引入预训练表示混合矢量量化和CTC的语音转换
2024-04-23王琳黄浩
王琳,黄浩
(新疆大学信息科学与工程学院,新疆 乌鲁木齐 830017)
0 引言
语音转换(VC)旨在改变说话人身份而不改变说话内容的过程。根据训练数据的来源和类型可分为平行VC和非平行VC。平行VC利用转换模型学习声级之间的映射关系从源说话人到目标说话人的帧。一般使用的模型包括高斯混合模型[1]、深度神经网络[2]、循环神经网络[3]等。
实际上,收集这种平行语音语料库可能很困难。因此,研究工作越来越集中在非平行VC上。语音后验图(PPG)[4]是非平行VC的典型早期方法。从非特定人自动语音识别器中提取PPG特征帧级语言表示。在实际应用中,PPG特征仍然包含一些说话人信息,往往会导致在转换阶段与预期说话人相似性方面的性能不令人满意。为了提高说话人相似度方面的性能,生成对抗网络(GAN)的变体通过应用鉴别器来模仿人类的听觉感知,如CycleGAN[5]和StarGAN[6]。然而,这些基于GAN的模型通常仍然难以训练。
变分自编码器(VAE)是这些方法针对非平行VC提出的易于训练的常用模型。基于VAE的VC通常采用编码器-解码器框架来学习内容和说话人表征的解纠缠。在传统的基于VAE的VC[7-8]中,编码器从输入声学特征中提取说话人独立的隐变量,解码器从隐变量和给定的说话人表示中重建声学特征。然而,VAE的建模局限于假设的高斯分布,而实际数据的分布可能要复杂得多。在VAE的基础上,通过对变分自编码器进行矢量量化(VQ)形成VQ-VAE[9]以有效解决这一问题。VQ-VAE是由DeepMind开发的一种强大的生成模型,也被应用于非平行VC。与VAE相比,基于VQVC的优势在于它能够通过嵌入字典学习先验知识,而不是使用预定义的静态分布,如高斯分布。矢量量化中的嵌入字典学习完全表示不同的语音内容。虽然VQVC已被证明是一种很有前途的内容和说话者表示解纠缠的方法,但是现有基于VQVC的方法仍然存在一定局限性。在模型训练过程中主要选择梅尔语谱作为输入声学特征,依赖于声学特征的自构误差,不可避免地存在一些信息缺失。由于缺乏语言监督,因此内容表征很难被解开。为解决VQVC中存在的问题,本文提出2种策略:1)选用自监督预训练表示代替传统的梅尔语谱学习内容表征;2)使用联结时序分类(CTC)[10]文本监督辅助网络提纯内容信息。
最近,自监督学习(SSL)在语音处理方面也取得了显著的成果,基于SSL的表征可用于音素识别[11]和说话人分类[12-14],这表明SSL表示中包含的语音和说话人信息都是遗传的。因此,自监督预训练表示(SSPR)被越来越多应用于语音转换任务中。之前的一些工作试图将SSPR引入到VC任务。例如,FragmentVC[15]是1个any-to-any VC模型,它可以将任意源说话人的语音转换为任何目标说话人,甚至是在训练期间未见过的说话人。FragmentVC从SSPR中提取语音信息和目标说话人信息,但它需要额外的交叉注意力模块来对齐源特征和目标特征。
