基于LSTM神经网络的浮选品位预测模型
2024-04-26王春景刘丹张文康邵平余龙舟周恭强
王春景 刘丹 张文康 邵平 余龙舟 周恭强

作者简介:王春景(1996-),硕士研究生,从事选矿设备与选矿过程自动化的研究。
通讯作者:刘丹(1983-),副教授,从事选矿工艺与理论、选矿设备及自动控制的研究,ldysyz1983@126.com。
引用本文:王春景,刘丹,张文康,等.基于LSTM神经网络的浮选品位预测模型[J].化工自动化及仪表,2024,51(2): 325-332.
DOI:10.20030/j.cnki.1000-3932.202402023
摘 要 针对目前选矿行业中浮选环节的精矿品位难以实时监测的问题,提出基于长短时记忆(LSTM)网络的浮选品位预测模型。利用浮选品位参数在时序上的相关性,采用两层LSTM网络提取特征,将浮选过程中的药剂添加量、充气速率、矿浆pH值等参数作为输入值,对浮选后的精矿品位进行实时预测,并以平均绝对误差(MAE)、均方根误差(RMSE)、可决系数(R2)对预测结果进行评价。实验结果表明:该神经网络模型的参数与结构设置合理,预测表现良好,MAE为0.080 7、RMSE为0.109、R2达到了0.678。该模型适用于浮选环节的实时精矿品位预测,后续可根据预测值反馈调节浮选过程参数,使得精矿品位趋近期望值,对浮选过程的智能化具有促进作用。
关键词 长短时记忆网络 深度学习 时间序列 浮选品位预测
中图分类号 TP14 文献标志码 A 文章编号 1000-3932(2024)02-0325-08
选矿作为连接采矿与冶炼的重要环节,其主要目的是剔除脉石并富集有用矿物,分选后的精矿品位高、杂质少,可以减轻后续冶炼过程的资源消耗。而品位作为衡量精矿品质的一个重要指标,在选矿过程中备受关注。长期以来,人们普遍缺乏对精矿品位的实时监测能力,在浮选过程中,选矿厂通常采用人工采样化验的方法来获取精矿的品位,但这样的方式在时间上存在着滞后,难以及时获取品位信息,使得各类可控变量调控不及时,进而影响精矿的品质。
由于浮选过程的复杂性,传统的机理建模方式往往难以准确描述浮选过程,产生的预测结果可靠性不足。随着机器学习技术的发展,基于数据驱动的建模方法日渐成熟,国内外学者提出了一些可行的品位预测方法。从基础的最小二乘法,到相对复杂的支持向量机、随机森林等,人们使用多种传统机器学习方法对浮选品位进行预测[1~7],通过采集浮选过程中的矿浆pH值、药剂添加量等参数,建立关键参数的输入输出模型,尝试对浮选品位进行实时软检测。之后,随着以多层神经网络为基础的深度学习技术的发展,一些新型预测模型被相继提出,部分模型在天气、交通预测等多种领域中表现出了优于传统机器学习模型的预测效果[8~10]。