基于图卷积网络的发明人跨领域合作伙伴识别方法*
2024-04-25谢小东盛永祥王建刚
谢小东 吴 洁 盛永祥 王建刚 周 潇
(江苏科技大学经济管理学院 镇江 212003)
0 引 言
当今科学技术演化最普遍的趋势之一是所有领域研究团队规模的扩大和跨组织合作的增加,现代科学问题的复杂性往往需要跨学科、跨领域的解决方案[1]。不同领域之间的交叉融合愈趋频繁和密集,从个人、团队、机构、地区到国家等各种层面的科研合作形式不断涌现[2]。科研合作通过知识、经验、资源全方位共享,不仅帮助研究者分担科研任务、减少重复劳动、提高研究效率,还能提高研究的创新性和深度。然而,科学技术的快速发展,意味着大量技术的不断产生与更替,科研人员尤其是发明人如何在大的行业范围内缩小查找范围,快速定位潜在合作伙伴及跨领域合作伙伴的问题亟待解决。
现阶段关于合作伙伴选择的研究主要分为两类:一类是利用网络分析方法研究合作网络的静态特征和动态特性,在此基础上主要使用复杂网络中的链路预测方法研究可能发生的科研合作关系;另一类是利用机器学习算法将多指标集成来提高推荐精度。但上述两类方法均有其局限性,复杂网络中的链路预测算法主要基于节点相似性的链路预测指标,且推荐成功率依赖网络本身的拓扑结构,方法适用性较差,机器学习中的集成算法虽然可以利用节点属性特征,但其往往计算复杂性较高,忽略了图结构特征的利用。
现有研究在寻找潜在合作伙伴时主要考虑了节点的局部信息,但没有充分利用节点的全局信息和节点特征,且研究主要集中于合作伙伴选择研究,鲜有研究针对跨领域合作伙伴展开。因此本文基于发明人专利数据从合作关系特征、摘要文本特征、领域信息特征三个维度视角下综合考虑发明人特征信息,提出基于图卷积网络的发明人跨领域合作伙伴识别方法,综合利用发明人之间合作网络结构特征和发明人自身节点属性特征,将现实复杂的发明人潜在合作伙伴选择问题转化为适合图卷积网络工作模式的链路预测任务。在此基础上,本文构建同领域指数和跨领域指数准确识别出发明人跨领域合作伙伴。本文所构建方法不仅可以提高潜在合作伙伴寻找的效率和准确性,而且通过挖掘合作网络中的节点特征和拓扑结构,可以充分学习发明人之间的合作模式。最终,通过识别具有跨领域研究方向的合作伙伴,有助于促进不同领域之间的交叉合作和知识转移,创造出更具创新性和前瞻性的成果。
1 相关研究
科研合作是科研网络中重要的组成部分,被研究者定义为“科研人员之间为完成同一科研任务而彼此按照计划协同合作的劳动形态”[3]。随着科学技术爆炸式发展,针对科研合作的研究也逐渐成为计量学等领域的研究热点。Newman等[4]最早利用网络分析方法研究合作关系,结合静态网络的特征研究科研合作网络的结构特征和合作网络中具有影响力的节点。在此基础上,部分学者[5-6]通过科研合作网络的动态特性研究科研人员产生合作关系的原因及演化过程中所呈现的规律。
