压气机叶片一次加工合格率预测
2024-04-27童一飞胡骥川
张 旭,童一飞,胡骥川
(1.中国航发南方工业有限公司,湖南株洲 412002;2.南京理工大学机械工程学院,江苏南京 210094)
0 引言
压气机叶片通常用于航空、能源等领域的气体压缩设备中,也应用于农业装备中,以提高零部件的加工效率和质量[1],提高整机的可靠性和耐用性。作为航空发动机的核心部件,叶片的质量很大程度上决定了发动机的性能,因此压气机叶片的质量尤为重要。一次加工合格指的是压气机叶片柔性加工单元完成对叶片的加工之后未经过返工返修,第一次检验就能合格的压气机叶片。而一次加工合格率指的是一次加工合格的压气机叶片占加工单元产出的比率。本文以F型号叶片为例,对压气机叶片柔性加工单元所产出叶片的一次加工合格率进行预测,根据预测结果采取相应的预防性措施,减小压气机叶片加工单元产出叶片的品质出现重大问题的概率。
目前,产品质量合格率预测方法主要分为传统质量预测方法和人工智能方法2个大类。传统的质量预测方法主要是基于统计过程控制的方法,人工智能方法的典型代表则是用神经网络预测产品合格率。
在人工智能方法预测产品合格率预测方面,Apriori算法和FP-Growth算法是2种关联性规则分析的经典算法。为了解决Apriori算法运行效率不高的缺点,Toivonen H[2]探究得出以采样思想算法为基础,分析和阐述数据之间的关联性规则,从而实现算法运行的并行化。而FP-Growth算法的缺陷是对数据结构的要求很高,Han J等人[3]针对FP-Growth算法对数据结构的要求很高的缺陷,构造FP-tree树,运用分治思想挖掘FP-tree,从而提高算法的运行效率。
王辰宇[4]运用BP神经网络模型进行焊点空洞率失效预测,但碍于缺少约束条件,该方法难以应用于不同环境条件下的空洞率失效预测。针对AFM模型自学习能力不强的问题,张永峰等人[5]融合PID算法与BP神经网络,使得系统具有更强鲁棒性,在此基础上进行质量控制仿真实验,验证了改进后的BP神经网络的可行性。由于BP神经网络模型存在求解过程中收敛速度慢和易陷于局部最优解的缺点[6],王晔等[7]运用人工鱼群算法优化BP神经网络,检验后得出了改进后的算法能使BP神经网络不陷入局部的最优解。然而基于人工鱼群改进的BP神经网络一般适用于数据样本充足的情况,导致该方法难以被多品种小批量生产采用。王星辰等[8]利用CS-BP技术来改进巡检机器人的位移补偿能力。
1 基于粒子群算法改进的BP神经网络预测模型
1.1 粒子群算法
粒子群算法要实现对最优解的搜索,首先需要在空间解中随机生成一组粒子群作为初始种群,每个粒子都可以视为目标问题模型的一个可行解,之后通过适应度函数计算出相应的适应度的值进而判断是否为最优解。粒子群中每一个粒子都由一个矢量来控制该粒子在空间解中的位移方向。粒子群算法对粒子进行初始化之后经过多次迭代得出最优解。
1.2 粒子群算法改进BP神经网络
传统BP神经网络在搜寻最优解的过程中容易陷入局部最优解,这就对预测精度产生了较大的影响。PSO无需梯度信息,可调参数少,仅通过不断更新粒子的速度和位置来不断搜寻到全局最优解,在粒子群算法参数选择合适的情况下,该算法全局搜索性能较好。本文采用粒子群算法对传统BP神经网络进行优化,以此来降低BP神经网络陷入局部最优解的可能性,提高预测的精度。
BP神经网络权值和阈值可以通过粒子群算法来进行优化。BP神经网络的全部权值和阈值组成粒子群算法中的单个粒子,群体极值决定粒子的选择。个体极值和群体极值根据适应度值不断迭代,得到最优群体极值对应的粒子,而后适应度最好的个体的值作为相应的BP神经网络的连接权值和阈值。因此,用优化后的BP神经网络进行预测可以得到更精确的预测值。算法具体过程如图1所示。