在选矿的品位预测领域,相关领域的研究人员也对一些深度学习方法进行了探索,文献[11]开发了一种专用的深层神经网络FlotationNet,使用定制架构处理输入变量和输出品位之间的不同映射关系,用以预测浮选品位;文献[12]为了解决训练数据采集困难的问题,使用胶囊网络建立模型,其模型只使用了少量数据进行训练,也得到了相对不错的预测结果。虽然这些尝试取得了一定的成果,但也存在着预测效果欠佳、预测评价指标一般、建模训练时间长、难以在生产中实际布署等问题,仍有改进空间。
除了基于浮选参数的品位预测外,研究人员还在尝试通过图像信息对浮选泡沫进行分类,并以此推导出最终的浮选品位[13~17]。首先采用一些聚类方法对浮选图像进行分类,并为各个分类人为添加其品位标签,用模型所输出的几个标签号对应品位级别。但这类方式普遍存在一些问题,不同于使用浮选参数建立的回归模型,使用泡沫图像的分类模型需要在训练前就设置好分类数量,并给每一类泡沫形态打上与其对应的品位标签,而泡沫图像的分类是否正確、需要划分为多少种类、如何将泡沫分类与精矿品位正确对应起来等问题的解决方案尚不完善,导致使用泡沫图像直接预测的浮选品位可靠性不高。同时,在浮选车间的实际生产过程中,受光照强度、液面反光等因素的干扰,泡沫图像无法像实验室条件中那样稳定,实际采集时会产生大量噪点,影响最终的预测结果。因此,笔者将使用便于采集的浮选过程参数,使用数据驱动方式构建LSTM神经网络模型,实现精矿品位的软测量。
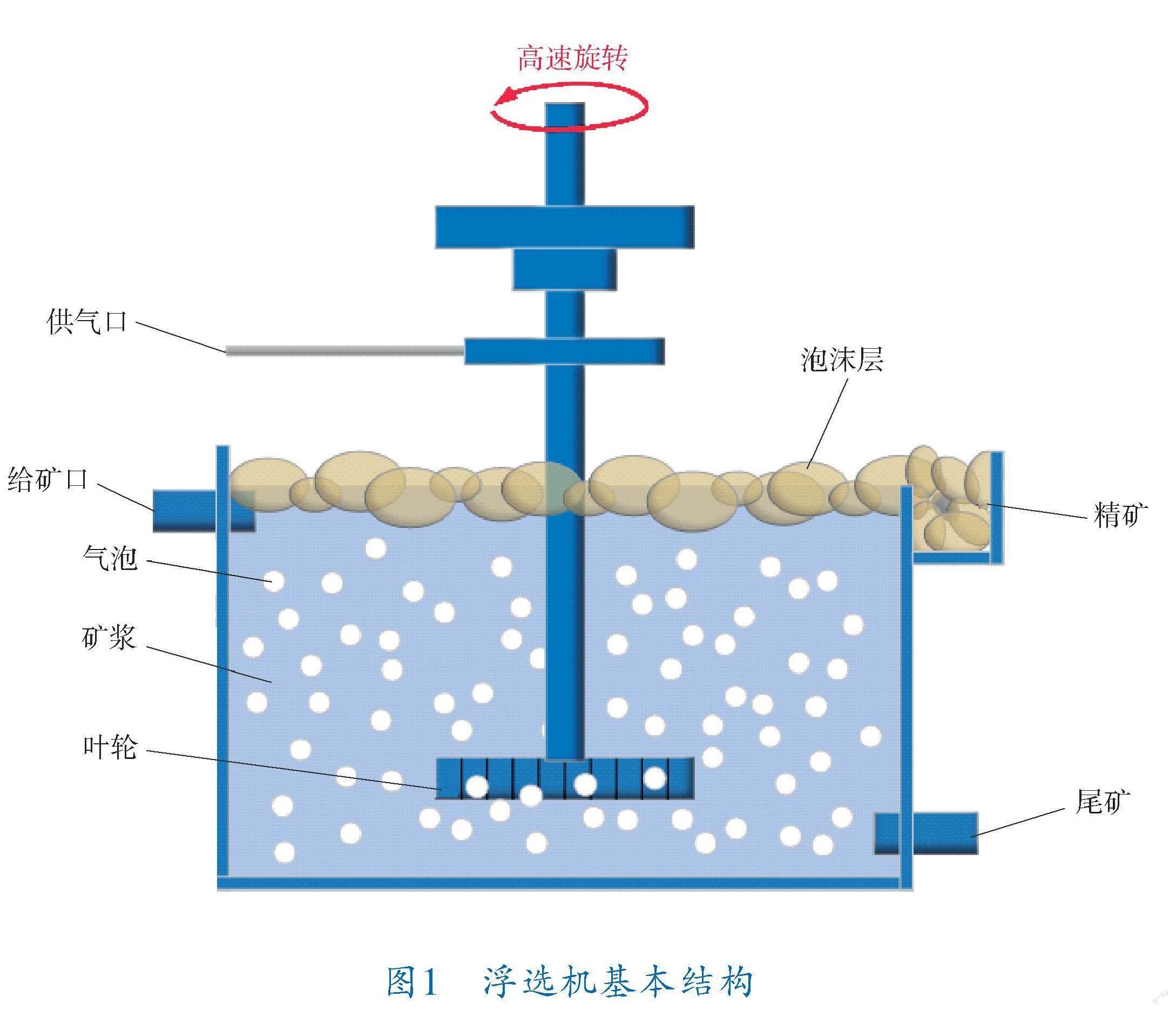
1 浮选基本原理
浮选又称浮游选矿,是根据物料的表面性质差异,通过药剂和机械调节,高效分离出有用矿物和无用矿物的方法。浮选机的基本结构如图1所示,主要由浮选槽、叶轮-定子结构、给矿口、精矿槽等部件组成。浮选时,先将矿浆置于浮选槽中,并通过叶轮搅动混匀,之后向矿浆中添加浮选药剂并开始供气。由于矿物的可浮性差异,易浮矿物在与气泡接触后会漂浮到泡沫层,此时可用刮板将含有精矿的泡沫刮到精矿槽中,尾矿则继续进入下一流程,如此便完成了一次浮选操作。在这一过程中,药剂添加量、矿浆pH值、矿浆浓度、充气速率等参数都会对浮选品位产生影响,如果可以实时预测精矿品位,则可以及时调整这些参数,稳定产品的质量。
2 品位预测模型
如图2所示,品位预测模型可分为3部分:数据集的预处理、模型训练、预测结果的输出与评价。数据集的预处理部分主要用于输入向量的筛选与处理,提高数据在神经网络中的训练效率;模型训练部分则需要搭建合适的网络架构,完成浮选过程的建模;输出与评价部分用于输出预测值,并使用有效的评估方法对预测结果进行评价。
图2 品位预测模型结构
2.1 数据预处理
