用于单图像超分辨率的全局特征高效融合网络
2024-04-26张玉波田康徐磊
张玉波 田康 徐磊

基金项目:黑龙江省自然科学基金(批准号:LH2022F005)資助的课题;东北石油大学引导性创新基金(批准号:1507
202202)资助的课题。
作者简介:张玉波(1982-),副教授,从事机器学习、图像处理、信号处理、单片机理论与应用等的研究。
通讯作者:田康(1994-),硕士研究生,从事图像超分辨率和图像去模糊的研究,tiankangg@163.com。
引用本文:张玉波,田康,徐磊.用于单图像超分辨率的全局特征高效融合网络[J].化工自动化及仪表,2024,51(2):207-214;300.
DOI:10.20030/j.cnki.1000-3932.202402009
摘 要 现有图像超分辨率网络中普遍存在对层间特征利用水平较低的现象,使得在图像重建过程中有细节特征丢失,最终处理结果纹理模糊、图像质量欠佳。为此提出一种用于图像超分辨率的全局特征高效融合网络模型。主体使用对称卷积神经网络实现浅层特征的逐级提取,并结合Transformer完成浅层与深层特征的融合利用。设计的对称自指导残差模块可以在浅层网络实现不同层间特征更具表达性的融合,同时提升网络的特征提取能力;特征互导融合模块可以增强网络对浅层特征与深层特征的融合能力,促进更多的特征信息参与到细图像重建过程。在Set5、Set14、BSD100和Urban100数据集上同近年来的经典网络(HR、CARN、IMDN、MADNet、LBNet)进行性能对比,实验结果表明:所提网络模型在峰值信噪比上有所提升,并在视觉直观对比中取得了较好的图像超分辨率效果,可改善超分辨率图像质量欠佳的问题。
关键词 单图像超分辨率 全局特征高效融合网络模型 对称自指导残差模块 特征互导融合模块
深度学习
中图分类号 TP391 文献标志码 A 文章编号 1000-3932(2024)02-0207-09
随着人们对更加高清图像的需求,图像超分辨率技术得以持续发展。该技术不受传感器和光学器件制造工艺、成本的限制,在保留现有硬件设施的基础上通过软件的方法,就能达到提高分辨率的目的。超分辨率技术在遥感成像、视频图像压缩传输、医学成像、视频感知与监控等领域得到广泛研究与应用。
单图像超分辨率旨在从模糊的低分辨率(LR)图像中恢复出具有更加丰富细节和更好视觉质量的高分辨率(HR)图像。近年来,由于深度神经网络强大的特征表示能力,基于卷积神经网络(CNN)的方法主导了超分辨率(SR)的研究,学者们通过多种途径来推动CNN结构的优化,如增加通道注意力、残差连接等。DONG C等提出SRCNN,完成了用CNN处理SR任务的开创性工
作[1]。KIM J等用残差连接来构建深度网络,提出了一种结构很深的卷积网络VDSR网络来实现更加优秀的性能[2]。LIM B等提出一种增强型深度残差网络(EDSR),该网络通过删除不必要的模块(如批量归一化)改进了SR任务的残差网络架
构[3]。AHN N等提出一种基于级联模块的神经网络(CARN)[4],通过多级表示和多个快捷连接有效地提高了性能。LAN R S等提出一个密集的轻量级网络(MADNet),其通过双残差路径块和具有注意力机制的残差多尺度模块,形成更强的多尺度特征表达和特征相关学习[5]。WANG L G等提出了一种稀疏掩码超分模型(SMSR),通过探索SR任务中的稀疏性来提高推理效率,能够在跳过冗余计算的同时保持卓越的性能[6]。SUN B等提出了一种新颖的轻量型超分网络(HPUN),其自残差可以克服单图像超分任务中的深度卷积缺陷,并且不会增加计算量[7]。