图1 基于粒子群算法改进的BP神经网络预测模型
1)初始化参数,包括种群规模、迭代次数、学习因子以及位置和速度取值的范围,粒子和速度初始化对粒子位置和粒子速度随机赋值。
2)根据时间序列的输入输出的参数数量建立BP神经网络的结构,随机生成一个种群粒子Wi=(Wi1,Wi2,…,Wis)T,i=1,2,…,n,代表BP神经网络的初始值。
3)确定适应度函数。给定一个BP神经网络进化参数,将上一步中的Wi粒子对BP神经网络权值和阈值进行赋值,输入训练样本进行神经网络的训练,达到设定的精度得到一个网络训练输出值,则种群W中个体Wi的适应度值fiti得计算公式如式(1)所示。
式中,yj为第i个节点的训练期望输出值;
M为种群规模。
4)寻找初始值。根据上步中定义适应度函数,计算每个初始粒子的适应度值。然后在通过适应度值求出粒子的初始个体极值和群体极值,并将每一个粒子的最好位置作为其历史最佳位置。
5)粒子位置和速度更新迭代。在每一次循环迭代中,把个体极值和群体极值代入式(1)和式(2),可以得到更新的粒子速度和粒子位置。
6)个体极值和群体极值更新。在步骤(5)中得到了粒子新的位置和速度,因此可以计算出新的粒子适应度值。个体极值和群体极值通过新的粒子适应度进行更新。
7)神经网络赋值预测。满足最大迭代次数后,将粒子群算法得到的最优粒子对BP神经网络权值和阈值进行赋值,并用优化的BP神经网络对压气机叶片合格率时间序列进行预测。
1.3 粒子群算法的参数选择
本小节对粒子群算法的参数包括种群规模M,粒子维度D,权重因子权重ω,学习因子C1和C2,最大速度Vmax,最大迭代次数Tmax进行选择。
1)种群规模M。种群规模M就是整个粒子群中粒子的数量。当选取的粒子数过少时,粒子群算法的求解速度较快,但是由于粒子数少导致搜索空间较小,陷入局部极小值的概率较大。当选取的粒子数过多时,粒子群算法的求解速度较慢,由于粒子数多所以搜索空间较大,陷入局部最优解的概率较小,发现全局最优解的概率较大。通常情况下选取20—40个粒子数量作为种群规模M的值,一些特殊问题可能要选取100~200个粒子数的种群规模。针对Y型号压气机叶片合格率的预测问题,本文选取40个粒子数作为种群规模,保证整个粒子群算法有足够的搜索空间不易陷入局部最优解,同时运行速度也不至于运行速度过慢。
2)粒子维度D。粒子维度D是目标问题的解空间的维度。本文用粒子群算法对BP神经网络的权值和阈值进行优化,所以本文粒子维度D的取值由预测压气机叶片合格率的BP神经网络的结构决定。粒子维度D的计算如式所示,其中R表示BP神经网络输入层节点数,S1表示隐藏层节点数,S2表示输出层节点数。
3)粒子最大速度Vmax。粒子群中的一个粒子在搜索空间中进行一次移动的最大距离就是这个粒子最大速度Vmax。粒子最大速度选择如果过快,那么粒子会在较远处进行最优解的搜索,忽略近处的解从而可能错过最优值,削弱整个粒子群算法的局部搜索能力。如果粒子最大速度选择过慢则容易陷入局部最优解。本文的粒子最大速度选择0.5,此时粒子群算法既可以有不错的局部搜索能力又可以陷入局部极小值。
4)权重因子ω。权重因子ω的作用是平衡粒子群算法粒子的全局搜索能力和局部搜索能力,因此权重因的取值也会影响粒子群算法对最优解的搜寻。权重因子太大,这种情况下粒子群算法陷入局部极小值的概率较低,但是粒子群整体的收敛性不足。权重因子太小,粒子群算法的收敛性满足要求,但是同时也增加了算法陷入局部最优解的概率。本文权重因子ω的值选用0.6,在粒子群算法不易陷入局部极小值的情况下,同时算法的收敛能力也较强。
5)学习因子C1和C2。学子因子表征了粒子群中的粒子移动至个体极值和群体极值所在位置上的加速常数。学习因子C1和C2分别表现出粒子的自生认知能力和社会群体能力。C1表示单个粒子自身认知能力对搜索环境的思考与判断,C2表示粒子群中的粒子之间信息的相互传递与共享。C1和C2的取值同样会影响粒子群算法整体对最优解的搜索能力。学习因子的取值如果过小,这种情况下限制了粒子在目标区域的搜索范围。学习因子取值过大时,粒子群中的粒子则会超出目标区域的搜索范围。通常学习因子C1和C2的取值为C1=C2=2,这种情况下粒子群中的粒子对于目标区域的搜索效率较高。
6)最大迭代次数Tmax。粒子群算法中,粒子的进行位置和速度更新的最大次数就是粒子群算法的最大迭代次数。当达到最大迭代次数后,粒子群算法停止运行,当前粒子群的最优群体极值就是目标问题的全局最优解。最大迭代次数选择太大则会增加粒子群算法的运行时间,导致粒子群算法的运行效率较低。而最大迭代次数选择太小,尽管运行时间缩短了,但是粒子群中的粒子迭代次数不足会导致粒子群算法所得的解不是最优解。本文的最大迭代次数Tmax取100,在算法求得的最优解较好的情况下,粒子群算法的整体运行效率也较好。
2 示例
使用Matlab2021a软件建立PSO-BP压气机叶片合格率的预测模型。
2.1 BP神经网络部分
经过多次实验对BP神经网络进行了调试,当输入层节点个数为20,输出层节点个数为1,隐含层为双层结构且节点个数为15,隐含层激活函数选sigmiod,输出层激活函数选purelin,训练次数取100,训练目标为1.00e-06,学习率取0.1时,BP神经网络的预测结果误差值最小。BP神经网络各参数如表1所示。

