基于数据挖掘的变质岩潜山岩性识别方法
2024-04-24符强谭忠健李鸿儒郭明宇刘志伟苑仁国
符强,谭忠健,李鸿儒,郭明宇,刘志伟,苑仁国
1.中海油能源发展股份有限公司工程技术分公司(天津 300459)
2.中海石油(中国)有限公司天津分公司(天津 300459)
0 引言
从已经发现的众多潜山类型油气藏来看,变质岩潜山约占潜山油气储量发现的四分之三,商业价值很大[1-3]。渤海油田在锦州25-1南构造、渤中19-6构造和渤中13-2构造等多个变质岩潜山中获得了好的油气发现,揭示了变质岩潜山在渤海油气勘探发现中的巨大潜力。
当前对于变质岩潜山岩性的定名,主要依据实验室岩石薄片鉴定结果结合常规测井曲线特征对变质岩岩性进行综合定名[4-6],虽然效果显著,但时效性差,成本较高。与实验室专用的高精度ZSX Primus Ⅱ波长色散X 射线元素荧光光谱仪相比,现场主要选用简易型能量色散型仪器EML-200 型和HB-X100型对现场岩屑进行元素分析,其特点是分析时间短,成本低,结构简单,易于拆卸和搬运,特别适合录井现场的作业环境。但相应的缺点也突出,受俄歇效应和基体效应影响,仪器对低原子序数(如Na元素)和低含量元素的测量精度较低,导致井间可对比性差[7-9],特别是对于由火山岩变质作用形成的非均质性较强的变质岩潜山来说,岩性识别精度更差。其次是缺少相应的变质岩潜山岩性判别图版,行业内相对权威的TAS 图版是基于矿物成分而非元素对火成岩岩性的判别[10]。最后是当前应用元素录井对岩性的判别多是依据经验,比如,陈颖等的塔河油田风化壳卡取难点及方法引用[11],陈然等的库车坳陷博孜1201 井古近系盐底卡层技术[12]。近年来,数据挖掘技术被广泛应用在石油行业。它是一种建立在计算机技术基础上的数学算法分析技术,通过统计、在线分析处理、机器学习、专家系统(经验法则)等方式挖掘隐藏在数据中的人工不易察觉的规律和价值。它的优势在于最大程度降低了人的主观因素在判别结果中的权重,评价结果更加客观且智能。近年来该方法在石油行业的成功案例不胜枚举[13-16]。