现阶段学者针对科研合作网络的研究偏重于预测合作网络中的潜在合作关系,其研究大致分为两类,一类是利用复杂网络中的链路预测方法分析现有合作网络中尚未产生连边的节点在未来产生链接的可能性,主要研究方法有基于网络拓扑结构相似性、基于网络结构的最大似然估计和利用概率模型三种[2, 7]。现有的链路预测方法大多是基于节点相似性的链路预测指标,针对单一指标或者简单对指标进行线性加权,这类方法往往效果较差,主要原因是单一指标涵盖的信息并不全面,且链路预测方法推荐成功率依赖网络本身的拓扑结构,方法适用性较差。另一类方法是利用机器学习算法集成多个指标对问题进行系统研究[8]。Guns等[9]将链路预测和机器学习方法进行组合对城市间科研合作进行研究,相较于单个链路预测指标的方法其推荐精度得到大幅提高。但这一类机器学习算法虽然可以综合利用多个节点属性特征,但其往往计算复杂性较高,忽略了图结构特征的利用,其适用范围也偏窄。
近年,深度学习越来越广泛地应用在各个学术领域,其与链路预测结合的思路已经开始有人关注[10]。随着深度学习模型的发展,尤其是卷积神经网络(CNN)在计算机视觉和自然语言处理等方面的应用中取得了可观成绩,越来越多的学者将神经网络的理论与技术应用到网络中,图神经网络的研究也随之兴起[11-12]。2017年,图卷积网络模型(GCN)被提出,并且在学习图表征方面表现出强大的表示能力,在以知识图谱[13-14]、推荐系统[15-16]、文本分类[17-18]为代表的广泛的任务和应用中表现出了卓越的性能。在过去的几年里,许多其他类型的图神经网络已经被提出,如图自动编码器、图生成模型、图注意模型,以及图递归神经网络。除了对节点的特征表示进行学习外,学者开始使用图神经学习对整个图结构的表示,将图表示为一个特征向量,从而分析不同图结构的异同。
针对现有合作伙伴推荐模型存在的不足,本文将链路预测与深度学习方法相结合,提出了一种基于图卷积网络的发明人跨领域合作伙伴识别方法,这种方法的主要思想是利用GCN来综合学习节点网络之间的互动关系以及节点自身的属性信息,然后基于特征学习来预测节点间的链接。该方法不仅考虑了节点的局部信息,还考虑了节点的全局信息和节点特征,能够更好地捕捉到节点的复杂关系,从而提高潜在合作伙伴寻找的效率和准确性。
2 研究设计
本文从发明人专利信息中的合作关系特征、摘要文本特征、领域信息特征三个维度视角下构建发明人合作网络,提出基于图卷积网络的发明人跨领域合作伙伴识别方法,将现实复杂的发明人潜在合作伙伴选择问题转化为适合图卷积网络工作模式的链路预测任务。如图1所示,从发明人专利信息中提取发明人之间的合作信息,构建发明人合作网络,提取发明人专利摘要信息和领域信息构造发明人节点的节点特征。接着,将所构建的发明人合作网络和发明人节点特征输入图卷积网络,训练图卷积网络之后利用链路预测思想预测发明人的潜在合作伙伴。在此基础上,构建同领域指数和跨领域指数准确识别出发明人跨领域合作伙伴,为发明人在现实中展开合作提供参考。

图1 发明人跨领域合作伙伴识别方法框架
2.1 多维特征提取
2.1.1合作维度特征
本文抽取专利信息中的发明人共现信息作为发明人之间的现实合作关系,首先从专利数据库中抽取某一领域的专利信息,剔除其中只存在单一发明人的专利信息,提取剩余专利的发明人信息以及他们的合作关系。在此基础上构建发明人合作网络,合作网络的节点为发明人,边为发明人之间的合作关系。具体来说,如果两个发明人在一项专利中有过合作,那么就在他们之间添加一条边,边的权重为发明人之间的实际合作次数。为适应图卷积网络的输入形式,将上述发明人合作网络构建成一个邻接矩阵,如公式(1)所示。

(1)
合作网络的邻接矩阵是一个二维矩阵,其大小是n×n,其中n表示发明人的数量。邻接矩阵的元素Aij的取值为发明人之间的实际合作次数。