受益于自注意力机制可以有效地捕获输入序列之间的长期依赖关系的特性,Transformer[8]成为一种功能强大的深度学习模型,并在自然语言处理(NLP)领域取得不断进步。研究人员尝试采用Transformer来解决计算机视觉问题,开创性地将引入Transformer模型的视觉转换器(ViT)[9]用于图像分类任务。ViT验证了不受局部连接约束的自注意力操作,使网络能够学习输入图像中的远程空间依赖关系,表明了Transformer在恢复任务中的适用性。由此,引入Transformer来解决各种视觉任务的工作,如图像分类、目标检测、语义分割和超分辨率。CHEN H T等提出了一种用于图像恢复的预训练图像处理Transformer(IPT),该网络中对比学习的引入促进了网络更好地适应不同的图像处理任务(如去噪、超分辨率和去雨)[10]。WANG S Z等提出了一种保留细节的Transformer(DPT),利用光场的梯度图来指导序列学习[11]。LUO Z W等结合光流和可变形卷积提出BSRT来解决突发超分辨率(BurstSR)任务,其可以更有效地处理错位并聚合多帧中的潜在纹理信息[12]。LIANG Z Y等提出了一种简单有效的基于Transformer的光场(LF)超分方法(LFT),该方法中设计了一个角度变换器来整合不同视图之间的互补信息,并开发了一个空间变换器来捕获每个子孔径图像内的局部和远程依赖关系[13]。GAO G W等提出了一个轻量级双峰网络(LBNet),其中包含对局部特征提取和粗图像重建的有效的对称CNN[14],同时还提出一种递归Transformer来充分学习图像的长期依赖性,从而促进利用全局信息来进一步细化纹理细节。
无论是基于CNN的方法,还是基于CNN与Transformer结合的方法,都可以通过精细的网络设计不断提高SR的性能。但大多数方法存在以下两个局限:一是对层间特征的利用不够细腻,特征的融合普遍采用直连的方法,这会使得在SR过程中对不同层间特征的利用率降低,造成局部特征提取不够充分;二是浅层特征往往通过一条连接线来指导图像的最终重建,未能充分参与到深层网络中的细图像重建过程。为此,笔者提出一种用于图像超分辨率的全局特征高效融合网络,该网络采用对称CNN结构实现局部特征的提取,其中所包含的对称自指导残差模块结合了自引导、通道注意力机制与多分支残差操作,可以在提升特征表达性的同时得到更加丰富的特征信息;网络使用Transformer学习图像的长期相关性,并且嵌入一个特征互导融合模块来实现浅层网络和深层网络中特征知识的融合,促进全局特征信息的高效利用。通过具体实验,在评价指标与图像主观视觉对比上,笔者所提网络优于近年来广泛使用的经典图像超分辨率网络,可以实现较好的图像超分性能。
1 网络设计
1.1 超分重建模型
超分重建旨在克服或补偿由于图像采集系统自身或采集环境限制所导致的成像图像模糊、质量低下及感兴趣区域不显著等问题,利用数字图像处理、计算机视觉等领域的相关知识,借助特定的算法和处理流程,从给定的低分辨率图像中重建出高分辨率图像。其原理可以建模为:
y=(xk)↓(1)
X=F(y)(2)
其中,x是给定的HR图像,y是通过某一确定的下采样核k人造的LR图像,而X是通过超分辨率模型F获得的SR图像。很显然超分任务中训练的模型实际上是模拟了一个k的逆映射,当F可以很好地模拟出这个逆映射时,X一定是非常接近x的,即最终实现一个与低分辨率图像内容相对应的、具有更加清晰细节表现的高分辨率图像。