井场元素录井数据虽然在一定程度上反应了变质岩潜山岩性的信息,但还无法对变质岩潜山岩性给出准确定名,需要借助数据挖掘技术提高数据本身的价值。本文基于井场元素录井数据,应用数据挖掘技术中的数据降维和随机森林算法,建立岩性判别模型,以实现对变质岩潜山岩性的智能高效判别。
1 识别方法建立及流程
实施方法是基于实验室薄片鉴定及测井数据的岩性结论,将井场元素录井(XRF)数据按照岩性结论整理为初选样本,再通过PCA(Principal Component Analysis)数据降维的方法精简样本,提高样本的代表性,最后应用随机森林算法形成训练样本决策树,进而形成基于随机森林算法的岩性判别模型,利用生成的判别模型对实际井资料进行分析,最终得出岩性判别结果(图1)。
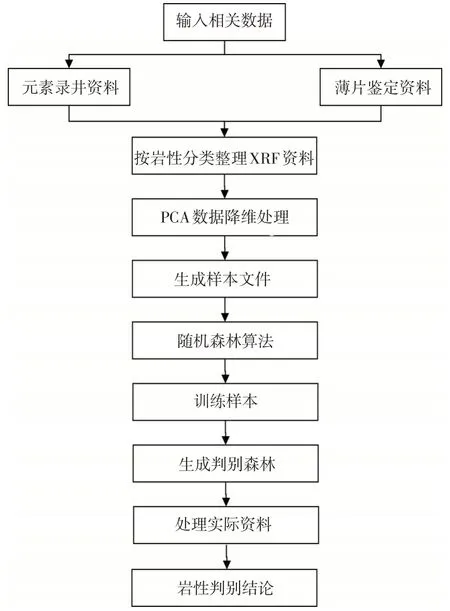
图1 随机森林岩性判别模型建立流程图
1.1 研究区岩性分类
以渤海渤中13-X 构造及渤中19-X 构造为研究目标,研究区潜山受构造及多期次岩浆侵入影响,储层具有岩性及内部结构复杂多样、缝—孔复合发育、非均质性强等特征,严重制约了储层的深入认识。通过研究区渤中13-X 构造电测参数结合岩心及壁心实验室薄片结论可建立综合解释岩电响应关系图版(图2),由图2 可见,研究区不同岩性间的电学特征差异十分明显。图3 为该构造井场人员依据元素录井数据结合经验做出的岩性解释剖面图。从图2、图3 可见,研究区内实际岩性种类繁杂,测井可分出6 种,但井场工程师解释岩性单一,录井仅能识别2 种,虽发现了元素数据含量变化,却无法据此对岩性进行细分判断,使得井场岩性解释不够精确,无法满足变质岩储层快速评价和勘探决策的需求。
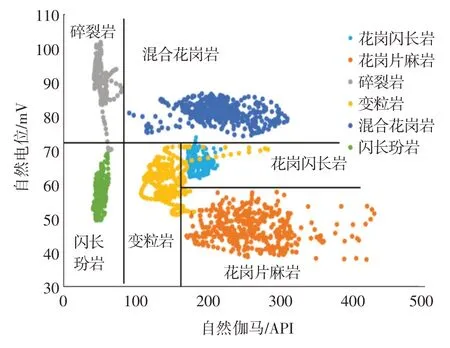
图2 目标区BZ13-X构造岩电响应关系图版
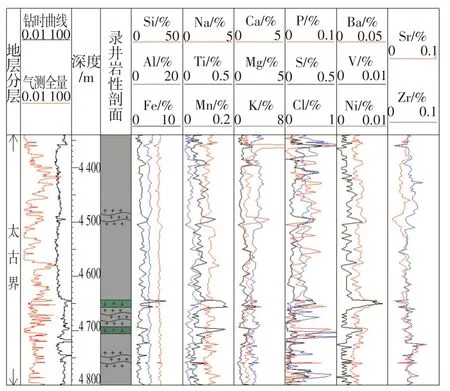