本文将基于自监督预训练模型提取的特征作为系统最初的内容嵌入,送入内容编码器提取内容表征。模型经过内容编码器的输出将被VQ量化为嵌入词典,表示语言信息。解码器将量化的内容表示和说话人表征预测声学特征。VQVC难以将只包含内容信息的表征与自监督预训练表示中声学特征分离开来,为了解决VQVC存在的问题,本文设计CTC辅助网络。通过引入强文本监督对内容编码器输出的表示进行建模,以提高模型的解缠能力。CTC已成为当前端到端自动语音识别(ASR)任务中广泛使用的训练目标函数[16-17]。CTC辅助网络能够引导内容编码器学习更纯的内容表示。CTC loss的好处是让内容编码器的输出不受序列长度的影响。此外,它还考虑了整个特征序列中的全局信息。本文提出使用自监督预训练表征混合VQ和CTC算法的非平行语音转换,模型被命名为SSPR-CTC-VQVC。
1 相关工作
1.1 SSPR学习
受预训练SSL表示和瓶颈特征的启发,越来越多的文章使用SSPR作为初始语言信息,并将其输入到语音转换系统中。内容编码器通过限制瓶颈特征最终获得与说话人相关的内容信息。将预训练模型WavLM[18]作为语音转换系统初始的内容嵌入。WavLM模型结构如图1所示,模型的结构与文献[18]的结构相同。
图1 预训练模型WavLM结构Fig.1 Structure of pre-trained model WavLM
本文采用自监督预训练模型WavLM通过Transformer的最后一层输出作为内容编码器系统输入,用来提取初阶的内容表示。
1.2 矢量量化
VQVC通过嵌入字典学习先验来表示完全不同的语音内容。矢量量化器在矢量量化嵌入字典的帮助下,将从内容编码器输出的连续信息编码为一组离散的嵌入。文献[19]等工作表明,VQ嵌入字典中的每个嵌入都与语音音素有密切的关系,即VQ嵌入字典具有对音素集建模的能力。VQ-VAE结构如图2所示。嵌入字典正式写为A=[a1,a2,…,aN],A∈N×D,有N个不同的码本。在前向计算时,由SSPR得到的声学特征x送入内容编码器中获得ze(x),映射到码本中最近嵌入ai来离散化。z(x)和说话人嵌入s将连接在一起送入解码器。最后,利用解码器D对声学特征进行重构训练的目标函数可以表示为:

图2 VQ-VAE结构Fig.2 The structure of VQ-VAE

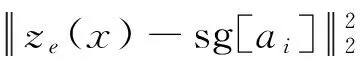
(1)
在矢量量化的损失中添加承诺成本,以鼓励每个ze(x)向所选码本靠近[19]。
1.3 联结时序分类
联结时序分类是一种损失函数,常用于解决输入特征与输出标签之间对齐不确定的时间序列映射问题。对于给定的由矢量量化得到的z(x)嵌入,其输入序列记为I=[i1,i2,…,iT],其中T是输入序列的长度。CTC损失函数的任务是最大化概率分布P(m|I)为对应的音素标号序列m的长度。实验中使用的2个语料库均为英文,选择开源的CMU英语词典和音素集,CMU音素集有39个音素,加上CTC的额外空白标签,音素数为40。CTC损失函数定义为:

(2)