1.2 网络结构
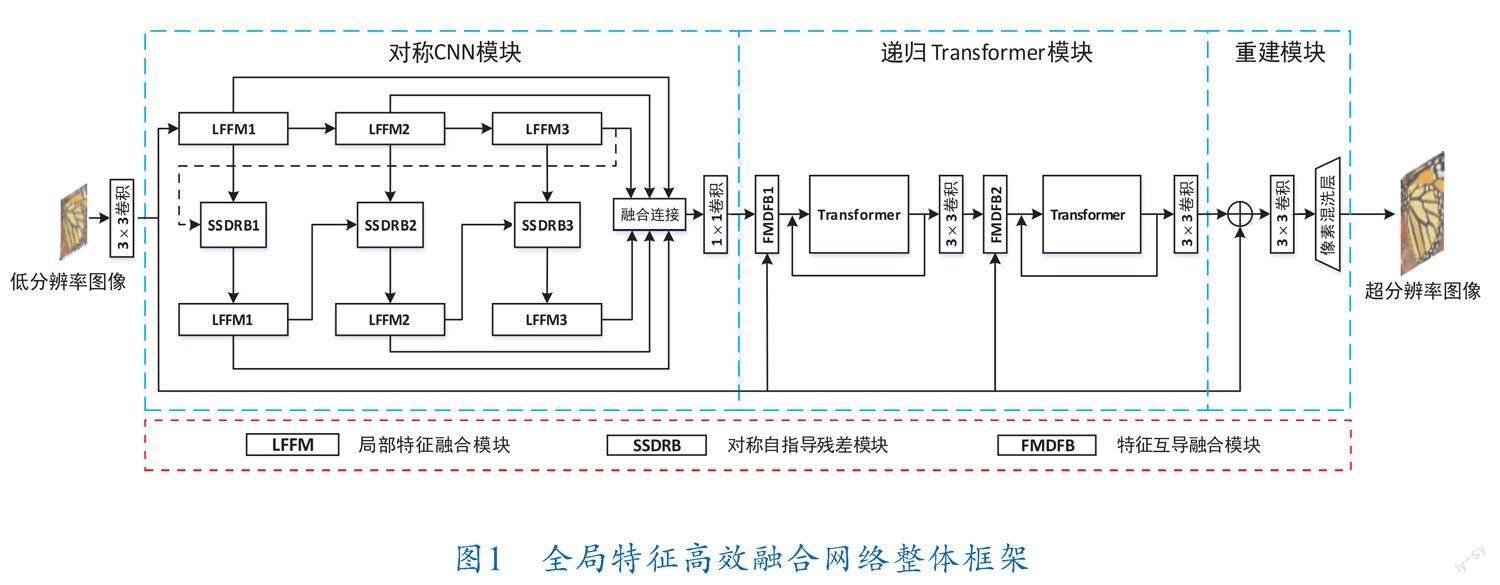
由CNN提取的局部特征可以在不同视角下保持自身的稳定性,并且Transformer可以对图像中的长期依赖进行建模,这种强大的表示能力可以帮助恢复图像的纹理细节。为充分利用二者的优点,笔者基于CNN和Transformer技术提出全局特征高效融合网络。具体来说,该网络主要包括对称CNN、递归Transformer和重建模块3部分,网络框架如图1所示。在模型的头部,笔者使用卷积来完成初始特征的提取,然后将初始特征传递给下级网络进行局部特征的操作。
CNN提取的特征具有局部不变性,这有助于图像理解和重建,笔者使用一种对称CNN结构实现局部特征的提取。该结构由局部特征融合模
块[14]和对称自指导残差模块组成,局部特征融合模块可以实现图像特征的粗提取,将由跨层间的局部特征融合模块所提取的粗特征共同传送给对称自指导残差模块来细化特征。受文献[15]在无监督自适应学习(UAL)网络中用一种自导结构来实现特征由粗到细的启发,笔者设计了对称自指导残差模块来进行特征细化,该模块在使不同层间特征更具表达性融合的同时,所采用的多分支残差结构可以进一步提升网络的局部特征提取能力。
由对称CNN产生的所有细化特征被传送到递归Transformer模块进行长期依赖学习,这部分由特征互导融合模块和Transformer[14]组成。笔者所提出的全局特征高效融合网络在保留了初始特征对图像重建的指导外,通过特征互导融合模块将浅层特征和深层特征进行融合,用以提供更加丰富的特征信息供Transformer进行长期依赖学习,进而促进全局特征信息的高效利用。此外,该网络在Transformer处沿用了递归结构,可以促进Transformer进行充分训练。
位于网络末端的重建模块由卷积层和像素混洗层组成。将由递归Transformer得到的细化特征与初始特征共同输入重建模块得到超分辨率图像。
1.3 对称自指导残差模块
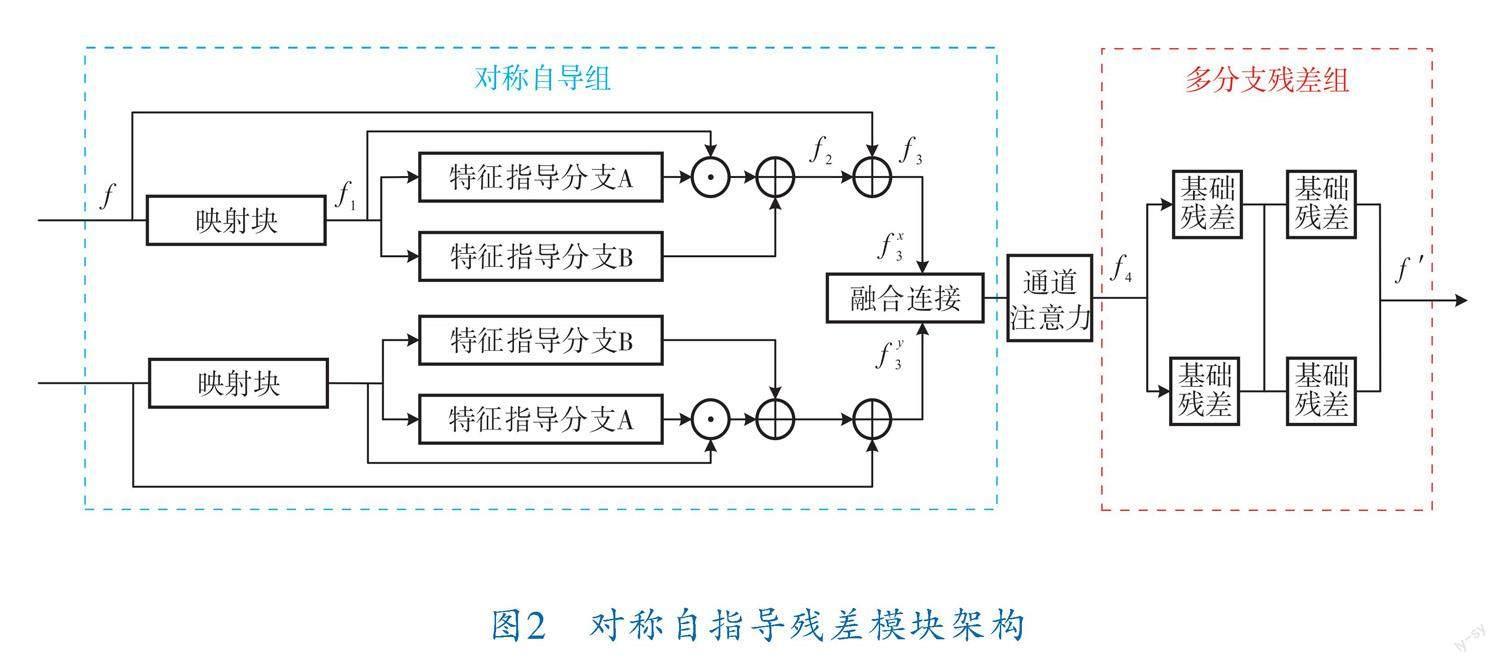
在局部特征处理阶段,为了促进不同局部特征融合模块组合之间的特征参数共享更加细腻和充分,因此笔者提出了一种对称自指导残差模块。如图2所示,对称自指导残差模块由对称自导组、通道注意力模块和多分支残差组[16]组成。对称自导组用于将来自不同局部特征融合模块处理的粗特征进行自导学习,提升特征的细节表达能力。通道注意力模块更加关注包含关键图像特征信息的通道,使更多有用的特征信息被筛选出来,从而达到提高特征表示能力的目的。经由通道注意力筛选的有用特征最终被传送到多分支残差组,多分支残差结构是对传统残差串联结构的改进,它不仅可以提升模块的特征提取能力,还在一定程度上减少了模块中的训练参数、降低了训练难度[17]。
对称自导组由上下两个结构对称的分支组成。下面以上分支为例进行介绍。
局部特征f经过映射块得到特征f,可表示为:
f=F(f)(3)
其中,F是映射块,由卷積层和RELU层穿插组成。
特征f经过指导分支A后与自身逐点乘积,并与f经过指导分支B的结果融合得到特征f:
f=f⊙F(f)+F(f)(4)
其中,F、F是特征指导分支,同样由卷积层和RELU层组成;⊙表示逐点乘积。
特征f与局部特征f相加最终得到更具表达性的特征f:
f=f+f(5)
f、f分别代表经过上下对称自导通道得到的特征结果,二者相加融合后经过通道注意力模块得到特征f:
f=F(f+f)(6)
其中,F是通道注意力。