图3 目标BZ13-X构造井场岩性解释剖面图
通过搜集研究区9 口井近600 个元素数据点,综合实验室薄片鉴定及区域不同岩性的测井曲线特征,将研究区岩性归纳为9 类:①二长片麻岩;②变晶花岗片麻岩;③碱长片麻岩;④斜长片麻岩;⑤混合花岗岩;⑥片麻质碎裂岩;⑦变粒岩;⑧闪长玢岩;⑨蚀变辉绿岩。
1.2 数据样本建立及数据预处理
1.2.1 数据样本建立
将上述9种岩性对应的现场元素数据处理形成初步样本,样本包括井场元素录井技术所测得17种元素(Si、Fe、Al、Na、Ti、Mn、Ca、Mg、K、P、S、Cl、Ba、V、Ni、Sr、Zr)和对应的岩性分析结果。
1.2.2 样本数据预处理
综上所述,当前渤海应用的能量色散类EML-200型和HB-X100型元素录井测量仪器对低原子序数(如Na元素)和低含量元素的测量精度较低,结合不同元素的含量情况,为了提高对变质岩潜山岩性的识别准确性,减少不准确元素对最终岩性判别模型的干扰,决定选取常见造岩矿物中具有代表性的7 种主元素,分别为Si、Al、Fe、Ca、Mg、Na、K(表1)。利用数据降维方法对该7 种元素进行降维处理,提取其中的主要敏感元素。
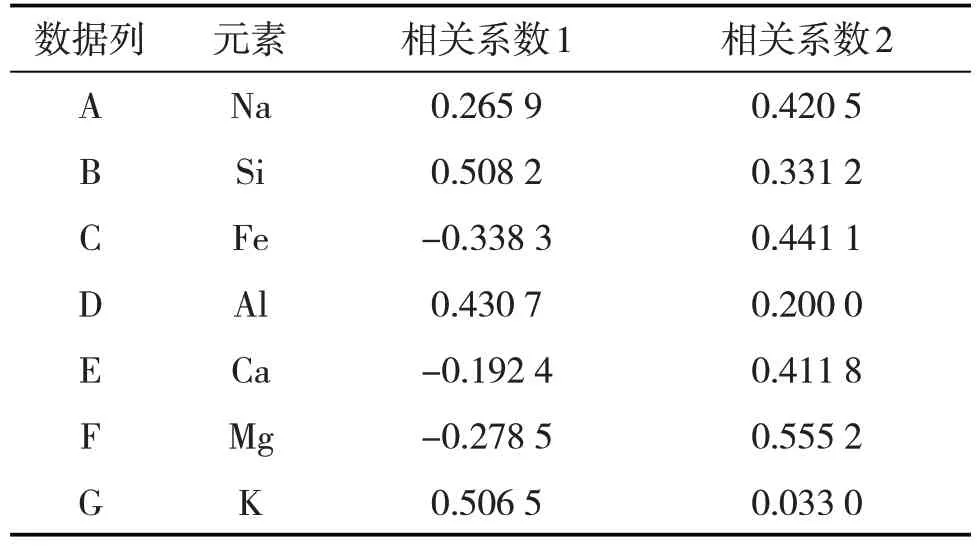
表1 元素数据与岩性的相关系数
1.3 岩性判别模型建立
1.3.1 基于PCA算法的元素录井数据降维处理
1.3.1.1 数据降维原理及推导
PCA 算法是一种常见数据分析方式,常用于将包含冗余信息的高维数据转化为包含原始数据所有主要信息的少量低维数据,即主成分分析。其核心是正交分解。通过选择新的相互正交的空间基向量将若干可能具有相关性的数据变成一组无关变量的方式,用少数几种最关键的主成分为代表,从而实现数据降维的目标[17-18]。
数学推导可以从最大可分性和最近重构性两方面进行,前者的优化条件为划分后方差最大,后者的优化条件为点到划分平面距离最小,这里选择方差最大的方式。PCA算法的典型步骤如下:
1)对原始数据矩阵进行标准化处理。假定原始数据样本数为n,特征变量维数为p,生成矩阵X=(Xi1,Xi2,...,Xip)T,其中i=1,2,...,n,n>p,对样本矩阵进行如下变换:
2)计算相关系数矩阵。通过公式(2)计算得到经过标准化处理后数据的相关系数:
并得到以下相关系数矩阵:
F=,其中p为参数个数,i,j为某个特征列的编号。
3)计算相关系数矩阵F的特征值和特征向量。计算矩阵F的特征值,并按特征值从大到小的顺序进行排列,假定求得的特征值:λ1,λ2...,λp。对应的特征向量为Ai=(Ai1,Ai2,...Aip),i=1,2,...,p。
4)选择重要的主成分,并计算主成分得分。由主成分分析可以得到p个主成分,但是在实际分析时,常根据各个主成分的累积贡献率的大小选取前k个主成分,以达到数据降维的目的。取相关系数矩阵F的特征值的累积贡献率达到一定值的前k个特征值所对应的特征向量组成特征矩阵P,即特征矩阵P=(Ai1,Ai2,...Aik)。
原始数据矩阵X乘以特征矩阵P,就得到了降维后的数据矩阵Q,即Q=XP
1.3.1.2 样本数据降维处理
利用上述降维方法对选取的7种主元素进行降维处理(表1,图4),选择降维后第一个主成分相关的数据列A、B、D、G 为敏感性元素,分别为Si、Al、Na、K,其中Si和Al主要存在于硅铝酸盐,在变质岩矿物中的占比较大,Na和K分别主要存在于变质岩中的斜长石和钾长石,这与研究区变质岩矿物组分也是吻合的。
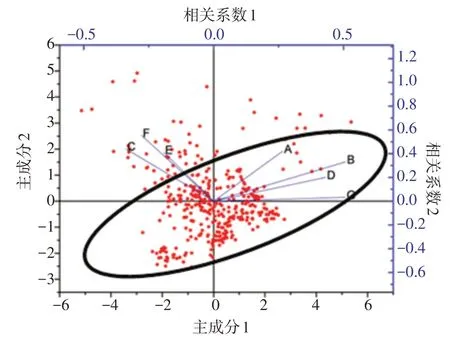
图4 PCA对7种元素进行数据降维处理结果
结合以上结论将初步样本降维处理为表2,形成降维样本数据。
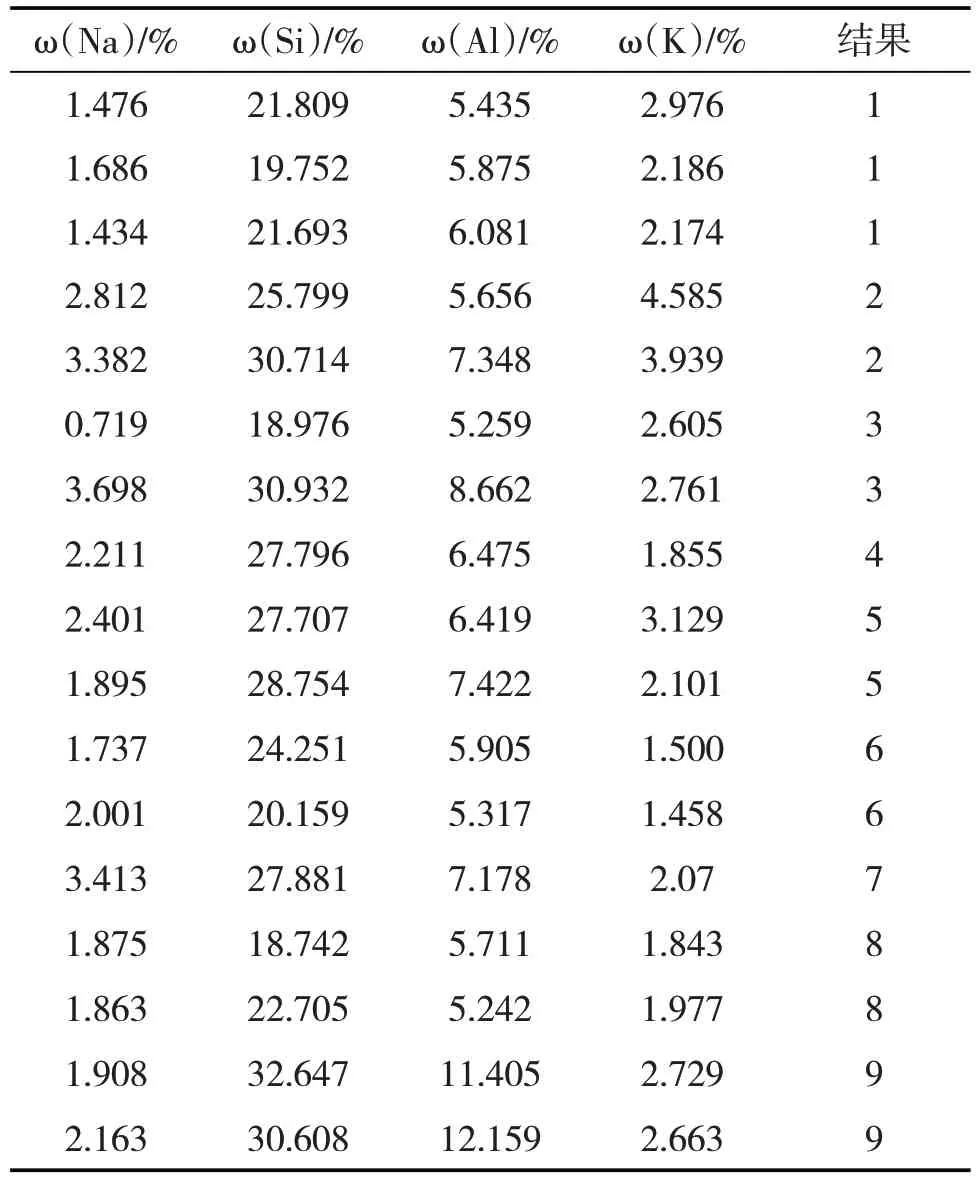
表2 降维后的样本数据质量分数及结果(部分)
从数据降维后的表2 中可以发现,每种岩性没有特别的直观特征,仅依靠个人主观判断无法将岩性进行细分,需要借助一种智能手段辅助进行岩性判别。本文选用数据挖掘技术中的随机森林算法建立对变质岩潜山岩性的判别模型。