2.1.2摘要文本特征
本文以专利摘要文本数据为研究对象,首先将专利的摘要文本信息进行分词、去除停用词等预处理,使用预训练的词嵌入模型Doc2Vec将每篇专利转化为向量表示。Doc2Vec是一种能够理解文本语义的文档嵌入方法,它可以将每篇专利摘要映射到一个固定长度的连续向量,这个向量可以捕捉到专利摘要的语义信息[19]。在处理发明人摘要文本维度特征时,存在发明人专利数量不一致的情况,因此本文在将发明人的摘要文本维度特征汇总时使用平均汇总方法,即对于每一位发明人,我们将其所有专利摘要的向量表示进行平均,以此得到发明人的整体摘要文本特征。具体来说,如果一位发明人有n篇专利摘要,那么其整体摘要文本特征可以由这n个向量的平均值来表示。
2.1.3领域维度特征
本文以专利IPC数据为研究对象,考虑构建IPC维度特征矩阵的稀疏度,使用IPC大组信息表征细分技术领域。由于IPC分类的标签是字母和数字的组合,为方便在计算过程中使用IPC分布信息,同时为体现IPC分布的领域特征,本文考虑将IPC分类进行独热编码,即将每个IPC分类都赋予一个独特的维度。其次,计算每位发明人在各个IPC类别中的专利数量,形成每个发明人的IPC分布向量。为了消除发明人专利数量的影响,对IPC分布特征进行标准化。具体来说,即将发明人的IPC分布向量除以他们的总专利数量,得到每个IPC分类中的专利占比[20]。最终得到的发明人IPC分布向量表征发明人的领域分布特征,这样图卷积网络可以在学习节点特征和边的同时,让模型在学习过程中充分利用领域分布信息来进行领域特征的学习和传递,也学习到发明人之间合作的模式。
2.1.4发明人节点特征
在获取发明人摘要文本特征和领域分布特征的基础上,进一步将其融合为发明人节点特征。在图卷积网络训练过程中将发明人节点特征嵌入发明人节点,使得图卷积网络可同时学习发明人节点在网络中的结构化拓扑信息与发明人节点特征构成的自身属性信息。
将代表发明人研究领域分布的专利IPC分布矩阵与代表发明人研究主题分布的发明人摘要文本信息节点嵌入向量融合成发明人节点特征矩阵,过程如图2所示。
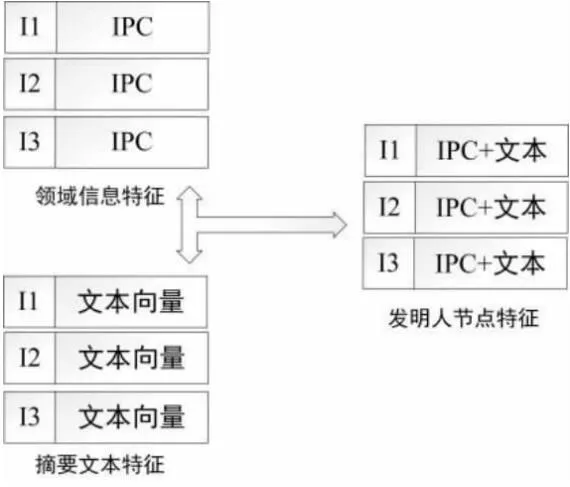
图2 发明人节点特征构建图
(2)
其中,n表示发明人数量,i、j表示各维度特征向量的维度数量。
2.2 发明人潜在合作伙伴识别
发明人潜在合作伙伴识别基于上述发明人合作特征、发明人摘要文本特征和发明人领域分布特征,使用图卷积网络算法(Graph Convolutional networks,GCN)[21]完成,具体步骤为:
b.将发明人节点信息矩阵Xn×(i+j)作为发明人合作网络的节点属性特征。
c.图卷积网络训练时将一部分边作为训练边,剩余的边作为测试边,模型在训练过程中只使用训练边进行参数更新,并计算重构损失(reconstruction loss),即模型重建训练边的能力。模型通过优化重构损失来学习节点的表示,最后利用学习到的节点表示计算链路预测结果。
d.图卷积网络的运算过程如式(3)所示[12, 22]。
(3)

e.经过多层卷积网络操作,得到经过网络处理后的节点特征矩阵X,使用GAE(Graph Autoencoder)作为解码器进行链路预测,运算过程如式(4)所示[23]。