特征f经过FRG模块后最终得到具有更多细节表达的特征f ′:
f ′=F(f)(7)
其中,F是新型多分支残差组模块。
多分支残差组由4个基础残差块(RB)组成。基础残差块结构如图3所示,其由两个3×3卷积和一个RELU层穿插组成,并且采用ResNet残差结构。在多分支残差结构中,不同基础残差块之间的不同组合可以形成3种残差结构,如图4所示。所采用的多分支残差结构可以充分提高模块的特征提取能力,为网络提供丰富的图像特征信息。
图3 基础残差块结构
图4 残差组的3种残差结构
1.4 特征互导融合模块
在超分辨率网络中,对浅层特征的利用大都是只通过直连结构参与最后的超分重建,使得全局特征信息的共享匮乏。为此,笔者提出一种特征互导融合模块,该模块将来自网络浅层与深层的特征信息进行融合,并通过互导学习提升特征的表达性,其结构如图5所示。
图5 特征互导融合模块架构
浅层特征fshallow与深层特征fdeep分别经过映射块后融合相加得到本地特征f:
f=F(f)+F(f)(8)
本地特征f经过指导分支A后与自身逐点乘积,并与f经过指导分支B的结果相加得到聚合特征f:
f=f⊙F(f)+F(f)(9)
特征互导融合模块不同于简单地将所有特征直接堆叠在一起来学习有用的特征信息,特征互导融合模块对特征f进一步采用互指导操作,提高了融合特征的表达性,促进全局信息和上下文信息更加紧密地连接来,实现高效、高性能的跨层特征融合,同时为下级递归Transformer模块提供具有更多细节表现的特征信息。
2 实验
2.1 实验设置
2.1.1 数据集与评价指标
笔者在DIV2K数据集上对模型进行了训练,并在Set5[18]、Set14[19]、BSD100[20]和Urban100[21]4个基准测试数据集上验证全局特征高效融合网络的性能。在这些数据集中,Set5、Set14和BSD100包含了自然景色,Urban100包含了具有挑战性的城市景色,具有不同频带的细节。笔者使用PSNR(Peak Signal-to-Noise Ratio)来定量评估全局特征高效融合网络的性能,PSNR表示最大可能信号功率与影响其表示精度的破坏性噪声功率之比。
2.1.2 实验环境与细节
笔者所提模型使用Python v3.6和PyTorch v1.1实现,并在带有NVIDIA GTX1080Ti GPU的工作站上进行训练。模型的训练过程共包括1 000次迭代。模型中每个部分的输入和输出通道均设置为32。在整个网络的训练过程中,笔者采用了2×10-4的初始学习率,在训练完成时学习率降至6.25×10-6。
2.2 实验结果及分析
为了定性地研究所提出模型的性能,笔者采用PSNR在4个基准测试数据集上评估该模型和其他现有网络模型。比较结果列于表1、2中(红色表示结果最好)。
由表1所列数据可以看到,在Scale为×3的情况下笔者所提模型取得的PSNR均优于所列其他模型。具体来说,在Set5数据集上与MADNet模型相比,PSNR从34.16提高到34.58,提高了1.23%;在Urban100数据集上与SMSR模型相比,PSNR从28.25提高到28.62,提高了1.31%;笔者所提模型在Set5、Set14和BSD100数据集上取得的PSNR比LBNet模型平均高出0.1,尤其在Urban100数据集上高出了0.2。