CTC辅助网络如图3所示,包含3个Conv1d层、1个双向长短时记忆(BLSTM)层和1个线性层。每个Conv1d层与批量归一化和ReLU激活层相结合,将BLSTM层和线性层的单元数分别设置为128和40。
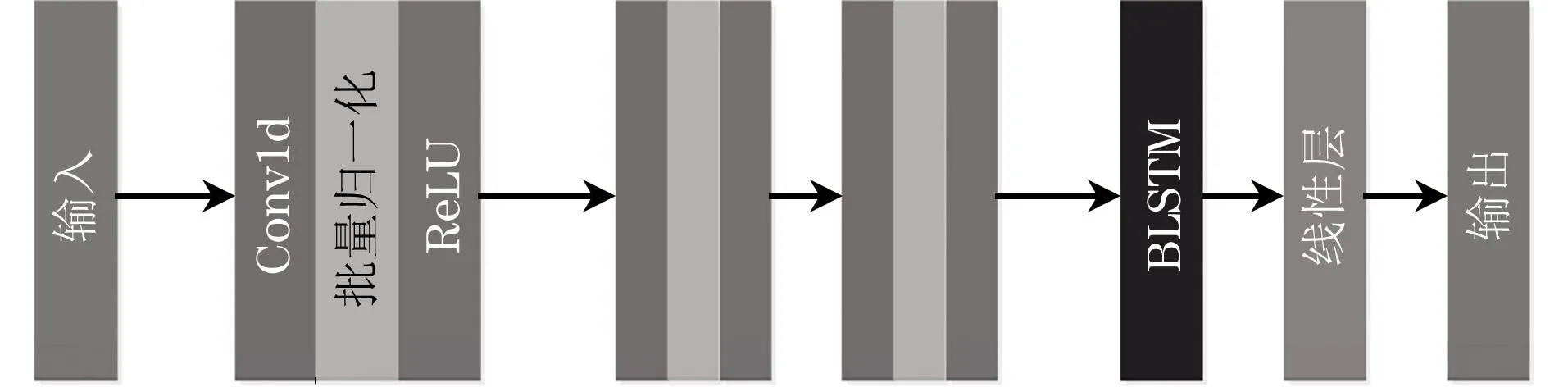
图3 联结时序分类辅助网络结构Fig.3 Structure of connectionist temporal classification auxiliary network
2 模型架构
本文提出的SSPR-CTC-VQVC包括1个内容编码器、1个说话人编码器、1个解码器和声码器。基于WavLM的SSPR送入内容编码器来提取内容表示。说话人嵌入信息是从说话人编码器得到的。VQ将内容表示离散化,CTC辅助网络用于去除内容表示中的说话人信息。将内容表示和说话人表示连接后送到解码器中以获得重构表示,并合成语音。SSPR-CTC-VQVC模型总体架构如图4所示。
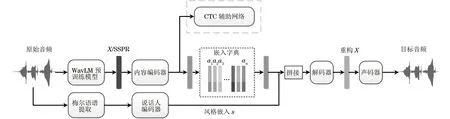
图4 SSPR-CTC-VQVC模型结构Fig.4 The structure of SSPR-CTC-VQVC model
2.1 内容编码器
实例归一化(IN)[20]可以很好地分离说话人和内容表示。与文献[20]不同,本文用4个卷积块改进了其内容编码器,比改进前的多1个卷积块和1个瓶颈线性层。在内容编码器中使用实例归一化层对全局信息进行归一化,有效地提取内容表示。内容表示由4个卷积块和1个瓶颈线性层生成。每个卷积块包含3个具有跳跃连接的Conv1d层,每个Conv1d层与实例归一化和ReLU激活函数相结合。Conv1d层的核大小、通道、步长分别设置为5、256和1。内容编码器将WavLM学习的SSPR作为初步提取内容表示的输入,其结构如图5所示。
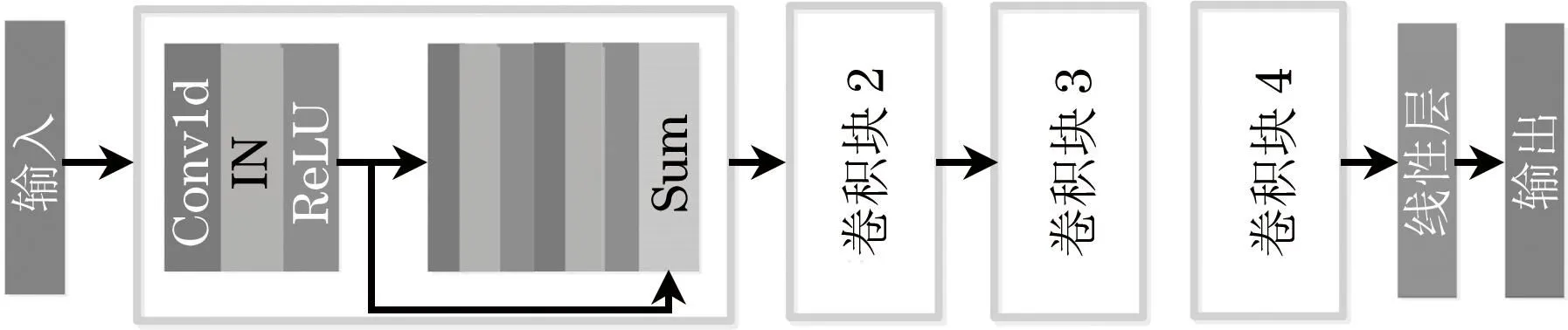
图5 内容编码器结构Fig.5 Structure of content encoder
2.2 说话人编码器
说话人编码器的目标是为不同的话语生成来自同一说话人相同的嵌入,但不同说话人的嵌入不同。一般来说,1个one-hot编码的说话人身份嵌入被用于many-to-many VC中,但实际的VC编码器需要产生可泛化到训练过程中unseen的说话人嵌入。
本文使用全局风格标记(GST)[21]作为也被广泛使用的语音合成说话人编码器。GST能够将变长声学特征序列压缩为固定维说话人风格嵌入并隐式学习说话人嵌入风格标签。说话人编码器结构如图6所示。GST提取说话人风格嵌入需要2个步骤:
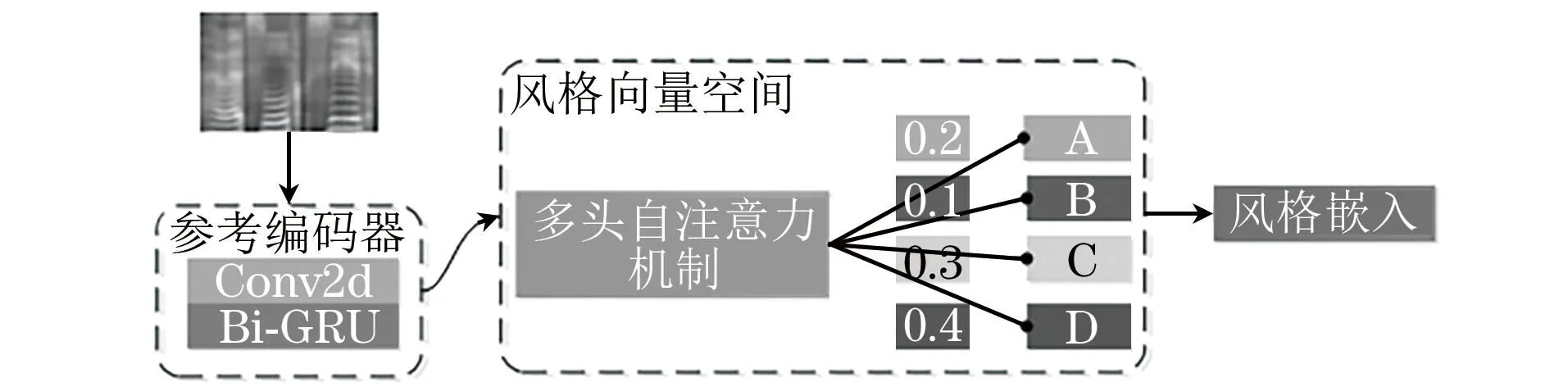
图6 说话人编码器结构Fig.6 Structure of speaker encoder
1)参考编码器采用连续堆叠的方式对声学特征序列进行压缩Conv2d层,然后将双向门控循环单元 (Bi-GRU)层的最后1个状态作为输出参考编码器。将变长声学特征序列转化为固定长度的嵌入,称为参考嵌入。