(4)
f.根据链路预测结果,识别发明人之间的潜在合作关系,并进行可视化展示。
2.3 跨领域合作伙伴鉴别
在现今日益复杂和多元化的科研环境下,随着科学知识的积累和技术的发展,单一领域的知识往往无法满足解决复杂问题的需求,寻找跨领域合作伙伴可以获得更广泛的知识和更深入的专业理解,从而在问题解决中取得更大的突破。寻找跨领域合作伙伴是推动创新的重要驱动力,寻找跨领域合作伙伴不仅可以促进科研和技术的发展,也可以帮助研发人员更好地理解和应对社会问题。这种合作有助于科研领域与社会的整合,提高科研的社会价值。
因此,结合发明人的细分技术领域的差异性和现实背景中关于跨领域合作伙伴寻找的迫切需要,本文进一步深化识别潜在合作伙伴与目标发明人是属于同领域还是属于跨领域,从深层次维度上进一步挖掘潜在合作伙伴关系,期待为合作伙伴之间的合作创新模式与规律提供借鉴。
在识别潜在合作伙伴与目标发明人之间的领域归属问题时,往往存在发明人有较多专利或者发明人的领域分布比较复杂的情况,这时发明人之间是否属于跨领域合作创新往往不能一目了然,借助本文提出的同领域指数I和跨领域指数S予以辅助判断,可较为清晰地判别。
本文以发明人的专利IPC信息表征发明人的领域信息,发明人之间的同领域指数I,如公式(5)所示[24]。
(5)
式中,N表示专利数量,N(A∩B)表示发明人A和发明人B共同拥有的IPC对应的专利数量,N(A∪B)表示发明人A和发明人B的专利总量。当两个发明人的同领域指数I较大时,表明两个发明人之间的合作属于同领域加强型合作,当同领域指标较小时,表明发明人之间领域差异较大,但是否属于跨领域仍需进一步界定。
在此基础上本文提出跨领域指标I判断两个发明人之间是否是属于跨领域合作关系,具体公式如公式(6)所示。
(6)
式中,N(A)-N(A∩B|A)表示发明人A拥有但发明人B没有的IPC对应的专利数量,N(A∪B)表示发明人A与B的专利总量。相对于双方来说,发明人A拥有的发明人B没有的IPC对应的比例越大,相较于发明人B,发明人A技术的跨领域程度越大,则两人在合作中产生跨领域、颠覆性创新的程度越大。因此,在两个发明人同领域指数较低的情况下,若发明人A相较于发明人B的跨领域指数较大,则说明发明人B在与发明人A合作时产生跨领域颠覆性创新的可能性较大,其合作创新相较于同领域增强型创新往往能产生更大的突破。
3 实证分析
3.1 数据集
现阶段,随着全球环境压力的日益增加和可持续能源需求的迅速增长,围绕氢燃料电池的科研活动成为了焦点。氢燃料电池作为一种能够转化氢能为电能的清洁技术,具有零碳排放、能量转化效率高、能源存储容量大等优势,为解决全球能源问题提供了一种可能的解决方案。然而,实现氢燃料电池技术的突破和广泛应用,依赖于各领域科研人员的深度合作和跨领域知识的整合。从科研合作的角度来看,寻找氢燃料电池领域发明人的潜在合作伙伴及跨领域合作伙伴显得尤为重要。
本文实证阶段所用专利样本数据来自Incopat全球专利数据库,选取氢燃料电池作为本文的实证方向。提取发明人专利的合作信息作为网络连边的特征来源,提取专利的摘要文本信息作为专利摘要文本特征来源,提取专利的IPC分类号作为专利的领域特征来源。检索条件为:关键词为“氢燃料电池”AND时间=“截止到2023年5月”AND申请地区=“中国”AND专利类型=“发明专利”,合并同族后得到3 024条专利族作为本文的数据研究基础。
