基于补偿注意力机制的Siamese网络跟踪算法
2024-04-23安玉葛海波何文昊马赛程梦洋
安玉,葛海波,何文昊,马赛,程梦洋
(西安邮电大学电子工程学院,陕西 西安 710121)
0 引言
视觉目标跟踪是计算机视觉领域的一项基本任务。选定视频第一帧中任意一个目标的位置,目标跟踪就是尽可能以最高的精度定位其在所有后续帧中的位置[1]。目前,目标跟踪被广泛应用于智能安防、无人驾驶、智能监控等领域[2-4]。
目标跟踪主要分为基于相关滤波的跟踪方法[5]与基于深度学习的跟踪方法[6]两种。对于前者,研究者们先后提出了很多跟踪算法[7-9],在简单背景下的物体追踪中取得了较好的成绩,但是伴随着对特征的不断改进,基于相关滤波的跟踪方法采用的特征变得越来越复杂,使得计算速度越来越慢,基于相关滤波的追踪器实时性优势逐渐消失。近年来,大数据时代的到来促进了深度学习[10-11]技术的快速发展,深度学习和卷积神经网络(CNN)[12-13]被应用于目标跟踪中,在保证跟踪速度的同时目标跟踪的精度也得到了大幅提升,基于深度学习的跟踪算法[14]在行业中成为研究热点,解决了一些基于相关滤波的跟踪器所存在的问题。但是,由于目标受到运动模糊、复杂背景相似干扰、尺寸变化、遮挡等相关因素的影响,导致这类算法依然面临巨大挑战。
近年来,作为目标跟踪经典框架的Siamese[15-16]网络受到关注,使用卷积神经网络获取目标特征,并将其与搜索区域特征进行匹配以实现目标追踪。Siamese网络最初由文献[17]于2005年提出,用于人脸相似性识别。随后,文献[18]将该框架应用于目标跟踪,并提出了SiamFC跟踪方法,SiamFC具有相同的两路卷积网络分别提取两帧图像特征,将提取的特征执行互相关操作并最终获得目标响应图。SiamFC的提出推动了基于Siamese网络的跟踪算法的发展。之后,许多国内外学者基于此方法对主干网络进行改进,提出了多种优秀的基于Siamese网络的目标跟踪算法。文献[19]将相关滤波器嵌入到SiamFC架构中,并提出CFNet跟踪方法。
文献[20]考虑浅层网络的局限性,使用性能更好的VGG网络取代层数较浅的AlexNet,利用VGG网络能够提取目标高维特征的特点,最终实现了精准高效的目标跟踪。此外,文献[21]还将Faster R-CNN所含的区域候选网络(RPN)应用到目标跟踪领域并提出了SiamRPN追踪方法,通过引入RPN,将目标跟踪任务作为one-shot learning,利用大量的数据集对跟踪器进行端到端的训练,成功平衡了速度与精度。但是,由于其主干网络AlexNet在复杂环境下提取的特征响应图不够准确,因此容易出现跟踪丢失、漂移等问题。针对该问题,SiamRPN++[22]在SiamRPN的基础上提出一种有效的采样策略,成功训练了更深层ResNet结构[23]驱动的跟踪器,在跟踪精度方面取得了目前最优的水平。得益于深度ResNet网络,许多基于Siamese网络的跟踪算法性能得到大幅提高,例如文献[24]在此基础上提出的SiamDW算法。此后,许多跟踪算法也都开始采纳强大的深度架构,这些跟踪算法在ResNet的最后3个残差块中提取特征,并对这些特征进行融合从而获得多通道响应图,最终实现视觉跟踪的目的,因此,ResNet作为骨干网,由于其简单性和强大的性能,已成为Siamese跟踪的首选方案。这些基于Siamese网络的跟踪器通过对特征提取网络与跟踪网络的改进,逐渐提高了成功率与跟踪精度,但是面临目标尺寸变化、复杂相似背景、运动模糊、遮挡等问题时,仍旧无法很好地区分目标与相似的对象。