2)将引用嵌入传递到样式标记层。在样式标记层中,有几个等长的样式标记(例如A、B、C、D)被初始化以模拟不同组件语音(例如情感、节奏、音高、语速等)。多头自注意力模块学习参考嵌入和每个样式Token。注意力模块输出1组组合权重,表示每个样式标记对引用嵌入的贡献。样式标记的加权和命名为风格嵌入。
2.3 解码器
解码器将所有编码器的输出作为输入,重构表示,并将解码后的表示提供给重构的声码器。在实现细节上,实验中使用的网络架构如图7所示。解码器包含3个Conv1d层,1个BLSTM层和1个线性层。每个Conv1d层的内核大小为5,通道数为512,步长为1。BLSTM层的单元数为512。

图7 解码器结构Fig.7 Decoder structure
2.4 多任务损失
使用CTC的VQVC与传统VQVC的相似之处在于两者都采用内容编码器和说话人编码器分别提取内容和说话人表示。区别在于内容编码器的输出是否受到CTC辅助网络 loss的监督。因此,本文提出的模型成为1个多任务学习框架,模型训练需要减少自重建误差、VQ loss和CTC loss。总损失函数可以写成:
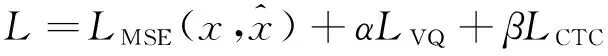
(3)

最后,采用MelGAN[22]作为声码器,以较快解码速度获得高保真波形。
3 实验结果与分析
本文实验的硬件环境:选用单个GPU,其型号为NVIDIA GeForce RTX 2080 Ti。深度学习网络模型搭建使用PyTorch框架,版本为1.8。
3.1 数据集
本文采用VCTK[23]语料库和CMU Arctic[24]语料库对所提的方法进行评价。在VCTK数据库中有109个不同口音的英语使用者,经过预处理后得到了43 398条语句作为训练集。与VCTK语料库不同,CMU Arctic语料库是1个平行英语语料库。男性说话人“bdl”和女性说话人“slt”被选为目标扬声器。男性说话人“rms”和女性说话人“clb”被选为源说话人。本文使用VCTK和CMU Arctic进行训练和测试,此外,选择了CMU Arctic语料库的一部分来评估该方法,其中每个演讲者包括40个语句。首先,从语料库中选取波形数据并转换为1.6×104Hz,然后,WavLM大型预训练模型提取1 024维表示并将其发送到内容编码器,同时提取80维梅尔语谱图并发送到说话人编码器中。
3.2 实验设置
本文选择WavLM学习的表征作为内容表示提取的输入。WavLM预训练模型在LibriSpeech 960h语料库进行训练,学习1 024维的瓶颈特征,用于后续学习内容表示,SSPR经过内容编码器最终得到1 024维表示,说话人表征通过GST最终产生256维的风格嵌入。VQ嵌入字典中的嵌入维度设置为64。为了用英语音素对应的VQ对音素进行建模,VQ嵌入字典中加上了CTC的1个空白标签的嵌入共计40个。CTC辅助网络仅在训练阶段使用。基于编码器-解码器结构将2种表示拼接送入解码器中学习重构的梅尔语谱表征,用于波形转换。本文选择MelGAN声码器,MelGAN是一种条件波形合成模型,具有速度快、模型参数小、非自回归结构等优点。其他型号配置与文献[25]相同。