3.2 特征提取
3.2.1合作网络连边特征
在获取专利信息后,提取专利信息中的发明人信息作为构建发明人合作网络的依据,本文在发明人合作维度特征提取阶段对数据的处理包括以下几个方面:
a.将发明人之间的共现关系作为发明人之间的合作信息,即发明人A和发明人B共同出现于专利文献C中,即代表发明人A和发明人B之间产生一次合作,则将发明人A和发明人B之间构建一条连边,合作的次数即连边的权重。
b.为适应图卷积网络的输入需要,构建发明人合作网络的邻接矩阵,该邻接矩阵是一个对称矩阵,矩阵的边是发明人,矩阵中的值是发明人合作的权重,即发明人之间合作的次数。由于本文专利数据涉及到的发明人众多,为便于展示,部分邻接矩阵展示如下(见表1):
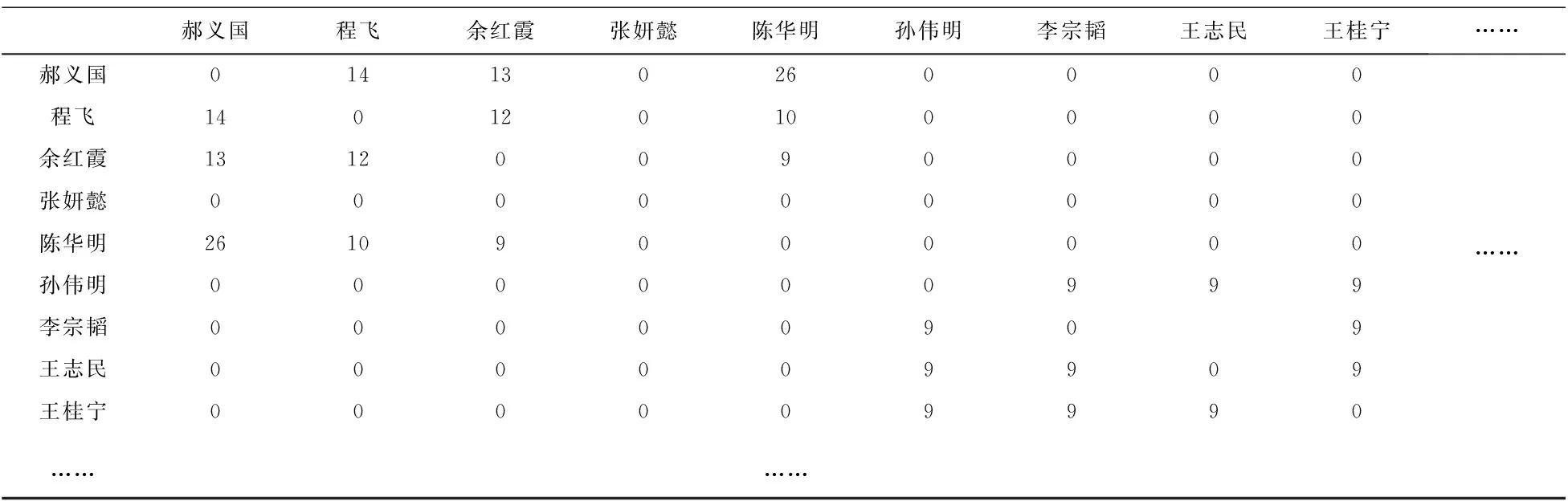
表1 邻接矩阵表(部分)
c.由于本文选取数据涉及发明人众多,邻接矩阵的展示效果不佳,综合考虑发明人合作次数和可视化效果,本文仅选取合作次数在5次以上的85位发明人作为节点构建发明人合作信息网络,具体网络如图3所示。

图3 发明人合作网络
图3为85个节点和111条连边构成的发明人合作网络,图中节点的大小表征了节点度的大小,即与该节点相连的边的数量,亦可表征该节点在合作网络中的重要性,从图中可以看出,郝义国、张妍懿、郝冬等发明人的节点度较大,说明这几个发明人是发明人合作网络的关键节点,即这几个发明人与他人合作次数较多,合作的可能性较大,是我们在实际合作中需要重点关注的对象。图中连边的粗细代表了发明人之间的合作次数,郝义国、陈华明、程飞、安元元、余红霞等人之间的连边较粗,说明这几个发明人在现实中存在较为紧密的合作关系,但也有部分发明人,如杜谦和胡玉凤仅两人之间产生连边,未和其他发明人产生连边,说明这两个发明人在现实中存在紧密的团队合作关系,但其与其他发明人的潜在合作关系是本文的研究重点。
3.2.2合作网络节点属性特征
在提取合作网络节点属性时主要包括三个步骤,即摘要文本特征提取,领域分布特征提取和节点属性特征构建,具体操作步骤如下所示:
a.摘要文本特征提取。在发明人摘要文本特征提取阶段,我们利用Doc2vec算法从专利摘要文本中提取出高维度的特征信息。首先对专利摘要进行预处理,在清洗阶段,移除摘要中的标点符号、数字和停用词,再使用jieba库将每个摘要分解为单独的词语,然后将所有预处理过的专利摘要作为语料库,最后使用语料库来训练Doc2Vec模型。在训练过程中,设置了128维的向量大小来代表每个文档的高维度特征,同时通过调整训练的参数,以优化模型的训练效果。最终使用每个发明人所有摘要文本向量的平均值表征该发明人的摘要文本特征。
b.领域分布特征提取。选用专利数据中涉及到的IPC大组(共计133个)为细分技术领域,用涉及到的133个细分技术领域表征整个氢燃料电池技术领域,以细分技术领域为向量空间维度,统计每个发明人专利的领域分布情况,作为发明人的领域分布特征。为了消除发明人专利数量的影响,对领域分布特征进行标准化。其中,发明人专利中涉及较多的IPC大组如表2所示。

表2 IPC大组TOP10