为了提高跟踪算法面对上述挑战时的成功率与精度,研究者发现将注意力机制[25]融入目标跟踪的模型更利于学习背景信息与目标物体之间的联系,得到更多感兴趣区域的细节信息。这种方式可以通过“动态加权”来抑制背景区域信息同时强调感兴趣区域的信息[26]。CVPR 2017中提出了一种有效的通道注意力机制SENet[27],通过一种全新的架构单元“挤压与激励(SE)”块显示建模通道之间的依赖关系,达到自适应对通道特征响应校准的目的。ECCV 2018中提出的一种双注意力网络CBAM[28],通过利用轻量化注意力模块,在通道以及空间维度上进行加强目标特征权重的操作,实现了高性能目标跟踪。CVPR 2020中对SENet进行分析改进,提出了一种改进的通道注意力ECA-Net[29],通过使用一维卷积实现了一种无须降维的局部不同通道之间的交互策略,并能够自适应确定一维卷积核的大小,最终通过对通道加权提高跟踪效率。
针对基于Siamese网络的跟踪器判别相似目标时精度不高以及抗干扰能力不强的问题,本文提出具有补偿注意力机制的Siamese网络跟踪算法CDAM-Siam。通过加深网络的方式增强追踪器主干网络的特征提取能力,获得强语义特征图,融入注意力机制提高其应对跟踪挑战的能力,从而提高跟踪模型的鲁棒性,实现精准的目标跟踪。
1 相关研究
SiamRPN跟踪算法最先将应用在目标检测算法中的 RPN[30]引入到目标跟踪领域,这为单目标跟踪算法带来了新的思路。SiamRPN具体的算法框架如图1所示(彩色效果见《计算机工程》官网HTML版,下同)。
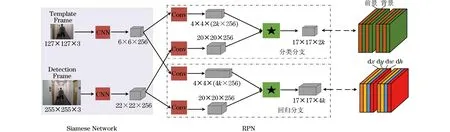
图1 SiamRPN算法框架Fig.1 SiamRPN algorithm framework
图1左侧即为Siamese网络,这2个分支网络除了具有相同的结构外还具有相同的参数。Siamese网络的上方输入为目标跟踪的模板帧,目标跟踪就是依靠输入的bounding box作为标准确定后续帧中的目标位置。下方分支网络的输入为后续视频或待检测的图片序列。RPN网络则是位于整个网络的中间部分,RPN网络又分为上下两部分,上方虚线框内为分类分支,下方框内为回归分支。将模板帧与待检测帧作为输入,首先经过Siamese网络的主干网络进行特征提取,再对得到的特征图进行卷积操作,经过卷积后的模板特征图通道数与待测帧特征图通道数分别为2k×256与4k×256,其中,k代表anchor数量。接着,对这2个不同分支分别进行相关特征图的区域提取。由于在进行跟踪任务时并未提前定义类别,这就需要使用模板分支将目标所具有的外表信息编码进RPN特征图内,由此来区分目标前景和背景。网络最右边即为输出结果。
2 本文Siamese网络跟踪算法
2.1 CDAM-Siam算法整体框架
本文所提CDAM-Siam跟踪算法框架如图2所示。首先采用ResNet-50网络代替AlexNet设计Siamese的主干网络进行特征提取,通过加深网络的方式加强其提取特征的能力;其次ResNet-50卷积层后方的绿色部分为本文提出的具有补偿机制的注意力网络CDAM,这是为了增强特征图的语义信息,以提高跟踪器面对遮挡、目标形变等时的鲁棒性,具体是通过在特征提取网络的卷积层中加权通道和空间注意力来获得更利于追踪的特征图,同时本文算法将模板分支的通道注意力权重复制并添加到了搜索分支,从而提高搜索分支对目标特征的辨别能力;最后对输出的特征图进行由上而下的多层特征融合,让获得的目标特征变得更为突出,将得到的特征图经过RPN以进行区域提取,通过使用回归分支回归目标位置,利用分类分支区分前景和背景,从而完成一帧视频序列的跟踪。为了提高算法的跟踪精度及成功率,将大规模图像对输入到框架中,并对整个系统进行端到端的离线训练。
