控制,为后续修复数据结果的导入提供支持。
2 基于输出不一致测度的数据预处理
输出不一致测度是根据分类器的输出标签进行度量的,对分类器fn和fm,设其输出结果为0或1。用Dif(fnk,fmk)表示两个分类器输出的差异,当这两个分类器对第k个样本的输出相同时,Dif(fnk,fmk)=0,否则等于1。此测度可由下式进行计算:
(3)
式中,Diversitm,n与分类器fn和fm之间的相异度成正比。以上测度是基于分类器输出结果的相异性来衡量的[7-8]。

(4)
显然,Diversit是个对角线为0的对称矩阵,用select,表示第i个极限学习机与其它所有极限学习机的相异性[9-10],表达式为:
(5)
基于水文数据的相异性结果可以揭示不同地理区域的水文特征和差异。通过比较不同水文站点的数据,可以了解不同地方的降水分布、径流情况以及水文循环过程的差异[11-12]。因此基于水文数据相异性输出结果提取出水文特征规律,以便真实地反应水文数据的基本属性。整合水文特征数据矩阵表达为:
(6)
式中,X—建立的水文数据矩阵;n—采集到的数据特征数量;xn—不同特征值对应的特征向量[13-14]。
3 基于FSOM神经网络的水文预报缺失数据修复
根据上述得到的水文特征数据矩阵,对水文预报数据进行聚类处理。通过聚类分层将所有水文特征数据聚类到对应层次,每一层整合为一个数据集。根据数据神经节点数量和隶属矩阵约束条件,将对应层次数据输入到运算程序中,再对最后得到的聚类效果进行优化,实现对水文预报确实数据的修复工作。
3.1 水文数据聚类
通过竞争学习原则对目标函数进行优化,进一步解决FSOM神经网络算法不收敛的缺陷。以拉格朗日乘数法优化聚类算法的目标函数,根据矩阵的递减顺序进行迭代,引入水文数据与聚类矩阵之间的隶属矩阵作为约束条件:
(7)
式中,e—聚类过程中产生的模糊指数;Uin—聚类过程的隶属度,满足该隶属关系的条件下进行聚类优化,随着迭代次数呈现不同的波动趋势,在拐点处能够取得相应的最小值,此时的聚类算法具有良好的收敛性[15]。通过计算会得到多个相对最佳的聚类数据特征值,而聚类结果数量的大小与合理性将直接影响水文预报数据的修复效果,因此需要设定聚类评价指标对聚类效果进行评价,防止聚类过程中出现主观性选择。
分析水文预报数据的分布状态,取每个数据集中的最大值与最小值进行观察评估,其变化情况能够直观反映整个聚类算法的运算效果。如果数据变化的波动不大,则说明聚类效果达到一个比较稳定的状态,数据集之间保持良好的相关关系;如果数据波动变化仍然较大,则说明聚类效果不稳定,需要再次进行约束,直至达到较好的收敛度。
3.2 基于聚类矩阵的水文数据修复
根据水文预报数据的特征矩阵和聚类运算结果,对多维映射后的水文预报缺失数据进行数据修复。基于前文所述的聚类分层策略,对每一层的数据特征矩阵进行搜索检查,查找缺失数据的序列位置和分层位置,确定缺失数据位置后,在其所在聚类层次中按以下公式进行修复:
(8)
式中,α—缺失数据修复数值;a、b—缺失数据所在空间序列位置;z—缺失数据所在聚类层次;v—所在层次的可用数据量。对修复后的数据进行融合运算,更新聚类层级中的权重数值,对缺失数据进行加权运算,得到单一维度映射层更准确更贴切的修复数据。完成上述计算后,将修复数据结果导入对应的多维映射层,按照多维映射规律将数据结果映射到单一维度映射层中,填补原来缺失数据位置,实现水文预报缺失数据修复。
为了尽量减少映射误差,应对数据平均绝对误差、平均方根误差以及信噪比等因素进行计算,针对各个采样数据点修复结果进行降噪优化。对于水文预报中出现数据连续丢失或随机丢失的情况,可以在矩阵优化中引入时间动态分析对矩阵进行分解,通过多元素分解回归来适应数据修复,目标函数如下:
(9)

4 实例分析
4.1 参数设置
为了验证本文提出的基于输出不一致测度的水文预报缺失数据修复方法的实际应用效果,进行实例分析。在水资源信息中心中抽取部分水文观测数据。该数据集应包含多个水文站点的观测数据,同时存在一定比例的缺失数据。将数据集划分为训练集和测试集。训练集用于模型的训练和参数调整,而测试集用于评估修复方法的实际应用效果。并将修复率最为实例分析指标进行实验测试,表达式为:
R=(F/T)×100%
(10)
式中,F—已修复数据数量;T—总缺失数据数量。
4.2 分析结果
基于上述环境设置,分别针对水文数据出现短暂地升高和降低时出现的异常进行检测,通过修复判断缺失数据。随机缺失数据修复效果如图4所示。

图4 随机缺失数据修复效果
根据图4可知,本文提出的修复方法在面对随机缺失数据时,有极好的修复效果,能够精准地检测出随机缺失的数据所处位置,根据周边数据信息完成数据修复。
根据图4修复结果,得到本文提出的修复方法随机数据修复率实验结果见表1。

表1 随机缺失数据修复率实验结果
根据表1可知,随着数据量的增加,本文提出的修复方法修复率出现了下降,但是下降程度较小,在数据、图像数据和跨纬数据上,本文提出的修复方法都展现出极好的修复效果,当数据量在500GB时,修复率仍然能够达到97.28%以上。
观察图5可知,在面对连续缺失数据时,本文提出的修复方法也能展示出较好的修复效果,通过FSOM神经网络进行数据映射,根据映射结果实现数据修复。

图5 连续缺失数据修复效果
根据上图的修复效果,得到本文提出的修复方法连续数据修复率实验结果见表2。

表2 连续缺失数据修复率实验结果
观察表2可知,与随机缺失数据相比,本文提出的方法连续数据修复效果相对较差,但是修复率仍然在97%以上,能够为水文相关工作提供较好的支持。
5 结语
水文预报需要对水域的实时状况进行全面、具体、长期的持续监测,因此水文数据是水文工作中非常重要的因素,然而由于数据量过大、网络事故、人为因素、硬件设施缺陷等问题,水文数据缺失错漏问题频发。为此,本文基于输出不一致测度对水文预报缺失数据修复进行了研究分析。实例分析表明,所提方法进行随机缺失数据修复后,修复率能够达到97.28%以上。进行连续缺失数据修复后,修复率在97%以上,表明所提方法具有良好的修复效果,能够为水文预报工作提供有效帮助。
