基于数据挖掘的网络信息可视化模型研究
2024-04-27王晓静陈玉英
王晓静 陈玉英
摘要:在网络信息系统中,随着信息量的不断增大,传统的信息可视化技术难以有效表达大量网络数据的内在规律,为此,将数据挖掘技术引入到网络信息可视化的研究中,构建了基于数据挖掘的网络信息可视化模型。该模型利用网络信息的特点,以网络信息为研究对象,利用数据挖掘技术,在不影响网络信息可视化效果的前提下,有效地发现网络中隐含的知识,从而为更好地服务于用户提供支持。本文提出了一种基于数据挖掘技术的网络信息可视化模型,为网络信息可视化技术的研究提供了新的思路,同时也为数据挖掘技术在网络信息系统中的应用提供了支持。
关键词:数据挖掘;网络信息;可视化模型
引言
随着信息化时代的到来,网络信息系统已经成为人类获取知识和知识共享的重要工具。在网络信息系统中,人们可以方便地获取各类信息,并可以对信息进行查询、分类、统计和分析。但是,由于网络数据具有动态变化性、半结构化和不完全性的特点,如何有效地提取并展示这些数据的内在规律,成为亟待解决的问题。因此,如何将计算机中的大量数据转化为用户容易理解和接受的形式,便于用户浏览和查询,是目前网络信息系统中的研究重点。数据挖掘技术应运而生,它为解决以上问题提供了新的思路。
1. 数据挖掘技术
数据挖掘(data mining,DM)是从大量数据中提取隐藏的有价值信息的过程,是对数据进行分析的过程。数据挖掘可以理解为从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的,但又是潜在有用的信息和知识,挖掘过程可以分为四个步骤:数据准备、特征提取、模式发现、知识发现。
(1)数据准备:对要处理和分析的数据进行预处理,使之一定程度上适合于数据挖掘。
(2)特征提取:对原始数据进行变换和转换,去除其中的噪声,如对缺失值进行填充、异常值处理等。
(3)模式发现:对转换后的数据进行分析,从不同角度挖掘出隐含在其中有意义的信息和知识。
(4)知识发现:通过对挖掘出来的信息和知识进行评价、检验,以决定是否将其应用到决策支持系统中。
数据挖掘技术在企业信息化建设中发挥着越来越重要的作用,已经成为企业信息化建设中的重要技术之一,能够帮助企业从海量数据中提取隐藏在其中的有价值的信息和知识,从而为企业作出正确决策提供参考和依据[1]。
由于网络数据的多样性、复杂性和多变性,对网络信息的处理和挖掘工作具有一定的难度。如何对网络数据进行有效的处理和分析,使其为企业的决策服务,是目前企业信息化建设中的热点问题之一,而网络信息的可视化能够在一定程度上帮助用户理解和分析网络信息,因此具有很强的应用价值。
2. 网络信息及其特点
网络信息是指在一定时间、地点、用户及信息载体的条件下,存在于互联网上的各种形式的信息。随着计算机和网络技术的飞速发展,网络已成为人们获取信息的主要来源,并成为信息处理和共享的重要场所,在人们获取和传递信息的过程中发挥着越来越重要的作用。目前,人们不仅要从网络上获得大量的信息资源,而且要根据自己的需求选择合适的信息源。