用于比较的3条基线模型如下:
1)VQVC。从文献[26]中的模型学习得到。该系统以非平行语料为基础,声学特征为梅尔语谱特征,模型结构包括内容编码器、嵌入词典、解码器和GST音色编码器4部分。本文使用Adam优化器以0.000 3的学习率训练VQVC基线模型。小批量大小设置为8。将VQ嵌入的数量设置为40,训练步数设置为3×105。
2)CTC-VQVC。重现了文献[25]模型,该模型由1个带有CTC辅助损失的内容编码器、1个矢量量化器、1个说话人编码器和1个解码器组成。CTC损失的权重在模型训练过程中线性增加,在5×104步内最大值为0.001。
3)FragmentVC[15]。利用预训练模型获取源说话人语音的潜在语音结构,利用80维梅尔语谱图获取目标说话人的音色特征。通过加入注意力机制实现2个不同特征空间的对齐,使用WavLM预训练模型代替wav2vec2.0模型,其余配置不变。
3.3 实验评估
3.3.1 主观评估
为了评估整体语音合成质量,本文收集了所有神经模型输出的平均意见分数(MOS)以及真实记录。语音质量包括自然度和相似度。本文进行性别内和性别间的语音转换实验,并对每个模型测试4种转换:rms→slt(男性到女性),rms→bdl(男性到男性),clb→slt(女性到女性),clb→bdl(女性到男性)。所有4组说话人在训练期间都是隐形的,测试集中每个说话人随机选择了40句话。每次主观评估测试都招募了20名志愿者。对于来自CMU数据集的随机样本,参与者被要求以1~5分的标准对语音的自然度进行评分。分数越高代表语音自然度越高。
语音自然度和说话人相似度的评价结果分别如表1和表2所示,统计了VQVC、CTC-VQVC、FragmentVC和SSPR-CTC-VQVC 4个模型在性别内、性别间和平均3个方面对语音自然度和说话人相似度的主观评价结果。从表1和表2可以看出,SSPR-CTC-VQVC在性别内和性别间语音转换上都明显优于其他方法,并取得了非常好的分数,语音自然度MOS平均值为3.29和说话人相似度MOS平均值为3.22。CTC-VQVC在语音自然度和说话人相似度方面优于VQVC模型,这是因为CTC-VQVC添加的CTC文本监督信息有利于内容建模。此外,与其他3种模型相比,FragmentVC在语音自然度方面的表现较差,可能是因为该模型使用了SSPR取代80维梅尔语谱重新训练的声码器,解码器输出特征与声码器的输入特征不匹配导致的。
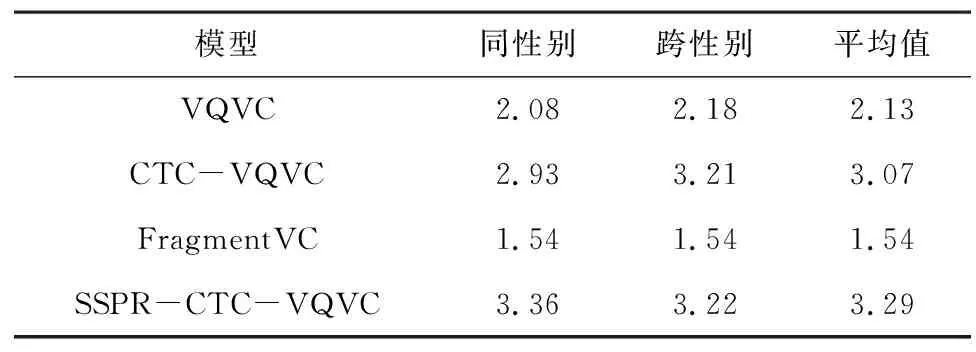
表1 各语音转换方法的语音自然度MOS比较Table 1 Comparison of speech naturalness MOS for each voice conversion methods
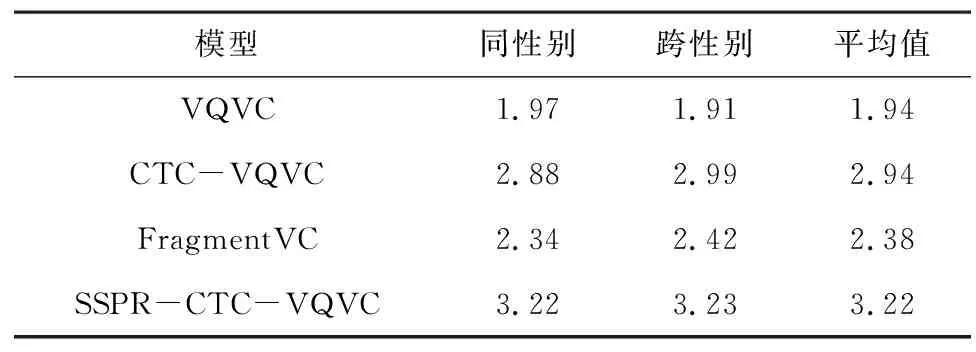