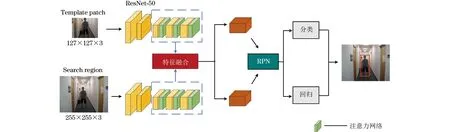
图2 CDAM-Siam跟踪算法框架Fig.2 Framework of CDAM-Siam tracking algorithm
2.2 CDAM注意力模型
本文采用ResNet-50作为骨干网络来提取特征,实验表明不同的通道对同一类别对象的反应不同,因此,深度特征能够学习对象不同的语义信息。由于Siamese网络的双分支结构所提取的特征在空间和通道等维度上具有不同的关注度,因此在特征提取过程中,本文使用注意力网络来过滤图像信息,即让网络进行特征提取时更关注对跟踪任务贡献度高的目标特征而忽略背景信息。
由于特征图的不同通道对图像的信息响应不同,因此本文使用通道注意力来增强对象的特征信息,同时为了消除由不同数据集的数据分布引起的位置偏差,使用空间注意力机制来学习对象的位置,抑制位置偏差,从而增强图像中对象位置信息的表示。因此,本文在追踪器的模板分支和搜索分支的特定层中分别引入这2种注意力网络,增强图像特征表达能力,还将模板分支对物体的特征注意力权重复制添加到搜索分支用于加强对对象特征的辨别能力,具体模型结构如图3所示。下文将重点介绍本模块的通道注意力机制、空间注意力机制与补偿注意力机制。
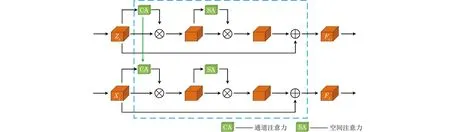
图3 CDAM注意力模型Fig.3 CDAM attention model
将本文所提CDAM注意力机制嵌入到Siamese网络的Conv3、Conv4和Conv5卷积层中,对添加注意力机制后的网络在Biker视频序列、Couple视频序列与Coke视频序列上进行测试,测试结果可视化如图4所示。从可视化热力图中可以明显看到,未添加CDAM模块时,追踪器虽然可以聚焦到目标,但是仍会受到一些背景的影响,而CDAM模块的添加明显提高了识别准确度,减少了背景信息的干扰。
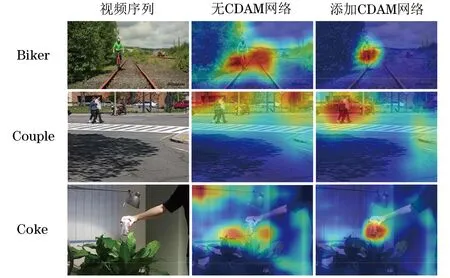
图4 在OTB100中的可视化结果Fig.4 Visual results in OTB100
2.2.1 通道注意力
在跟踪任务中,不同的注意力机制作用不同,不同的特征通道其重要程度也不同,通道注意力旨在给这些通道添加相应的权重系数。本文引入ECA-Net作为通道注意力机制,它具有参数少、更轻量、更稳定等优点,可以在不提高算法复杂度的基础上保证其整体性能。通道注意力机制如图5所示,其中,W、H、C分别为目标特征图的宽、高、通道维数。

图5 通道注意力网络Fig.5 Channel attention network
通过Siamese主干网ResNet-50提取的特征图,首先通过一次全局平均池化操作,将H和W维度都压缩为1,只保留channel的维度,特征图也因此被拉为长条状,得到如下的响应值:

(1)
其中:g为各通道全局平均池化响应值;γij为对应像素点的特征值。然后经过相邻通道数等于n的一维卷积,生成对应通道权重,并将每层的channel和n个相邻层channel信息进行交互,在仅考虑通道yi与其n个相邻通道之间相互作用的情况下计算yi的权重,如下:

(2)
其中:αi,j代表不同通道上对应的学习参数;Ωi,n表示yi的n个相邻通道集合。为了进一步提高模型的效率,减少参数带来的额外计算量,本文使各通道共享相同的学习参数,可得简化后yi权重如下:

(3)
这里可以简单地通过核大小为n的一维卷积来快速实现:
ω=Sigmoid(RCIDn(y))
(4)