在网络环境下,人们对于网络信息资源的要求不仅是获得现有的知识,而且希望对未知知识进行预测、发现、探索和决策。因此,如何从大量数据中提取出有用的知识或模式,以帮助用户更好地理解数据中的内在规律并指导决策,成为当前研究工作的重点之一[2]。目前,网络数据具有以下几个方面特点。
2.1 网络数据的多样性、复杂性和多变性
网络数据来源于互联网上的各种信息资源,包括文字、图片、音频、视频和数据库等,其来源和形式多样。由于不同的网络用户所关注的信息领域不同,其获取信息的手段也不一样,因此网络数据具有多样性。同时,由于互联网是一个开放性的虚拟环境,所以在互联网上产生的数据不仅包括网页和网页之间的链接数据,还包括网络上的各种媒体资源。因此,网络数据具有复杂性。由于互联网上信息资源的发布与获取是无中心化的,网络上每天都会产生大量数据,而这些数据在不同时间和不同地点所呈现出来的特征也不一样。
2.2 网络数据具有开放性和自治性
由于网络世界中存在着许多具有独立地位的信息资源,各资源之间往往难以直接联系,而且不同资源间还存在着许多不对称性,因此,用户往往需要通过一定的途径来获取所需信息。而网络数据正是这些资源之一,因此具有很强的开放性。随着网络技术的发展,网络上的信息资源种类越来越多,数量也越来越大,用户可以根据自己的需要从网络中获取所需的信息资源。同时,由于网络具有很强的自治性,用户可以根据自己的需求自主地选择所需要的信息,从而使用户在获取信息时能够获得更大的自主性。此外,由于网络数据来源众多、内容繁杂,因此,对于用户来说,如何选择合适的信息源获取所需信息是一个非常复杂和困难的问題。在这方面,已有多种技术来帮助用户选择合适的信息源,如搜索引擎、Web结构化查询语言以及各种个性化服务等。
2.3 网络数据具有很强的动态性
网络中每天都会产生大量的信息,这些信息不是静止不变的,而是不断更新、不断变化的。如果不能及时对这些信息进行处理,用户就难以真正地了解网络数据。因此,用户要想获得信息就必须对其进行跟踪、管理和维护,否则这些信息就会被遗忘或者遗弃,从而影响用户的使用效果。由于网络中的资源分布极不均衡,即使是同一台计算机也有可能访问不同的资源,这就给用户提供了很大的选择余地。由于不同来源的网络数据往往具有不同的格式、结构和内容,而且用户所处的环境和所要访问的网络资源也不尽相同,往往会给用户带来很大的困难。因此,如何解决这些问题就成为用户使用网络资源的关键。为了提高网络数据的利用率,除了对数据进行必要的加工外,还需要对数据进行分类、过滤和主题跟踪,以避免无效信息和冗余信息的出现,从而提高网络数据的利用率。
3. 网络信息可视化研究
随着互联网的快速发展,网络信息越来越丰富。为了方便用户使用,需要对网络信息进行组织与管理。利用网络信息可视化技术,将庞大的网络信息以直观、易理解的形式表达出来,使用户能够迅速了解其中蕴含的信息。网络信息可视化包括网络信息的可视化建模、可视化数据的处理与可视化结果的输出。首先是对网络信息进行分析,对其进行抽象、提取、描述等处理,将其转化为可视化的对象,即网络信息可视化建模;其次进行可视化数据处理,即提取其中的隐含知识;最后是将得到的可视化结果输出,如网络地图、网络拓扑图等。