训练所用的数据集采集自某铁选厂的浮选车间,对于浮选液位、充气速率、矿浆流量、矿浆pH值、矿浆密度等连续变量,每20 s采集一次;对于给矿品位、精矿品位等需要化验的参数,则是每15 min收集一次矿样,但每2 h才进行一次品位化验。通过连续6个多月的采集,该数据集共含有737 453组数据,每组包含时间刻度在内有24类参数,共17 698 872个可训练参数,数据集的参数组成汇总于表1。
在浮选过程中,虽然所采集的这些参数均会对浮选精矿产生相应的影响,但影响的程度有大有小。同时,数据的输入量会影响模型的训练效率,输入过多的无关数据还会占用大量显存,提升训练的硬件成本。因此,在进行训练前,需要通过相关性分析,剔除一些与精矿品位相关性不高的数据组。笔者在删除数据集中的缺失值与重复项后,使用皮尔逊相关系数对相关性进行判断。皮尔逊相关系数可用于统计两个变量之间的相关程度,计算值分布在-1~1之间,数值越接近0,表示相关性越差,反之则表示相关性越强。其计算式为:
表1 数据集的参数组成
r==(1)
整个数据集相关性的计算结果如图3所示,其中,各类参数与精矿铁品位的相关性如图4所示。统计发现,精矿的铁品位与参数N(07浮选机充气量)相关性较低,与参数F(矿浆pH值)、D(Amina用量)等的相关性较高,故在模型的输入中剔除参数N。此外,因为给矿品位也是后期化验所得,不应加入训练集中,因此参数A(给矿铁品位)、B(给矿硅品位)也予以剔除,其余数据则保留。
完成数据筛选后,还需进行标准化处理,统一参数的数量级,避免参数量纲差异影响模型训练,同时提高梯度下降算法求最优解的效率,加快模型的训练速度。笔者使用零均值归一化方法进行数据处理:
μ=x (2)
σ= (3)
z= (4)
其中,N为样本数量,x为数据值,μ表示均值,σ为标准差,z为标准化的结果参数。
2.2 LSTM网络框架
2.2.1 LSTM模型概述
长短时记忆网络的结构如图5所示。与传统的循环神经网络相比,LSTM仍然是基于x和h来计算h,但对内部结构进行了更精细的设计,加入了输入门i、遗忘门f以及输出门o3个门和1个内部记忆单元c。输入门控制当前计算的新状态以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元中的信息如何被遗忘;输出门控制当前输出与记忆单元间的关系。
图5 LSTM单元结构
经典的LSTM中,第t步的更新计算式为:
i=σ(Wx+Uh+b)
f=σ(Wx+Uh+b)
o=σ(Wx+Uh+b)
=tanh(Wx+Uh)
c=f⊙c+i⊙
h=o⊙tanh(c)