其中:CID代表一维卷积。此时等式中的方法是由ECA-Net调用,并且这里仅使用了n个参数,而这个通道模块的作用就是适当捕捉本地跨通道交互,因而确定这个交互覆盖范围大小n就很有必要。在卷积网络中,不同网络架构与通道数目的卷积块通常能够手动调整,从而确定这个交互覆盖的最优范围,但这种通过手动交叉验证来调整的方式会浪费许多计算资源。本文依据ECA模块的方案可知,一维卷积核的大小n与信道维度C成比例,可得表达式如下:
C=ψ(n)=2(χ×n-b)
(5)
因此,当信道维度确定为C时,通过以下方法自适应地确定卷积核大小,可以有效地避免计算资源消耗:

(6)
其中:|·|odd的计算方式为选取最相近奇数;χ与b的取值在本文中分别为2和1。
2.2.2 空间注意力
不同于通道注意力,空间注意力更关注图像空间特征的相关信息,更有利于精确定位目标。空间注意力机制将经过通道注意力机制筛选后的特征进行再次筛选,获取对追踪目标位置更具价值的特征,本文空间注意力网络如图6所示。
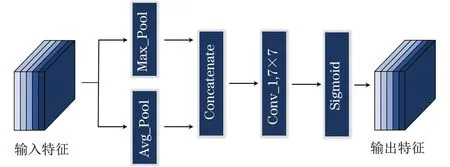
图6 空间注意力网络Fig.6 Spatial attention network
对经过ECA-Net后的特征映射Fi,z∈C×W×H,先经过平均池化和最大池化2个操作,获得2个Fi,max∈H×W×1的二维空间特征描述符,然后,空间特征描述符被级联并发送到一个单一卷积层中,生成一个二维空间注意力图Wi,sz∈H×W×1,将此结果经过Sigmoid激活函数即可生成所需的最终空间注意力特征,其表达式如下:
Wi,sz=Sigmoid(conv([Fi,max,fi,avg]))
(7)
其中:[Fi,max,fi,avg]∈H×W×2表示全局平均池化和最大池化特征描述符的级联;conv表示具有S形激活的单个7×7卷积层。
2.2.3 补偿注意力
Siamese网络的双分支结构分为模板分支与搜索分支,模板分支仅对目标进行特征提取,而搜索分支则对整个输入的图像进行特征提取,因此,跟踪过程中常会出现干扰物影响搜索分支中注意力机制对目标的判断,而补偿注意力机制模型结构可以有效消除这种影响,图7即为搜索分支添加补偿注意力机制的模型结构。

图7 补偿注意力机制模型Fig.7 Compensated attention mechanism model
在图7中,模板分支具有第i层特征Zi∈b×C×W×H,搜索分支具有第i层特征Xi∈b×C×W×H。本文将获得的模板分支特征的通道注意力权重Wi,z与搜索分支的通道注意力权重Wi,x进行加权,作为搜索分支的注意力权重,定义为:
Wi=f(Wi,z,Wi,x)
(8)
其中:f(·)代表fmul(·)。最后,Wi,z与Wi通过对Zi和Xi特征图进行加权,获得第i层中对通道注意力权重重新分配后的特征图,这个特征图对于目标跟踪更加聚焦。
2.3 特征融合网络
一般来说,ResNet-50网络的不同层具有不同的意义,目标跟踪既需要富含深层语义信息的深层特征,又需要颜色、边缘信息等浅层特征来进一步对目标进行定位。来自不同卷积层的特征之间可以相互补充,因此,本文提出一种基于2种不同卷积的特征融合模块。如图8所示,首先使用一个卷积核大小为3×3的反卷积对特征图f2进行空间上采样操作,将f2的大小扩大至与特征图f1相同大小,然而上采样可能引起特征图语义信息不均,从而造成跟踪精度下降问题,本文加入可变形卷积来缓解这种情况;然后将经过反卷积和可变形卷积得到的特征图与f1相加,生成融合的特征图。
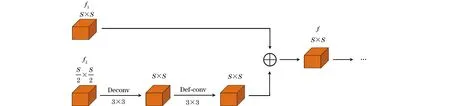
图8 特征融合模块Fig.8 Feature fusion module