c.发明人数字特征构建阶段。将发明人摘要文本特征和领域分布特征融合成发明人节点属性特征,在图卷积网络训练前将发明人节点属性特征与合作关系网络一起输入图卷积网络[25]。构建的网络基本信息如表3所示。

表3 网络基本信息
3.3 实证结果
3.3.1模型性能评估
模型有效性的验证通常基于预测的准确性。在链路预测任务中,常用的评估指标有AUC(Area Under the Curve)和AP(Average Precision)。
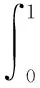
(7)
其中,TPR(f)为真正例率,FPR(f)为假正例率。
(8)
其中,P(k)表示在前k个预测中的精确率,rel(k)表示第k个预测是否是正样本,n表示总预测数,numpos表示正样本的数量。
实验①:使用不同维度特征训练的图卷积网络的潜在发明人自动识别性能对比
本文通过对比实验,采用摘要文本特征和合作关系特征联用的图卷积网络与仅使用合作关系特征的模型性能对比判别摘要文本特征是否能显著提高模型性能,同理,采用领域分布特征和合作关系特征联用的图卷积网络与仅使用合作关系特征的模型性能对比判别领域分布特征是否能显著提高模型性能,最后采用合作关系特征、摘要文本特征和领域分布特征联用判别三维特征联用是否能显著提高模型准确性,不同维度特征的输入对图卷积网络潜在发明人自动识别性能的影响如表4所示。

表4 输入不同维度特征的图卷积网络性能
从表4可知,仅使用合作信息特征的模型AUC值和AP值分别为0.62和0.61,模型在识别发明人潜在合作伙伴时的效果并不好;在添加摘要文本特征后,模型的AUC值和AP值分别为0.75和0.69,在添加领域分布特征后,模型的AUC值和AP值分别为0.73和0.72,说明这两个维度特征加入对模型准确性有显著的提高;在使用合作信息维度特征、摘要文本特征和领域分布特征之后,模型的AUC值和AP值分别达到0.81和0.80,说明三个维度特征的联用相比单个维度特征或者两个维度特征的使用对模型的性能有显著的提高。
实验②:现有研究模型与本文所提模型的潜在发明人自动识别性能对比
本文在实验过程中也应用支持向量机、随机森林、神经网络三种算法完成发明人潜在合作伙伴自动识别,将发明人潜在合作伙伴自动识别问题转化为发明人之间是否会产生合作的二分类问题。鉴于合作信息维度数据输入会对模型准确性造成影响,可能会导致模型的准确性被高估,因此本文在实验时使用上文所构建发明人节点属性特征结合这三种算法完成发明人潜在合作伙伴自动识别任务。上述模型的性能对比结果如表5所示。

表5 各模型性能对比
从表5可知,支持向量机算法的AUC值和AP值分别为0.75和0.72,随机森林算法的AUC值和AP值分别为0.71和0.69,神经网络算法的AUC值和AP值分别为0.76和0.73,本文方法的AUC值和AP值分别为0.81和0.80。总体来看,本文所构建的多维特征视角下的图卷积网络模型的分类预测效果优于传统机器学习算法,证明了本文所构建方法对模型准确性提高有显著作用。
3.3.2发明人潜在合作伙伴自动识别
将发明人合作信息作为图结构,发明人摘要文本特征和领域分布特征作为发明人节点属性输入图卷积网络,使用图自编码器(Graph Auto Encoder,GAE)进行链路预测。