其中,i是通过输入x和上一步的隐含层输出h进行线性变换,再经过激活函数σ得到的。输入门i的结果是向量,其中每个元素是0~1间的实数,用于控制各维度流过阀门的信息量;W、U两个矩阵和向量b为输入门的参数,是在训练过程中需要学习得到的。遗忘门f和输出门o的计算方式与输入门类似,它们有各自的参数W、U和b。与传统的循环神经网络不同的是,LSTM从上一个记忆单元的状态c到当前状态c的转移不一定完全取决于激活函数计算得到的状态,还由输入门和遗忘门共同控制。
在一个训练好的网络中,当输入的序列中没有重要信息时,LSTM的遗忘门的值接近于1,输入门的值接近于0,此时过去的记忆会被保存,从而实现了长期记忆功能;当输入的序列中出现了重要信息时,LSTM会将其存入记忆中,此时其输入门的值会接近于1;当输入的序列中出现了重要信息,且该信息意味着之前的记忆不再重要时,输入门的值接近1,而遗忘门的值接近于0,这样旧的记忆被遗忘,新的重要信息被记忆。经过这样的设计,整个网络更容易学习到序列之间的长期特征。
2.2.2 模型架构
如表2所示,数据处理完毕后,将会依次进入两个LSTM层进行计算,最后再经过一个全连接层以输出计算值,其中,损失函数Loss设为MAE,優化器Optimizer设为Adam,学习率Learning rate为0.001,迭代次数Epoch为100,批处理量Batch size为32。
表2 网络结构
2.3 模型评价指标
神经网络模型根据任务的目的不同,可分为回归模型和分类模型,不同于分类模型中常用的正确率指标,回归模型更常用平均绝对误差MAE、均方根误差RMSE、可决系数R2等统计指标来衡量结果的好坏。本模型作为时间序列的预测模型,仍属于一种回归模型,故采用MAE、RMSE和R2评价预测效果,MAE与RMSE越接近0、R2越接近1,则说明模型的预测效果越好。其计算式为:
MAE=|(y-)|
RMSE=
R=1-
其中,y为真实值,为预测值,y为真实值的平均值。
3 实验及分析
3.1 实验配置
实验环境列于表3,处理器为Intel (R)Core(TM)i5-12400,GPU型号为NVIDIA GeForce 3090,显存为24 GB,预测模型开发环境为Python3.9、Pytorch1.7.0、cuda10.1。
表3 配置和环境
3.2 层结构对预测结果的影响
在时间序列预测模型中,网络的层结构对预测结果有着显著的影响。层数少时训练速度快,但预测效果可能不佳;而由于LSTM网络为具有时间记忆功能的串行网络,且难以进行并行优化,当所用层数过多时又会消耗大量的计算资源,还存在梯度消失的风险。
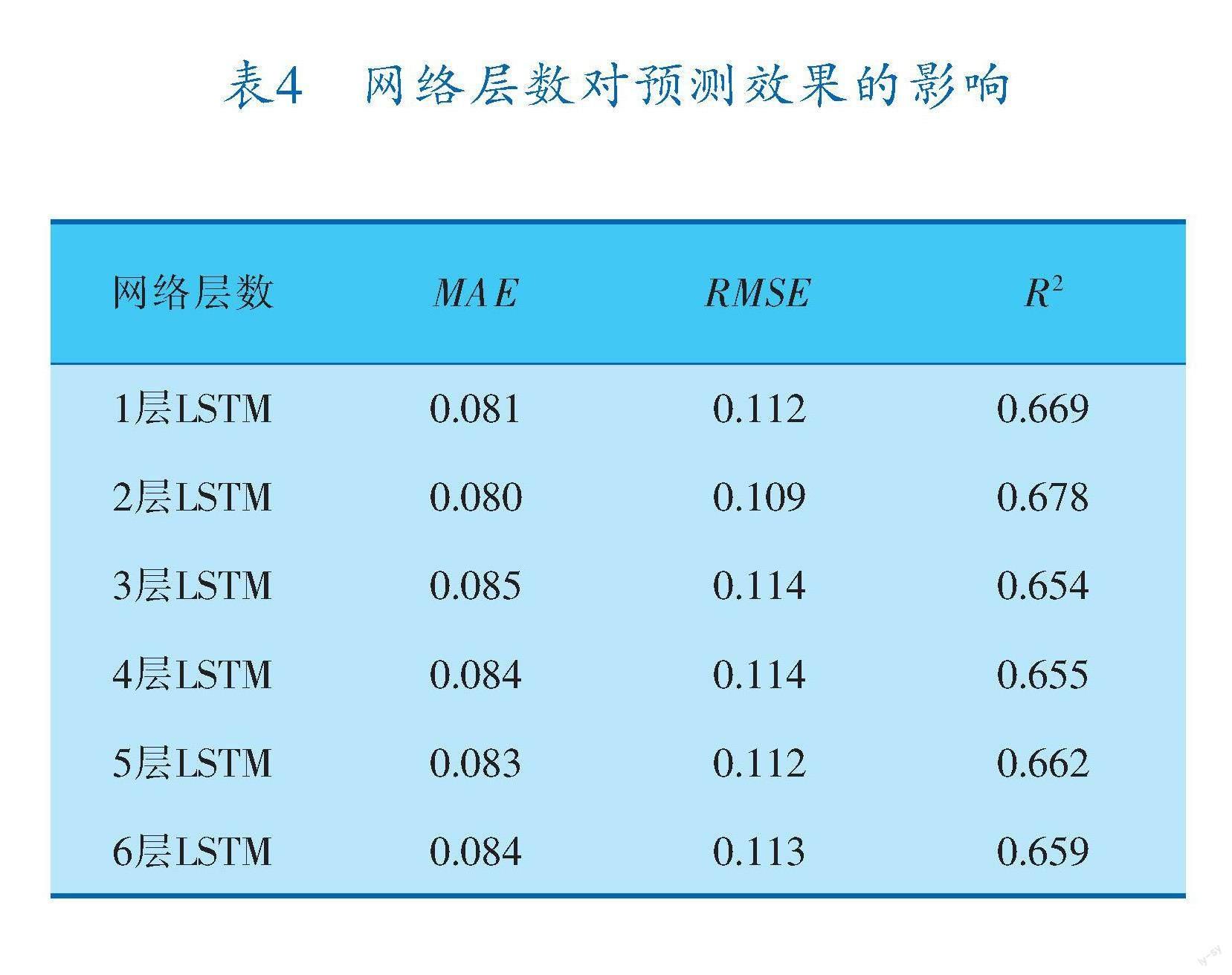
现将在其余参数不变的情况下,以层数为区分分别训练网络,对比不同层数下的预测效果,最终训练结果见表4,可以看出,3个评价指标呈现一致。
表4 网络层数对预测效果的影响