表2 各语音转换方法说话人相似度MOS比较Table 2 Comparison of speaker similarity MOS for each voice conversion methods
3.3.2 客观评价
本文采用梅尔倒谱失真(MCD)对图像的自然度进行客观评价,MCD越低表示自然度越好。在每组VC系统中,本文使用4对转换(clb-slt,clb-bdl,rms-slt,rms-bdl),为每对转换生成40条语句,共计160条语句。分别对同性别(clb-slt,rms-bdl)和跨性别(clb-bdl,rms-slt)各80句以及VC生成的160个语句进行MCD结果验证。
各语音转换方法的MCD比较如表3所示。从表3可以看出,同性别的MCD值整体低于跨性别的值,可能是因为同性别语音转换过程中说话人音色变化幅度小,语音质量稍高。总体来看,SSPR-CTC-VQVC的MCD值低于VQVC和CTC-VQVC。同时使用VQ和CTC辅助网络的性能优于单独使用CTC或仅引入嵌入词典的性能。VQ和CTC辅助网络对内容编码器学习更多的内容信息起相互促进作用。FragmentVC表现最差,可能是因为使用注意力机制的内容和音频之间的映射效果不好。

表3 各语音转换方法的MCD比较Table 3 Comparison of MCD of each voice conversion methods 单位:dB
3.3.3 可视化分析
本文对SSPR-CTC-VQVC模型转换前后进行可视化分析,将真实声音和通过SSPR-CTC-VQVC模型得到的转换后声音进行梅尔谱图可视化。图8显示了CMU中的slt说话人的Arctic_a0002.wav真实语句和由SSPR-CTC-VQVC转换后语音的梅尔谱图对比(彩色效果见《计算机工程》官网HTML版)。

图8 SSPR-CTC-VQVC模型转换比较Fig.8 Comparison of SSPR-CTC-VQVC model transformations
从图8可以看出,经过SSPR-CTC-VQVC转换后的语音与真实语音的轮廓一致,这表明转换后的语音内容得到保留。图8中越亮的点代表分贝越高,从同一频率下的对比可以看出,转换为目标说话人slt的音色、音高等身份信息也得到了保障。
3.3.4 消融实验
关于解耦向量方面,本文对VQ和CTC辅助网络进行消融研究,分别进行了MOS评分(包括语音自然度和说话人相似度)和MCD评分的客观评价。表4显示了在95%置信区间下,2种网络模块对语音自然度MOS值和说话人相似度MOS值以及MCD客观的影响。从表4的MOS值可以看出,这2种辅助网络的模型在性别内和性别间转换的自然性和相似性方面总体优于仅使用VQ或CTC网络模型。从MCD值来看,同时使用2个网络的模型MCD值最小,优于仅使用VQ或CTC的网络模型。上述2组实验证明了SSPR-CTC-VQVC提出的2个辅助内容编码器在学习更纯粹的内容表示方面的有效性。

表4 各语音转换方法的MOS和MCD比较Table 4 Comparison of MOS and MCD of each voice conversion methods