依照上述特征融合方法,ResNet-50依次使用从最后3个卷积块中提取的特征进行融合。在特征融合的路径中,使用2个串联的特征融合模块。首先将Conv5和Conv4的输出特征图按上述方法反馈到一个特征融合模块中进行特征融合,即:
fmap=f(fConv5,fConv4)
(9)
其中:fConv5、fConv4分别代表卷积块Conv5、Conv4的输出特征图。然后将这个输出的模块fmap和Conv3的输出特征图反馈到另一个特征融合模块中:
Fmap=f(fmap,fConv3)
(10)
其中:fConv3代表卷积块Conv3的输出特征图。通过这种方式,生成最终的融合特征图Fmap。这种由上而下的融合策略可以获得高分辨率和信息丰富的特征图,还可以增加网络最后一层的感受野,所提算法通过这种融合网络,提高了视觉语义层次的多样性。
3 实验结果与评估
3.1 实验设置
实验所使用的处理器为Intel i9-10900K,10核20线程3.70 GHz,显卡为NVIDIA GeForce RTX3090,显存24 GB。使用PyTorch深度学习框架,利用Python语言在Pycharm上实现运行。
训练数据集选择GOT-10K和YouTube-BB这2个大型数据集,其中,GOT-10K包含了66 GB的图片序列,含有多达563种目标类别以及多于150万个的真实目标边界框;YouTube-BB含有约38万个15~20 s的视频片段,这些视频选取于YouTube网站中的公开视频,主要以自然环境中的目标作为视频内容。在模型训练阶段,由于本文使用层数更深的ResNet-50替代AlexNet作为骨干网络,模型精度得到了很好提升,但是这使得计算模型变得更为复杂,也因此延长了模型训练的时间。
在测试阶段选取OTB100与VOT2018测试集。OTB100共包含100个不同的目标,并对98个视频序列进行了标记,此外还包含了11种不同的挑战属性,分别为尺度变化(SV)、光照变化(IV)、遮挡(OCC)、运动模糊(MB)、形变(DEF)、快速移动(FM)、外平面旋转(OPR)、平面内旋转(IPR)、出视野(OV)、低像素(LR)、背景干扰(BC),每个视频包含一个或以上的挑战属性。首先选取一次通过评估(OPE)为测评标准,OPE将手动标注的真实值与算法所生成的结果进行对比,可以得出算法的成功率和精度并绘制成曲线图;随后在VOT2018数据集上进行性能评估测试,对所提算法进行验证分析。
3.2 消融实验
为了验证本文算法中各模块的有效性,使用OTB100数据集对6组实验进行测试,消融实验结果如表1所示。首先根据第1行可以看到,本文的基线算法SiamRPN的成功率和精度分别为63.1%和85.1%;然后使用深层网络ResNet-50替换AlexNet,由第1行和第2行对比可得成功率和精度分别提升了2.2和1.3个百分点;其次在替换主干网络的基础上添加具有补偿机制的双注意力网络,根据第2行和第4行可得其成功率和精度分别提高了2.3和1.3个百分点;最后在跟踪器中添加特征融合模块(第6行),其成功率和精度与只添加注意力机制(第4行)相比分别提升了0.7和1.8个百分点。因此,每个模块都对本文跟踪算法的性能提升作出了贡献,而且本文算法的速度可达56 帧/s,满足实时性需求。
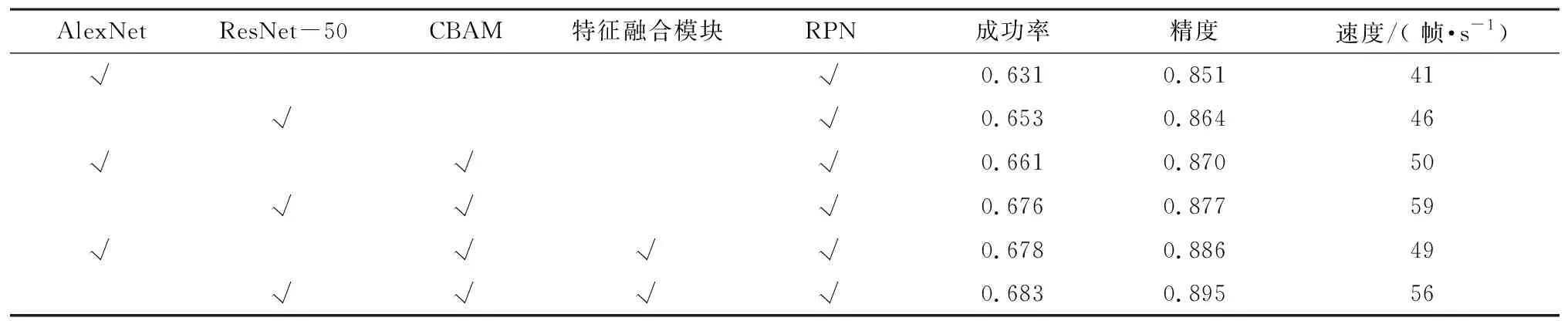
表1 消融实验结果Table 1 Results of ablation experiment
为了进一步确定补偿注意力机制的具体性能,在OTB100数据集上,本文对添加通道、空间注意力并应用补偿注意力机制的追踪器(SiamRPN-CA)与仅添加通道、空间注意力而不添加补偿注意力机制的追踪器(SiamRPN-NCA)进行对比,实验结果如表2所示,实验结果表明,本文所提补偿双注意力机制能够提高Siamese网络追踪器的性能。