可决系数的变化趋势如图6所示,可以看出,当LSTM网络层数为2时,预测效果最佳。因为LSTM每一层的特征提取能力都很强,两层结构已经足够提取所需特征,继续增加网络层数对预测结果并无益处,反而会使特征梯度在传递过程中逐渐消失,预测效果变差。
图6 网络层数对可决系数R2的影响
3.3 超参数的优化
在机器学习中,超参数是指无法通过模型训练得到,而是需要在训练前就进行设置的参数。训练时,需要对批处理量Batch size、学习率Learning rate、损失函数Loss、优化器Optimizer等超参数进行优化,以提高预测模型的准确性。现将在保持其余变量不变的情况下,逐一调试常用的超参数,调试结果见表5,可以看出,当Batch size为32、Learning rate为0.001、Loss为MAE、Optimizer为Adam时,此数据集在该硬件平台的预测效果最佳。
表5 各组超参数对预测效果的影响
3.4 预测结果
使用优化后的网络结构和超参数再次对数据集进行模型训练,构建品位预测模型。训练过程的损失值曲线如图7所示,随着迭代次数的增加,测试集的损失值逐渐减小,并开始出现振荡,直至不再持续减小时停止训练。
图7 预测模型的损失值曲线
使用此模型对验证集做预测,其结果如图8所示,发现预测值可以较好地贴合实际值曲线,预测结果的MAE为0.080 7、RMSE为0.109、R2为0.678。
4 结束语
为了解决浮选环节中精矿品位难以实时监测的问题,使用浮选过程中的易测参数进行建模,提出基于LSTM的浮选精矿品位预测模型。LSTM算法可以充分提取浮选过程的参数特征,提供可靠的预测结果。实验表明,浮选精矿品位与矿浆pH值、药剂添加量、浮选机充气量等参数在时序上存在相关性,当使用网络层数为2、超参数Batch size為32、Learning rate为0.001、Loss为MAE、Optimizer为Adam的LSTM模型时预测效果最佳。
本模型在数据集总体的预测上表现良好,但在部分区间仍存在预测结果波动的情况,对此,后续研究拟通过改进调参方式、扩展数据集或更换其他模型的方式进行优化。
参 考 文 献
[1] 李启福,王雅琳,曹泊,等.基于滑窗B样条偏最小二乘的浮选过程质量指标软测量[J].中国科技论文,2012,7(4):294-301.
[2] 雷雨田,王庆凯,王旭.基于动态随机森林算法的铜浮选精矿品位预测[J].矿冶,2022,31(6):110-113.
[3] 任传成,杨建国.浮选过程精矿品位软测量技术的研究进展[J].矿山机械,2013,41(8):8-12.
[4] 阳春华,任会峰,许灿辉,等.基于稀疏多核最小二乘支持向量机的浮选关键指标软测量[J].中国有色金属学报,2011,21(12):3149-3154.