网络信息的可视化,本质上是一种数据处理技术,利用该技术对网络数据进行处理,得到可视化的信息。网络信息的可视化不仅可以直观地表现出网络信息的内容,而且可以根据用户需求,将复杂的网络数据以图形、图像等直观形式展现出来。因此,将数据挖掘技术应用于网络信息的可视化处理,可以有效地提高可视化结果的质量与效率。
4. 基于数据挖掘的网络信息可视化研究
在网络环境下,由于网络信息具有海量性、多样性、复杂性和动态性等特点,致使传统的信息管理方法无法有效地对其进行管理和分析,尤其是进行有效的可视化管理。而数据挖掘技术可以从大量的网络信息资源中挖掘出有用的知识和模式,实现对网络信息资源的有效分析,有利于用户通过可视化界面获取有关知识或进行决策分析。本文采用数据挖掘技术中的关联规则挖掘算法对网络信息资源进行挖掘,并采用可视化方法对挖掘出的结果进行分析和展示,以便用户更好地理解和使用网络信息资源[3]。
5. 网络信息可视化分析模型的设计与实现
本文从网络信息资源的特点出发,以可视化分析为基础,针对网络信息资源中存在的大量重复、无序、模糊等问题,利用数据挖掘技术从大量网络信息资源中挖掘出有用的知识和模式,并根据用户的需要进行网络信息可视化分析。
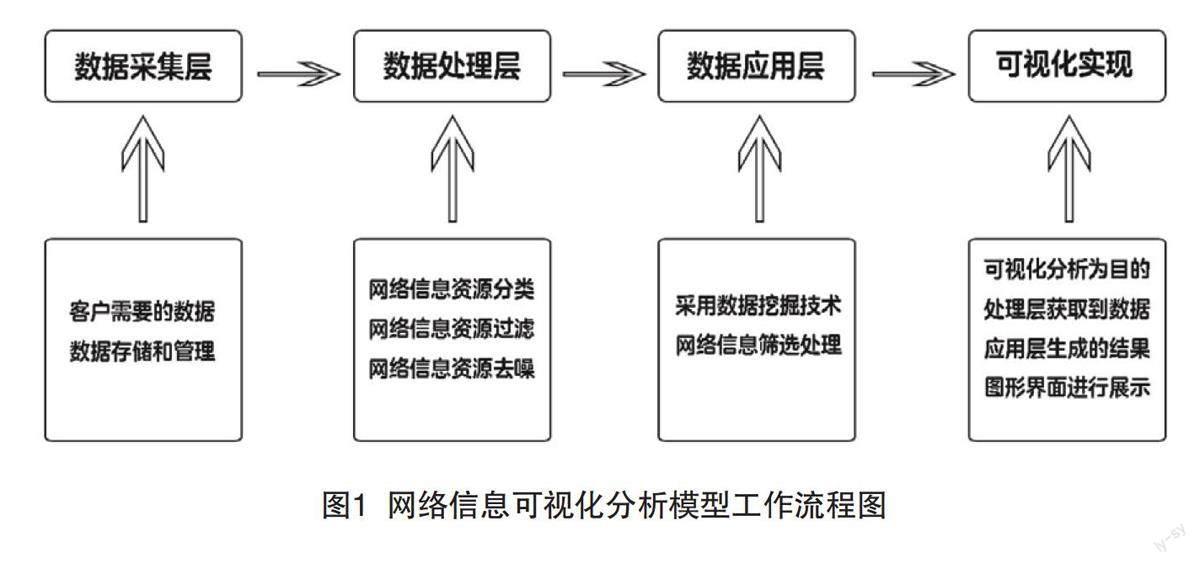
网络信息可视化模型以网络信息资源为数据源,以网络信息资源可视化分析为目标,构建一个多层次、多角度的可视化模型。模型由数据采集层、数据处理层、数据应用层和可视化实现四个部分组成。该模型的工作流程如图1所示。
5.1 数据采集层
数据采集层的主要功能是从网络中采集到需要的数据,并对这些数据进行存储和管理。网络信息资源是指由计算机技术、通信技术和信息处理技术等组成的一个庞大的网络环境,其主要表现形式是各种形式的信息资源,如文字、图片、视频等。对于这些不同类型的信息资源,需要根据不同的采集目的、采集方式和数据特征等选择不同的采集手段。数据采集层通常使用以下两种方式来实现数据采集:一是人工采集,即由相关人员对网络信息资源进行人工抽取,并将抽取到的数据存入数据库中。这种方式比较简单,但人工抽取时不能保证所抽取到的所有数据都是完整的,而且在处理过程中会出现一些错误和疏漏,另外,人工抽取出来的数据通常不具备可挖掘性。二是自动化采集,即利用网络信息资源库中已经存在的信息资源来代替人工从网络中提取数据。
5.2 数据处理层
数据处理层是基于数据挖掘的网络信息资源可视化分析模型的核心部分,接收数据采集层传来的数据,对采集到的数据进行预处理。在该模型中,预处理过程主要是对网络信息资源进行分类、过滤和去噪处理,以提高网络信息资源的质量,并为数据应用层提供了基础。
對于非结构化数据源,首先需要对其进行清洗,包括数据的分割、格式化和去噪等操作。分割是指将原始数据根据一定规则进行切割处理,使其符合一定的格式;格式化是指对数据源进行相应的格式化处理;去噪则是利用一定技术方法去除原始数据中不需要的信息。其次,需要将其转换为结构化格式,然后再进行进一步处理。在该模型中采用了SQL Server作为数据库存储系统。在转换过程中采用了SQL语言来编写程序,实现数据库与Web服务器之间的通信。