1.3.2 基于随机森林算法的岩性识别模型建立
随机森林算法是机器学习领域中的一种集成学习方法[19],它通过集成多个决策树的分类效果来组成一个整体意义上的分类器(图5)。随机森林算法主要有两大优势:①分类准确度高;②算法学习过程快速且易于并行化[20-21]。
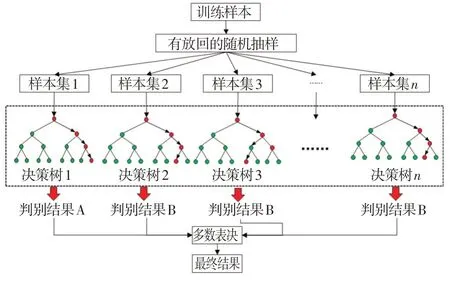
图5 随机森林分类示意图
该方法是用随机的方式建立一个森林,森林里有很多相互之间无关联的决策树。在得到森林之后,当新样本输入时,会在森林中的每棵决策树进行一次分类和判别,系统会统计出判别结果,以出现频率最多的为最终输出结果。
通过样本数据随机选取和待选特征随机选取构建随机森林判别模型。①首先从m个对象数据的样本文件(训练数据)中进行有放回的抽样,构造n个子数据集,然后利用子数据集构建决策树,这些样本组成了决策树的训练数据集。待选特征随机选取即为子决策树构建过程,与数据集随机选取类似,随机森林中的子决策树的每一个分裂过程并未用到所有待选特征。②随机选择一定的特征值,然后再在随机选择的特征中选取最优特征,这样能够保证随机森林中的每一个决策树都不相同,提升系统的多样性,进而提升分类性能。假设每个样本数据均有k个特征,从所有特征中随机选取i(i≤k)个特征,选择最佳分割属性作为节点建立决策树,重复上述步骤即可构建m棵决策树,进而形成随机森林。
应用上述理论,将获得的表3数据做训练数据,以1~9号岩性作为决策树分类模型,对数据降维后的样本数据做随机森林模型建立。建立好的模型可以用来进行新样本的岩性判别,从而实现对区域内变质岩潜山岩性快速识别,减少了个人主观因素对岩性判别结果的影响。
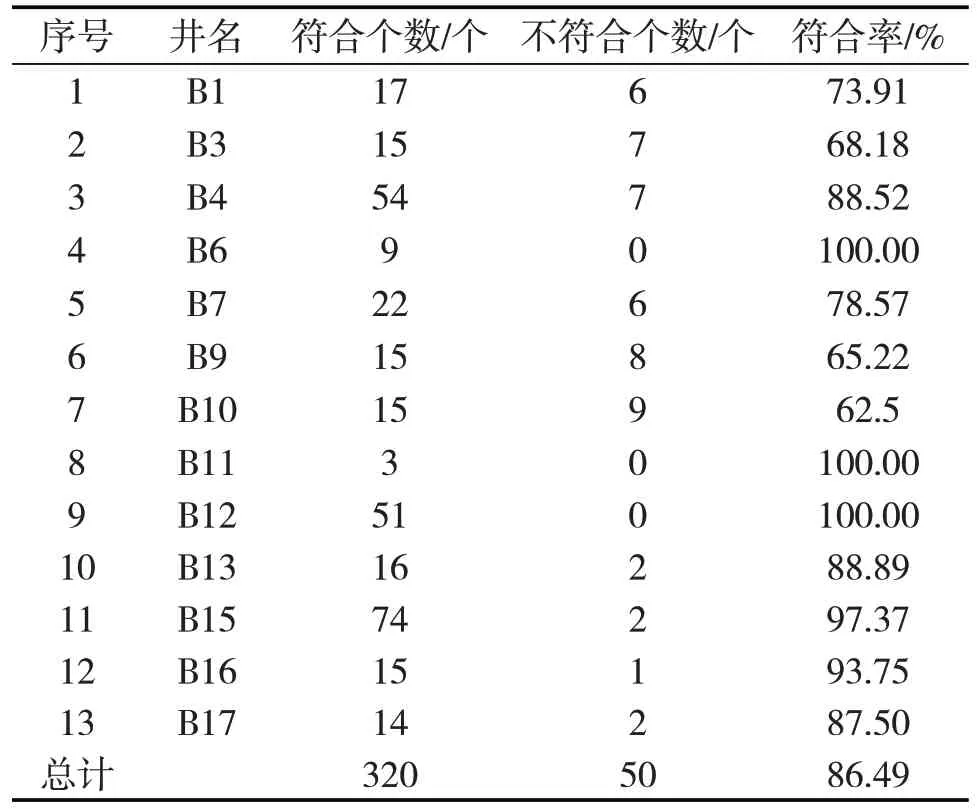
表3 实际资料处理符合率统计表
2 结果与分析