表1 BP神经网络参数
2.2 粒子群算法部分
粒子群相关参数的取值如表2所示,其中粒子维度根据式(2)计算可知。
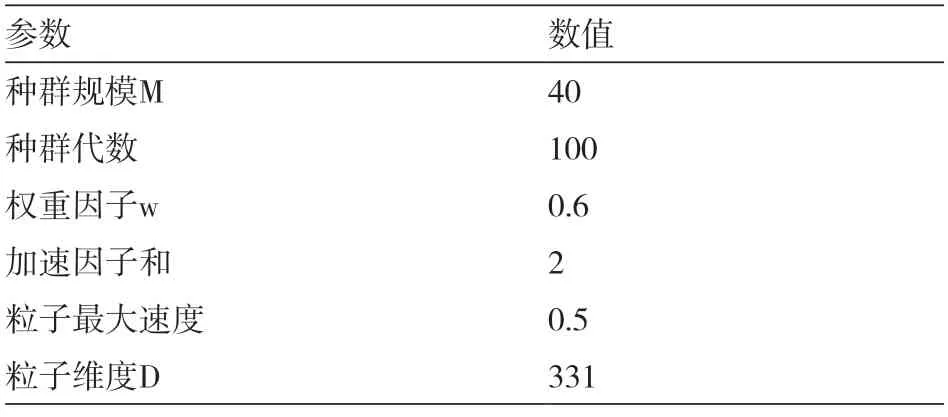
表2 粒子群算法参数
本文选取N企业2021年一年365天压气机叶片柔性加工单元所产出的F型号的一次加工合格率,经相空间重构(嵌入维数m=5和时间延迟)后的360个样本作为训练样本,由于所获取的一次加工合格率数据为2021年12个月每天的一次加工合格率数据,因此留出一个月30天的样本作为预测输出样本,剩下的330个一次合格率数据作为训练样本。F型号压气机叶片合格率PSO-BP预测模型的运行结果如图2~图4所示。

图2 实际值与预测值验证对比
如图2所示,预测值在实际值附近小幅度波动,该波动在误差的允许范围之内,表明用PSO-BP预测模型对于压气机叶片的一次加工合格率的预测具有良好的预测效果。
决定系数(又称拟合优度)R2越接近1,说明拟合效果越好,如图3所示,决定系数R2为0.9243,属于一个较高的值,说明PSO-BP预测模型的拟合效果较好。

图3 散点拟合图
如图4所示,PSO-BP预测模型输出的30个预测值与实际值对比,最大的误差百分比为1.24%,平均误差百分比为0.24%,对于压气机叶片的一次加工合格率的预测来说,达到了一个较为精确的值。预测误差在1%以内视为预测成功,则PSO-BP预测模型的预测准确度到达了96.67%。

图4 误差百分比
3 结论
通过粒子群算法改进的BP神经网络预测模型对于压气机叶片的一次加工合格率的预测具有较好的预测效果,可以为压气机叶片的质量控制与决策提供依据和参考。