表2 补偿注意力机制的影响Table 2 The impact of compensated attention mechanism
3.3 定量分析
将本文所提算法和一些具有代表性的视觉跟踪算法进行对比分析,对比算法包括SiamFC、fDSST[31]、Staple[32]、SiamDWfc、DeepSRDCF[33]、SiamRPN,在OTB100数据集中进行测试,结果如图9所示。由图9可知,本文所提算法CDAM-Siam的平均成功率和平均跟踪精度分别为68.3%和89.5%,均高于其他代表性视觉跟踪算法。与基准算法SiamRPN相比,CDAM-Siam的成功率平均提高了5.2个百分点,跟踪精度平均提高了4.4个百分点。通过定量分析可知CDAM-Siam跟踪器的跟踪效果良好。
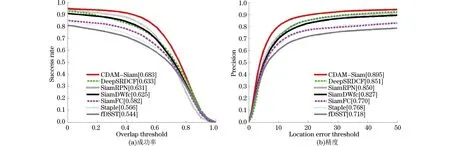
图9 各算法在OTB100数据集上的评估结果Fig.9 Evaluation results of various algorithms on the OTB100 dataset
为了进一步说明本文算法面对不同挑战属性时的跟踪性能,将本文所提算法与其他代表性算法在OTB100各种跟踪挑战属性上的成功率进行对比,结果如表3所示,最优结果加粗标注。根据表3中的结果可知,本文所提算法在面对大多数挑战属性时仍能保持领先水平,其中在遮挡、背景干扰、出视野、光照变化、运动模糊以及形变的挑战属性中得到最优结果,这得益于深层网络对更多深层语义信息的捕获以及注意力机制对重要区域权重的增强,使得模型在目标受到不同挑战时性能可以得到保证。

表3 在OTB100数据集不同属性下算法的跟踪成功率对比Table 3 Comparison of tracking success rate of algorithms under different attributes of OTB100 dataset
3.4 定性分析
从OTB100测试集中选取6段视频序列,分别为:Biker视频序列具有SV、LR、OCC、MB、FM、OPR、OV挑战属性;Couple视频序列具有SV、DEF、FM、OPR、BC挑战属性;DragonBaby视频序列具有SV、OCC、MB、FM、IPR、OPR、OV挑战属性;Ironman视频序列具有IV、SV、OCC、MB、FM、IPR、OPR、OV、BC挑战属性;Jump视频序列具有SV、OCC、DEF、MB、IPR、OPR挑战属性;Skiing视频序列具有IV、SV、DEF、IPR、OPR、LR挑战属性。图10所示为本文算法和其他6种跟踪算法在上述视频序列中的跟踪结果。

图10 7种算法在OTB100部分视频序列中的跟踪结果Fig.10 Tracking results of 7 algorithms in OTB100 partial video sequences
从图10可以看出:
1)遮挡。以视频序列Biker为例,跟踪的主要难点为外界干扰物遮挡目标以及视频分辨率低等问题,造成跟踪过程中出现了跟踪丢失、无法正确跟踪到目标的情况。在第62帧已经出现部分跟踪器跟踪不准确的现象,在后续第112帧、第130帧以及第142帧中,多数跟踪器由于鲁棒性不高,已经无法继续跟踪到目标,只有本文所提算法和SiamRPN算法可以继续跟踪目标物体。
2)背景干扰。以视频序列Couple为例,该视频中存在树木、阴影、车辆等比较多的背景物体,SiamFC以及其他算法对视频序列中的目标判别能力不佳,导致跟踪失败,尤其是在第107帧可以看到只有本文所提算法有效捕捉到了跟踪目标,其他算法则表现出了跟踪漂移现象。这是由于本文算法中所添加的注意力模块可以很好地描述视频序列中跟踪目标的特征信息,在杂乱背景下依旧能够进行稳定的跟踪。