由表2可以看到,在Scale为×4的情况下笔者所提模型也取得了较好的PSNR。在Set14数据集上与SMSR相比,PSNR从28.55提高到28.73,提高了0.63%;在Urban100数据集上与IMDN相比,PSNR从26.04提高到26.42,提高了1.46%;笔者所提模型在Set14和BSD100数据集上取得的PSNR与LBNet相当,但在Set5与Urban100数据集上分别高出0.1和0.15。总而言之,全局特征高效融合网络模型在Set5、Set14、BSD100和Urban100数据集上都表现出高性能,这证实了该模型在超分辨率任务中是有效的。
为了更直观地展示模型优势,笔者在BSD100和Urban100数据集上分别与HR、CARN、IMDN、MADNet、LBNet网络模型[4,5,14,23]进行了视觉对比。图6、7分别显示了全局特征高效融合网络模型和其他5个网络模型在BSD100数据集和Urban100数据集上的视觉比较。
由图6可以看出,MADNet模型虽然开发了具有注意机制的残差多尺度模块来增强信息多尺度特征表示能力,但取得的实际效果却不尽人意。其生成的图片在中间部分具有严重的形变并且十分模糊,墙体的结构也非常扭曲。IMDN模型得到的图片比MADNet模型略微清晰,但形变依然很严重。CARN模型在本地和全局级别都使用级联机制来合并来自多个层的特征,进一步提升了特征信息在整个SR过程中的利用水平,但其生成的图片边缘很模糊,窗子的形状扭曲不规则。LBNet模型利用一种有效的对称CNN促进局部特征提取和粗图像重建,推动了该网络产生更加清晰的图像,但结果中位于图片边缘的部分缺乏细节表现,比如窗子的轮廓不清晰。得益于对不同层次特征的高效利用,笔者所提模型在实验中取得了很可观的视觉效果,得到的图像结果墙体结构更加规则,窗子轮廓也更加清晰。
對以上结果的描述,同样适用于在数据集Urban100上的视觉对比,如图7所示。综合来看笔者所提模型重建的超分辨率图像具有更丰富的细节纹理和更好的视觉效果,这进一步验证了该模型处理图像超分辨率任务是有效的。
2.3 消融研究
为证明对称自指导残差模块和特征互导融合模块的有效性,笔者在基线网络[14]上进行消融实验,采用PSNR指标同时在Set5、Set14、BSD100和Urban100数据集上评估模型。消融实验首先将自指导残差模块和特征互导融合模块分别嵌入基线网络进行单独测试,验证单一模块的性能;然后将两个模块共同嵌入组合成全局特征高效融合网络并进行实验,实验结果见表3。所有消融实验都遵循相同的设置。
由表3可知,与基线方法相比,笔者所提出模块能够促进性能指标的提升。具体来说,在Set5数据集上,仅加入对称自指导残差模块时,指标从32.29上升到32.36;仅加入特征互导融合模块时,指标从32.29上升到32.35。在Urban100数据集上,分别加入对称自指导残差模块和特征互导融合模块时,指标从26.27分别上升到了26.38和26.39。同时引入两个模块之后,指标在Set5数据集上从32.29提高到32.39,在Urban100数据集上从26.27提高到26.42。此外,笔者所提方法取得的指标结果在Set14和BSD100数据集上也有所提升。
3 结束语
为提升图像超分辨率任务中对层间特征的利用水平,笔者提出一种新颖的用于实现单图像超分辨率的全局特征高效融合网络模型。该网络结合卷积神经网络和Transformer的技术优势,采用对称结构逐级实现特征信息由粗到细的过程,所提出的对称自指导残差模块可以在增加特征表达性的同时提升模型的特征提取能力,使超分辨率过程中的特征信息更加丰富;特征互导融合模块的提出与嵌入使全局特征信息共享更加充分,为Transformer提供具有更多细节表达的特征信息来进行长期依赖学习。最终的实验结果表明,笔者提出的网络模型可以在多个数据集上获得较好的图像超分效果,性能指标同现有的超分网络相比具有一定的优势;消融研究也再次验证了笔者所提出模块在图像超分辨率任务中的有效性。