本文在上文构建的85位发明人现实合作网络的基础上增加潜在合作网络连边,具体潜在合作网络关系图如图4所示。

图4 发明人潜在合作网络图
图4仍为85个发明人构成的节点网络图,其中包含111条灰色连边和56条黑色连边,其中灰色连边为发明人之间已经产生的合作关系,黑色连边表示发明人之间的潜在合作关系,鉴于本文选取链路预测值大于0.5的发明人节点对构建连边,故潜在合作关系的连边粗细是相同的。图中可以看出大部分发明人的合作关系较为固定,仅在一个小范围内展开合作,如发明人李彬斌在现实中仅与发明人张剑和李飞产生合作,但其潜在合作伙伴便有四位,分别为张威、郭帅帅、郑振和王震坡,其可与这四位发明人之间展开交流,积极寻找合作机会。图中可以看出,这85个发明人在以往合作中形成了数个合作较为紧密的合作小组,如郝义国、陈华明、程飞、安元元、余红霞等成员的合作小组和孙伟明、董佳怡、王智慧、王志民、王桂宁、李宗韬等为核心成员的合作小组之间产生了较多的潜在合作关系连边,表明这两个组织之间可积极寻找合作机会,共同研发创新。从图中可以看出,85位发明人在现实中产生合作连边的数量较少,通过本文构建的发明人潜在合作伙伴自动识别方法可以有效增加发明人之间的合作互动频率,增强合作科研攻关的能力。
本文将预测链接值排名前20的节点对展示如表6所示。表6中所有的发明人之间还没有产生实际合作关系,链路预测值是各个主体在未来合作产生链接的可能性。

表6 链路预测分数排名TOP20
从表6可知,预测结果中排名第一位的是李庆荣和黎科,李庆荣工作单位为苏州欣富辉精密机械科技有限公司,其主要专利是一种氢燃料电池热管理系统、一种氢燃料电池供氢系统、一种氢燃料电池排水系统等,黎科来自湖南凌翔磁浮科技有限责任公司,其主要专利是采用氢燃料电池的高速悬浮控制电路、基于氢燃料电池的悬浮控制供电电路、基于氢燃料电池的悬浮控制方法和系统等,这两人在现实中并未产生合作,从多维特征视角下考虑这两人的潜在合作机会较大,虽然研究领域没有完全重叠,但这两人可以从不同视角在氢燃料电池领域产生跨领域、突破性的技术创新。
3.3.3跨领域合作伙伴鉴别
在上文识别出发明人潜在合作伙伴的基础上,本文进一步识别目标发明人与潜在合作伙伴之间的合作创新是否属于跨领域合作。本文以上文中产生合作链接关系较多的郝义国为例,对其前5位潜在合作伙伴进行判别,具体计算结果如表7所示。

表7 郝义国潜在合作伙伴判别
根据图卷积网络计算结果,郝冬、董佳怡、王智慧、吴健、杨星是目标发明人郝义国的潜在合作对象的前5位,其链路预测值均远超0.5,表明这5人与郝义国的潜在合作机会较大。根据本文提出的同领域指数S和跨领域指数I计算得出,郝冬、董佳怡与郝义国的专利技术领域较为相似,其在合作时偏向于同领域加强型合作。王智慧、吴健、杨星与郝义国的同领域指数较低,表明其专利技术领域相似程度较低,结合跨领域指数I可以看出,王智慧和吴健的专利技术领域相较于郝义国差别较大,其在现实中展开合作偏向于跨领域合作,而杨星相较于郝义国虽然技术领域相似度较低,但其跨领域指数也较低,主要原因是杨星的专利数量较少,相较于郝义国的专利技术领域补充能力较弱。综上所述,若郝义国偏向于加强现有研发技术,则其可以寻求与郝冬、董佳怡在同领域展开增强型合作创新;若郝义国偏向于创新性、颠覆性技术创新,则可以积极谋求与王智慧、杨健进行合作,其在合作中展开跨领域合作,有助于获得更广泛的知识和更深入的专业理解,从而在问题解决中取得更大的突破。