3)出视野。以视频序列DragonBaby为例,该视频中的目标会进行一系列快速动作,并且有消失在视野中的情况,跟踪难度较大。以第48帧为例,其他对比跟踪算法受到影响都出现了不同程度的跟踪不准确或跟踪目标丢失的情况,而本文算法可以有效应对本视频序列中的各项挑战属性,有效捕捉到目标,并且在其他算法跟踪框偏移时,本文算法所代表的红色框更为准确地表示了跟踪物体。
4)光照变化。以视频序列Ironman为例,该视频序列中存在过暗和过亮的巨大光照反差,在跟踪过程中给各种跟踪算法造成了困扰,在视频跟踪序列第17帧、第27帧、第61帧以及第104帧中可以看到,在背景中有剧烈闪光后,各类跟踪算法包括本文所提算法都出现了不同程度的跟踪丢失以及漂移情况,但本文算法相较而言漂移程度较低,可见本文跟踪算法更加鲁棒,能够更好地跟踪到目标。
5)运动模糊。以视频序列Jump为例,跳高运动员在跳高过程中使得目标表观信息产生模糊现象,SiamFC、fDSST、Staple等算法由于模型泛化能力不强,很容易出现跟踪丢失等问题,在视频序列第19帧、第31帧、第74帧和第99帧中,只有本文所提算法完整且准确地框出了目标所在位置,这得益于所提的各个模块,而其他跟踪算法出现跟踪目标丢失、识别目标不完整、偏移等情况。
6)形变。以视频序列Skiing为例,滑雪运动员在空中完成一系列动作,使得目标发生形变,导致跟踪任务难度增加。视频序列具有的挑战属性对各跟踪算法的特征提取能力提出了更高的要求,一些特征匹配或特征提取能力不高的跟踪算法在跟踪中无法正确定位目标,在跟踪序列第15帧、第42帧、第65帧以及第81帧中可见,只有本文所提算法在跟踪过程中保持了对目标的锁定,而其他算法则丢失了跟踪目标,SiamRPN算法也不能一直锁定目标,发生了跟踪漂移、跟踪不准确的情况。
通过对以上涵盖各种挑战属性的跟踪视频序列的分析可以发现,本文所提算法在应对跟踪任务中常见的各种挑战时,依然具有良好的表现,相对其他算法而言对目标的跟踪更为准确。
3.5 性能评估
为了更好地评估所提算法,在VOT2018上进行测试,选择准确率、鲁棒性、平均重叠率(EAO)作为评价指标,其中,EAO代表每帧预测区域与真实区域的交并比平均值。跟踪效果和EAO、准确率成正比,和鲁棒性成反比,实验结果如表4所示。

表4 VOT2018数据集上的评估结果Table 4 Evaluation results on the VOT2018 dataset
从表4可以看出,本文所提算法的准确率、EAO相较于SiamRPN算法分别提高了0.9、1.6个百分点,鲁棒性降低了3.7个百分点。
4 结束语
本文提出一种具有补偿注意力机制的Siamese网络跟踪算法。首先,使用ResNet-50深层网络作为Siamese的骨干网络,对目标特征进行提取;然后,在Siamese网络结构中插入具有补偿注意力机制的双重注意力网络,获取更有利于目标定位的通道及空间注意力特征;最后,使用特征融合网络将来自不同卷积层的特征进行融合,使得不同卷积层的特征被充分利用,最终达到准确进行目标跟踪的目的。在OTB100数据集中的实验结果表明,本文所提算法与基准算法相比网络模型更加鲁棒,且具有更好的跟踪效果,成功率和跟踪精度较基线算法分别提高了5.2和4.4个百分点。下一步将对不同注意力之间的相互干扰作用进行分析,并对能够有效减少注意力模型相互干扰的并行网络进行研究,以提高注意力机制的特征提取效果,从而进一步提升算法的跟踪性能。