3.3.5 说话人分类
为了验证说话人编码器能够有效地提取说话人信息,本文对编码器提取的风格嵌入进行了说话人分类实验。风格嵌入是从选定的句子中生成的,它表示从句子中提取的关于说话人的信息。说话人分类器对风格嵌入进行分类的能力被用作说话人建模能力的度量。期望的结果是来自同一说话人的不同话语可以聚类在一起,不同说话人可以相互分离。较好的聚类表明说话人分类实验取得了较好的效果,从而证明了说话人编码器能够有效地提取说话人信息。该说话人分类器由3个Conv1d层、1个BLSTM层和1个线性层组成。每个卷积层配对批量归一化和ReLU激活函数,BLSTM节点数量为128个。线性层的激活函数是Softmax,损失函数是交叉熵。
图9显示了CTC-VQVC和所提出的SSPR-CTC-VQVC与t-SNE在二维空间中的向量比较(彩色效果见《计算机工程》官网HTML版),其中图9(a)和图9(b)分别表示CTC-VQVC和SSPR-CTC-VQVC。相同的颜色代表相同的说话人。在说话人分类实验中,本文从VCTK语料库中选取了5位女性说话人(p225、p228、p229、p230、p231)和5位男性说话人(p226、p227、p232、p237、p241),对每个人10条语音进行分类。选择的话语通过GST音色编码器生成其音色向量。从图9(a)和图9(b)中可以看出,同一说话人的10个话语都能聚类在一起,并且不同说话人之间也可以区分开,这表明2个系统的说话人编码器都学习了有意义的说话人嵌入。这表明GST提取的风格向量可以作为说话人身份。此外,与图9(a)相比,图9(b)中同一说话人10句话分布得更紧密。因此,与CTC-VQVC相比,SSPR-CTC-VQVC在不同说话人身份方面具有更好的聚类性能。

图9 CTC-VQVC和 SSPR-CTC-VQVC可视化风格嵌入比较Fig.9 Visual style embedding comparison between CTC-VQVC and SSPR-CTC-VQVC
4 结束语
本文提出一种基于自监督预训练表示同时混合VQ和CTC的单次VC方法SSPR-CTC-VQVC。使用GST获取语音中说话人信息,使用基于WavLM自监督预训练模型学习的表征送入内容编码器中学习最初内容信息的嵌入。与传统使用梅尔语谱作为声学特征学习内容嵌入相比,使用基于预训练模型学习的SSPR减少了嵌入向量中内容信息的损失,提高了语音质量。采用矢量量化和基于联结时序分类的监督模型,从内容表示中去除其中冗余的说话人信息。这2个辅助网络模块对净化的内容向量在性能上是互补的。实验结果表明,本文提出的方法可以很好地从SSPR中学习纯的内容信息,极大地提高了转换后的语音质量。但SSPR-CTC-VQVC学习的内容表示仍包含少量的说话人信息,为了更好地进行语音信息解耦,下一步将设计更好提取纯净内容的方法。比如在VQ层后加入互信息进行内容表征提纯,或者基于梯度反转达到类似于生成对抗网络的作用,进一步将对抗的思想引入到表征学习中,使得说话人表征和内容表征有效分离。