4 结 论
随着科技创新的爆炸式发展,单个发明人往往难以涵盖创新所必备的知识和技能,发明人之间展开合作创新不仅可以提高创新的效率和质量,还可以促进知识的传播和技术的转移,有助于推动科技的进步和社会的发展。对此,本文融合发明人多维特征,使用图卷积网络模型,将发明人潜在合作伙伴寻找任务转化为适合图卷积网络工作的链路预测任务。在此基础上,构建同领域指数和跨领域指数准确识别出发明人跨领域合作伙伴。主要研究结论如下:
a.多维度提取发明人特征,拓宽伙伴选择维度。现有研究在提取专利特征进行伙伴识别时考虑维度较少,大多研究仅考虑单方面的特征如引用关系、合作关系、文本特征相似度等。本文所提出的发明人跨领域合作伙伴识别方法从合作关系特征、摘要文本特征和领域分布特征三个维度提取发明人信息,从多维度视角利用发明人特征,且通过对比实验,证明了合作关系特征、摘要文本特征、领域分布特征三维特征在进行伙伴识别时能够有效提升模型准确性。本文所使用的伙伴识别三维特征丰富了伙伴选择模型特征表示,对现有研究做出补充。
b.综合利用网络关系和节点特征,提高伙伴识别准确率。现有研究大多基于网络分析、机器学习等方法完成潜在合作伙伴识别任务,但这几类方法往往有其局限性,如复杂网络中的链路预测算法主要基于节点相似性的链路预测指标,且推荐成功率依赖网络本身的拓扑结构,方法适用性较差,机器学习中的集成算法往往计算复杂性较高,忽略了图结构特征的利用。本文所提出的发明人跨领域合作伙伴识别方法从合作关系特征、摘要文本特征、领域分布特征三个维度提取发明人信息,图卷积网络在工作时能够捕捉到复杂的网络关系和节点特征,对图结构数据进行端到端学习,能够更好地理解发明人合作网络中的合作模式和信息传递,相较于现有研究,有效提高了潜在合作伙伴识别准确率。
c.寻找跨领域合作伙伴,助推科研合作攻关。在现今日益复杂和多元化的科研环境下,单一领域的知识往往无法满足解决复杂问题的需求,针对现实背景的迫切需求,本文针对领域信息进行深度挖掘,借助专利的IPC大组指代发明人技术细分领域,构建同领域指数和跨领域指数准确识别发明人跨领域合作伙伴,通过跨领域合作伙伴的精准识别有助于推动跨领域的科研合作,促进科学研究的创新发展,有助于促进不同领域之间的交叉合作和知识转移,创造出更具创新性和前瞻性的成果。
d.动态识别潜在合作伙伴,有效提升伙伴寻找效率。传统的合作伙伴选择往往依赖于专家经验和人工筛选,需要耗费大量时间和精力,且针对数据变化的动态感知能力较弱。随着时间推移,发明人的合作关系特征、摘要文本特征和领域分布特征发生变化,本文构建方法能够敏锐识别发明人特征变化,根据实时数据快速且准确地评估发明人之间的合作潜力,这有助于加快合作伙伴选择的过程,提高选择的效率和准确性。现实合作过程中,发明人可以以月为单位或者以年为单位等进行专利检索,利用本文提出的方法得到现阶段最适合与其合作的潜在合作伙伴及跨领域合作伙伴推荐结果,利用本文方法动态地进行简单、快捷、实时的推荐。
本文的不足之处在于,仅仅考虑发明人的专利信息,而忽略了发明人的多源创新成果(如论文信息等),下一步可以考虑构建融合多源创新成果信息的潜在合作伙伴预测方法,从而更精确地预测发明人之间的潜在合作关系。