[5] KHAJEHZADEH N,HAAVISTO O,KORESAAR L.On-stream and quantitative mineral identification of tailing slurries using LIBS technique[J].Minerals Engineering,2016,98:101-109.
[6] KHAJEHZADEH N,HAAVISTO O,KORESAAR L.On-stream mineral identification of tailing slurries of an iron ore concentrator using data fusion of LIBS,reflectance spectroscopy and XRF measurement techniques[J].Minerals Engineering,2017,113:83-94.
[7] WANG Q Y,LI F S,JIANG X Y,et al.On-stream mineral identification of tailing slurries of tungsten via NIR and XRF data fusion measurement techniques[J].Anal Methods,2020,12(25):3296-3307.
[8] TRAN T,LEE T,SHIN J Y,et al.Deep Learning-Based Maximum Temperature Forecasting Assisted with Meta-Learning for Hyperparameter Optimization[J].Atmosphere,2020,11(5):487.
[9] YU Y J,CAO J F,ZHU J F.An LSTM Short-Term Solar Irradiance Forecasting under Complicated Weather Conditions[J].IEEE Access,2018(7):053501.
[10] YUAN J,ABDEL-ATY M,GONG Y,et al.Real-Time Crash Risk Prediction Using Long Short-Term Memory Recurrent Neural Network[J].Transportation Research Record Journal of the Transportation Research Board,2019. DOI:10.1177/0361198119840611.
[11] PU Y,SZMIGIEL A,CHEN J,et al.FlotationNet:A hierarchical deep learning network for froth flotation recovery prediction[J].Powder Technology,2020,375:317-326.
[12] CEN L H,WU Y M,HU J,et al.Application of density-based clustering algorithm and capsule network to performance monitoring of antimony flotation process[J].Minerals Engineering,2022,184:ARTN 107603.
[13] ZHANG J,TANG Z H,LIU J P,et al.Recognition of flotation working conditions through froth image statistical modeling for performance monitoring[J].Minerals Engineering,2016,86:116-129.
[14] WANG X,CHEN S,YANG C,et al.Process working co-ndition recognition based on the fusion of morphological and pixel set features of froth for froth flotation[J].Minerals Engineering,2018,128:17-26.
[15] FU Y,ALDRICH C.Using Convolutional Neural Net -works to Develop State-of-the-Art Flotation Froth Image Sensors[J].IFAC-PapersOnLine,2018,51(21):152-158.
[16] FU Y,ALDRICH C.Froth image analysis by use of tra- nsfer learning and convolutional neural networks[J].Minerals Engineering,2018,115:68-78.
[17] ZARIE M,JAHEDSARAVANI A,MASSINAEI M.Flo-tation froth image classification using convolutional neural networks[J].Minerals Engineering,2020,155:106443.
(收稿日期:2023-06-06,修回日期:2023-06-28)
Flotation Grade Prediction Model Based on LSTM Neural Network
WANG Chun-jing1,2, LIU Dan1,2, ZHANG Wen-kang1,2,
SHAO Ping1,2, YU Long-zhou3, ZHOU Gong-qiang4
(1.Faculty of Land and Resources Engineering, Kunming University of Science and Technology;2.State Key Laboratory of Clean Utilization of Complex Nonferrous Metal Resources ;3. Yunnan Amade Electrical Engineering Co.,Ltd;
4. CAS Chengdu Information Technology Co., Ltd.)
Abstract Considering the difficulty in real-time monitoring the concentrate grade of flotation process in the mineral processing industry, a flotation grade prediction model based on long short-term memory (LSTM) cyclic neural network was proposed. In which, through making use of the time-series correlation of flotation grade parameters, a two-layer LSTM network was used to extract features, and parameters such as reagent addition, aeration rate, ore pulp pH value during flotation were used as input values to real-time predict the concentrate grade after the flotation, including evaluating the prediction results with mean absolute error (MAE), root mean square error (RMSE), and R-squared (R2). The experimental results show that, the both parameters and structure of the neural network model are set reasonably along with good prediction performance; and the MAE is 0.080 7, the RMSE stands at 0.109 and the R2 reaches 0.678. The model is suitable for real-time concentrate grade prediction in the flotation process, and the parameters of the flotation process can be adjusted according to the predicted value feedback to make the concentrate grade approach the expected value, which can promote the intelligence of the flotation process.
Key words long short-term memory network, deep learning, time series, flotation grade forecast