5.3 数据应用层
在网络信息资源可视化分析模型的数据应用层,主要实现用户通过Web浏览器获取网络信息资源可视化分析结果的功能。Web浏览器是一个面向对象的程序,具有良好的交互性和可重用性。在Web浏览器中,用户只需要输入简单的HTML代码就可以获得一个可视化分析结果,而且可以方便地对数据进行删除、复制和粘贴等操作。在Web服务器端,采用Java语言进行开发,采用PHP作为开发语言。首先,根据Web浏览器中所提供的数据访问接口对数据采集层中的数据进行解析;其次,将解析后的数据存储在数据库中,并在数据库中为该数据建立一个索引;最后,对用户输入的查询语句进行解析和处理,并将处理后的结果以HTML页面的形式返回给用户。通过Web浏览器可以方便地获取网络信息资源可视化分析结果,并以图形化界面展示给用户,从而提高用户使用网络信息资源分析工具的效率。
5.4 可视化实现
该模型以可视化分析为目的,将数据处理层获取到的数据和应用层生成的结果,以图形化界面进行展示,为用户提供一个直观、全面的展示工具。通过将数据挖掘算法得到的结果以图形化界面进行展示,可以使用户更清楚地了解数据挖掘算法的作用和挖掘结果对网络信息资源的影响,使用户对网络信息资源有更深刻和全面的理解。例如,对于用户关心的某一主题,如经济类、管理类、社会类等,可以通过相应的图表对其进行可视化展示。这些图表包括不同层次和不同角度的可视化形式。比如在经济类专题图中,可以通过折线图展示某一年份我国GDP增长率与当年全国GDP增长率的差值;在管理类专题图中,可以通过柱状图展示某一省份GDP增长率与当年该省份GDP增长率的差值;在社会类专题图中,可以通过折线图展示某一年份我国就业率与当年该行业就业率之间的差值等。通过不同形式和角度进行可视化展示,不仅能更好地传达信息,还能让用户更清楚地了解数据间的关系。
结语
本文分析了数据挖掘技术、网络信息可视化技术以及网络信息可视化模型设计方法,在此基础上,对基于数据挖掘的网络信息可视化模型进行了设计与实现。该模型利用数据挖掘技术从大量网络信息资源中挖掘出有用的知识和模式,实现对网络信息资源的有效分析,有利于用户通过可视化界面获取有关知识或进行决策分析。由于该模型还存在一些不足之处,如对数据挖掘的有效性判断等问题,因此还需要进一步完善和改进。
参考文献:
[1]杨红艳.基于数据挖掘的能源互联网数据安全风险检测方法[J].信息技术与信息化,2023(7):145-148.
[2]翟海华,周圣铠,汤答,等.我国互联网诊疗管理现状与启示[J].中国动物检疫,2023,40(10):43-46.
[3]刘泽霖.基于数据挖掘的网络信息安全技术研究[J].信息与电脑(理论版), 2023,35(12):210-212.
作者简介:王晓静,硕士研究生,副教授,研究方向:网络安全和信息化建设;陈玉英,硕士研究生,工程师,研究方向:文化和旅游行业信息化建设。
基金项目:呼和浩特市科技计划项目(重大科技专项)——数据中台及数字信息服务平台的研发与应用——基于人工智能技术的海量时序数据中台研究与应用开发(编号:2022-高重-2)。