參 考 文 献
[1] DONG C, LOY C C, HE K M, et al.Image super-resolution using deep convolutional networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,38(2):295-307.
[2] KIM J, LEE J K,LEE K M. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2016:1646-1654.
[3] LIM B,SON S,KIM H,et al.Enhanced deep residual networks for single image super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE,2017:136-144.
[4] AHN N,KANG B,SOHN K A. Fast,accurate,and lightweight super-resolution with cascading residual network[C]//Proceedings of the European Conference on Computer Vision(ECCV).2018:252-268.
[5] LAN R S,SUN L,LIU Z B,et al.MADNet:A fast and lightweight network for single-image super resolution[J].IEEE Transactions on Cybernetics,2020,51(3):1443-1453.
[6] WANG L G,DONG X Y,WANG Y Q,et al.Exploring sparsity in image super-resolution for efficient inferen-
ce[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2021:4917-4926.
[7] SUN B,ZHANG Y L,JIANG S Y,et al.Hybrid Pixel-Unshuffled Network for Lightweight Image Super-Resolution[J].arXiv Preprint,2022.DOI:10.48550/arXiv.2203.08921.
[8] VASWANI A, SHAZEER N, PARMAR N, et al.Attention is all you need[J].Advances in Neural Information Processing Systems,2017,30:5998-6008.
[9] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al.An image is worth 16×16 words:Transformers for image recognition at scale[J].arXiv Preprint,2020.DOI:10.48550/arXiv.2010.11929.