应用已经建立好的变质岩潜山岩性判别模型对目标区渤中19 构造内其余13 口井370 个元素样品资料进行处理,将结果与相应的薄片鉴定结果进行对比,其中320 个符合,50 个不符合,整体符合率达86.5%,与现场录井原始岩性剖面仅60%的准确率相比有很大提高。从图6 可见,本技术方法在变质岩潜山复杂岩性识别上具有较好的实际应用效果。实际资料处理符合率统计见表3。
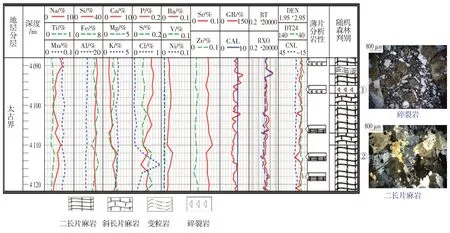
图6 BZ19-B1井元素录井资料处理剖面图(4 088~4 122 m)
由图7 分析可知,该方法能较好地识别变晶花岗岩、碱长片麻岩、混合花岗岩等,而对碎裂岩识别效果相对较差,其中未能识别的碎裂岩21 个,占不符合样本的42%,这主要是由于碎裂岩属于动力变质岩,其母岩与其他变质岩成分相似,因此识别准确率不高,可结合镜下薄片,依据其母岩成分对碎裂岩岩性进行细分,以达到井场元素录井数据可以识别的程度。此外,一部分识别错误存在于岩性变化处,其原因是元素录井资料采样间距为5~10 m,导致在靠近岩性界面处识别效果较差,可以通过空间插值的方法提高元素录井数据间隔密度。
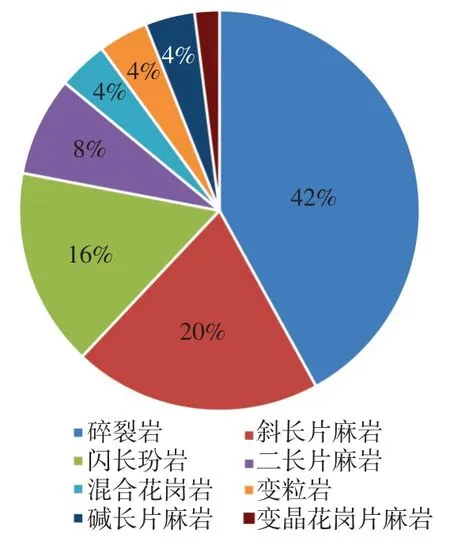
图7 未能识别岩性分析统计图
对于变质岩岩性的识别,行业界还没有统一的标准,相对权威的火成岩岩性TAS 模型也是基于矿物,并没有基于元素的岩性识别模型。本模型的建立一定程度上解决了特定构造内的变质岩潜山复杂岩性的识别问题,但有待改进,需要加入更大更全面的标准样本,加大模型的覆盖面,最终形成一套完整的、行业内相对认可的基于岩石元素数据的变质岩岩性分类及判别模型。
3 结论
1)基于井场元素录井数据,通过数据挖掘技术中的数据降维及随机森林算法,以实验室薄片鉴定结论做标定,建立对变质岩潜山岩性识别模型。该方法对研究区13 口井的岩性识别准确率达到86.5%,可以实现对变质岩潜山岩性的有效智能识别。
2)对于变质岩潜山岩性的识别依托于实验室薄片鉴定的结论,部分岩性定名结论对于井场现有技术条件下较难区分,比如碎裂岩,需要根据其母岩成分进行进一步细分,以达到井场元素录井技术可以判别的程度。