[10] CHEN H T,WANG Y H,GUO T Y,et al.Pre-trained image processing transformer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Patt-
ern Recognition.Piscataway,NJ:IEEE,2021:12299-12310.
[11] WANG S Z,ZHOU T F,LU Y,et al.Detail-preserving transformer for light field image super-resolution[J].arXiv Preprint,2022.DOI:10.48550/arXiv.2201.00346.
[12] LUO Z W,LI Y M,CHENG S,et al.BSRT:Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE,2022:998-1008.
[13] LIANG Z Y, WANG Y Q, WANG L G,et al.Light field image super-resolution with transformers[J].IEEE Signal Processing Letters,2022,29:563-567.
[14] GAO G W,WANG Z X,LI J C,et al.Lightweight Bimodal Network for Single-Image Super-Resolution via Symmetric CNN and Recursive Transformer[J].arXiv Preprint,2022.DOI:10.48550/arXiv.2204.13286.
[15] ZHANG L ,NIE J T, WEI W,et al.Unsupervised adaptation learning for hyperspectral imagery super-resolution[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2020:3073-3082.
[16] GAO B K,ZHANG Z X,WU C N,et al.Staged cascaded network for monocular 3D human pose estimation[J].Applied Intelligence,2022,53(1):1021-1029.
[17] GAO B K,BI Y Z,BI H B,et al.A Lightweight-Grouped Model for Complex Action Recognition[J].Pattern Recognition and Image Analysis,2021,31(4):749-757.
[18] BEVILACQUA M,ROUMY A,GUILLEMOT C,et al.Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C]//British Machine Vision Conference.BMVA Press,2012.DOI:10.5244/C.26.135.
[19] ZEYDE R,ELAD M, PROTTER M.On single image scale-up using sparse-representations[C]//Internatio-
nal Conference on Curves and Surfaces. Berlin,Heidelberg:Springer,2010:711-730.
[20] MARTIN D, FOWLKES C,TAL D,et al.A database of human segmented natural images and its applicat-
ion to evaluating segmentation algorithms and meas-
uring ecological statistics[C]//Proceedings Eighth IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2002:416-423.
[21] HUANG J B, SINGH A, AHUJA N.Single image super-resolution from transformed self-exemplars[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2015:5197-5206.
[22] TAI Y,YANG J,LIU X M.Image super-resolution via deep recursive residual network[C]//Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition.Piscataway,NJ:IEEE,2017:3147-
3155.
[23] HUI Z, GAO X B, YANG Y C,et al.Lightweight image super-resolution with information multi-distillation network[C]//Proceedings of the 27th ACM International Conference on Multimedia.New York,United States:Association for Computing Machinery,2019:2024-2032.
[24] ZHANG X Y,GAO P,LIU S X Y,et al.Accurate and efficient image super-resolution via global-local adjusting dense network[J].IEEE Transactions on Multimedia,2020,23:1924-1937.
(收稿日期:2023-03-08,修回日期:2024-01-18)
Global Feature Efficient Fusion Network for Single Image
Super Resolution
ZHANG Yubo, TIAN Kang, XU Lei
(School of Electrical and Information Engineering, Northeast Petroleum University)
Abstract In existing image super resolution networks, the utilization of interlayer features stays at low level, which leads to the loss of detail features in image reconstruction, fuzzy texture and poor image quality in the final processing result. In this paper, a global feature efficient fusion network for image super resolution was proposed. The main body of the network has the symmetric convolutional neural network used to extract shallow features step by step, and Transformer combined to realize both integration and utilization of shallow and deep features. The designed symmetric selfdirected residual block can achieve more expressive feature fusion between different layers in shallow network and improve feature extraction ability of the network. The feature mutualdirected fusion block can enhance the fusion ability of shallow feature and deep feature, and promote more feature information to participate in the process of fine image reconstruction. Finally, on the Set5, Set14, BSD100 and Urban100 datasets, having its performance compared with that of the recent years classical networks(HR, CARN, IMDN, MADNeT and LBNeT) shows that, this network can improve the peak signaltonoise ratio,and achieve better image super resolution effect in the visual comparison, as well as improve the poor quality of the SR image.
Key words singleimage superresolution, global feature efficient fusion network, symmetric selfdirected residual block, feature mutualdirected fusion block, deep learning
